Automatisk failover för MySQL-replikering har varit föremål för debatt i många år.
Är det en bra sak eller en dålig sak?
För de med långt minne i MySQL-världen kanske de kommer ihåg GitHub-avbrottet 2012 som främst orsakades av att programvara tog fel beslut.
GitHub hade då precis migrerat till en kombination av MySQL Replication, Corosync, Pacemaker och Percona Replication Manager. PRM bestämde sig för att göra en failover efter misslyckade hälsokontroller på mastern, som överbelastades under en schemamigrering. En ny master valdes ut, men den fungerade dåligt på grund av kalla cacher. Den höga frågebelastningen från den upptagna platsen gjorde att PRM-hjärtslag misslyckades igen på den kalla mastern, och PRM utlöste sedan ytterligare en failover till den ursprungliga mastern. Och problemen fortsatte bara, som sammanfattas nedan.
 Källa:Henrik Ingo &Massimo Brignoli’s på Percona Live 2013
Källa:Henrik Ingo &Massimo Brignoli’s på Percona Live 2013 Snabbspola framåt ett par år och GitHub är tillbaka med ett ganska sofistikerat ramverk för att hantera MySQL-replikering och automatiserad failover! Som Shlomi Noach uttrycker det:
"För detta ändamål använder vi automatiska master-failovers. Tiden det skulle ta en människa att vakna och fixa en misslyckad master är över vår förväntade tillgänglighet, och att använda en sådan failover är ibland inte trivialt. Vi förväntar oss att masterfel upptäcks och återställs automatiskt inom 30 sekunder eller mindre, och vi förväntar oss att failover kommer att resultera i minimal förlust av tillgängliga värdar.”
De flesta företag är inte GitHub, men man skulle kunna hävda att inget företag gillar avbrott. Avbrott är störande för alla företag, och de kostar också pengar. Min gissning är att de flesta företag där ute förmodligen önskade att de hade någon form av automatiserad failover, och anledningarna till att inte implementera det är förmodligen komplexiteten hos de befintliga lösningarna, bristande kompetens att implementera sådana lösningar eller bristande förtroende för mjukvara att ta ett så viktigt beslut.
Det finns ett antal automatiserade failover-lösningar där ute, inklusive (och inte begränsat till) MHA, MMM, MRM, mysqlfailover, Orchestrator och ClusterControl. Vissa av dem har funnits på marknaden i ett antal år, andra är nyare. Det är ett gott tecken, flera lösningar betyder att marknaden finns där och att människor försöker lösa problemet.
När vi designade automatisk failover inom ClusterControl använde vi några vägledande principer:
-
Se till att mastern verkligen är död innan du failover
I händelse av en nätverkspartition, där failover-mjukvaran förlorar kontakten med mastern, kommer den att sluta se den. Men mastern kanske fungerar bra och kan ses av resten av replikeringstopologin.
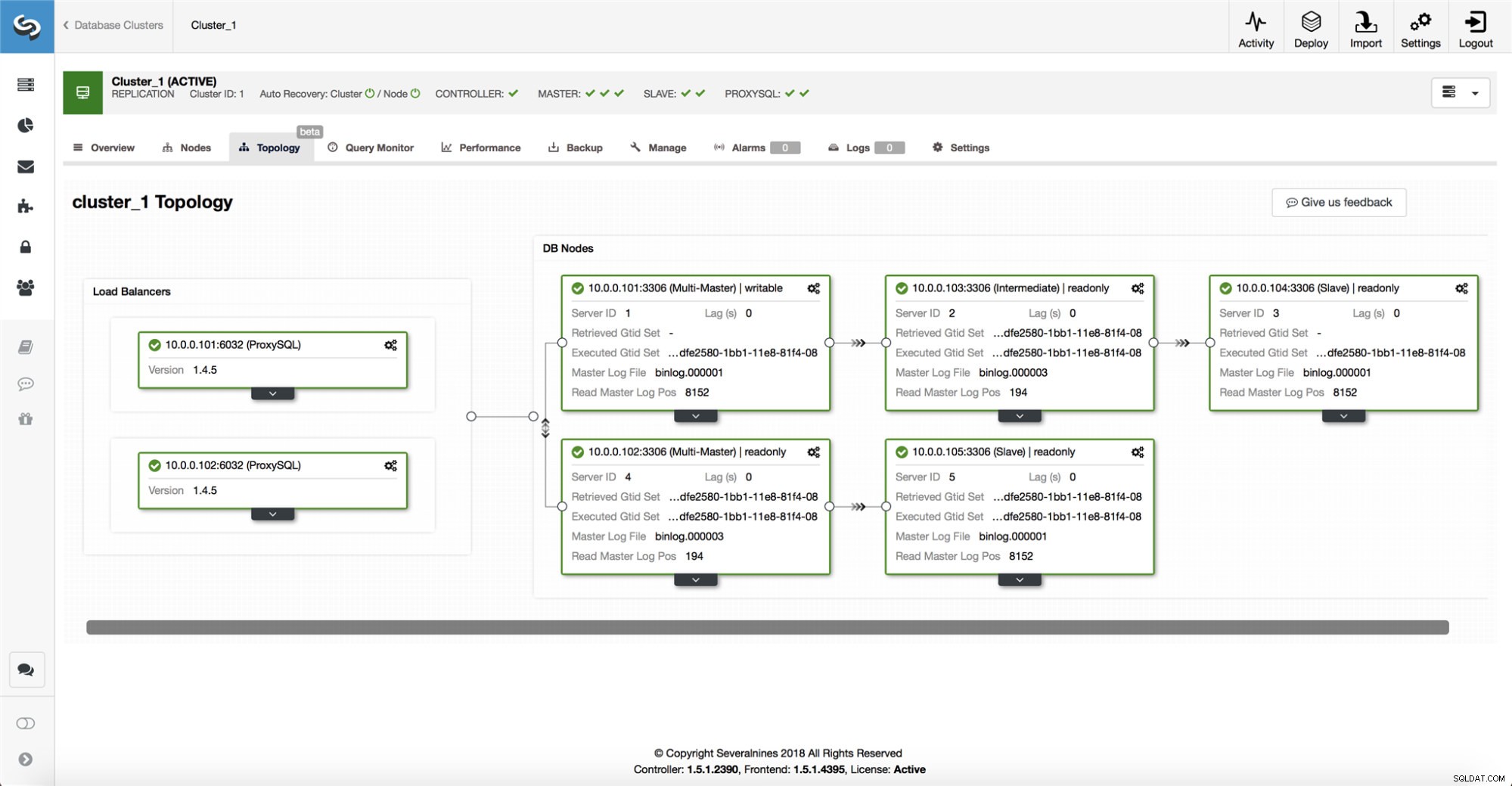
ClusterControl samlar in information från alla databasnoder såväl som alla databasproxyer/lastbalanserare som används och bygger sedan en representation av topologin. Det kommer inte att försöka en failover om slavarna kan se mastern, inte heller om ClusterControl inte är 100 % säker på masterns tillstånd.
ClusterControl gör det också enkelt att visualisera topologin för installationen, såväl som statusen för de olika noderna (detta är ClusterControls förståelse av systemets tillstånd, baserat på den information som samlas in).
-
Filover endast en gång
Det har skrivits mycket om flaxande. Det kan bli väldigt rörigt om tillgänglighetsverktyget bestämmer sig för att göra flera failovers. Det är en farlig situation. Varje vald mästare, oavsett hur kort period den innehade huvudrollen, kan ha sina egna uppsättningar av ändringar som aldrig replikerades till någon server. Så du kan sluta med inkonsekvens mellan alla valda mästare.
-
Failover inte till en inkonsekvent slav
När vi väljer en slav att marknadsföra som master, säkerställer vi att slaven inte har inkonsekvenser, t.ex. felaktiga transaktioner, eftersom detta mycket väl kan bryta replikeringen.
-
Skriv bara till mastern
Replikeringen går från mastern till slaven/slavarna. Att skriva direkt till en slav skulle skapa en divergerande datauppsättning, och det kan vara en potentiell källa till problem. Vi ställer in slavarna till read_only och super_read_only i nyare versioner av MySQL eller MariaDB. Vi rekommenderar också att du använder en lastbalanserare, t.ex. ProxySQL eller MaxScale, för att skydda applikationslagret från den underliggande databastopologin och eventuella ändringar av den. Lastbalanseraren framtvingar också skrivningar på den aktuella mastern.
-
Återställ inte den misslyckade mastern automatiskt
Om mastern har misslyckats och en ny master har valts, kommer ClusterControl inte att försöka återställa den misslyckade mastern. Varför? Den servern kan ha data som ännu inte har replikerats och administratören skulle behöva undersöka felet. Ok, du kan fortfarande konfigurera ClusterControl för att radera data på den misslyckade mastern och få den att gå med som en slav till den nya mastern - om du är okej med att förlora en del data. Men som standard kommer ClusterControl att låta den misslyckade mastern vara, tills någon tittar på den och bestämmer sig för att återinföra den i topologin.
Så, bör du automatisera failover? Det beror på hur du har konfigurerat replikering. Cirkulära replikeringsinställningar med flera skrivbara masters eller komplexa topologier är förmodligen inte bra kandidater för automatisk failover. Vi skulle hålla oss till ovanstående principer när vi utformar en replikeringslösning.
På PostgreSQL
När det kommer till PostgreSQL-strömreplikering använder ClusterControl liknande principer för att automatisera failover. För PostgreSQL stöder ClusterControl både asynkrona och synkrona replikeringsmodeller mellan mastern och slavarna. I båda fallen och vid misslyckande väljs slaven med de mest uppdaterade uppgifterna till ny master. Misslyckade masters återställs/åtgärdas inte automatiskt för att återansluta till replikeringsinställningen.
Det finns några skyddsåtgärder som vidtagits för att se till att den misslyckade mastern är nere och stannar nere, t.ex. den tas bort från lastbalanseringsuppsättningen i proxyn och den dödas om t.ex. användaren skulle starta om det manuellt. Det är lite mer utmanande där att upptäcka nätverksdelningar mellan ClusterControl och mastern, eftersom slavarna inte ger någon information om statusen för mastern de replikerar från. Så en proxy framför databasinstallationen är viktig eftersom den kan ge en annan väg till mastern.
På MongoDB
MongoDB-replikering inom en replikaset via oploggen är mycket lik binlog-replikering, så hur kommer det sig att MongoDB automatiskt återställer en misslyckad master? Problemet finns fortfarande kvar, och MongoDB åtgärdar det genom att återställa alla ändringar som inte replikerades till slavarna vid tidpunkten för felet. Denna data tas bort och placeras i en "återställningsmapp", så det är upp till administratören att återställa den.
För att ta reda på mer, kolla in ClusterControl; och kommentera eller ställ frågor nedan.