I dag är databaser som spänner över flera moln ganska vanliga. De lovar hög tillgänglighet och möjlighet att enkelt implementera katastrofåterställningsprocedurer. De är också en metod för att undvika leverantörslåsning:om du designar din databasmiljö så att den kan fungera över flera molnleverantörer, är du troligen inte bunden till funktioner och implementeringar som är specifika för en viss leverantör. Detta gör det enklare för dig att lägga till ytterligare en infrastrukturleverantör till din miljö, oavsett om det är ett annat moln eller en lokal installation. Sådan flexibilitet är mycket viktig med tanke på att det finns hård konkurrens mellan molnleverantörer och att migrera från en till en annan kan vara ganska genomförbar om det skulle backas upp av minskade kostnader.
Att spänna din infrastruktur över flera datacenter (från samma leverantör eller inte, det spelar egentligen ingen roll) medför allvarliga problem att lösa. Hur kan man designa hela infrastrukturen på ett sätt så att data blir säker? Hur hanterar du utmaningar som du måste möta när du arbetar i en miljö med flera moln? I den här bloggen kommer vi att ta en titt på en, men utan tvekan den mest allvarliga – potentialen för en split-brain. Vad betyder det? Låt oss gräva lite i vad split-brain är.
Vad är "Split-Brain"?
Delad hjärna är ett tillstånd där en miljö som består av flera noder drabbas av nätverkspartitionering och har delats upp i flera segment som inte har kontakt med varandra. Det enklaste fallet kommer att se ut så här:
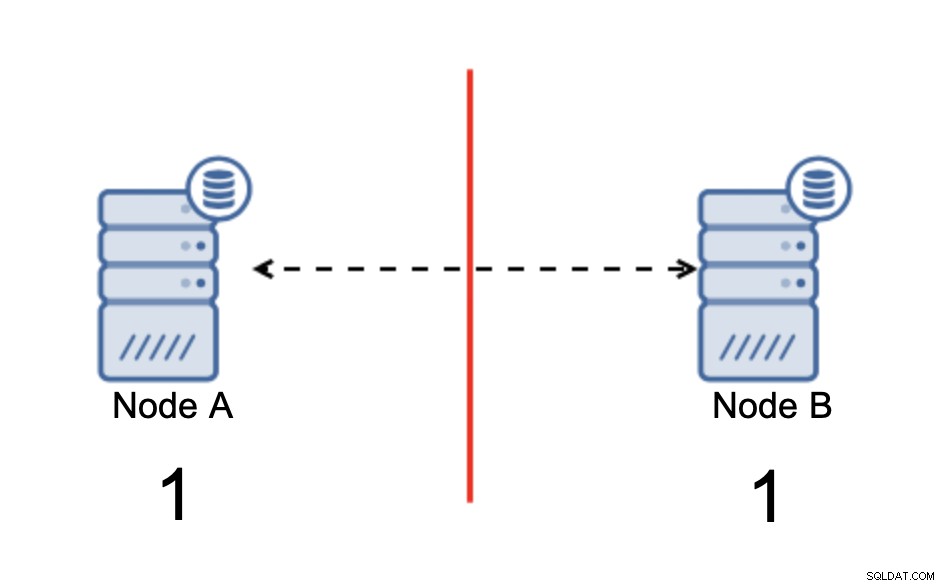
Vi har två noder, A och B, anslutna över ett nätverk med bi -riktad asynkron replikering. Sedan bryts nätverksanslutningen mellan dessa noder. Som ett resultat kan båda noderna inte ansluta till varandra och eventuella ändringar som utförs på nod A kan inte överföras till nod B och vice versa. Båda noderna, A och B, är uppe och accepterar anslutningar, de kan bara inte utbyta data. Detta kan leda till allvarliga problem eftersom applikationen kan göra ändringar på båda noderna och förväntar sig att se hela tillståndet för databasen medan det i själva verket bara fungerar på ett delvis känt datatillstånd. Som ett resultat kan felaktiga åtgärder vidtas av applikationen, felaktiga resultat kan presenteras för användaren och så vidare. Vi tror att det är uppenbart att split-brain potentiellt är ett mycket farligt tillstånd och en av prioriteringarna skulle vara att hantera det till viss del. Vad kan man göra åt det?
Hur man undviker split-brain
Kort sagt, det beror på. Huvudfrågan att ta itu med är det faktum att noderna är igång men inte har anslutning mellan dem och därför är de omedvetna om tillståndet för den andra noden. I allmänhet har MySQL asynkron replikering inte någon form av mekanism som internt skulle lösa problemet med split-brain. Du kan försöka implementera några lösningar som hjälper dig att undvika split-brain men de kommer med begränsningar eller så löser de fortfarande inte problemet helt.
När vi vågar oss bort från den asynkrona replikeringen ser saker och ting annorlunda ut. MySQL Group Replication och MySQL Galera Cluster är teknologier som drar nytta av att bygga upp kluster. Båda dessa lösningar upprätthåller kommunikationen över noderna och säkerställer att klustret är medvetet om nodernas tillstånd. De implementerar en kvorummekanism som styr om kluster kan vara i drift eller inte.
Låt oss diskutera dessa två lösningar (asynkron replikering och kvorumbaserade kluster) mer i detalj.
Kvorumbaserad klustring
Vi kommer inte att diskutera implementeringsskillnaderna mellan MySQL Galera Cluster och MySQL Group Replication, vi kommer att fokusera på grundidén bakom det kvorumbaserade tillvägagångssättet och hur det är utformat för att lösa problemet med split-brain i ditt kluster.
Konklusionen är att:kluster, för att fungera, kräver att majoriteten av dess noder är tillgängliga. Med detta krav kan vi vara säkra på att minoriteten aldrig riktigt kan påverka resten av klustret eftersom minoriteten inte ska kunna utföra några handlingar. Detta innebär också att, för att kunna hantera ett fel på en nod, bör ett kluster ha minst tre noder. Om du bara har två noder:
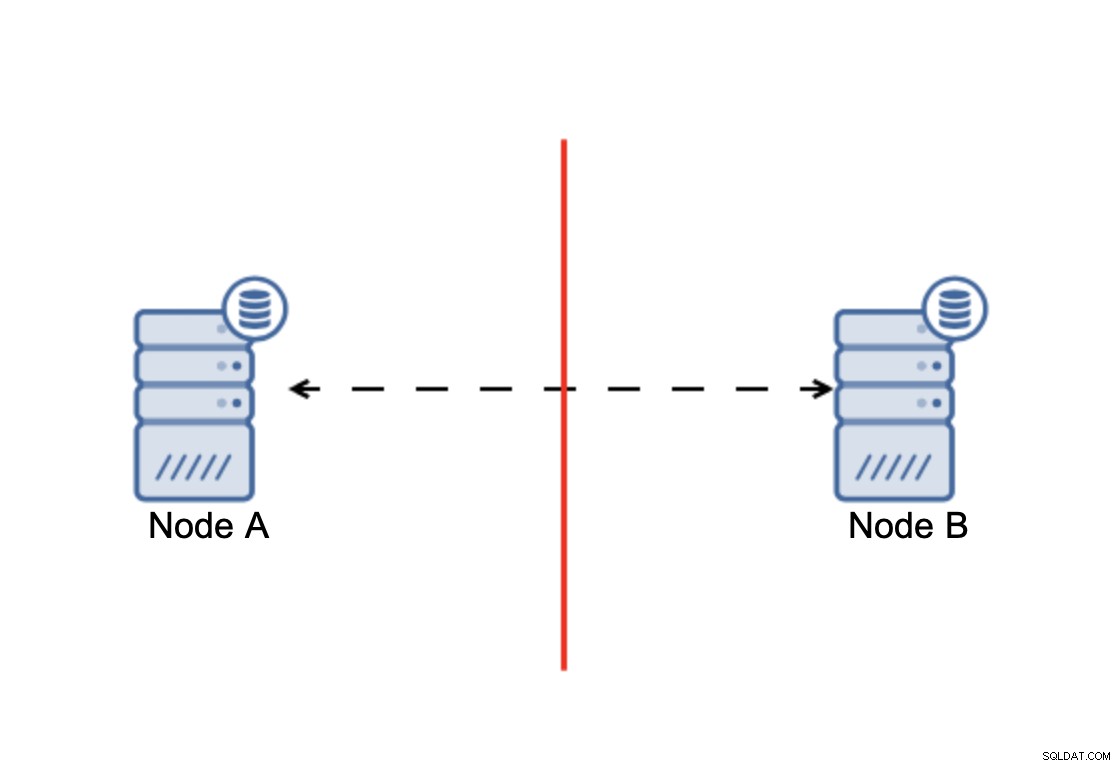
När det uppstår en nätverksdelning, slutar du med två delar av kluster, som var och en består av exakt 50 % av de totala noderna i klustret. Ingen av dessa delar har majoritet. Om du har tre noder är saker och ting annorlunda:
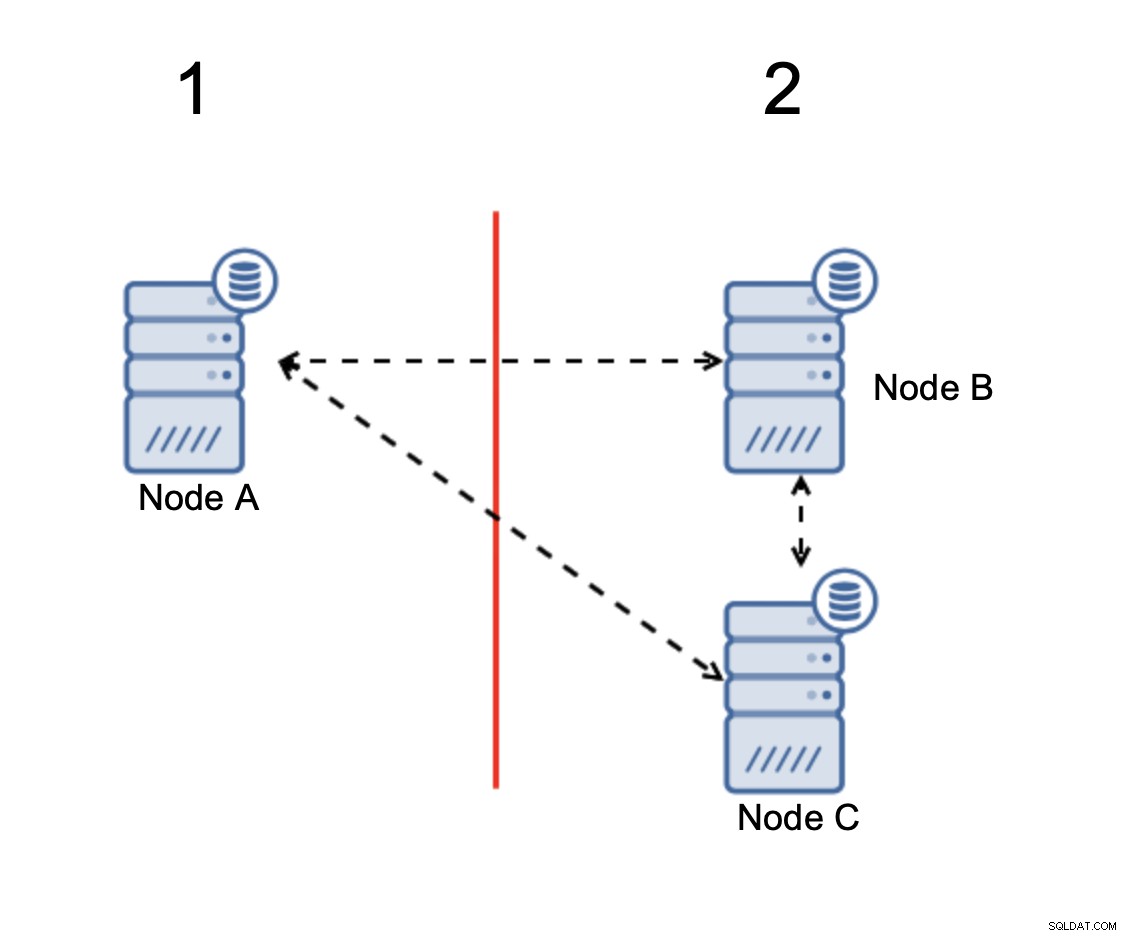
Noderna B och C har majoriteten:den delen består av två noder ut av tre så att den kan fortsätta att fungera. Å andra sidan representerar nod A endast 33 % av noderna i klustret, så den har inte en majoritet och den kommer att sluta hantera trafik för att undvika den splittrade hjärnan.
Med en sådan implementering är det mycket osannolikt att split-brain inträffar (det skulle behöva introduceras genom några konstiga och oväntade nätverkstillstånd, rasförhållanden eller helt enkelt buggar i klustringskoden. Även om det inte är omöjligt att stöta på sådana förhållanden är att använda en av lösningarna som är kvorumbaserade det bästa alternativet för att undvika den splittrade hjärnan som finns i detta ögonblick.
Asynkron replikering
Även om det inte är det perfekta valet när det gäller att hantera split-brain, är asynkron replikering fortfarande ett gångbart alternativ. Det finns flera saker du bör tänka på innan du implementerar en multimolndatabas med asynkron replikering.
Först, failover. Asynkron replikering kommer med en skrivare - endast master ska vara skrivbar och andra noder ska endast betjäna skrivskyddad trafik. Utmaningen är hur man hanterar mastermisslyckandet?
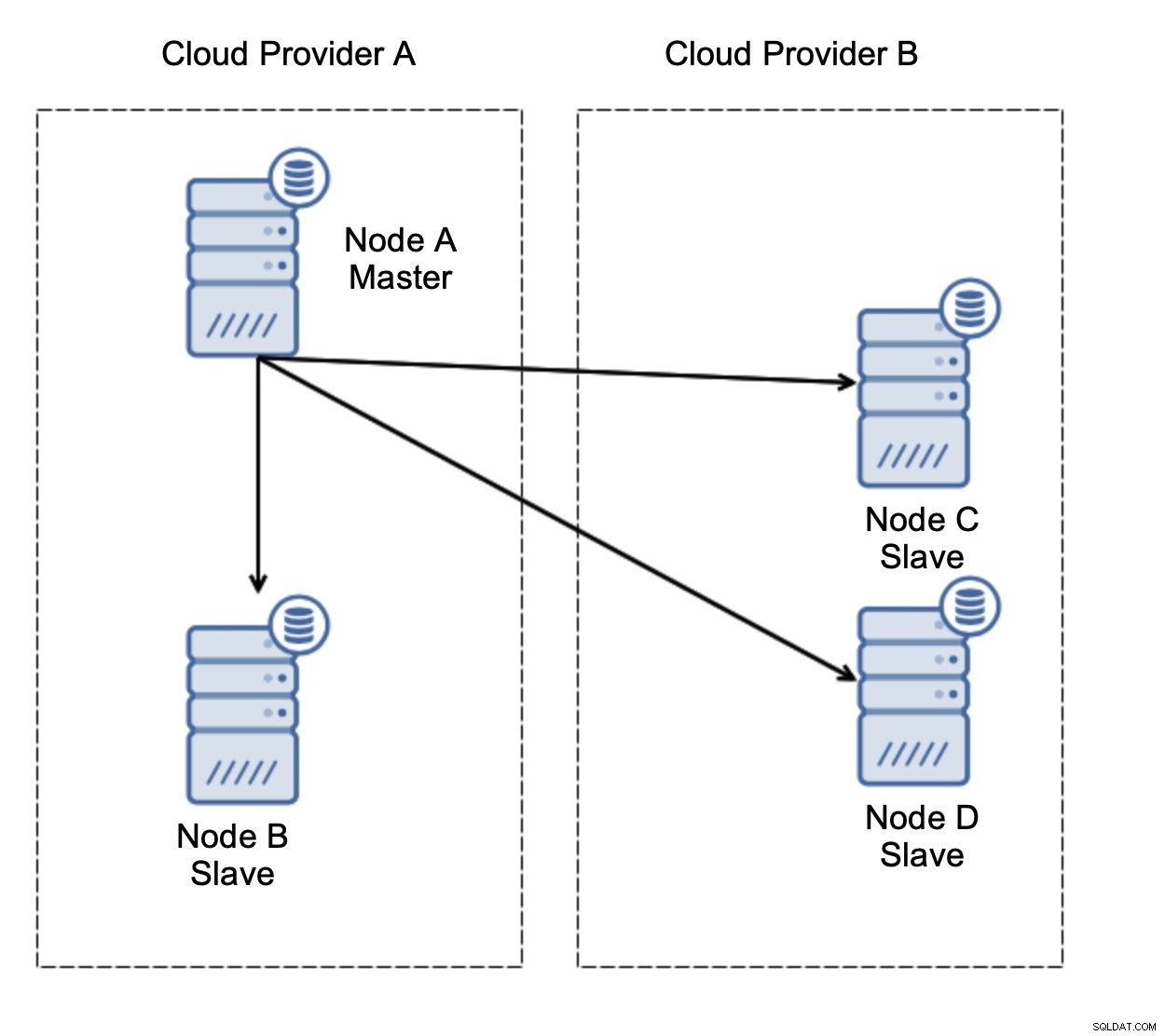
Låt oss överväga installationen som i diagrammet ovan. Vi har två molnleverantörer, två noder i varje. Leverantör A är även värd för mastern. Vad ska hända om befälhavaren misslyckas? En av slavarna bör främjas för att säkerställa att databasen kommer att fortsätta att fungera. Helst bör det vara en automatiserad process för att minska den tid som behövs för att få databasen till operativt tillstånd. Vad skulle dock hända om det skulle finnas en nätverkspartitionering? Hur förväntas vi verifiera klustrets tillstånd?
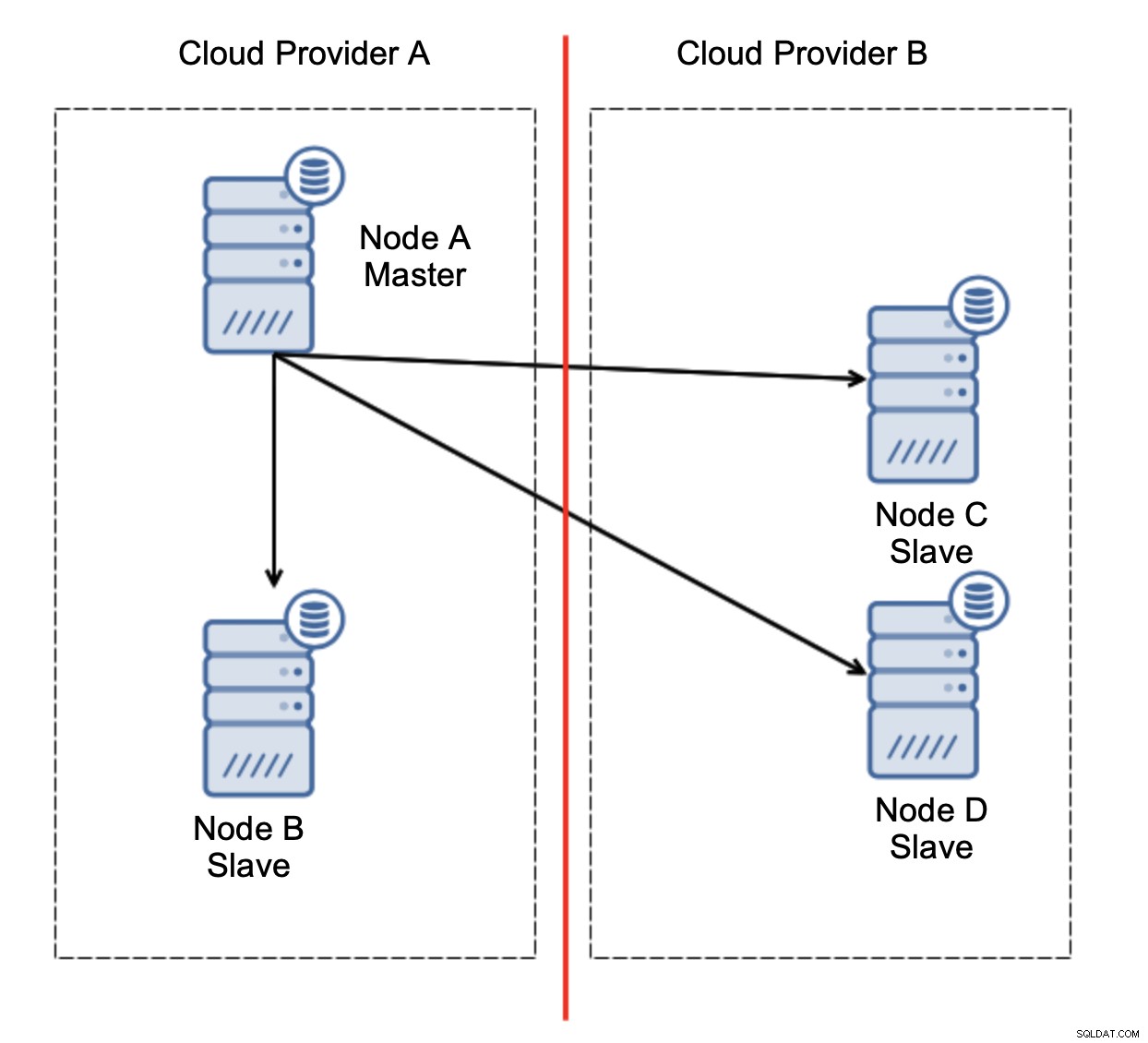
Här är utmaningen. Nätverksanslutning går förlorad mellan två molnleverantörer. Från nodernas C och D synvinkel är både nod B och master nod A offline. Ska nod C eller D befordras till att bli en mästare? Men den gamla mästaren är fortfarande uppe - den kraschade inte, den är bara inte tillgänglig via nätverket. Om vi skulle marknadsföra en av noderna som finns hos leverantör B, kommer vi att sluta med två skrivbara masters, två datamängder och delad hjärna:
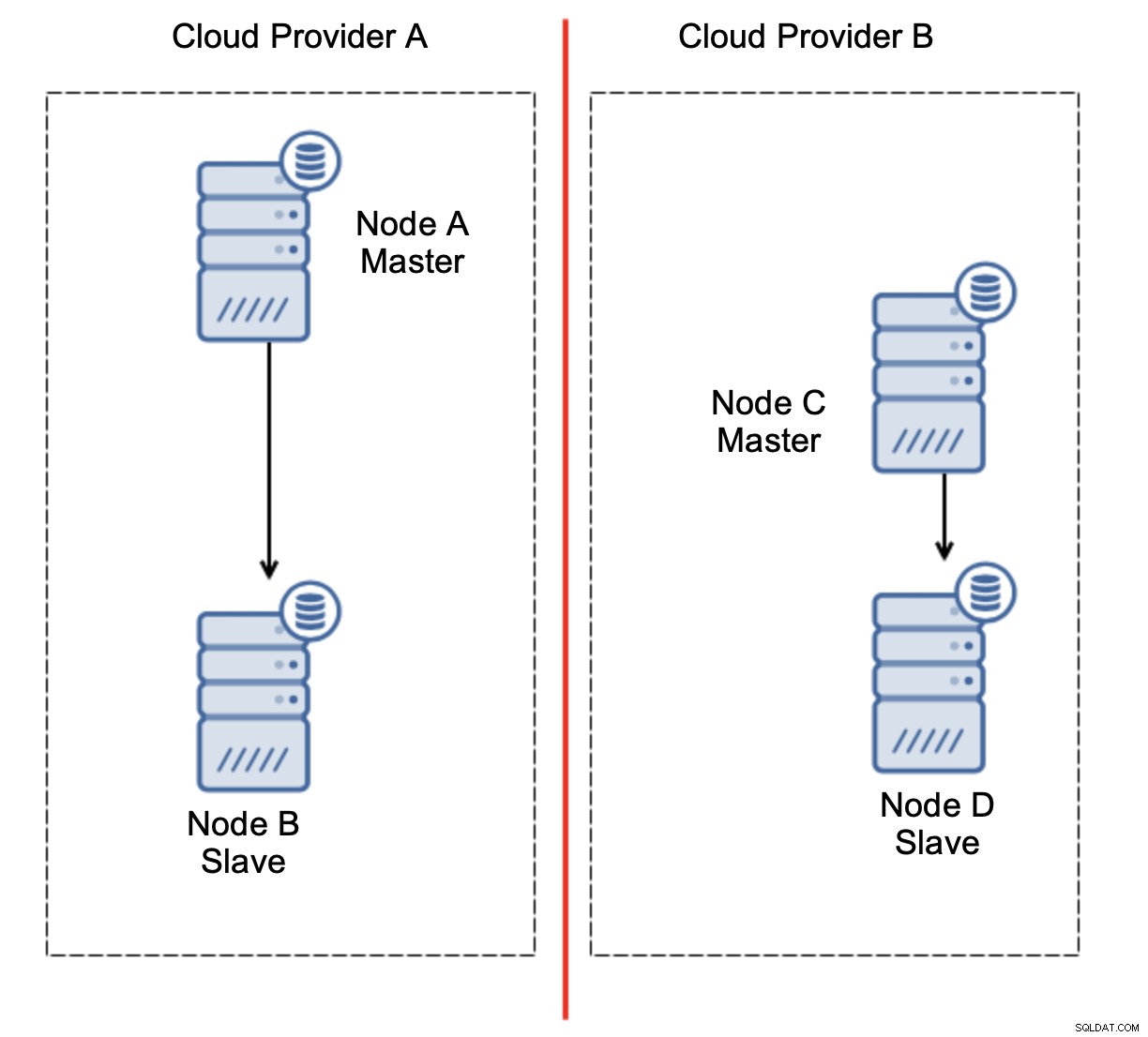
Detta är definitivt inte något vi vill ha. Det finns ett par alternativ här. Först kan vi definiera failover-regler på ett sätt så att failover endast kan ske i ett av nätverkssegmenten, där mastern finns. I vårt fall skulle det innebära att endast nod B automatiskt skulle kunna befordras till att bli en master. På så sätt kan vi säkerställa att den automatiska failover kommer att ske om nod A är nere men ingen åtgärd kommer att vidtas om det finns en nätverkspartitionering. Några av verktygen som kan hjälpa dig att hantera automatiska failovers (som ClusterControl) stöder vita och svarta listor, vilket gör att användare kan definiera vilka noder som kan betraktas som kandidater för failover till och vilka som aldrig ska användas som masters.
Ett annat alternativ skulle vara att implementera någon form av en "topologimedvetenhet"-lösning. Till exempel kan man försöka kontrollera huvudtillståndet med hjälp av externa tjänster som lastbalanserare.
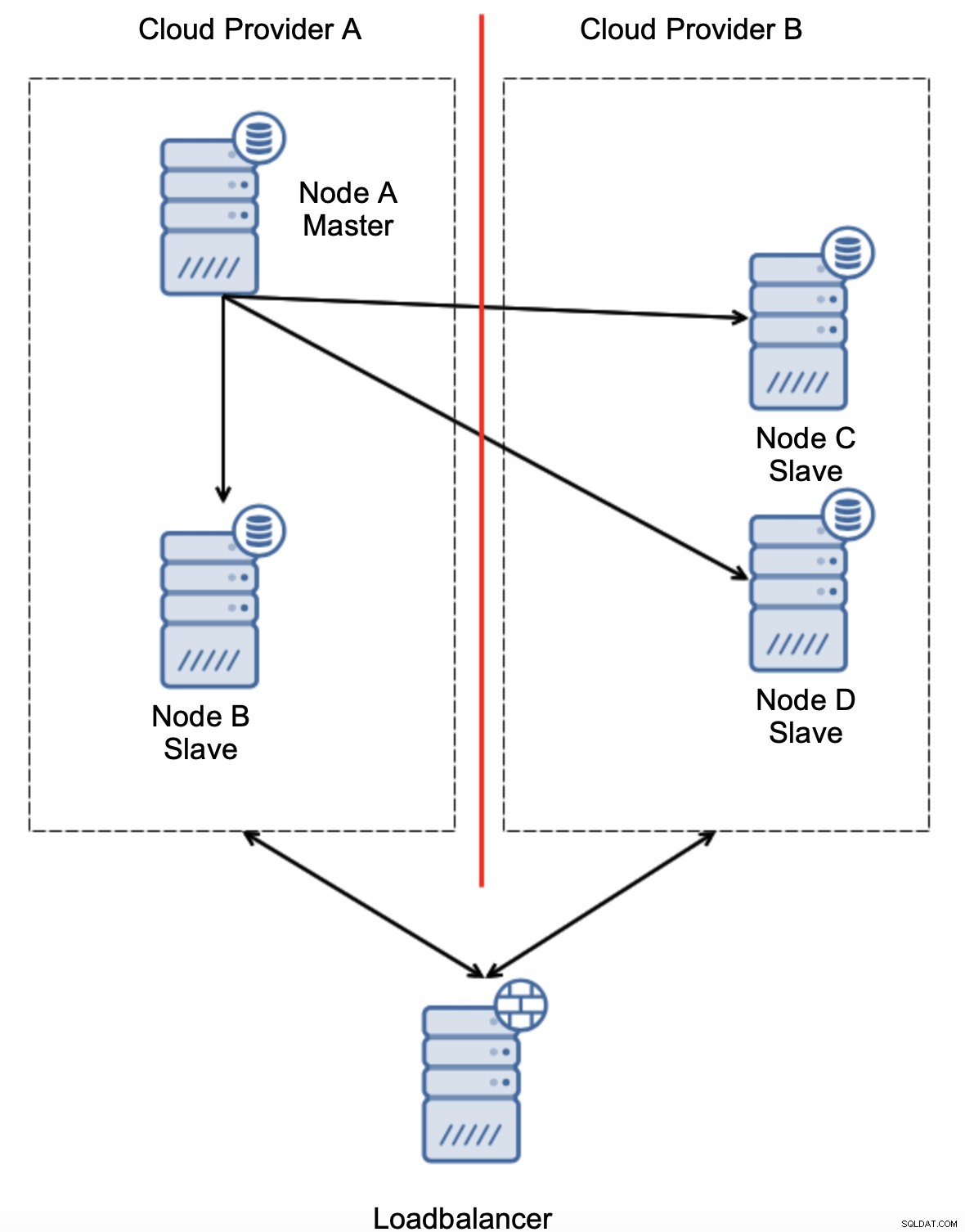
Om failover-automatiseringen kunde kontrollera topologins tillstånd som ses av lastbalanserare, kan det vara så att lastbalanseraren, som finns på en tredje plats, faktiskt kan nå båda datacenterna och göra det tydligt att noder i molnleverantör A inte är nere, de kan bara inte nås från molnleverantör B. Sådana ett extra lager av kontroller implementeras i ClusterControl.
Slutligen, oavsett vilket verktyg du använder för att implementera automatisk failover, kan det också utformas så att det är kvorummedvetet. Sedan, med tre noder på tre platser, kan du enkelt avgöra vilken del av infrastrukturen som ska hållas vid liv och vilken som inte ska göra det.
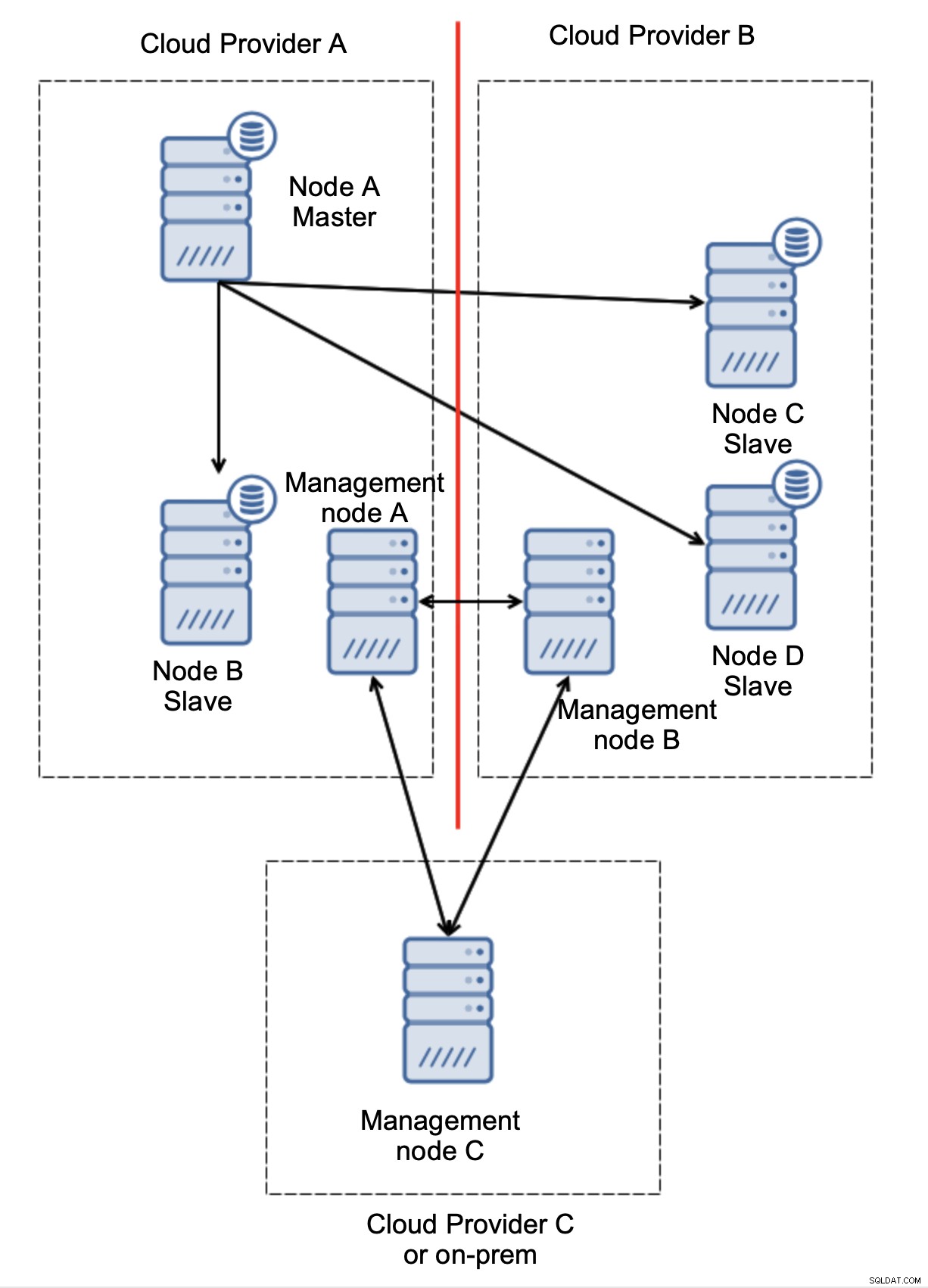
Här kan vi tydligt se att problemet endast är relaterat till anslutningen mellan leverantörerna A och B. Hanteringsnod C kommer att fungera som ett relä och som ett resultat bör ingen failover startas. Å andra sidan, om ett datacenter är helt avstängt:

Det är också ganska tydligt vad som hände. Ledningsnod A kommer att rapportera att den inte kan nå ut till majoriteten av klustret medan förvaltningsnoderna B och C kommer att utgöra majoriteten. Det är möjligt att bygga vidare på detta och till exempel skriva skript som kommer att hantera topologin enligt tillståndet för förvaltningsnoden. Det kan betyda att skripten som körs i molnleverantör A skulle upptäcka att hanteringsnod A inte utgör majoriteten och de kommer att stoppa alla databasnoder för att säkerställa att inga skrivningar sker i den partitionerade molnleverantören.
ClusterControl, när den distribueras i hög tillgänglighetsläge kan behandlas som de hanteringsnoder vi använde i våra exempel. Tre ClusterControl-noder, ovanpå RAFT-protokollet, kan hjälpa dig att avgöra om ett visst nätverkssegment är partitionerat eller inte.
Slutsats
Vi hoppas att det här blogginlägget ger dig en uppfattning om scenarier med split-brain som kan hända för MySQL-distributioner som spänner över flera molnplattformar.