Att distribuera ett databaskluster är inte raketvetenskap - det finns många instruktioner om hur man gör det. Men hur vet du att det du just har installerat är produktionsklart? Manuella distributioner kan också vara tråkiga och repetitiva. Beroende på antalet noder i klustret kan distributionsstegen vara tidskrävande och felbenägna. Konfigurationshanteringsverktyg som Puppet, Chef och Ansible är populära för att distribuera infrastruktur, men för stateful databaskluster måste du utföra betydande skript för att hantera distributionen av hela databasen HA-stacken. Dessutom måste den valda mallen/modulen/kokboken/rollen testas noggrant innan du kan lita på den som en del av din infrastrukturautomatisering. Versionsändringar kräver att skripten uppdateras och testas igen.
Den goda nyheten är att ClusterControl automatiserar distributioner av hela stacken - och det är gratis! Vi har distribuerat tusentals produktionskluster och vidtar ett antal försiktighetsåtgärder för att säkerställa att de är produktionsklara. Olika topologier stöds, från master-slave replikering till Galera, NDB och InnoDB-kluster, med olika databasproxyer ovanpå.
En hög tillgänglighetsstack, distribuerad genom ClusterControl, består av tre lager:
- Databaslager (t.ex. Galera Cluster)
- Omvänt proxylager (t.ex. HAProxy eller ProxySQL)
- Keepalived lager, som med användning av virtuell IP säkerställer hög tillgänglighet för proxylagret
I den här bloggen kommer vi att visa dig hur du distribuerar ett Galera Cluster i produktionsklass komplett med lastbalanserare för hög tillgänglighetsinstallation. Den kompletta installationen består av 6 värdar:
- 1 värd - ClusterControl (distribution, övervakning, hanteringsserver)
- 3 värdar - MySQL Galera Cluster
- 2 värdar – omvända proxyservrar fungerar som lastbalanserare framför klustret.
Följande diagram illustrerar vårt slutresultat när distributionen är klar:
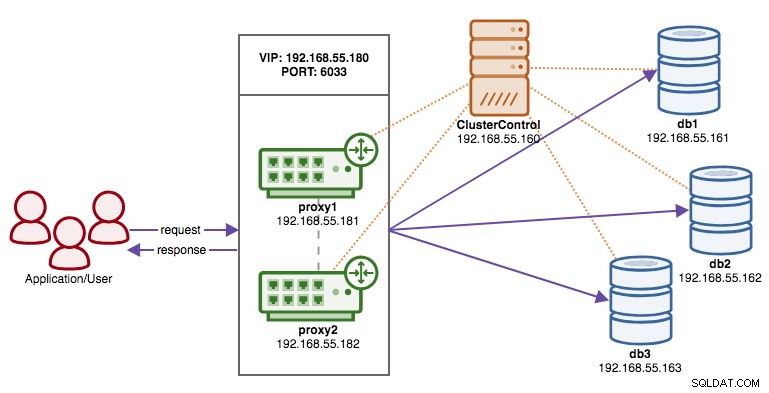
Förutsättningar
ClusterControl måste finnas på en oberoende nod som inte är en del av klustret. Ladda ner ClusterControl, så genererar sidan en unik licens för dig och visar stegen för att installera ClusterControl:
$ wget -O install-cc https://severalnines.com/scripts/install-cc
$ chmod +x install-cc
$ ./install-cc # as root or sudo userFölj instruktionerna där du kommer att guidas med inställning av MySQL-server, MySQL root-lösenord på ClusterControl-noden, cmon-lösenord för ClusterControl-användning och så vidare. Du bör få följande rad när installationen är klar:
Determining network interfaces. This may take a couple of minutes. Do NOT press any key.
Public/external IP => https://{public_IP}/clustercontrol
Installation successful. If you want to uninstall ClusterControl then run install-cc --uninstall.Sedan, på ClusterControl-servern, generera en SSH-nyckel som vi kommer att använda för att ställa in den lösenordslösa SSH senare. Du kan använda vilken användare som helst i systemet men den måste ha förmågan att utföra superanvändaroperationer (sudoer). I det här exemplet valde vi root-användaren:
$ whoami
root
$ ssh-keygen -t rsaStäll in lösenordslös SSH till alla noder som du vill övervaka/hantera via ClusterControl. I det här fallet kommer vi att ställa in detta på alla noder i stacken (inklusive själva ClusterControl-noden). På ClusterControl-noden, kör följande kommandon och ange root-lösenordet när du uppmanas:
$ ssh-copy-id example@sqldat.com # clustercontrol
$ ssh-copy-id example@sqldat.com # galera1
$ ssh-copy-id example@sqldat.com # galera2
$ ssh-copy-id example@sqldat.com # galera3
$ ssh-copy-id example@sqldat.com # proxy1
$ ssh-copy-id example@sqldat.com # proxy2Du kan sedan verifiera om det fungerar genom att köra följande kommando på ClusterControl-noden:
$ ssh example@sqldat.com "ls /root"Se till att du kan se resultatet av kommandot ovan utan att behöva ange lösenord.
Distribuera klustret
ClusterControl stöder alla leverantörer för Galera Cluster (Codership, Percona och MariaDB). Det finns några mindre skillnader som kan påverka ditt beslut om att välja leverantör. Om du vill lära dig mer om skillnaderna mellan dem, kolla in vårt tidigare blogginlägg - Galera Cluster Comparison - Codership vs Percona vs MariaDB.
För produktionsinstallation är ett Galera-kluster med tre noder det minsta du bör ha. Du kan alltid skala ut det senare när klustret har distribuerats, manuellt eller via ClusterControl. Vi öppnar vårt ClusterControl-gränssnitt på https://192.168.55.160/clustercontrol och skapar den första adminanvändaren. Gå sedan till toppmenyn och klicka på Deploy -> MySQL Galera och du kommer att presenteras med följande dialogruta:
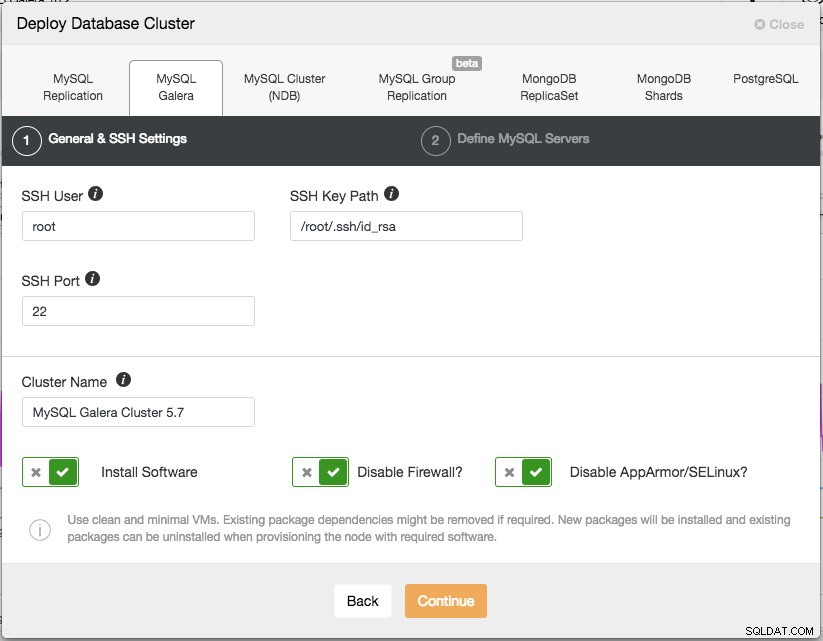
Det finns två steg, det första är "Allmänna &SSH-inställningar". Här måste vi konfigurera SSH-användaren som ClusterControl ska använda för att ansluta till databasnoderna, tillsammans med sökvägen till SSH-nyckeln (som genereras under Prerequisite-avsnittet) samt SSH-porten för databasnoderna. ClusterControl förutsätter att alla databasnoder är konfigurerade med samma SSH-användare, nyckel och port. Ge sedan klustret ett namn, i det här fallet kommer vi att använda "MySQL Galera Cluster 5.7". Detta värde kan ändras senare. Välj sedan alternativen för att instruera ClusterControl att installera den nödvändiga programvaran, inaktivera brandväggen och även inaktivera säkerhetsförbättringsmodulen på den specifika Linux-distributionen. Alla dessa rekommenderas att aktiveras för att maximera potentialen för framgångsrik implementering.
Klicka på Fortsätt så visas följande dialogruta:
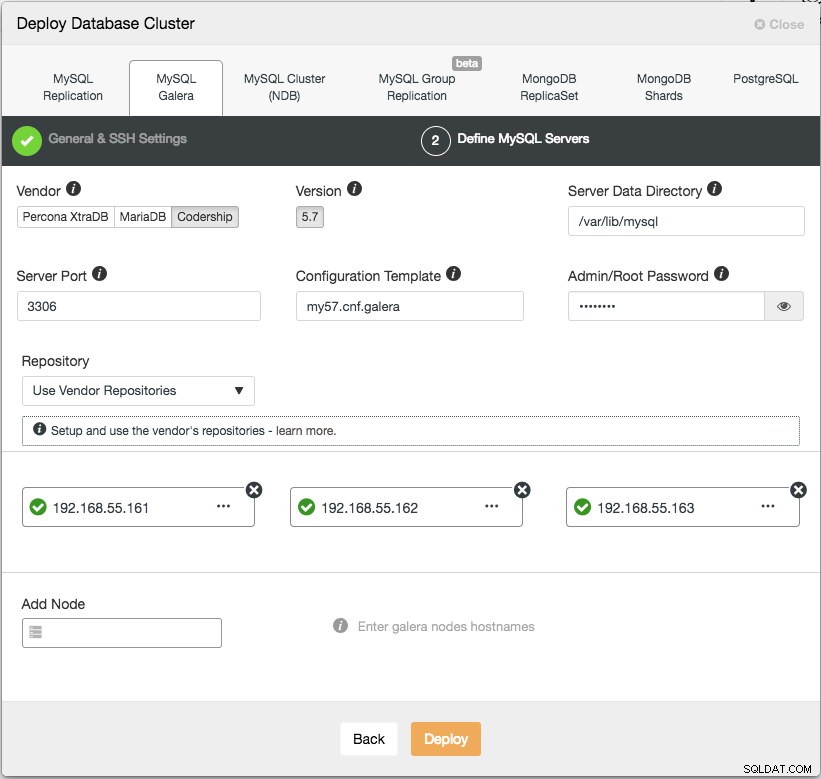
I nästa steg måste vi konfigurera databasservrarna - leverantör, version, datadir, port, etc - som är ganska självförklarande. "Configuration Template" är mallens filnamn under /usr/share/cmon/templates för ClusterControl-noden. "Repository" är hur ClusterControl ska konfigurera förvaret på databasnoden. Som standard kommer den att använda leverantörens arkiv och installera den senaste versionen som tillhandahålls av arkivet. Men i vissa fall kan användaren ha ett redan existerande arkiv speglat från det ursprungliga arkivet på grund av säkerhetspolicybegränsningar. Trots det stöder ClusterControl de flesta av dem, som beskrivs i användarhandboken, under Repository.
Lägg slutligen till IP-adressen eller värdnamnet (måste vara ett giltigt FQDN) för databasnoderna. Du kommer att se en grön bockikon till vänster om noden, vilket indikerar att ClusterControl kunde ansluta till noden via lösenordslös SSH. Nu är du bra att gå. Klicka på Distribuera för att starta distributionen. Detta kan ta 15 till 20 minuter att slutföra. Du kan övervaka distributionsförloppet under Aktivitet (översta menyn) -> Jobb -> Skapa kluster :
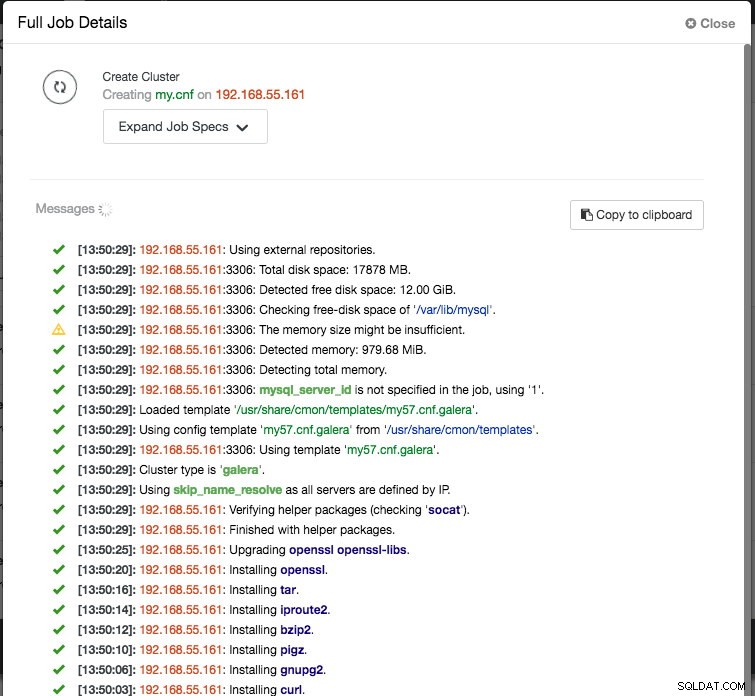
När implementeringen är klar, vid denna tidpunkt, kan vår arkitektur illustreras enligt nedan:
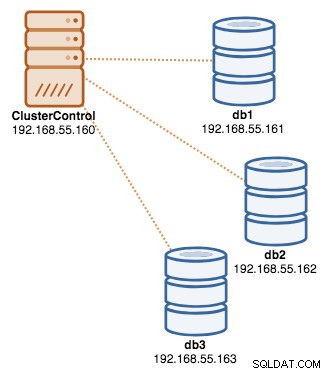
Isättning av lastbalanserare
I Galera Cluster är alla noder lika - varje nod har samma roll och samma datauppsättning. Därför finns det ingen failover inom klustret om en nod misslyckas. Endast applikationssidan kräver failover, för att hoppa över de inoperativa noderna medan klustret är partitionerat. Därför rekommenderas det starkt att placera lastbalanserare ovanpå ett Galera-kluster för att:
- Förena de flera databasslutpunkterna till en enda slutpunkt (lastbalanseringsvärd eller virtuell IP-adress som slutpunkt).
- Balansera databasanslutningarna mellan backend-databasservrarna.
- Utför hälsokontroller och vidarebefordra endast databasanslutningarna till friska noder.
- Omdirigera/skriva om/blockera stötande (dåligt skrivna) frågor innan de träffar databasservrarna.
Det finns tre huvudval av omvända proxyservrar för Galera Cluster - HAProxy, MariaDB MaxScale eller ProxySQL - alla kan installeras och konfigureras automatiskt av ClusterControl. I den här implementeringen valde vi ProxySQL eftersom den kontrollerar allt ovan plus att den förstår MySQL-protokollet för backend-servrarna.
I den här arkitekturen vill vi använda två ProxySQL-servrar för att eliminera eventuella single-point-of-failure (SPOF) till databasnivån, som kommer att knytas samman med hjälp av en flytande virtuell IP-adress. Vi kommer att förklara detta i nästa avsnitt. En nod kommer att fungera som aktiv proxy och den andra som hot-standby. Vilken nod som helst som håller den virtuella IP-adressen vid en given tidpunkt är den aktiva noden.
För att distribuera den första ProxySQL-servern, gå helt enkelt till klusteråtgärdsmenyn (höger sida av sammanfattningsfältet) och klicka på Lägg till lastbalanserare -> ProxySQL -> Deploy ProxySQL och du kommer att se följande:
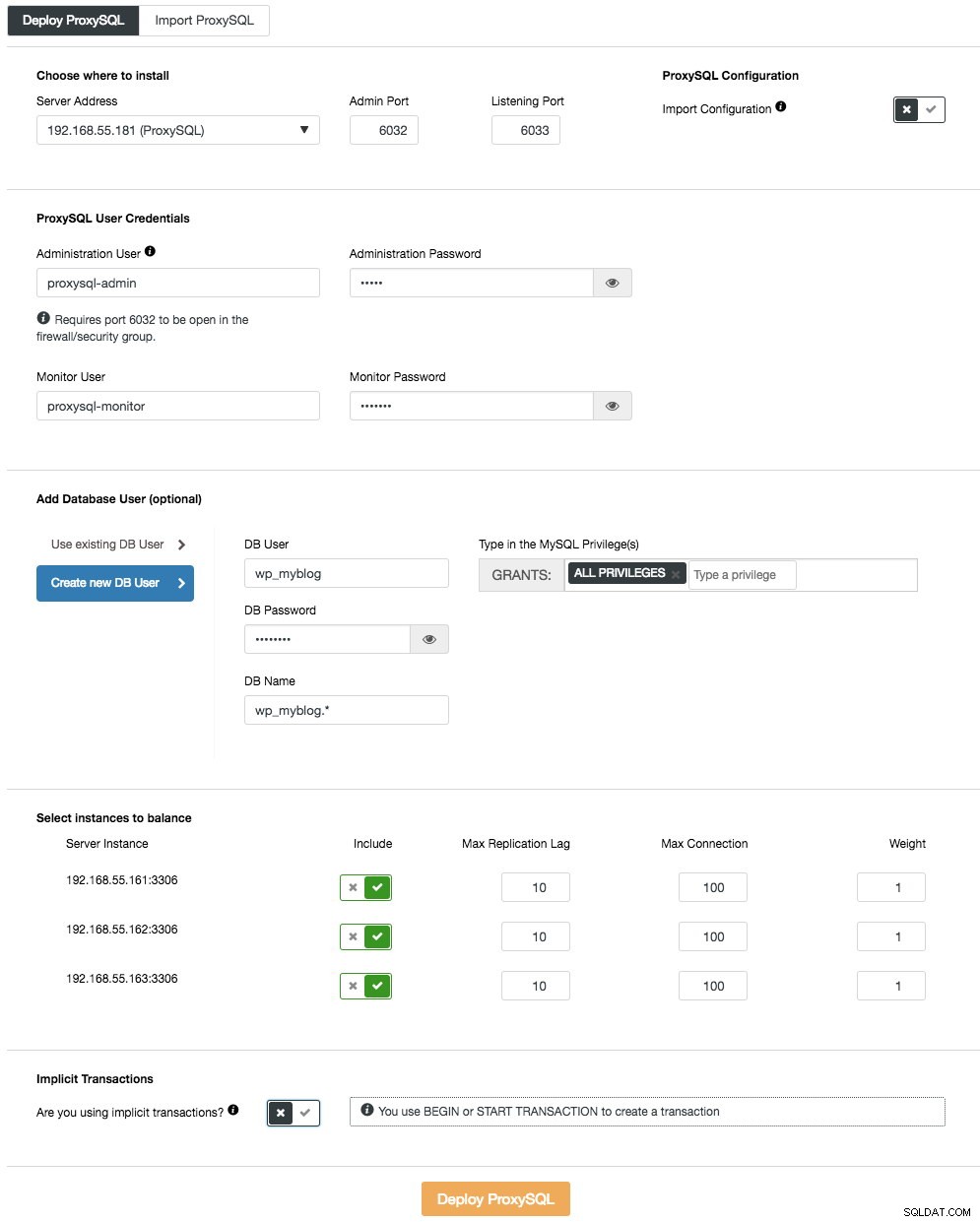
Återigen, de flesta av fälten är självförklarande. I avsnittet "Databasanvändare" fungerar ProxySQL som en gateway genom vilken din applikation ansluter till databasen. Applikationen autentiserar mot ProxySQL, därför måste du lägga till alla användare från alla backend MySQL-noder, tillsammans med deras lösenord, till ProxySQL. Från ClusterControl kan du antingen skapa en ny användare som ska användas av applikationen - du kan bestämma dess namn, lösenord, åtkomst till vilka databaser som beviljas och vilka MySQL-privilegier den användaren ska ha. En sådan användare kommer att skapas på både MySQL- och ProxySQL-sidan. Det andra alternativet, mer lämpligt för befintliga infrastrukturer, är att använda befintliga databasanvändare. Du måste skicka användarnamn och lösenord, och en sådan användare skapas endast på ProxySQL.
Det sista avsnittet, "Implicit Transaction", ClusterControl kommer att konfigurera ProxySQL för att skicka all trafik till mastern om vi startade transaktionen med SET autocommit=0. Annars, om du använder BEGIN eller START TRANSACTION för att skapa en transaktion, kommer ClusterControl att konfigurera läs/skrivdelning i frågereglerna. Detta för att säkerställa att ProxySQL kommer att hantera transaktioner korrekt. Om du inte har någon aning om hur din ansökan gör detta kan du välja det senare.
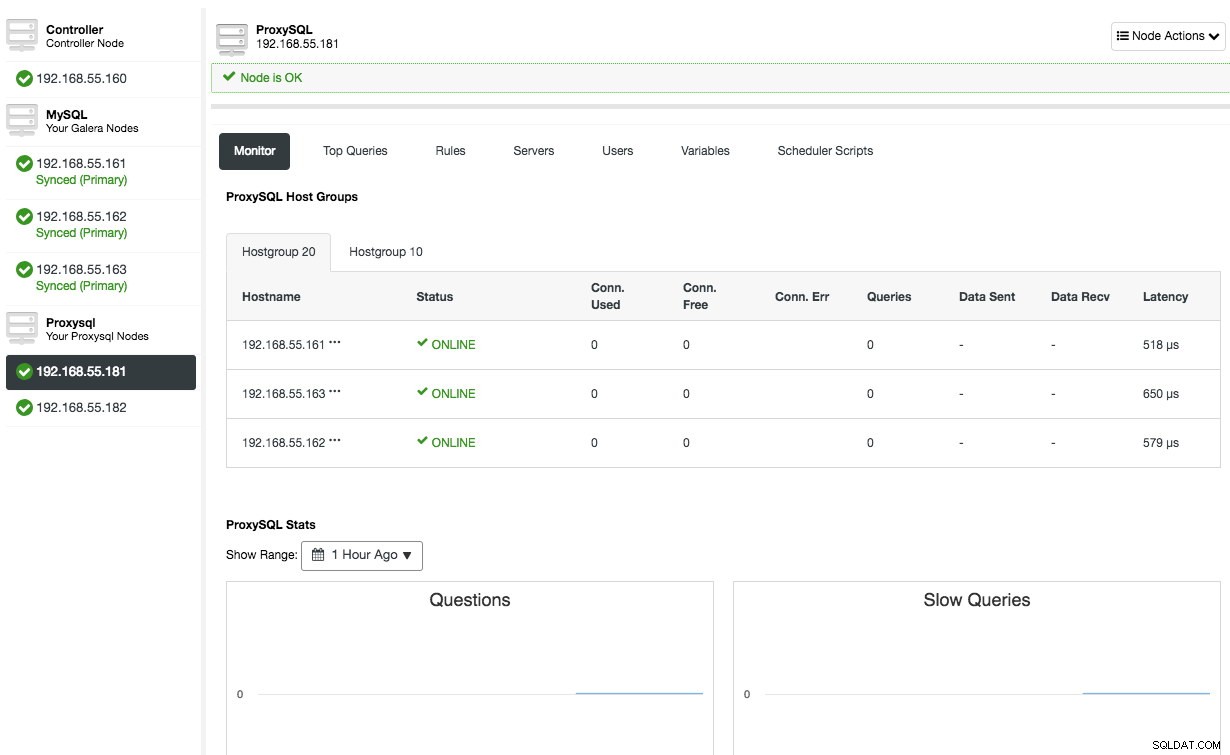
Upprepa samma konfiguration för den andra ProxySQL-noden, förutom värdet "Server Address" som är 192.168.55.182. När det är klart kommer båda noderna att listas under fliken "Noder" -> ProxySQL där du kan övervaka och hantera dem direkt från användargränssnittet:
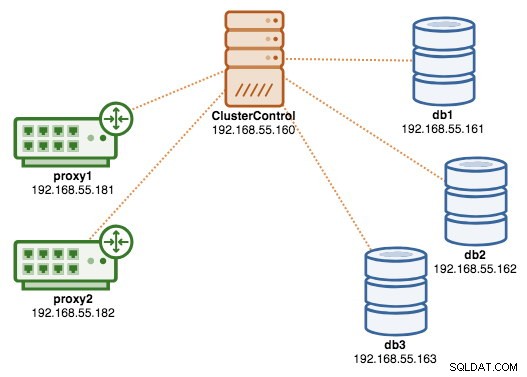
Vid det här laget ser vår arkitektur nu ut så här:
Om du vill lära dig mer om ProxySQL, kolla in den här handledningen - Databasbelastningsbalansering för MySQL och MariaDB med ProxySQL - Handledning.
Distribuera den virtuella IP-adressen
Den sista delen är den virtuella IP-adressen. Utan det skulle våra belastningsutjämnare (omvända proxyservrar) vara den svaga länken eftersom de skulle vara en enda felpunkt - om inte applikationen har förmågan att automatiskt omdirigera misslyckade databasanslutningar till en annan lastbalanserare. Ändå är det bra att förena dem både med virtuell IP-adress och förenkla anslutningsändpunkten till databaslagret.
Från ClusterControl UI -> Add Load Balancer -> Keepalived -> Implementera Keepalived och välj de två ProxySQL-värdarna som vi har distribuerat:
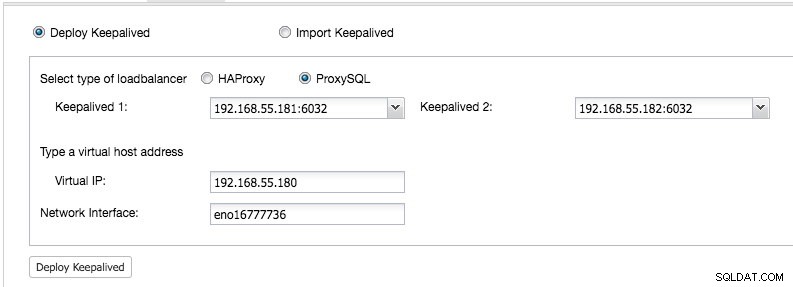
Ange också den virtuella IP-adressen och nätverksgränssnittet för att binda IP-adressen. Nätverksgränssnittet måste finnas på båda ProxySQL-noderna. När du har distribuerat det bör du se följande gröna bockar i klustrets sammanfattningsfält:

Vid det här laget kan vår arkitektur illustreras enligt nedan:
Vårt databaskluster är nu redo för produktionsanvändning. Du kan importera din befintliga databas till den eller skapa en ny ny databas. Du kan använda funktionen Schema and Users Management om testlicensen inte har löpt ut.
För att förstå hur ClusterControl konfigurerar Keepalived, kolla in det här blogginlägget, How ClusterControl Configures Virtual IP and What to Expect Under Failover.
Ansluter till databasklustret
Ur applikations- och klientsynpunkt måste de ansluta till 192.168.55.180 på port 6033 som är den virtuella IP-adressen som flyter ovanpå lastbalanserarna. Till exempel kommer Wordpress-databaskonfigurationen att vara ungefär så här:
/** The name of the database for WordPress */
define( 'DB_NAME', 'wp_myblog' );
/** MySQL database username */
define( 'DB_USER', 'wp_myblog' );
/** MySQL database password */
define( 'DB_PASSWORD', 'mysecr3t' );
/** MySQL hostname - virtual IP address with ProxySQL load-balanced port*/
define( 'DB_HOST', '192.168.55.180:6033' );Om du vill komma åt databasklustret direkt, förbi belastningsutjämnaren, kan du bara ansluta till port 3306 för databasvärdarna. Detta krävs vanligtvis av DBA-personalen för administration, hantering och felsökning. Med ClusterControl kan de flesta av dessa operationer utföras direkt från användargränssnittet.
Sluta tankar
Som visas ovan är det inte längre en svår uppgift att distribuera ett databaskluster. När det väl har distribuerats finns det en komplett uppsättning gratis övervakningsfunktioner såväl som kommersiella funktioner för säkerhetskopiering, failover/återställning och andra. Snabb distribution av olika typer av kluster-/replikeringstopologier kan vara användbart när man utvärderar databaslösningar med hög tillgänglighet och hur de passar till just din miljö.