Att förbättra systemets prestanda, särskilt för datorstrukturer, kräver en process för att få en bra överblick över prestanda. Denna process kallas allmänt för övervakning. Övervakning är en viktig del av databashantering och den detaljerade prestandainformationen för din MongoDB hjälper dig inte bara att mäta dess funktionella tillstånd; men ger också en ledtråd om anomalier, vilket är användbart vid underhåll. Det är viktigt att identifiera ovanliga beteenden och åtgärda dem innan de eskalerar till mer allvarliga misslyckanden.
Några av de typer av misslyckanden som kan uppstå är...
- Lag eller avmattning
- Otillräckliga resurser
- Systemhicka
Övervakning är ofta centrerad på att analysera mätvärden. Några av nyckelmåtten du vill övervaka inkluderar...
- Databasens prestanda
- Användning av resurser (CPU-användning, tillgängligt minne och nätverksanvändning)
- Tillskjutande motgångar
- Mättnad och begränsning av resurserna
- Genomströmningsåtgärder
I den här bloggen kommer vi att diskutera, i detalj, dessa mätvärden och titta på tillgängliga verktyg från MongoDB (som verktyg och kommandon.) Vi kommer också att titta på andra mjukvaruverktyg som Pandora, FMS Open Source och Robo 3T. För enkelhetens skull kommer vi att använda programvaran Robo 3T i den här artikeln för att demonstrera måtten.
Databasens prestanda
Det första och främsta att kontrollera på en databas är dess allmänna prestanda, till exempel om servern är aktiv eller inte. Om du kör det här kommandot db.serverStatus() på en databas i Robo 3T, kommer du att presenteras med denna information som visar tillståndet för din server.
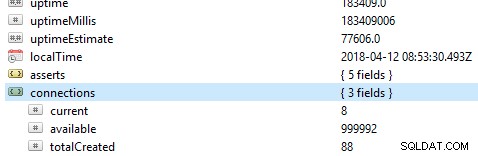

Replika uppsättningar
Replica set är en grupp mongod-processer som upprätthåller samma datamängd. Om du använder replikuppsättningar, särskilt i produktionsläget, kommer operationsloggar att utgöra en grund för replikeringsprocessen. Alla skrivoperationer spåras med hjälp av noder, det vill säga en primär nod och en sekundär nod, som lagrar en samling av begränsad storlek. På den primära noden tillämpas och bearbetas skrivoperationerna. Men om den primära noden misslyckas innan de kopieras till operationsloggarna, görs den sekundära skrivningen men i det här fallet kanske data inte replikeras.
Nyckelmått att hålla ett öga på...
Replikeringsfördröjning
Detta definierar hur långt den sekundära noden är bakom den primära noden. Ett optimalt tillstånd kräver att gapet är så litet som möjligt. På ett normalt operativsystem uppskattas denna fördröjning vara 0. Om gapet är för stort kommer dataintegriteten att äventyras när den sekundära noden flyttas upp till primär. I det här fallet kan du ställa in ett tröskelvärde, till exempel 1 minut, och om det överskrids ställs en varning in. Vanliga orsaker till stor replikeringsfördröjning inkluderar...
- Skärvor som kan ha en otillräcklig skrivkapacitet, vilket ofta är förknippat med resursmättnad.
- Den sekundära noden tillhandahåller data i en lägre hastighet än den primära noden.
- Noder kan också på något sätt hindras från att kommunicera, möjligen på grund av ett dåligt nätverk.
- Operationer på den primära noden kan också vara långsammare och blockerar därmed replikering. Om detta händer kan du köra följande kommandon:
- db.getProfilingLevel():om du får värdet 0, så är dina db-operationer optimala.
Om värdet är 1, så motsvarar det långsamma operationer som följaktligen kan bero på långsamma frågor. - db.getProfilingStatus():i det här fallet kontrollerar vi värdet på slowms, som standard är det 100ms. Om värdet är större än detta kan du ha tunga skrivoperationer på den primära eller otillräckliga resurser på den sekundära. För att lösa detta kan du skala den sekundära så den har lika mycket resurser som den primära.
- db.getProfilingLevel():om du får värdet 0, så är dina db-operationer optimala.
Markörer
Om du gör en läsbegäran till exempel hitta, kommer du att få en markör som är en pekare till datamängden för resultatet. Om du kör det här kommandot db.serverStatus() och navigerar till metrics-objektet och sedan markören, kommer du att se detta...

I det här fallet uppdaterades cursor.timeOut-egenskapen stegvis till 9 eftersom det fanns 9 anslutningar som dog utan att stänga markören. Konsekvensen är att den förblir öppen på servern och därför konsumerar minne, såvida den inte skördas av standardinställningen för MongoDB. En varning till dig bör vara att identifiera icke-aktiva markörer och skörda dem för att spara på minnet. Du kan också undvika markörer som inte har timeout eftersom de ofta håller fast vid resurser och därigenom saktar ner den interna systemets prestanda. Detta kan uppnås genom att ställa in värdet på egenskapen cursor.open.noTimeout till värdet 0.
Journalist
Med tanke på WiredTiger Storage Engine, innan data registreras, skrivs det först till diskfilerna. Detta kallas journalföring. Journalföring säkerställer tillgängligheten och hållbarheten för data om en händelse av fel som en återställning kan utföras från.
I återställningssyfte använder vi ofta kontrollpunkter (särskilt för WiredTiger-lagringssystemet) för att återställa från den senaste kontrollpunkten. Men om MongoDB stängs av oväntat använder vi journaltekniken för att återställa all data som bearbetades eller lämnades efter den senaste kontrollpunkten.
Journalering bör inte stängas av i det första fallet, eftersom det bara tar ungefär 60 sekunder att skapa en ny kontrollpunkt. Om ett fel inträffar kan MongoDB följaktligen spela upp journalen för att återställa data som förlorats inom dessa sekunder.
Journalföring minskar i allmänhet tidsintervallet från det att data appliceras på minnet tills det är hållbart på disken. Storage.journal-objektet har en egenskap som beskriver commiting-frekvensen, det vill säga commitIntervalMs som ofta sätts till ett värde på 100ms för WiredTiger. Att ställa in det till ett lägre värde kommer att förbättra frekventa inspelningar av skrivningar och därmed minska antalet dataförluster.
Låsningsprestanda
Detta kan orsakas av flera läs- och skrivförfrågningar från många klienter. När detta händer finns det ett behov av att hålla konsistensen och undvika skrivkonflikter. För att uppnå detta använder MongoDB multi-granularitetslåsning som gör att låsningsoperationer kan ske på olika nivåer, såsom global, databas eller samlingsnivå.
Om du har dåliga mönster för schemadesign, kommer du att vara sårbar för lås som hålls kvar under långa perioder. Detta upplevs ofta när man gör två eller flera olika skrivoperationer till ett enda dokument i samma samling, med en konsekvens av att varandra blockeras. För WiredTiger-lagringsmotorn kan vi använda biljettsystemet där läs- eller skrivförfrågningar kommer från något som en kö eller tråd.
Som standard definieras det samtidiga antalet läs- och skrivoperationer av parametrarna wiredTigerConcurrentWriteTransactions och wiredTigerConcurrentReadTransactions som båda är inställda på värdet 128.
Om du skalar detta värde för högt kommer du att bli begränsad av CPU-resurser. För att öka genomströmningsoperationerna skulle det vara tillrådligt att skala horisontellt genom att tillhandahålla fler skärvor.
Severalnines Become a MongoDB DBA - Bringing MongoDB to ProductionLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala MongoDBDownload gratisAnvändning av resurser
Detta beskriver generellt användningen av tillgängliga resurser såsom CPU-kapacitet/bearbetningshastighet och RAM. Prestandan, speciellt för CPU:n kan förändras drastiskt i enlighet med ovanliga trafikbelastningar. Saker att kontrollera inkluderar...
- Antal anslutningar
- Lagring
- Cache
Antal anslutningar
Om antalet anslutningar är högre än vad databassystemet klarar av blir det mycket köer. Följaktligen kommer detta att överväldiga databasens prestanda och få din installation att gå långsamt. Detta nummer kan resultera i drivrutinsproblem eller till och med komplikationer med din applikation.
Om du övervakar ett visst antal anslutningar under en period och sedan märker att det värdet har nått sin topp, är det alltid bra att ställa in en varning om anslutningen överskrider detta antal.
Om siffran blir för hög kan du skala upp för att tillgodose denna ökning. För att göra detta måste du veta antalet tillgängliga anslutningar inom en given period, annars, om de tillgängliga anslutningarna inte räcker, kommer förfrågningar inte att hanteras i tid.
Som standard ger MongoDB stöd för upp till 1 miljon anslutningar. Med din övervakning, se alltid till att de nuvarande anslutningarna aldrig kommer för nära detta värde. Du kan kontrollera värdet i anslutningsobjektet.

Lagring
Varje rad och datapost i MongoDB kallas ett dokument. Dokumentdata är i BSON-format. På en given databas, om du kör kommandot db.stats(), kommer du att presenteras med dessa data.
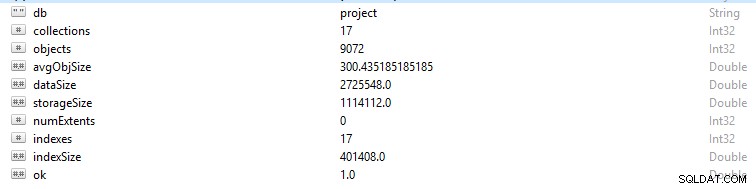
- StorageSize definierar storleken på alla datamängder i databasen.
- IndexSize beskriver storleken på alla index som skapats i den databasen.
- dataSize är ett mått på det totala utrymmet som tas upp av dokumenten i databasen.
Du kan ibland se en förändring i minnet, särskilt om mycket data har raderats. I det här fallet bör du skapa en varning för att säkerställa att den inte berodde på skadlig aktivitet.
Ibland kan den totala lagringsstorleken skjuta upp medan databastrafikdiagrammet är konstant och i det här fallet bör du kontrollera din applikation eller databasstruktur för att undvika dubbletter om det inte behövs.
Liksom det allmänna minnet på en dator har MongoDB även cacher där aktiv data lagras tillfälligt. Emellertid kan en operation begära data som inte finns i detta aktiva minne, vilket gör en begäran från huvuddiskminnet. Denna begäran eller situationen kallas sidfel. Förfrågningar om sidfel kommer med en begränsning av att det tar längre tid att utföra, och kan vara skadligt när de inträffar ofta. För att undvika detta scenario, se till att storleken på ditt RAM-minne alltid är tillräckligt för att tillgodose de datamängder du arbetar med. Du bör också se till att du inte har någon schemaredundans eller onödiga index.
Cache
Cache är ett temporärt datalagringsobjekt för data som ofta används. I WiredTiger används ofta filsystemcachen och lagringsmotorns cache. Se alltid till att din arbetsuppsättning inte buktar ut över den tillgängliga cachen, annars kommer sidfelen att öka i antal och orsaka vissa prestandaproblem.
Vid något tillfälle kan du bestämma dig för att ändra dina frekventa operationer, men ändringarna återspeglas ibland inte i cachen. Dessa oförändrade data kallas för "Smutsiga data". Det finns eftersom det ännu inte har tömts till disken. Flaskhalsar uppstår om mängden "Dirty Data" växer till ett medelvärde som definieras av långsam skrivning till disken. Att lägga till fler skärvor hjälper till att minska detta antal.
CPU-användning
Felaktig indexering, dålig schemastruktur och ovänliga designade frågor kommer att kräva mer CPU-uppmärksamhet och kommer därför uppenbarligen att öka dess användning.
Throughput Operations
Att i stor utsträckning få tillräckligt med information om dessa operationer kan göra det möjligt för en att undvika följdmässiga bakslag såsom fel, mättnad av resurser och funktionella komplikationer.
Du bör alltid notera antalet läs- och skrivoperationer till databasen, det vill säga en översikt över klustrets aktiviteter. Genom att känna till antalet operationer som genereras för förfrågningarna kommer du att kunna beräkna belastningen som databasen förväntas hantera. Belastningen kan sedan hanteras antingen genom att skala upp din databas eller skala ut; beroende på vilken typ av resurser du har. Detta gör att du enkelt kan mäta kvotförhållandet i vilket förfrågningarna ackumuleras till den takt med vilken de behandlas. Dessutom kan du optimera dina frågor på lämpligt sätt för att förbättra prestandan.
För att kontrollera antalet läs- och skrivoperationer, kör det här kommandot db.serverStatus(), navigera sedan till locks.global-objektet, värdet för egenskapen r representerar antalet läsbegäranden och w antalet skrivningar.
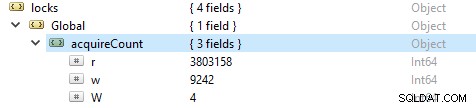
Oftare är läsoperationerna fler än skrivoperationerna. Aktiva klientmått rapporteras under globalLock.
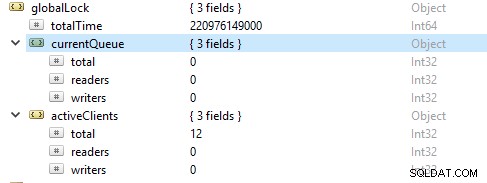
Mättnad och begränsning av resurser
Ibland kan databasen misslyckas med att hålla jämna steg med skriv- och läshastigheten, vilket framställs av ett ökande antal förfrågningar i kö. I det här fallet måste du skala upp din databas genom att tillhandahålla fler skärvor för att MongoDB ska kunna hantera förfrågningarna tillräckligt snabbt.
Tillskjutande bakslag
MongoDB loggfiler ger alltid en allmän översikt över påstå undantag som returneras. Detta resultat ger dig en ledtråd om möjliga orsaker till fel. Om du kör kommandot db.serverStatus() inkluderar några av de felvarningar som du kommer att notera:

- Vanliga påståenden:dessa är ett resultat av ett driftsfel. Till exempel i ett schema om ett strängvärde tillhandahålls i ett heltalsfält, vilket resulterar i att BSON-dokumentet misslyckas.
- Varning hävdar:dessa är ofta varningar om vissa frågor men har inte någon större inverkan på dess funktion. Till exempel när du uppgraderar din MongoDB kan du bli varnad med föråldrade funktioner.
- Meddelande hävdar:de är ett resultat av interna serverundantag såsom långsamt nätverk eller om servern inte är aktiv.
- Användarpåståenden:liksom vanliga påståenden uppstår dessa fel när ett kommando körs men de returneras ofta till klienten. Till exempel om det finns dubbletter av nycklar, otillräckligt diskutrymme eller ingen åtkomst att skriva in i databasen. Du kommer att välja att kontrollera din ansökan för att åtgärda dessa fel.