Utforska arkitekturen för Hadoop, som är det mest använda ramverket för att lagra och bearbeta massiva data.
I den här artikeln kommer vi att studera Hadoop Architecture. Artikeln förklarar Hadoop-arkitekturen och komponenterna i Hadoop-arkitekturen som är HDFS, MapReduce och YARN. I artikeln kommer vi att utforska Hadoop-arkitekturen i detalj, tillsammans med Hadoop Architecture-diagrammet.
Låt oss nu börja med Hadoop Architecture.
Hadoop-arkitektur
Målet med att designa Hadoop är att utveckla ett billigt, pålitligt och skalbart ramverk som lagrar och analyserar den växande big data.
Apache Hadoop är ett mjukvaruramverk designat av Apache Software Foundation för att lagra och bearbeta stora datamängder av varierande storlekar och format.
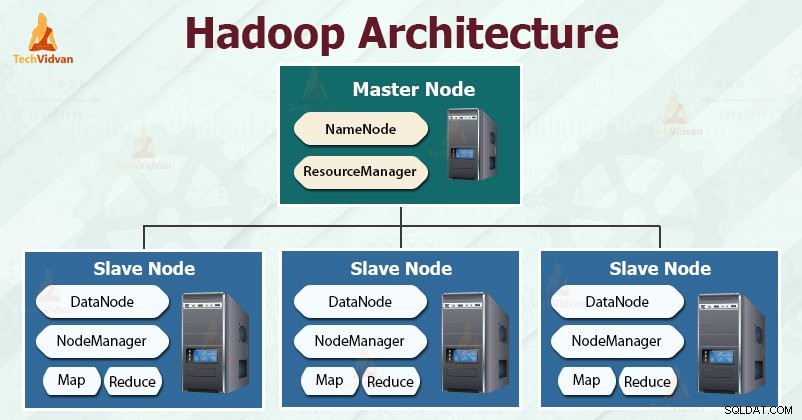
Hadoop följer mästarslaven arkitektur för att effektivt lagra och bearbeta stora mängder data. Masternoderna tilldelar uppgifter till slavnoderna.
Slavnoderna är ansvariga för att lagra den faktiska datan och utföra den faktiska beräkningen/bearbetningen. Masternoderna är ansvariga för att lagra metadata och hantera resurserna över klustret.
Slavnoder lagrar själva affärsdata, medan mastern lagrar metadata.
Hadoop-arkitekturen består av tre lager. De är:
- Lagringslager (HDFS)
- Resurshanteringslager (YARN)
- Bearbetar lager (MapReduce)
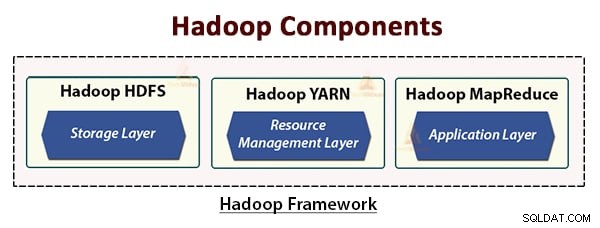
HDFS, YARN och MapReduce är kärnkomponenterna i Hadoop Framework.
Låt oss nu studera dessa tre kärnkomponenter i detalj.
1. HDFS
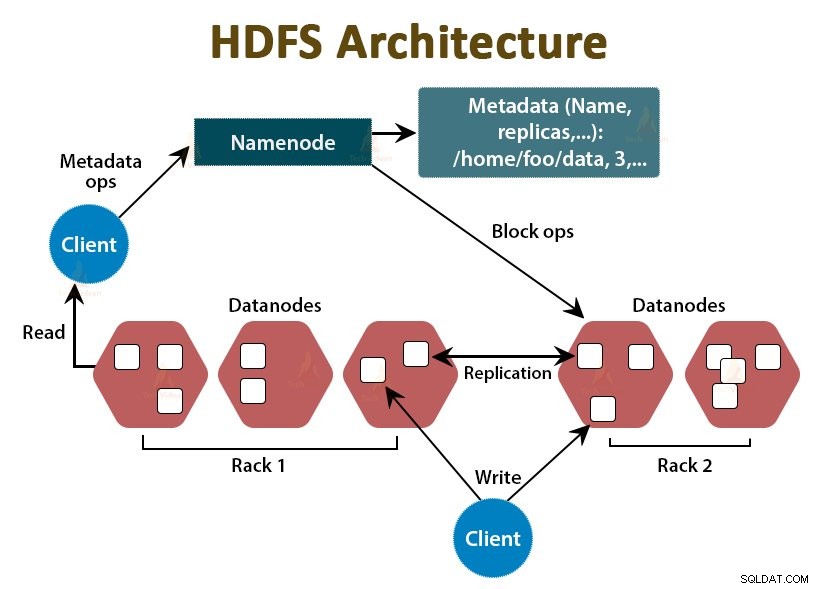
HDFS är Hadoop Distributed File System , som körs på billig råvaruhårdvara. Det är lagringslagret för Hadoop. Filerna i HDFS är uppdelade i blockstorlekar som kallas datablock.
Dessa block lagras sedan på slavnoderna i klustret. Blockstorleken är 128 MB som standard, vilket vi kan konfigurera enligt våra krav.
Precis som Hadoop följer HDFS också master-slave-arkitekturen. Den består av två demoner - NameNode och DataNode. NameNode är masterdemonen som körs på masternoden. DataNoderna är slavdemonen som körs på slavnoderna.
NameNode
NameNode lagrar filsystemets metadata, det vill säga filnamn, information om block av en fil, blockerar platser, behörigheter, etc. Den hanterar datanoderna.
DataNode
DataNodes är slavnoder som lagrar den faktiska affärsdatan. Den betjänar klientens läs-/skrivförfrågningar baserat på NameNode-instruktionerna.
DataNodes lagrar blocken av filerna och NameNode lagrar metadata som blockplatser, behörigheter etc.
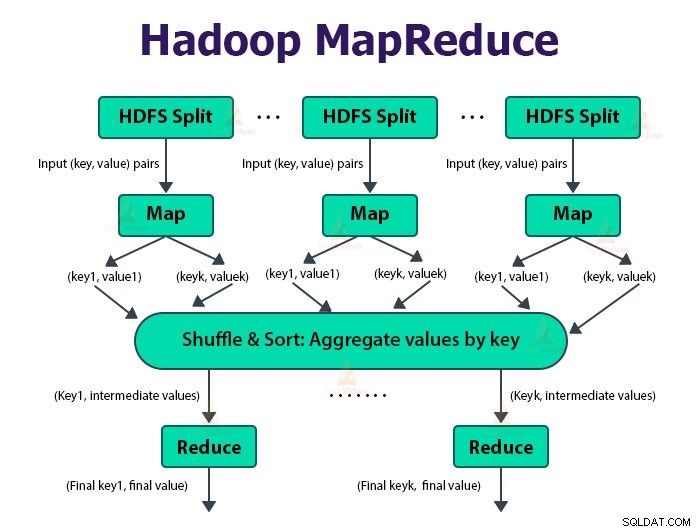
2. MapReduce
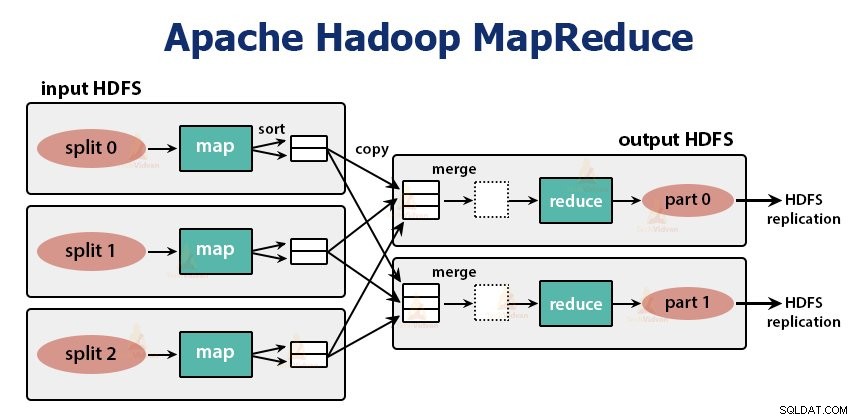
Det är databearbetningsskiktet i Hadoop. Det är ett ramverk för programvara för att skriva applikationer som bearbetar stora mängder data (terabyte till petabyte inom räckvidd) parallellt på klustret av råvaruhårdvara.
MapReduce-ramverket fungerar på
MapReduce-jobbet är den arbetsenhet som klienten vill utföra. MapReduce-jobbet består huvudsakligen av indata, MapReduce-programmet och konfigurationsinformationen. Hadoop kör MapReduce-jobben genom att dela upp dem i två typer av uppgifter som är kartuppgifter och minska uppgifter . Hadoop YARN schemalagda dessa uppgifter och körs på noderna i klustret.
På grund av vissa ogynnsamma förhållanden, om uppgifterna misslyckas, kommer de automatiskt att omplaneras till en annan nod.
Användaren definierar kartfunktionen och reducera-funktionen för att utföra MapReduce-jobbet.
Indata till kartfunktionen och utdata från reduceringsfunktionen är nyckeln, värdeparet.
Funktionen för kartuppgifterna är att ladda, analysera, filtrera och transformera data. Utdata från kartuppgiften är input till reduceringsuppgiften. Reducera-uppgiften utför sedan gruppering och aggregering på utdata från kartuppgiften.
MapReduce-uppgiften görs i två faser-
1. Kartfas
a. RecordReader
Hadoop delar in ingångarna till MapReduce-jobbet i de fasta storleksdelarna som kallas ingångsdelningar eller splittringar. RecordReader omvandlar dessa uppdelningar till poster och analyserar data till poster men den analyserar inte själva posterna. RecordReader tillhandahåller data till mapparfunktionen i nyckel-värdepar.
b. Karta
I kartfasen skapar Hadoop en kartuppgift som kör en användardefinierad funktion som kallas kartfunktion för varje post i ingångsdelningen. Den genererar noll eller flera mellanliggande nyckel-värdepar som kartuppgiftsutdata.
Kartuppgiften skriver sin utdata till den lokala disken. Denna mellanutgång bearbetas sedan av reduceringsuppgifterna som kör en användardefinierad reduceringsfunktion för att producera den slutliga utmatningen. När jobbet är klart rensas kartutdata.
c. Kombinator
Indata till den enskilda reduceringsuppgiften är utdata från alla mappare som utmatas från alla kartuppgifter. Hadoop låter användaren definiera en kombinerarfunktion som körs på kartutdata.
Kombinator grupperar data i kartfasen innan de skickas till Reducer. Den kombinerar utdata från kartfunktionen som sedan skickas som en ingång till reduceringsfunktionen.
d. Partitioner
När det finns flera reducerare partitionerar kartuppgifterna sin utdata, var och en skapar en partition för varje reduceringsuppgift. I varje partition kan det finnas många nycklar och deras tillhörande värden, men posterna för en given nyckel är alla i en enda partition.
Hadoop låter användare styra partitioneringen genom att ange en användardefinierad partitioneringsfunktion. I allmänhet finns det en standardpartitionerare som bokar nycklarna med hjälp av hash-funktionen.
2. Minska fasen:
De olika faserna i reduceringsuppgiften är följande:
a. Sortera och blanda:
Uppgiften Reducer börjar med ett steg för att blanda och sortera. Huvudsyftet med denna fas är att samla ihop motsvarande nycklar. Sortera och blanda fas laddar ner data som skrivs av partitioneraren till noden där Reducer körs.
Den sorterar varje databit i en stor datalista. MapReduce-ramverket utför denna sortering och blandar så att vi enkelt kan iterera över det i reduceringsuppgiften.
Sortera och blanda utförs av ramverket automatiskt. Utvecklaren kan genom komparatorobjektet ha kontroll över hur nycklarna sorteras och grupperas.
b. Minska:
Reducer, som är den användardefinierade reduceringsfunktionen, utförs en gång per nyckelgruppering. Reduceraren filtrerar, aggregerar och kombinerar data på flera olika sätt. När reduceringsuppgiften är klar ger den noll eller fler nyckel-värdepar till OutputFormat. Reduceringsuppgiftens utdata lagras i Hadoop HDFS.
c. OutputFormat
Den tar reduceringsutgången och skriver den till HDFS-filen av RecordWriter. Som standard separerar den nyckel, värde med en tabb och varje post med ett nyradstecken.
3. GARN
YARN står för Yet Another Resource Negotiator . Det är Hadoops resurshanteringslager. Det introducerades i Hadoop 2.
YARN är designat med idén att dela upp funktionerna för jobbschemaläggning och resurshantering i separata demoner. Grundidén är att ha en global ResourceManager och Application Master per ansökan där ansökan kan vara ett enstaka jobb eller DAG av jobb.
YARN består av ResourceManager, NodeManager och ApplicationMaster per applikation.
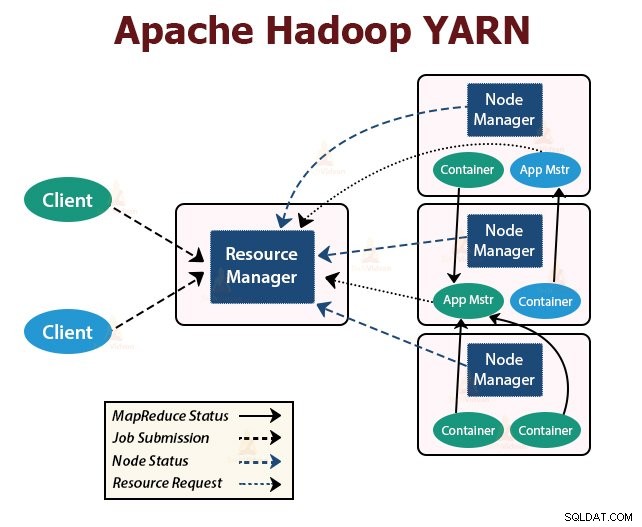
1. ResourceManager
Den meddelar resurser bland alla applikationer i klustret.
Den har två huvudkomponenter som är Scheduler och ApplicationManager.
a. Schemaläggare
- Schemaläggaren allokerar resurser till de olika applikationerna som körs i klustret, med hänsyn till kapacitet, köer etc.
- Det är en ren Schemaläggare. Den övervakar eller spårar inte programmets status.
- Schemaläggaren garanterar inte omstart av de misslyckade uppgifterna som misslyckades antingen på grund av programfel eller maskinvarufel.
- Den utför schemaläggning baserat på resurskraven för applikationerna.
b. Application Manager
- De är ansvariga för att acceptera jobbinlämningarna.
- ApplicationManager förhandlar fram den första behållaren för att köra applikationsspecifik ApplicationMaster.
- De tillhandahåller service för att starta om ApplicationMaster-behållaren vid fel.
- Per-applikation ApplicationMaster ansvarar för att förhandla om behållare från Scheduler. Den spårar och övervakar deras status och framsteg.
2. NodeManager:
NodeManager körs på slavnoderna. Den ansvarar för containrar, övervakar maskinens resursanvändning som är CPU, minne, disk, nätverksanvändning och rapporterar detsamma till ResourceManager eller Scheduler.
3. ApplicationMaster:
ApplicationMaster per applikation är ett ramspecifikt bibliotek. Den ansvarar för att förhandla om resurser från Resurshanteraren. Det fungerar med NodeManager(erna) för att utföra och övervaka uppgifterna.
Sammanfattning
I den här artikeln har vi studerat Hadoop Architecture. Hadoop följer master-slav topologi. Masternoderna tilldelar uppgifter till slavnoderna. Arkitekturen består av tre lager som är HDFS, YARN och MapReduce.
HDFS är det distribuerade filsystemet i Hadoop för att lagra big data. MapReduce är bearbetningsramverket för att bearbeta omfattande data i Hadoop-klustret på ett distribuerat sätt. YARN ansvarar för att hantera resurserna bland applikationer i klustret.
HDFS-demonen NameNode och YARN-demonen ResourceManager körs på huvudnoden i Hadoop-klustret. HDFS-demonen DataNode och YARN NodeManager körs på slavnoderna.
HDFS och MapReduce-ramverket körs på samma uppsättning noder, vilket resulterar i mycket hög sammanlagd bandbredd över klustret.
Fortsätt lära dig!