Hur skulle du vilja slå samman "topp"-processen för alla dina 5 databasnoder och sortera efter CPU-användning med bara ett one-liner-kommando? Ja, du läste rätt! Vad sägs om interaktiva grafer som visas i terminalgränssnittet? Vi introducerade CLI-klienten för ClusterControl som heter s9s för ungefär ett år sedan, och den har varit ett utmärkt komplement till webbgränssnittet. Det är också öppen källkod...
I det här blogginlägget visar vi dig hur du kan övervaka dina databaser med din terminal och s9s CLI.
Introduktion till s9s, The ClusterControl CLI
ClusterControl CLI (eller s9s eller s9s CLI), är ett projekt med öppen källkod och valfritt paket som introduceras med ClusterControl version 1.4.1. Det är ett kommandoradsverktyg för att interagera, kontrollera och hantera din databasinfrastruktur med ClusterControl. s9s kommandoradsprojekt är öppen källkod och kan hittas på GitHub.
Från och med version 1.4.1 installerar installationsskriptet automatiskt paketet (s9s-tools) på ClusterControl-noden.
Några förutsättningar. För att du ska kunna köra s9s-tools CLI måste följande vara sant:
- En körande ClusterControl Controller (cmon).
- s9s-klient, installera som ett separat paket.
- Port 9501 måste vara tillgänglig för s9s-klienten.
Att installera s9s CLI är enkelt om du installerar det på själva ClusterControl Controller-värden:$ rm
$ rm -Rf ~/.s9s
$ wget https://repo.severalnines.com/s9s-tools/install-s9s-tools.sh
$ ./install-s9s-tools.shDu kan installera s9s-tools utanför ClusterControl-servern (din arbetsstations bärbara dator eller bastionvärd), så länge som ClusterControl Controller RPC (TLS)-gränssnittet är exponerat för det offentliga nätverket (standard till 127.0.0.1:9501). Du kan hitta mer information om hur du konfigurerar detta på dokumentationssidan.
För att verifiera om du kan ansluta till ClusterControl RPC-gränssnittet korrekt bör du få OK-svaret när du kör följande kommando:
$ s9s cluster --ping
PING OK 2.000 msSom en sidoanteckning, titta också på begränsningarna när du använder det här verktyget.
Exempel på implementering
Vår exempelimplementering består av 8 noder över 3 kluster:
- PostgreSQL strömmande replikering - 1 master, 2 slavar
- MySQL-replikering - 1 master, 1 slav
- MongoDB Replica Set - 1 primär, 2 sekundär noder
Alla databaskluster distribuerades av ClusterControl med hjälp av distributionsguiden "Deploy Database Cluster" och från gränssnittets synvinkel är detta vad vi skulle se i klustrets instrumentpanel:
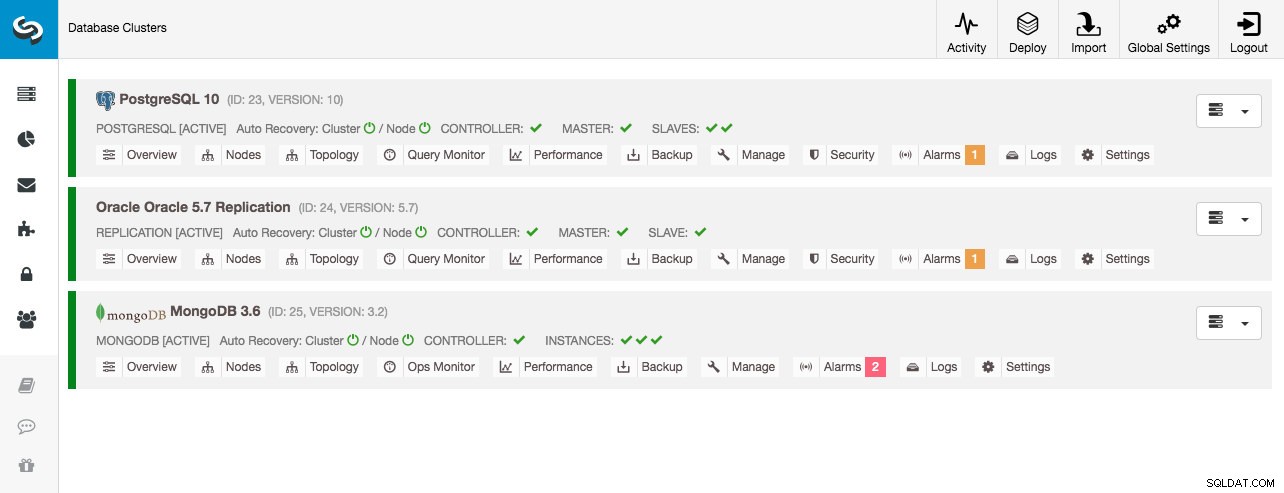
Klusterövervakning
Vi börjar med att lista ut klustren:
$ s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
23 STARTED postgresql_single system admins PostgreSQL 10 All nodes are operational.
24 STARTED replication system admins Oracle 5.7 Replication All nodes are operational.
25 STARTED mongodb system admins MongoDB 3.6 All nodes are operational.Vi ser samma kluster som UI. Vi kan få mer information om det specifika klustret genom att använda flaggan --stat. Flera kluster och noder kan också övervakas på detta sätt, kommandoradsalternativen kan till och med använda jokertecken i nod- och klusternamnen:
$ s9s cluster --stat *Replication
Oracle 5.7 Replication Name: Oracle 5.7 Replication Owner: system/admins
ID: 24 State: STARTED
Type: REPLICATION Vendor: oracle 5.7
Status: All nodes are operational.
Alarms: 0 crit 1 warn
Jobs: 0 abort 0 defnd 0 dequd 0 faild 7 finsd 0 runng
Config: '/etc/cmon.d/cmon_24.cnf'
LogFile: '/var/log/cmon_24.log'
HOSTNAME CPU MEMORY SWAP DISK NICs
10.0.0.104 1 6% 992M 120M 0B 0B 19G 13G 10K/s 54K/s
10.0.0.168 1 6% 992M 116M 0B 0B 19G 13G 11K/s 66K/s
10.0.0.156 2 39% 3.6G 2.4G 0B 0B 19G 3.3G 338K/s 79K/sUtdata ovan ger en sammanfattning av vår MySQL-replikering tillsammans med klusterstatus, status, leverantör, konfigurationsfil och så vidare. Längre fram kan du se listan över noder som faller under detta kluster-ID med en sammanfattad vy av systemresurser för varje värd som antal CPU:er, totalt minne, minnesanvändning, växlingsdisk och nätverksgränssnitt. All information som visas hämtas från CMON-databasen, inte direkt från de faktiska noderna.
Du kan också få en sammanfattning av alla databaser på alla kluster:
$ s9s cluster --list-databases --long
SIZE #TBL #ROWS OWNER GROUP CLUSTER DATABASE
7,340,032 0 0 system admins PostgreSQL 10 postgres
7,340,032 0 0 system admins PostgreSQL 10 template1
7,340,032 0 0 system admins PostgreSQL 10 template0
765,460,480 24 2,399,611 system admins PostgreSQL 10 sbtest
0 101 - system admins Oracle 5.7 Replication sys
Total: 5 databases, 789,577,728, 125 tables.Den sista raden sammanfattar att vi har totalt 5 databaser med 125 tabeller, 4 av dem finns i vårt PostgreSQL-kluster.
För ett komplett exempel på användning av s9s kluster kommandoradsalternativ, kolla in s9s kluster dokumentation.
Nodövervakning
För nodövervakning har s9s CLI liknande funktioner med klusteralternativet. För att få en sammanfattad vy av alla noder kan du helt enkelt göra:
$ s9s node --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.6.2.2662 23 PostgreSQL 10 10.0.0.156 9500 Up and running
poM- 10.4 23 PostgreSQL 10 10.0.0.44 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.58 5432 Up and running
poS- 10.4 23 PostgreSQL 10 10.0.0.60 5432 Up and running
soS- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.104 3306 Up and running.
coC- 1.6.2.2662 24 Oracle 5.7 Replication 10.0.0.156 9500 Up and running
soM- 5.7.23-log 24 Oracle 5.7 Replication 10.0.0.168 3306 Up and running.
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.125 27017 Up and Running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.131 27017 Up and Running
coC- 1.6.2.2662 25 MongoDB 3.6 10.0.0.156 9500 Up and running
mo-- 3.2.20 25 MongoDB 3.6 10.0.0.35 27017 Up and Running
Total: 11Kolumnen längst till vänster anger typen av nod. För den här distributionen representerar "c" ClusterControl Controller, "p" för PostgreSQL, "m" för MongoDB, "e" för Memcached och s för generiska MySQL-noder. Nästa är värdstatus - "o" för online, " l" för off-line, "f" för misslyckade noder och så vidare. Nästa är rollen för noden i klustret. Det kan vara M för master, S för slav, C för controller och - för allt annat. De återstående kolumnerna är ganska självförklarande.
Du kan få hela listan genom att titta på man-sidan för denna komponent:
$ man s9s-nodeDärifrån kan vi hoppa in i en mer detaljerad statistik för alla noder med --stats flagga:
$ s9s node --stat --cluster-id=24
10.0.0.104:3306
Name: 10.0.0.104 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.104 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: slave
OS: centos 7.0.1406 core Access: read-only
VM ID: -
Version: 5.7.23-log
Message: Up and running.
LastSeen: Just now SSH: 0 fail(s)
Connect: y Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 16592 Uptime: 01:44:38
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.168:3306
Name: 10.0.0.168 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.168 Port: 3306
Alias: - Owner: system/admins
Class: CmonMySqlHost Type: mysql
Status: CmonHostOnline Role: master
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 5.7.23-log
Message: Up and running.
Slaves: 10.0.0.104:3306
LastSeen: Just now SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: y SuperReadOnly: n
Pid: 975 Uptime: 01:52:53
Config: '/etc/my.cnf'
LogFile: '/var/log/mysql/mysqld.log'
PidFile: '/var/lib/mysql/mysql.pid'
DataDir: '/var/lib/mysql/'
10.0.0.156:9500
Name: 10.0.0.156 Cluster: Oracle 5.7 Replication (24)
IP: 10.0.0.156 Port: 9500
Alias: - Owner: system/admins
Class: CmonHost Type: controller
Status: CmonHostOnline Role: controller
OS: centos 7.0.1406 core Access: read-write
VM ID: -
Version: 1.6.2.2662
Message: Up and running
LastSeen: 28 seconds ago SSH: 0 fail(s)
Connect: n Maintenance: n Managed: n Recovery: n Skip DNS: n SuperReadOnly: n
Pid: 12746 Uptime: 01:10:05
Config: ''
LogFile: '/var/log/cmon_24.log'
PidFile: ''
DataDir: ''Att skriva ut grafer med s9s-klienten kan också vara mycket informativt. Detta presenterar uppgifterna som den registeransvarige samlat in i olika grafer. Det finns nästan 30 grafer som stöds av detta verktyg som listas här och s9s-node räknar upp dem alla. Följande visar serverbelastningshistogram för alla noder för kluster-ID 1 som samlats in av CMON, direkt från din terminal:
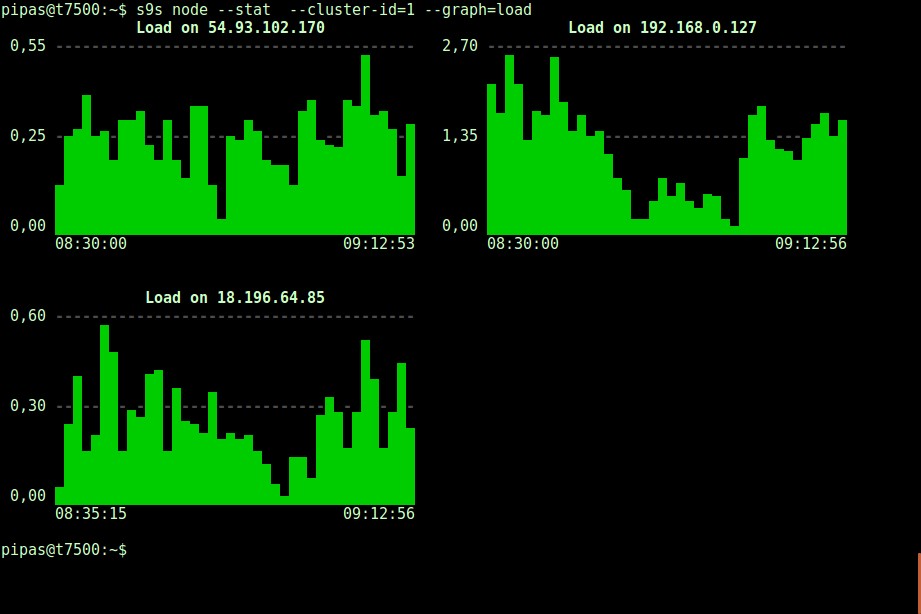
Det är möjligt att ställa in start- och slutdatum och tid. Man kan se korta perioder (som den senaste timmen) eller längre perioder (som en vecka eller en månad). Följande är ett exempel på hur du visar diskanvändningen den senaste timmen:
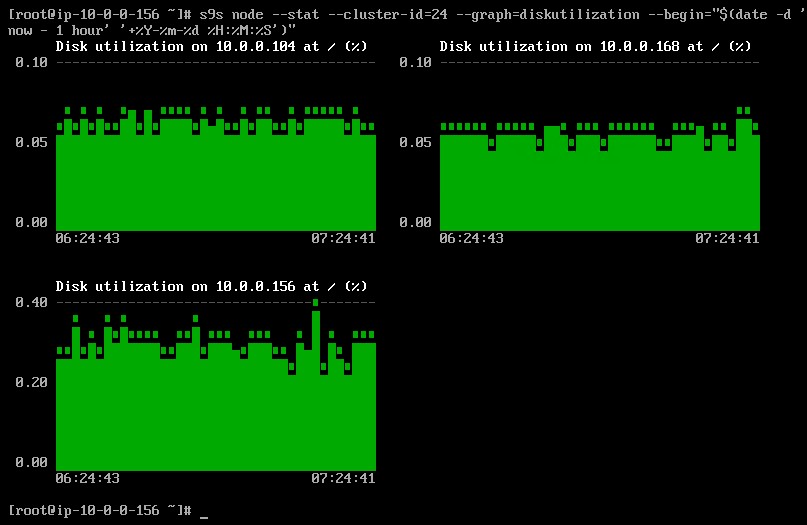
Med alternativet --density kan en annan vy skrivas ut för varje graf. Denna densitetsgraf visar inte tidsserien, utan hur ofta de givna värdena sågs (X-axeln representerar densitetsvärdet):
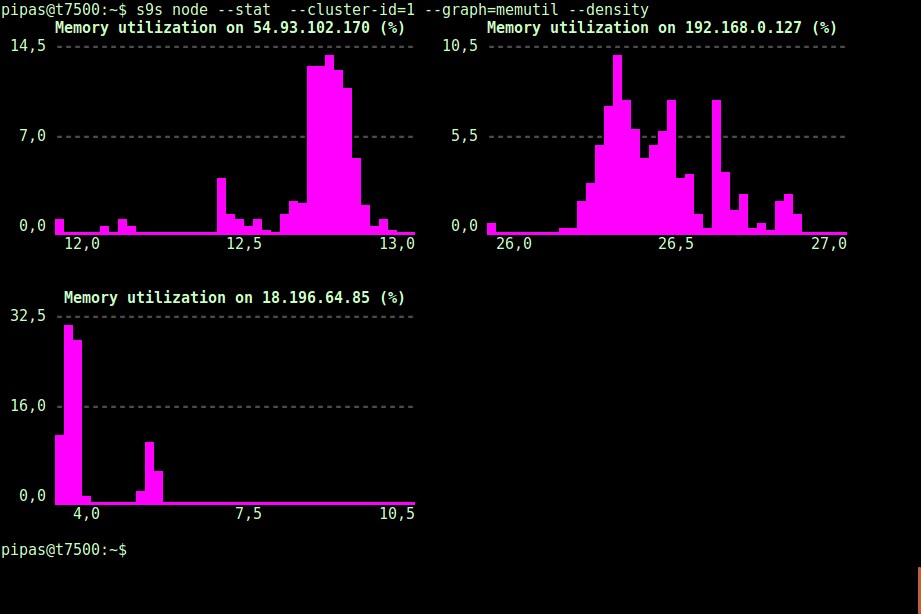
Om terminalen inte stöder Unicode-tecken, kan --only-ascii-alternativet stänga av dem:
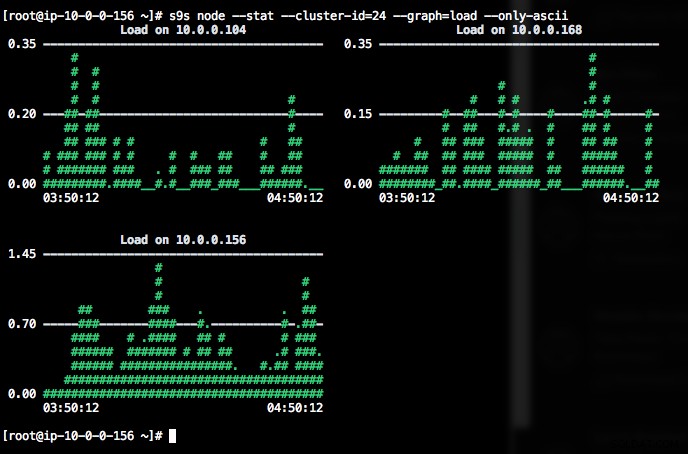
Graferna har färger, där farligt höga värden till exempel visas i rött. Listan över noder kan filtreras med alternativet --nodes, där du kan ange nodnamnen eller använda jokertecken om det passar.
Processövervakning
En annan cool sak med s9s CLI är att den tillhandahåller en processlista över hela klustret - en "topp" för alla noder, alla processer sammanslagna till en. Följande kommando kör kommandot "top" på alla databasnoder för kluster-ID 24, sorterat efter den största CPU-förbrukningen och uppdateras kontinuerligt:
$ s9s process --top --cluster-id=24
Oracle 5.7 Replication - 04:39:17 All nodes are operational.
3 hosts, 4 cores, 10.6 us, 4.2 sy, 84.6 id, 0.1 wa, 0.3 st,
GiB Mem : 5.5 total, 1.7 free, 2.6 used, 0.1 buffers, 1.1 cached
GiB Swap: 0 total, 0 used, 0 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
12746 root 10.0.0.156 20 1359348 58976 S 25.25 1.56 cmon
1587 apache 10.0.0.156 20 462572 21632 S 1.38 0.57 httpd
390 root 10.0.0.156 20 4356 584 S 1.32 0.02 rngd
975 mysql 10.0.0.168 20 1144260 71936 S 1.11 7.08 mysqld
16592 mysql 10.0.0.104 20 1144808 75976 S 1.11 7.48 mysqld
22983 root 10.0.0.104 20 127368 5308 S 0.92 0.52 sshd
22548 root 10.0.0.168 20 127368 5304 S 0.83 0.52 sshd
1632 mysql 10.0.0.156 20 3578232 1803336 S 0.50 47.65 mysqld
470 proxysql 10.0.0.156 20 167956 35300 S 0.44 0.93 proxysql
338 root 10.0.0.104 20 4304 600 S 0.37 0.06 rngd
351 root 10.0.0.168 20 4304 600 R 0.28 0.06 rngd
24 root 10.0.0.156 20 0 0 S 0.19 0.00 rcu_sched
785 root 10.0.0.156 20 454112 11092 S 0.13 0.29 httpd
26 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/1
25 root 10.0.0.156 20 0 0 S 0.13 0.00 rcuos/0
22498 root 10.0.0.168 20 127368 5200 S 0.09 0.51 sshd
14538 root 10.0.0.104 20 0 0 S 0.09 0.00 kworker/0:1
22933 root 10.0.0.104 20 127368 5200 S 0.09 0.51 sshd
28295 root 10.0.0.156 20 127452 5016 S 0.06 0.13 sshd
2238 root 10.0.0.156 20 197520 10444 S 0.06 0.28 vc-agent-007
419 root 10.0.0.156 20 34764 1660 S 0.06 0.04 systemd-logind
1 root 10.0.0.156 20 47628 3560 S 0.06 0.09 systemd
27992 proxysql 10.0.0.156 20 11688 872 S 0.00 0.02 proxysql_galera
28036 proxysql 10.0.0.156 20 11688 876 S 0.00 0.02 proxysql_galeraDet finns också en --list-flagga som returnerar ett liknande resultat utan kontinuerlig uppdatering (liknande "ps"-kommandot):
$ s9s process --list --cluster-id=25Jobbövervakning
Jobb är uppgifter som utförs av styrenheten i bakgrunden, så att klientapplikationen inte behöver vänta tills hela jobbet är klart. ClusterControl utför hanteringsuppgifter genom att tilldela ett ID för varje uppgift och låter den interna schemaläggaren bestämma om två eller flera jobb kan köras parallellt. Till exempel kan mer än en klusterdistribution exekveras samtidigt, liksom andra långvariga operationer som säkerhetskopiering och automatisk uppladdning av säkerhetskopior till molnlagring.
I alla hanteringsoperationer skulle det vara till hjälp om vi kunde övervaka framstegen och statusen för ett specifikt jobb, som t.ex. skala ut en ny slav för vår MySQL-replikering. Följande kommando lägg till en ny slav, 10.0.0.77 för att skala ut vår MySQL-replikering:
$ s9s cluster --add-node --nodes="10.0.0.77" --cluster-id=24
Job with ID 66992 registered.Vi kan sedan övervaka jobID 66992 med jobbalternativet:
$ s9s job --log --job-id=66992
addNode: Verifying job parameters.
10.0.0.77:3306: Adding host to cluster.
10.0.0.77:3306: Testing SSH to host.
10.0.0.77:3306: Installing node.
10.0.0.77:3306: Setup new node (installSoftware = true).
10.0.0.77:3306: Setting SELinux in permissive mode.
10.0.0.77:3306: Disabling firewall.
10.0.0.77:3306: Setting vm.swappiness = 1
10.0.0.77:3306: Installing software.
10.0.0.77:3306: Setting up repositories.
10.0.0.77:3306: Installing helper packages.
10.0.0.77: Upgrading nss.
10.0.0.77: Upgrading ca-certificates.
10.0.0.77: Installing socat.
...
10.0.0.77: Installing pigz.
10.0.0.77: Installing bzip2.
10.0.0.77: Installing iproute2.
10.0.0.77: Installing tar.
10.0.0.77: Installing openssl.
10.0.0.77: Upgrading openssl openssl-libs.
10.0.0.77: Finished with helper packages.
10.0.0.77:3306: Verifying helper packages (checking if socat is installed successfully).
10.0.0.77:3306: Uninstalling existing MySQL packages.
10.0.0.77:3306: Installing replication software, vendor oracle, version 5.7.
10.0.0.77:3306: Installing software.
...Eller så kan vi använda flaggan --wait och få en spinner med förloppsindikator:
$ s9s job --wait --job-id=66992
Add Node to Cluster
- Job 66992 RUNNING [ █] ---% Add New Node to ClusterDet var allt för dagens övervakningstillägg. Vi hoppas att du kommer att ge CLI ett försök och få värde av det. Glad klustring