Få en överblick över de tillgängliga mekanismerna för att säkerhetskopiera data lagrad i Apache HBase, och hur man återställer dessa data i händelse av olika dataåterställnings-/failover-scenarier
Med ökad användning och integrering av HBase i kritiska affärssystem behöver många företag skydda denna viktiga affärstillgång genom att bygga ut robusta strategier för säkerhetskopiering och katastrofåterställning (BDR) för sina HBase-kluster. Hur skrämmande det än kan låta att snabbt och enkelt säkerhetskopiera och återställa potentiellt petabyte data, HBase och Apache Hadoop-ekosystemet tillhandahåller många inbyggda mekanismer för att åstadkomma just detta.
I det här inlägget får du en översikt över de tillgängliga mekanismerna för att säkerhetskopiera data som lagras i HBase, och hur du återställer den datan i händelse av olika dataåterställning/failover-scenarier. Efter att ha läst det här inlägget bör du kunna fatta ett välgrundat beslut om vilken BDR-strategi som är bäst för dina affärsbehov. Du bör också förstå fördelarna, nackdelarna och prestandakonsekvenserna av varje mekanism. (Uppgifterna häri gäller CDH 4.3.0/HBase 0.94.6 och senare.)
Obs:När detta skrivs erbjuder Cloudera Enterprise 4 produktionsklar säkerhetskopiering och återställningsfunktion för HDFS och Hive Metastore via Cloudera BDR 1.0 som en individuellt licensierad funktion. HBase ingår inte i den GA-versionen; därför krävs de olika mekanismerna som beskrivs i den här bloggen. (Cloudera Enterprise 5, för närvarande i betaversion, erbjuder HBase ögonblicksbildhantering via Cloudera BDR.)
Säkerhetskopiering
HBase är ett loggstrukturerat sammanslagningsträd distribuerat datalager med komplexa interna mekanismer för att säkerställa datanoggrannhet, konsistens, versionshantering och så vidare. Så hur i hela friden kan du få en konsekvent säkerhetskopia av denna data som finns i en kombination av HFiles och Write-Ahead-Logs (WALs) på HDFS och i minnet på dussintals regionservrar?
Låt oss börja med det minst störande, minsta dataavtrycket, minst prestandapåverkande mekanismen och arbeta oss fram till det mest störande verktyget i gaffeltruckstil:
- Ögonblicksbilder
- Replikering
- Exportera
- CopyTable
- HTable API
- Offline säkerhetskopiering av HDFS-data
Följande tabell ger en översikt för att snabbt jämföra dessa metoder, som jag kommer att beskriva i detalj nedan.
| Prestandapåverkan | Dataavtryck | Nedtid | Inkrementella säkerhetskopior | Enkel implementering | Mean Time To Recovery (MTTR) | |
| Ögonblicksbilder | Minimal | liten | Kort (endast vid återställning) | Nej | Lätt | Sekunder |
| replikering | Minimal | Stor | Inga | Inneboende | Medium | Sekunder |
| Exportera | Hög | Stor | Inga | Ja | Lätt | Hög |
| CopyTable | Hög | Stor | Inga | Ja | Lätt | Hög |
| API | Medium | Stor | Inga | Ja | Svårt | upp till dig |
| Manual | N/A | Stor | Lång | Nej | Medium | Hög |
Ögonblicksbilder
Från och med CDH 4.3.0 är HBase-ögonblicksbilder fullt funktionella, funktionsrika och kräver ingen klusteravbrottstid under skapandet. Min kollega Matteo Bertozzi täckte ögonblicksbilder väldigt bra i sitt blogginlägg och efterföljande djupdykning. Här kommer jag bara att ge en översikt på hög nivå.
Ögonblicksbilder fångar helt enkelt ett ögonblick i tiden för ditt bord genom att skapa motsvarande UNIX-hårda länkar till ditt bords lagringsfiler på HDFS (Figur 1). Dessa ögonblicksbilder slutförs inom några sekunder, placerar nästan ingen prestanda över huvudet på klustret och skapar ett mycket litet dataavtryck. Din data dupliceras inte alls utan bara katalogiserad i små metadatafiler, vilket gör att systemet kan rulla tillbaka till det ögonblicket i tiden om du skulle behöva återställa den ögonblicksbilden.
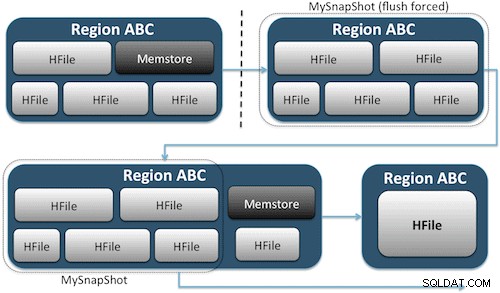
Att skapa en ögonblicksbild av en tabell är lika enkelt som att köra det här kommandot från HBase-skalet:
hbase(main):001:0> snapshot 'myTable', 'MySnapShot'
Efter att ha utfärdat det här kommandot hittar du några små datafiler som finns i /hbase/.snapshot/myTable (CDH4) eller /hbase/.hbase-snapshots (Apache 0.94.6.1) i HDFS som innehåller nödvändig information för att återställa din ögonblicksbild . Återställning är lika enkelt som att utfärda dessa kommandon från skalet:
hbase(main):002:0> disable 'myTable' hbase(main):003:0> restore_snapshot 'MySnapShot' hbase(main):004:0> enable 'myTable'
Obs:Som du kan se kräver återställning av en ögonblicksbild ett kort avbrott eftersom bordet måste vara offline. All data som läggs till/uppdateras efter att den återställda ögonblicksbilden togs kommer att gå förlorad.
Om dina affärskrav är sådana att du måste ha en extern säkerhetskopia av dina data, kan du använda kommandot exportSnapshot för att duplicera en tabells data till ditt lokala HDFS-kluster eller ett fjärranslutet HDFS-kluster som du väljer.
Ögonblicksbilder är en fullständig bild av ditt bord varje gång; ingen inkrementell ögonblicksbildfunktion är tillgänglig för närvarande.
HBase-replikering
HBase-replikering är ett annat verktyg för säkerhetskopiering med mycket låg overhead. (Min kollega Himanshu Vashishtha tar upp replikering i detalj i det här blogginlägget.) Sammanfattningsvis kan replikering definieras på kolumnfamiljnivå, fungerar i bakgrunden och håller alla redigeringar synkroniserade mellan kluster i replikeringskedjan.
Replikering har tre lägen:master->slave, master<->master och cyklisk. Detta tillvägagångssätt ger dig flexibilitet att mata in data från vilket datacenter som helst och säkerställer att det replikeras över alla kopior av tabellen i andra datacenter. I händelse av ett katastrofalt avbrott i ett datacenter kan klientapplikationer omdirigeras till en alternativ plats för data med hjälp av DNS-verktyg.
Replikering är en robust, feltolerant process som ger "eventuell konsistens", vilket innebär att när som helst i tiden kanske de senaste redigeringarna av en tabell inte är tillgängliga i alla repliker av den tabellen, men de kommer garanterat att nå dit så småningom.
Obs:För befintliga tabeller måste du först manuellt kopiera källtabellen till måltabellen via ett av de andra sätten som beskrivs i det här inlägget. Replikering fungerar bara på nya skrivningar/redigeringar efter att du aktiverat det.

(Från Apaches replikeringssida)
Exportera
HBases exportverktyg är ett inbyggt HBase-verktyg som möjliggör enkel export av data från en HBase-tabell till vanliga SequenceFiles i en HDFS-katalog. Det skapar ett MapReduce-jobb som gör en serie HBase API-anrop till ditt kluster, och en i taget hämtar varje rad med data från den angivna tabellen och skriver dessa data till din specificerade HDFS-katalog. Det här verktyget är mer prestandakrävande för ditt kluster eftersom det använder MapReduce och HBase-klient-API, men det är funktionsrikt och stöder filtrering av data efter version eller datumintervall – vilket möjliggör inkrementella säkerhetskopieringar.
Här är ett exempel på kommandot i dess enklaste form:
hbase org.apache.hadoop.hbase.mapreduce.Export
När din tabell har exporterats kan du kopiera de resulterande datafilerna var du vill (som lagring utanför platsen eller utanför kluster). Du kan också ange ett fjärranslutet HDFS-kluster/-katalog som utdataplats för kommandot, och Export kommer att skriva innehållet direkt till fjärrklustret. Observera att detta tillvägagångssätt kommer att införa ett nätverkselement i exportens skrivväg, så du bör bekräfta att din nätverksanslutning till fjärrklustret är pålitlig och snabb.
CopyTable
CopyTable-verktyget täcks väl i Jon Hsiehs blogginlägg, men jag kommer att sammanfatta grunderna här. I likhet med Export skapar CopyTable ett MapReduce-jobb som använder HBase API för att läsa från en källtabell. Den viktigaste skillnaden är att CopyTable skriver sin utdata direkt till en destinationstabell i HBase, som kan vara lokal för ditt källkluster eller på ett fjärrkluster.
Ett exempel på den enklaste formen av kommandot är:
hbase org.apache.hadoop.hbase.mapreduce.CopyTable --new.name=testCopy test
Detta kommando kommer att kopiera innehållet i en tabell med namnet "test" till en tabell i samma kluster som heter "testCopy."
Observera att det finns en betydande prestandaoverhead för CopyTable genom att den använder individuella "puts" för att skriva in data, rad för rad, i destinationstabellen. Om din tabell är mycket stor kan CopyTable få memstore på destinationsregionservrarna att fyllas upp, vilket kräver memstore-tömningar som så småningom kommer att leda till packningar, sophämtning och så vidare.
Dessutom måste du ta hänsyn till prestandakonsekvenserna av att köra MapReduce över HBase. Med stora datamängder kanske det tillvägagångssättet inte är idealiskt.
HTable API (som en anpassad Java-applikation)
Som alltid är fallet med Hadoop kan du alltid skriva din egen anpassade applikation som använder det offentliga API:et och frågar tabellen direkt. Du kan göra detta genom MapReduce-jobb för att utnyttja ramverkets fördelar med distribuerad batchbearbetning, eller genom något annat sätt med din egen design. Det här tillvägagångssättet kräver dock en djup förståelse för Hadoop-utveckling och alla API:er och prestandakonsekvenser av att använda dem i ditt produktionskluster.
Offlinesäkerhetskopiering av rå HDFS-data
Den mest brutala säkerhetskopieringsmekanismen – även den mest störande – involverar det största dataavtrycket. Du kan helt enkelt stänga av ditt HBase-kluster och manuellt kopiera alla data- och katalogstrukturer som finns i /hbase i ditt HDFS-kluster. Eftersom HBase är nere kommer det att säkerställa att all data har bevarats till hFiles i HDFS och du kommer att få en korrekt kopia av data. Inkrementella säkerhetskopior kommer dock att vara nästan omöjliga att få eftersom du inte kommer att kunna se vilka data som har ändrats eller lagts till när du försöker göra framtida säkerhetskopieringar.
Det är också viktigt att notera att återställning av dina data skulle kräva en offline-metareparation eftersom .META. Tabell skulle innehålla potentiellt ogiltig information vid tidpunkten för återställning. Detta tillvägagångssätt kräver också ett snabbt tillförlitligt nätverk för att överföra data utanför platsen och återställa dem senare om det behövs.
Av dessa skäl avråder Cloudera starkt detta tillvägagångssätt för HBase-säkerhetskopior.
Återställning efter katastrof
HBase är designat för att vara ett extremt feltolerant distribuerat system med inbyggd redundans, förutsatt att hårdvaran kommer att misslyckas ofta. Katastrofåterställning i HBase finns vanligtvis i flera former:
- Katastrofalt misslyckande på datacenternivå, som kräver failover till en backupplats
- Behöver återställa en tidigare kopia av dina data på grund av användarfel eller oavsiktlig radering
- Möjligheten att återställa en punkt-i-tid kopia av dina data för revisionsändamål
Som med alla katastrofåterställningsplaner kommer affärskraven att styra hur planen är utformad och hur mycket pengar som ska investeras i den. När du väl har skapat de säkerhetskopior du väljer tar återställningen olika former beroende på vilken typ av återställning som krävs:
- Failover till backup-kluster
- Importera tabell/återställ en ögonblicksbild
- Peka HBase rotkatalog till säkerhetskopieringsplatsen
Om din säkerhetskopieringsstrategi är sådan att du har replikerat dina HBase-data till ett säkerhetskopieringskluster i ett annat datacenter, är det lika enkelt att misslyckas som att peka dina slutanvändarapplikationer till säkerhetskopieringsklustret med DNS-tekniker.
Tänk dock på att om du planerar att tillåta att data skrivs till ditt backupkluster under avbrottsperioden, måste du se till att data kommer tillbaka till det primära klustret när avbrottet är över. Master-to-master eller cyklisk replikering kommer att hantera denna process automatiskt åt dig, men ett master-slave-replikeringsschema kommer att lämna ditt masterkluster ur synk, vilket kräver manuell ingripande efter avbrottet.
Tillsammans med exportfunktionen som beskrivits tidigare, finns det ett motsvarande importverktyg som kan ta data som tidigare säkerhetskopierats av Export och återställa den till en HBase-tabell. Samma prestandaimplikationer som gällde för Export är också i spel med Import. Om ditt säkerhetskopieringsschema involverade att ta ögonblicksbilder, är det lika enkelt att återgå till en tidigare kopia av din data som att återställa den ögonblicksbilden.
Du kan också återhämta dig från en katastrof genom att helt enkelt modifiera egenskapen hbase.root.dir i hbase-site.xml och peka den till en säkerhetskopia av din /hbase-katalog om du hade gjort brute-force offline-kopian av HDFS-datastrukturerna . Detta är dock också det minst önskvärda av återställningsalternativ eftersom det kräver ett längre avbrott medan du kopierar hela datastrukturen tillbaka till ditt produktionskluster, och som tidigare nämnts, .META. kan vara osynkroniserad.
Slutsats
Sammanfattningsvis kräver återställning av data efter någon form av förlust eller avbrott en väl utformad BDR-plan. Jag rekommenderar starkt att du grundligt förstår ditt företags krav på drifttid, datanoggrannhet/tillgänglighet och katastrofåterställning. Beväpnad med detaljerad kunskap om dina affärskrav kan du noggrant välja de verktyg som bäst möter dessa behov.
Att välja verktyg är dock bara början. Du bör köra storskaliga tester av din BDR-strategi för att försäkra dig om att den fungerar i din infrastruktur, uppfyller dina affärsbehov och att dina verksamhetsteam är mycket bekanta med stegen som krävs innan ett avbrott inträffar och du får reda på den hårda vägen din BDR-plan kommer inte att fungera.
Om du vill kommentera eller diskutera det här ämnet ytterligare, använd vårt communityforum för HBase.
Mer läsning:
- Jon Hsiehs presentation av Strata + Hadoop World 2012
- HBase:The Definitive Guide (Lars George)
- HBase In Action (Nick Dimiduk/Amandeep Khurana)