När jag arbetade med personnamn och gjorde suddiga sökningar på dem, var det som fungerade för mig att skapa en andra tabell med ord. Skapa också en tredje tabell som är en skärningstabell för många till många-relationen mellan tabellen som innehåller texten och ordtabellen. När en rad läggs till i texttabellen delar du upp texten i ord och fyller i skärningstabellen på lämpligt sätt, och lägger till nya ord i ordtabellen vid behov. När den här strukturen är på plats kan du göra uppslagningar lite snabbare, eftersom du bara behöver utföra din damlev-funktion över tabellen med unika ord. En enkel sammanfogning ger dig texten som innehåller de matchande orden. 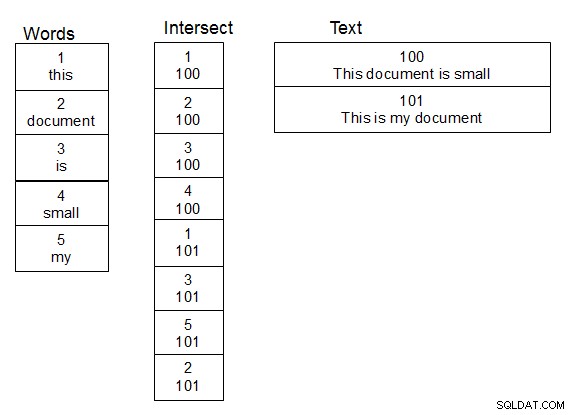
En fråga för en enstaka ordmatchning skulle se ut ungefär så här:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
och två ord skulle se ut så här (utanför mitt huvud, så det kanske inte är helt korrekt):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
Fördelarna här, till priset av lite databasutrymme, är att du bara behöver applicera den tidskostsamma damlev-funktionen på de unika orden, som förmodligen bara kommer att räknas till 10-talet av tusentals oavsett storleken på din texttabell. Det här spelar roll, eftersom damlev UDF inte kommer att använda index - den kommer att skanna hela tabellen som den används på för att beräkna ett värde för varje rad. Att skanna bara de unika orden borde gå mycket snabbare. Den andra fördelen är att damlev tillämpas på ordnivå, vilket verkar vara det du efterfrågar. En annan fördel är att du kan utöka frågan för att stödja sökning på flera ord, och kan rangordna resultaten genom att gruppera de matchande korsade raderna på TextId och rangordna efter antalet träffar.