Vad är indexering?
Indexering är ett viktigt begrepp i databasvärlden. Den största fördelen med att skapa index på alla fält är snabbare tillgång till data. Det optimerar processen för databassökning och åtkomst. Tänk på det här exemplet för att förstå detta.
När en användare frågar efter en specifik rad från databasen, vad gör DB-systemet? Det kommer att börja från första raden och kontrollera om det är den raden som användaren vill ha? Om ja, returnera den raden, annars fortsätter du att söka efter raden till slutet.
I allmänhet, när du definierar ett index på ett visst fält, kommer DB-systemet att skapa en ordnad lista med det fältets värde och lagra det i en annan tabell. Varje post i denna tabell kommer att peka på motsvarande värden i den ursprungliga tabellen. Så när användaren försöker söka efter valfri rad, kommer den först att söka efter värdet i indextabellen med hjälp av binär sökalgoritm och returnera motsvarande värde från den ursprungliga tabellen. Denna process kommer att ta kortare tid eftersom vi använder binär sökning istället för linjär sökning.
I den här artikeln kommer vi att fokusera på MongoDB-indexering och förstå hur man skapar och använder index i MongoDB.
Hur skapar man ett index i MongoDB Collection?
För att skapa index med Mongo-skal, kan du använda denna syntax:
db.collection.createIndex( <key and index type specification>, <options> )Exempel:
För att skapa index på namnfält i myColl-samlingen:
db.myColl.createIndex( { name: -1 } )Typer av MongoDB-index
-
Standard _id-index
Detta är standardindexet som kommer att skapas av MongoDB när du skapar en ny samling. Om du inte anger något värde för det här fältet kommer _id att vara primärnyckel som standard för din samling så att en användare inte kan infoga två dokument med samma _id-fältvärden. Du kan inte ta bort detta index från _id-fältet.
-
Single Field Index
Du kan använda den här indextypen när du vill skapa ett nytt index på något annat fält än _id-fältet.
Exempel:
db.myColl.createIndex( { name: 1 } )Detta kommer att skapa ett stigande nyckelindex på namnfältet i myColl-samlingen
-
Sammansatt index
Du kan också skapa ett index på flera fält med hjälp av sammansatta index. För detta index är ordningen på fälten där de är definierade i indexet avgörande. Tänk på det här exemplet:
db.myColl.createIndex({ name: 1, score: -1 })Detta index kommer först att sortera samlingen efter namn i stigande ordning och sedan för varje namnvärde, den kommer att sortera efter poängvärden i fallande ordning.
-
Multikey Index
Detta index kan användas för att indexera matrisdata. Om något fält i en samling har en array som värde kan du använda detta index som kommer att skapa separata indexposter för varje element i arrayen. Om det indexerade fältet är en array kommer MongoDB automatiskt att skapa Multikey-index på det.
Tänk på det här exemplet:
{ ‘userid’: 1, ‘name’: ‘mongo’, ‘addr’: [ {zip: 12345, ...}, {zip: 34567, ...} ] }Du kan skapa ett Multikey-index på addr-fältet genom att utfärda detta kommando i Mongo-skalet.
db.myColl.createIndex({ addr.zip: 1 }) -
Geospatialt index
Anta att du har lagrat några koordinater i MongoDB-samlingen. För att skapa index på denna typ av fält (som har geospatiala data), kan du använda ett geospatialt index. MongoDB stöder två typer av geospatiala index.
-
2d Index:Du kan använda detta index för data som lagras som punkter på 2D-planet.
db.collection.createIndex( { <location field> : "2d" } ) -
2dsphere Index:Använd detta index när dina data lagras som GeoJson-format eller koordinatpar (longitud, latitud)
db.collection.createIndex( { <location field> : "2dsphere" } ) -
-
Textindex
För att stödja frågor som inkluderar sökning efter viss text i samlingen kan du använda Textindex.
Exempel:
db.myColl.createIndex( { address: "text" } ) -
Hashat index
MongoDB stöder hash-baserad sharding. Hashed index beräknar hash för värdena i det indexerade fältet. Hashed index stöder sharding med hashade shardade nycklar. Hashed skärning använder detta index som skärvnyckel för att partitionera data över ditt kluster.
Exempel:
db.myColl.createIndex( { _id: "hashed" } )
-
Unikt index
Den här egenskapen säkerställer att det inte finns några dubbletter av värden i det indexerade fältet. Om några dubbletter hittas när indexet skapas, kommer det att kassera dessa poster.
-
Gles index
Den här egenskapen säkerställer att alla frågor söker i dokument med indexerat fält. Om något dokument inte har ett indexerat fält, kommer det att kasseras från resultatuppsättningen.
-
TTL-index
Detta index används för att automatiskt ta bort dokument från en samling efter ett visst tidsintervall (TTL) . Detta är idealiskt för att ta bort dokument från händelseloggar eller användarsessioner.
Prestandaanalys
Överväg en samling av studentpoäng. Den har exakt 3 000 000 dokument. Vi har inte skapat några index i den här samlingen. Se den här bilden nedan för att förstå schemat.
 Exempeldokument i partitursamling
Exempeldokument i partitursamling Tänk nu på den här frågan utan några index:
db.scores.find({ student: 585534 }).explain("executionStats")Den här frågan tar 1155ms att köra. Här är utgången. Sök efter executionTimeMillis-fältet för resultatet.
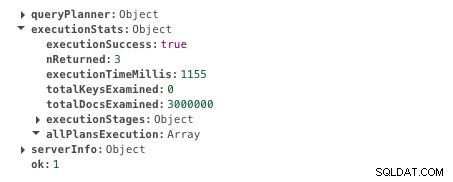 Körtid utan indexering
Körtid utan indexering Låt oss nu skapa index på studentfält. Kör den här frågan för att skapa indexet.
db.scores.createIndex({ student: 1 })Nu tar samma fråga 0ms.
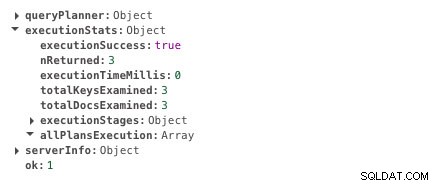 Körtid med indexering
Körtid med indexering Du kan tydligt se skillnaden i exekveringstid. Det är nästan omedelbart. Det är kraften med indexering.
Slutsats
En uppenbar takeaway är:Skapa index. Baserat på dina frågor kan du definiera olika typer av index på dina samlingar. Om du inte skapar index kommer varje fråga att skanna hela samlingarna vilket tar mycket tid vilket gör din applikation väldigt långsam och den använder massor av resurser på din server. Å andra sidan, skapa inte för många index heller eftersom att skapa onödiga index kommer att orsaka extra tidskostnader för all infogning, radering och uppdatering. När du utför någon av dessa operationer på ett indexerat fält måste du också utföra samma operation på indexträdet, vilket tar tid. Index lagras i RAM så att skapa irrelevanta index kan äta upp ditt RAM-utrymme och sakta ner din server.