Din fråga är verkligen oprecis. Vänligen följ @RiggsFolly förslag och läs referenserna om hur man ställer en bra fråga.
Dessutom, som föreslagits av @DuduMarkovitz, bör du börja med att förenkla problemet och rensa dina data. Några resurser för att komma igång:
- Grundläggande handledning för textbearbetning av Matt Deny
- Hantera och bearbeta strängar i R av Gaston Sanchez
När du är nöjd med resultaten kan du fortsätta att identifiera en grupp för varje Var1 post (detta hjälper dig på vägen att utföra ytterligare analys/manipulationer på liknande poster) Detta kan göras på många olika sätt, men enligt @GordonLinoff, en möjlighet är Levenshtein-avståndet.
Obs :för 50 000 bidrag kommer resultatet inte att vara 100 % korrekt eftersom det inte alltid kategorisera termerna i lämplig grupp men detta bör avsevärt minska manuella ansträngningar.
I R kan du göra detta med code>adist()
Använd din exempeldata:
d <- adist(df$Var1)
# add rownames (this will prove useful later on)
rownames(d) <- df$Var1
> d
# [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#125 Hollywood St. 0 1 1 16 15 16 15 15 15 15
#125 Hllywood St. 1 0 2 15 14 15 15 14 14 14
#125 Hollywood St 1 2 0 15 15 15 14 14 15 15
#Target Store 16 15 15 0 2 1 2 10 10 9
#Trget Stre 15 14 15 2 0 3 4 9 10 8
#Target. Store 16 15 15 1 3 0 3 11 11 10
#T argetStore 15 15 14 2 4 3 0 10 11 9
#Walmart 15 14 14 10 9 11 10 0 5 2
#Walmart Inc. 15 14 15 10 10 11 11 5 0 6
#Wal marte 15 14 15 9 8 10 9 2 6 0
För det här lilla urvalet kan du se de 3 distinkta grupperna (klustren med låga Levensthein-avståndsvärden) och kan enkelt tilldela dem manuellt, men för större uppsättningar behöver du troligen en klustringsalgoritm.
Jag har redan hänvisat dig i kommentarerna till en av mina föregående svar
visar hur man gör detta med hclust() och avdelningens metod för minsta varians men jag tror att du här skulle vara bättre att använda andra tekniker (en av mina favoritresurser i ämnet för en snabb översikt över några av de mest använda metoderna i R är denna detaljerat svar
)
Här är ett exempel som använder affinitetsutbredningsklustring:
library(apcluster)
d_ap <- apcluster(negDistMat(r = 1), d)
Du hittar i APResult-objektet d_ap elementen associerade med varje kluster och det optimala antalet kluster, i detta fall:3.
> example@sqldat.com
#[[1]]
#125 Hollywood St. 125 Hllywood St. 125 Hollywood St
# 1 2 3
#
#[[2]]
# Target Store Trget Stre Target. Store T argetStore
# 4 5 6 7
#
#[[3]]
# Walmart Walmart Inc. Wal marte
# 8 9 10
Du kan också se en visuell representation:
> heatmap(d_ap, margins = c(10, 10))
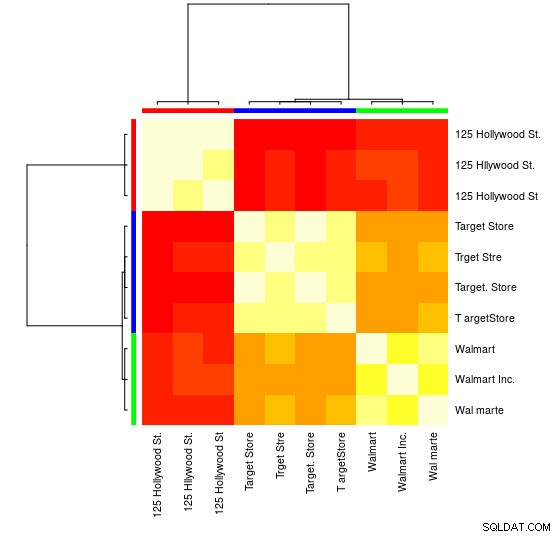
Sedan kan du utföra ytterligare manipulationer för varje grupp. Som ett exempel använder jag här hunspell för att slå upp varje separat ord från Var1 i en en_US ordbok för stavfel och försök hitta inom varje grupp , vilket id har inga stavfel (potential_id )
library(dplyr)
library(tidyr)
library(hunspell)
tibble(Var1 = sapply(example@sqldat.com, names)) %>%
unnest(.id = "group") %>%
group_by(group) %>%
mutate(id = row_number()) %>%
separate_rows(Var1) %>%
mutate(check = hunspell_check(Var1)) %>%
group_by(id, add = TRUE) %>%
summarise(checked_vars = toString(Var1),
result_per_word = toString(check),
potential_id = all(check))
Vilket ger:
#Source: local data frame [10 x 5]
#Groups: group [?]
#
# group id checked_vars result_per_word potential_id
# <int> <int> <chr> <chr> <lgl>
#1 1 1 125, Hollywood, St. TRUE, TRUE, TRUE TRUE
#2 1 2 125, Hllywood, St. TRUE, FALSE, TRUE FALSE
#3 1 3 125, Hollywood, St TRUE, TRUE, TRUE TRUE
#4 2 1 Target, Store TRUE, TRUE TRUE
#5 2 2 Trget, Stre FALSE, FALSE FALSE
#6 2 3 Target., Store TRUE, TRUE TRUE
#7 2 4 T, argetStore TRUE, FALSE FALSE
#8 3 1 Walmart FALSE FALSE
#9 3 2 Walmart, Inc. FALSE, TRUE FALSE
#10 3 3 Wal, marte FALSE, FALSE FALSE
Obs :Här eftersom vi inte har utfört någon textbearbetning är resultaten inte särskilt avgörande, men du fattar.
Data
df <- tibble::tribble(
~Var1,
"125 Hollywood St.",
"125 Hllywood St.",
"125 Hollywood St",
"Target Store",
"Trget Stre",
"Target. Store",
"T argetStore",
"Walmart",
"Walmart Inc.",
"Wal marte"
)