SQLAlchemy hjälper dig att arbeta med databaser i Python. I det här inlägget berättar vi allt du behöver veta för att komma igång med den här modulen.
I den tidigare artikeln pratade vi om hur man använder Python i ETL-processen. Vi fokuserade på att få jobbet gjort genom att exekvera lagrade procedurer och SQL-frågor. I den här artikeln och nästa kommer vi att använda ett annat tillvägagångssätt. Istället för att skriva SQL-kod använder vi verktygslådan SQLAlchemy. Du kan också använda den här artikeln separat, som en snabb introduktion om att installera och använda SQLAlchemy.
Redo? Låt oss börja.
Vad är SQLAlchemy?
Python är välkänt för sitt antal och variation av moduler. Dessa moduler minskar vår kodningstid avsevärt eftersom de implementerar rutiner som behövs för att uppnå en specifik uppgift. Ett antal moduler som arbetar med data finns tillgängliga, inklusive SQLAlchemy.
För att beskriva SQLAlchemy använder jag ett citat från SQLAlchemy.org:
SQLAlchemy är Python SQL-verktygssatsen och Object Relational Mapper som ger applikationsutvecklare den fulla kraften och flexibiliteten hos SQL.
Det ger en komplett uppsättning välkänd uthållighet på företagsnivå mönster, designade för effektiv och högpresterande databasåtkomst, anpassade till ett enkelt och pytoniskt domänspråk.
Den viktigaste delen här är lite om ORM (object-relational mapper), som hjälper oss att behandla databasobjekt som Python-objekt snarare än listor.
Innan vi går vidare med SQLAlchemy, låt oss pausa och prata om ORM.
För- och nackdelar med att använda ORM
Jämfört med rå SQL har ORM sina för- och nackdelar – och de flesta av dessa gäller även för SQLAlchemy.
The Good Stuff:
- Kodportabilitet. ORM tar hand om syntaktiska skillnader mellan databaser.
- Endast ett språk behövs för att hantera din databas. Även om, för att vara ärlig, detta inte borde vara den främsta motivationen att använda en ORM.
- ORM förenklar din kod , t.ex. de tar hand om relationer och behandlar dem som föremål, vilket är bra om du är van vid OOP.
- Du kan manipulera dina data inuti programmet .
Tyvärr kommer allt med ett pris. The Not-So-Good Stuff om ORM:
- I vissa fall kan en ORM vara långsam .
- Skriva komplexa frågor kan bli ännu mer komplicerat, eller kan resultera i långsamma frågor. Men detta är inte fallet när du använder SQLAlchemy.
- Om du kan ditt DBMS väl är det ett slöseri med tid att lära dig hur man skriver samma saker i en ORM.
Nu när vi har hanterat det ämnet, låt oss gå tillbaka till SQLAlchemy.
Innan vi börjar...
… låt oss påminna oss själva om målet med den här artikeln. Om du bara är intresserad av att installera SQLAlchemy och behöver en snabb handledning om hur man utför enkla kommandon, kommer den här artikeln att göra det. Kommandona som presenteras i den här artikeln kommer dock att användas i nästa artikel för att utföra ETL-processen och ersätta SQL (lagrade procedurer) och Python-kod som vi presenterade i tidigare artiklar.
Okej, låt oss börja direkt från början:med att installera SQLAlchemy.
Installera SQLAlchemy
1. Kontrollera om modulen redan är installerad
För att använda en Python-modul måste du installera den (det vill säga om den inte var installerad tidigare). Ett sätt att kontrollera vilka moduler som har installerats är att använda detta kommando i Python Shell:
help('modules')
För att kontrollera om en specifik modul är installerad, prova helt enkelt att importera den. Använd dessa kommandon:
import sqlalchemy sqlalchemy.__version__
Om SQLAlchemy redan är installerat, kommer den första raden att köras framgångsrikt. importera
Det andra kommandot returnerar den aktuella versionen av SQLAlchemy. Resultatet som returneras visas nedan:

Vi behöver en annan modul också, och det är PyMySQL . Detta är ett rent Python-lätta MySQL-klientbibliotek. Den här modulen stöder allt vi behöver för att arbeta med en MySQL-databas, från att köra enkla frågor till mer komplexa databasåtgärder. Vi kan kontrollera om det finns med help('modules') , som tidigare beskrivits, eller med följande två satser:
import pymysql pymysql.__version__
Det här är naturligtvis samma kommandon som vi använde för att testa om SQLAlchemy var installerat.
Vad händer om SQLAlchemy eller PyMySQL inte redan är installerat?
Att importera tidigare installerade moduler är inte svårt. Men vad händer om modulerna du behöver inte redan är installerade?
Vissa moduler har ett installationspaket, men oftast använder du kommandot pip för att installera dem. PIP är ett Python-verktyg som används för att installera och avinstallera moduler. Det enklaste sättet att installera en modul (i Windows OS) är:
- Använd Kommandotolken -> Kör -> cmd .
- Placera till Python-katalogen cd C:\...\Python\Python37\Scripts .
- Kör kommandot pip
install(i vårt fall kör vi pip install pyMySQLochpip installera sqlAlchemy.
PIP kan också användas för att avinstallera den befintliga modulen. För att göra det bör du använda pip uninstall
2. Ansluter till databasen
Även om det är viktigt att installera allt som behövs för att använda SQLAlchemy, är det inte särskilt intressant. Det är inte heller en del av det vi är intresserade av. Vi har inte ens anslutit till de databaser vi vill använda. Vi löser det nu:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
Med hjälp av skriptet ovan upprättar vi en anslutning till databasen som finns på vår lokala server, subscription_live databas.
(Obs! Ersätt
Låt oss gå igenom skriptet, kommando för kommando.
import sqlalchemy from sqlalchemy.engine import create_engine
Dessa två rader importerar vår modul och create_engine funktion.
Därefter upprättar vi en anslutning till databasen som finns på vår server.
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
Funktionen create_engine skapar motorn och använder .connect() , ansluter till databasen. create_engine funktionen använder dessa parametrar:
dialect+driver://username:password@host:port/database
I vårt fall är dialekten mysql , drivrutinen är pymysql (tidigare installerat) och de återstående variablerna är specifika för servern och databaserna vi vill ansluta till.
(Obs! Om du ansluter lokalt, använd localhost istället för din "lokala" IP-adress, 127.0.0.1 och lämplig port :3306 .)

Resultatet av kommandot print(engine_live.table_names()) visas på bilden ovan. Som väntat fick vi listan över alla tabeller från vår operativa/live databas.
3. Köra SQL-kommandon med SQLAlchemy
I det här avsnittet kommer vi att analysera de viktigaste SQL-kommandona, undersöka tabellstrukturen och utföra alla fyra DML-kommandon:SELECT, INSERT, UPDATE och DELETE.
Vi kommer att diskutera påståendena som används i det här skriptet separat. Observera att vi redan har gått igenom anslutningsdelen av det här skriptet och vi har redan listat tabellnamn. Det finns mindre ändringar på denna rad:
from sqlalchemy import create_engine, select, MetaData, Table, asc
Vi har precis importerat allt vi kommer att använda från SQLAlchemy.
Tabell och struktur
Vi kör skriptet genom att skriva följande kommando i Python Shell:
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
Resultatet är det körda skriptet. Låt oss nu analysera resten av skriptet.
SQLAlchemy importerar information relaterad till tabeller, struktur och relationer. För att arbeta med den informationen kan det vara användbart att kontrollera listan med tabeller (och deras kolumner) i databasen:
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

Detta returnerar helt enkelt en lista över alla tabeller från den anslutna databasen.
Obs! tabellnamn() metod returnerar en lista med tabellnamn för den givna motorn. Du kan skriva ut hela listan eller iterera genom den med en loop (som du kan göra med vilken annan lista som helst).
Därefter returnerar vi en lista över alla attribut från den valda tabellen. Den relevanta delen av skriptet och resultatet visas nedan:
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
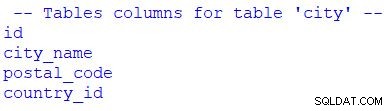
Du kan se att jag har använt för för att gå igenom resultatuppsättningen. Vi skulle kunna ersätta table_city.c med table_city.columns .
Obs! Processen att ladda databasbeskrivningen och skapa metadata i SQLAlchemy kallas reflektion.
Obs! MetaData är objektet som håller information om objekt i databasen, så tabeller i databasen är också länkade till detta objekt. I allmänhet lagrar detta objekt information om hur databasschemat ser ut. Du kommer att använda den som en enda kontaktpunkt när du vill göra ändringar i eller få fakta om DB-schemat.
Obs! Attributen autoload =True och autoload_with =engine_live bör användas för att säkerställa att tabellattribut laddas upp (om de inte redan har gjorts).
VÄLJ
Jag tror inte att jag behöver förklara hur viktig SELECT-satsen är :) Så låt oss bara säga att du kan använda SQLAlchemy för att skriva SELECT-satser. Om du är van vid MySQL-syntax kommer det att ta lite tid att anpassa sig; ändå är allt ganska logiskt. För att uttrycka det så enkelt som möjligt skulle jag säga att SELECT-satsen är uppskuren och vissa delar är utelämnade, men allt är fortfarande i samma ordning.
Låt oss prova några SELECT-satser nu.
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
Den första är en enkel SELECT-sats returnerar alla värden från den givna tabellen. Syntaxen för detta uttalande är mycket enkel:jag har placerat namnet på tabellen i select() . Observera att jag har:
- Förberedde uttalandet -
stmt =select([tabellstad]. - Skriv ut satsen med
print(stmt), vilket ger oss en god uppfattning om uttalandet som just har utförts. Detta kan också användas för felsökning. - Skriv ut resultatet med
print(connection_live.execute(stmt).fetchall()). - Släpade igenom resultatet och skrev ut varje enskild post.
Obs! Eftersom vi också laddade primära och främmande nyckelbegränsningar i SQLAlchemy, tar SELECT-satsen en lista med tabellobjekt som argument och upprättar automatiskt relationer där det behövs.
Resultatet visas på bilden nedan:

Python kommer att hämta alla attribut från tabellen och lagra dem i objektet. Som visas kan vi använda detta objekt för att utföra ytterligare operationer. Det slutliga resultatet av vårt uttalande är en lista över alla städer från staden bord.
Nu är vi redo för en mer komplex fråga. Jag har precis lagt till en ORDER BY-klausul .
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Obs! asc() Metoden utför stigande sortering mot det överordnade objektet, med definierade kolumner som parametrar.
Den returnerade listan är densamma, men nu sorteras den efter id-värdet, i stigande ordning. Det är viktigt att notera att vi helt enkelt har lagt till .order_by( till föregående SELECT-fråga. .order_by(...) metoden tillåter oss att ändra ordningen på resultatuppsättningen som returneras, på samma sätt som vi skulle använda i en SQL-fråga. Därför bör parametrar följa SQL-logik, använda kolumnnamn eller kolumnordning och ASC eller DESC.
Därefter lägger vi till WHERE till vår SELECT-sats.
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

Obs! .where() metod används för att testa ett villkor som vi har använt som argument. Vi kan också använda .filter() metod, som är bättre på att filtrera mer komplexa förhållanden.
Återigen, .where del är helt enkelt kopplad till vår SELECT-sats. Lägg märke till att vi har satt skicket inom parentesen. Vilket tillstånd som än finns inom parentes testas på samma sätt som det skulle testas i WHERE-delen av en SELECT-sats. Likhetsvillkoret testas med ==istället för =.
Det sista vi ska försöka med SELECT är att sammanfoga två tabeller. Låt oss ta en titt på koden och dess resultat först.
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

Det finns två viktiga delar i uttalandet ovan:
välj([tabellstad.kolumner.stadsnamn, tabellland.kolumner.landsnamn])definierar vilka kolumner som kommer att returneras i vårt resultat..select_from(table_city.join(table_country))definierar sammanfogningsvillkoret/tabellen. Lägg märke till att vi inte behövde skriva ner hela anslutningsvillkoret, inklusive nycklarna. Detta beror på att SQLAlchemy "vet" hur dessa två tabeller är sammanfogade, eftersom regler för primärnycklar och främmande nycklar importeras i bakgrunden.
INSERT / UPPDATERA / DELETE
Det här är de tre återstående DML-kommandona som vi kommer att täcka i den här artikeln. Även om deras struktur kan bli mycket komplex, är dessa kommandon vanligtvis mycket enklare. Den använda koden presenteras nedan.
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
Samma mönster används för alla tre påståenden:förbereda påståendet, skriva ut och köra det, och skriva ut resultatet efter varje påstående så att vi kan se vad som faktiskt hände i databasen. Observera ännu en gång att delar av satsen behandlades som objekt (.values(), .where()).

Vi kommer att använda denna kunskap i den kommande artikeln för att bygga ett helt ETL-skript med SQLAlchemy.
Nästa upp:SQLAlchemy in the ETL Process
Idag har vi analyserat hur man ställer in SQLAlchemy och hur man utför enkla DML-kommandon. I nästa artikel kommer vi att använda denna kunskap för att skriva hela ETL-processen med SQLAlchemy.
Du kan ladda ner hela skriptet som används i den här artikeln här.