Att driva en bil-/bilverkstad är en riktigt komplex verksamhet. Du måste boka tid medan vissa kunder kommer att köra in och du vill inte att de ska vänta i timmar. Dessutom måste du organisera anställda, spåra reparationer, material, debitera kunder, etc. Du behöver definitivt en IT-lösning och, naturligtvis, en datamodell i bakgrunden. Idag ska vi prata om en sådan modell.
Idén
Jag har redan nämnt att denna affärsmodell är riktigt komplex. Därför kommer jag inte försöka täcka allt. Jag har avsiktligt utelämnat spårningsmaterial och reservdelar och även förenklat vissa delar av modellen. Anledningen till det är ganska enkel. Om jag har tagit med verkligen allt, skulle modellen helt enkelt vara för stor för en artikel av rimlig storlek. Så låt oss börja.
Datamodell
Modellen består av 5 ämnesområden:
Repair shops & employeesCustomers & contactsVehiclesServices & offersochVisits
Vi kommer att beskriva vart och ett av dessa 5 ämnesområden i den ordning de listades.
Avsnitt 1:Reparationsverkstäder och anställda
Det första ämnesområdet vi börjar med är Repair shops & employees ämnesområde. Det är ganska uppenbart att vi måste veta vad vi har till förfogande innan vi kan lämna erbjudanden till kunder.
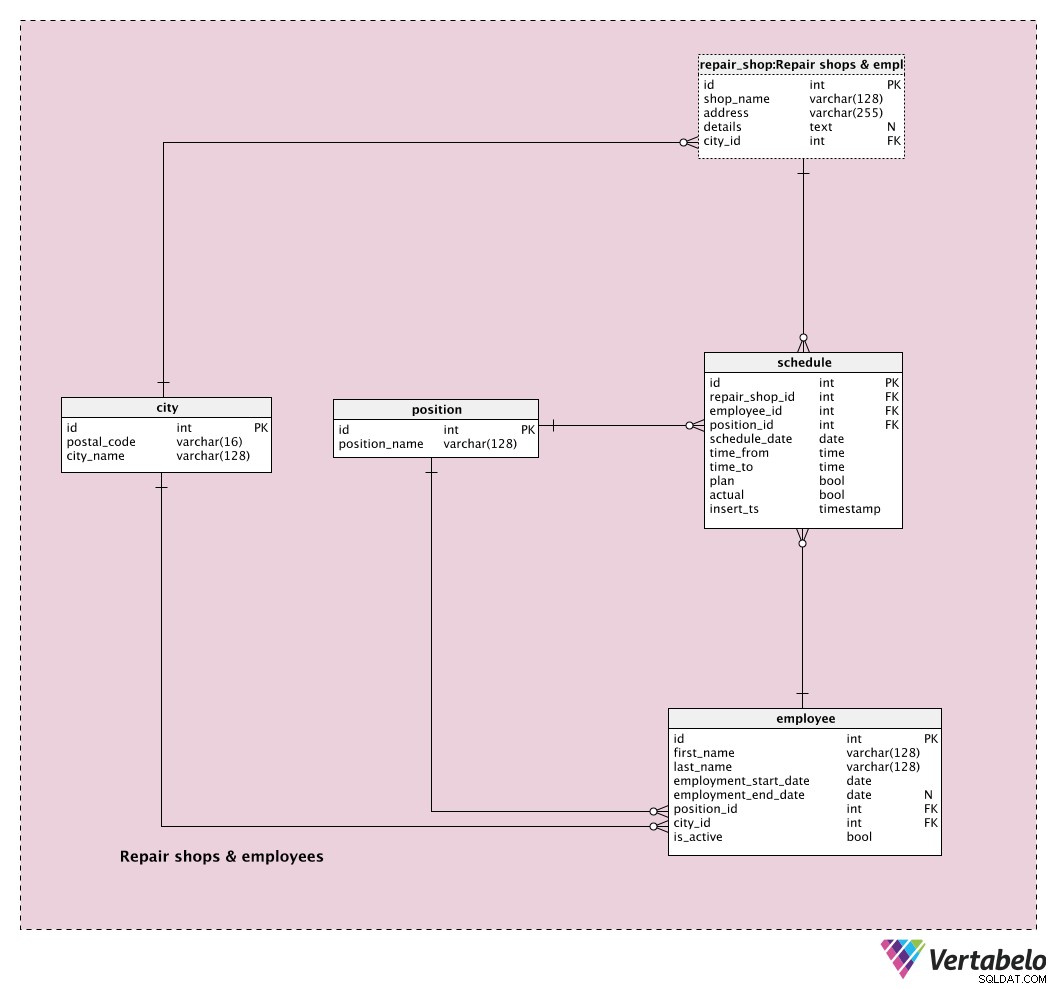
city ordbok används för att lagra alla distinkta städer där vi har reparationsverkstäder eller våra kunder kommer ifrån. Varje stad definieras unikt av paret postal_code – city_name . Vi skulle kunna välja att bara ha en post per stad, även om den staden har flera postnummer. I så fall skulle vi bara använda "huvudpostnumret" för den staden. Ändå har vi ett alternativ att ha flera poster för samma stad och olika postnummer – om vi vill ha det.
repair_shop tabellen är platsen där vi kommer att lagra en lista över alla våra reparationsverkstäder. Vi kan förvänta oss att vi kommer att driva mer än en någon gång. Varje butik är unikt definierad av dess shop_name och id för staden den tillhör (city_id ). Vi lagrar även butikens adress och ytterligare details i eventuellt textformat.
position ordbok används för att lagra unika position_names som skulle kunna tilldelas våra anställda. Även om de flesta befattningar ska vara relaterade till vår kärnverksamhet, kommer vi också att ha några som inte är en del av kärnverksamheten (tekniska roller/befattningar) men som också är viktiga (administration, försäljning, etc.).
En lista över alla våra anställda lagras i employee tabell. För varje anställd lagrar vi hans:
first_name&last_name– Den anställdes för- och efternamn.employment_start_date&employment_end_date– Anställds start- och slutdatum i företaget. Slutdatumet ska innehålla NULL-värdet tills vi kan definiera det.position_id– En referens till den aktuella positionen i företaget.city_id– En hänvisning till den stad där den anställde för närvarande bor.is_active– En flagga som anger om medarbetaren är aktiv eller inte.
Den sista tabellen i detta ämnesområde är schedule tabell. I den här tabellen lagrar vi exakta scheman för alla våra anställda på daglig nivå. Vi kommer också att ha möjlighet att lagra flera intervaller för samma anställd under samma dag. För att uppnå detta använder vi följande attribut:
repair_shop_id– En referens till den relaterade verkstaden.employee_id– En referens till den relaterade medarbetaren.position_id– En referens till den relaterade befattningen, den anställde skulle ha under den definierade tidsperioden. I de flesta fall skulle detta vara hans nuvarande position, men vi har flexibiliteten att tilldela någon annan position här.schedule_date– Ett datum som denna post är relaterad till.time_from&time_to– Detta par definierar tidsperioden som denna post är relaterad till.plan– En flagga som anger om detta var planerat inträde. Inträde ska inte planeras endast om vi infogat det ad-hoc.actual– Den här flaggan anger om denna post realiserades. Observera att i de flesta fall skulle både flaggor, plan och faktiska, vara inställda på True. Detta skulle påpeka att vi planerade och faktiskt förverkligade den planen.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Kombinationen repair_shop_id - employee_id - schedule_date - time_from bildar den UNIKA/alternativa nyckeln för denna tabell. Innan vi infogar en ny post bör vi också kontrollera det nya intervallet time_from – time_to överlappar inte något befintligt intervall för samma anställd och datum.
Avsnitt 2:Kunder och kontakter
Nu är vi redo att gå över till den kundrelaterade delen av modellen.
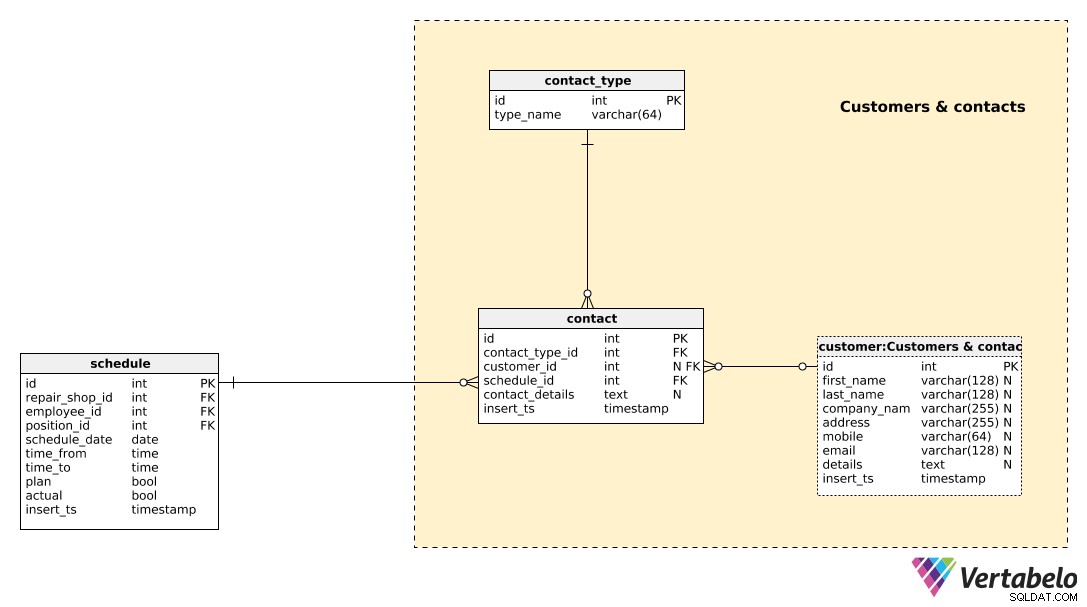
Vi lagrar alla kunder, vi arbetat med tidigare eller vi haft kontakt med, i customer tabell. För varje kund lagrar vi:
first_name&last_name– Kundens för- och efternamn, om vår kund är en privatperson.company_name– Ett företagsnamn, i ett fall ut är kund ett företag och inte en privatperson.address– Kundens adress.mobile– Kundens mobiltelefonnummer.email– Kundens e-postdetails– Alla ytterligare kunduppgifter, om några, i textformat.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
De flesta av attributen i den här tabellen är nullbara eftersom vi förmodligen inte kommer att ha några av dem och några (first_name &last_name kontra company_name ) utesluta andra.
Vi måste spåra alla kontakter vi gjort med varje kund. För att göra det använder vi två tabeller. Den första, contact_type table, är en enkel ordbok som endast innehåller det UNIKA type_name värde.
Verkliga kontaktuppgifter lagras i contact tabell. Vi lagrar referenser till typen av den kontakten (contact_type_id ), en kund som vi hade kontakt med (customer_id ), en anställd som tog kontakten (schedule_id ), och lagra även kontaktuppgifter och tidpunkten då denna post infogades i tabellen (insert_ts ).
Avsnitt 3:Fordon
Efter att ha känt till våra resurser och kunder måste vi lagra fordon vi kommer att arbeta med. Förutom att spåra data och skapa interna rapporter behöver vi i de flesta länder också skapa rapporter för tillsynsmyndigheter, försäkringsbolag, polis.
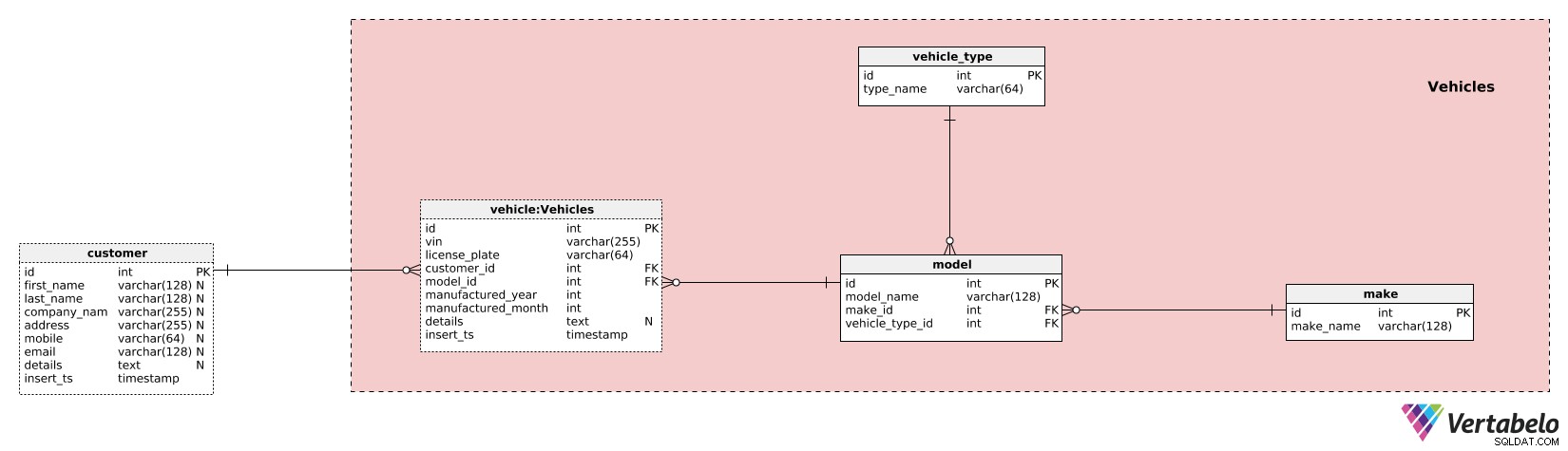
Först kommer vi att definiera modeller av våra fordon. Vi kommer att använda 3 tabeller för att uppnå det. I make ordbok kommer vi att lista unika make_names för alla bil-/fordonstillverkare/märken. Förutom det måste vi känna till fordonstyper, så vi kommer att använda ytterligare en ordbok med bara ett unikt värdeattribut – type_name . Den 3 ordboken som används är model lexikon. Den här ska innehålla listan över alla modeller som kom genom våra dörrar. För varje modell kommer vi att definiera den unika kombinationen model_name – make_id – vechicle_type_id .
Vi avslutar beskrivningen av detta ämnesområde med vehicle tabell. Detta är den enda tabellen i detta ämnesområde som innehåller "riktiga" data. Vi använder den här tabellen för att lagra följande information:
vin– Ett fordonsidentifikationsnummer som unikt definierar detta fordon.license_plate– Ett aktuellt registreringsnummer.customer_id– En referens till kunden som detta fordon tillhör. Om fordonet byter ägare kommer vi att infoga det som ett nytt rekord, men vi vet att detta är samma fordon baserat på serienumret.model_id– En referens till modelllexikonet.manufactured_year&manufactured_month– Ange år och månad då detta fordon tillverkades.details– Alla ytterligare detaljer i textformatet.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Avsnitt 4:Tjänster och erbjudanden
Vi är redo att ta nästa stora steg. Vi måste definiera vad vi erbjuder våra (potentiella) kunder. Dessa kan vara enstaka uppgifter eller en uppsättning uppgifter – tjänster.
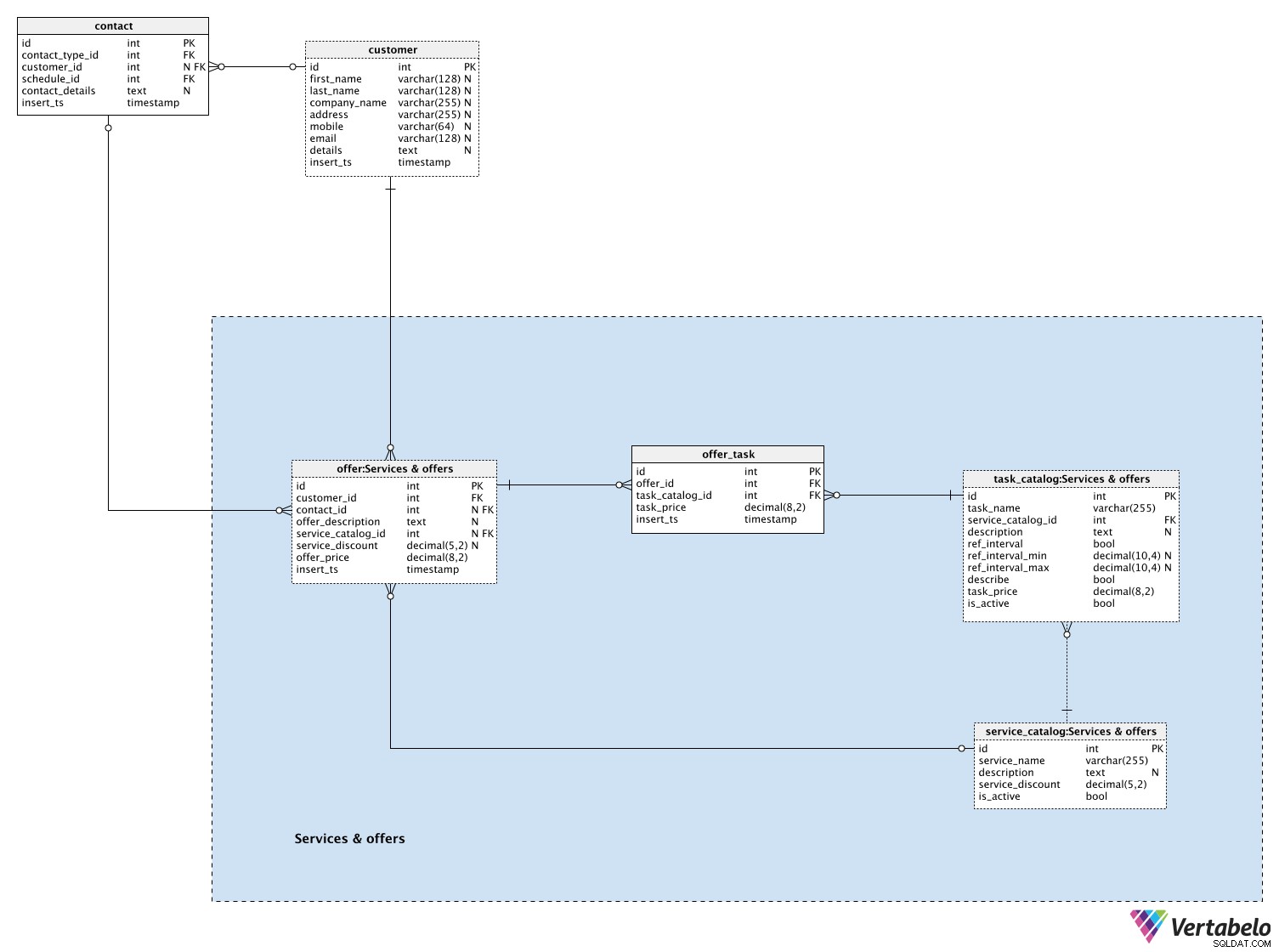
Listan över alla tjänster lagras i service_catalog lexikon. Varje tjänst består av ett fåtal uppgifter och är unikt definierad av dess service_name . Förutom namnet lagrar vi även en beskrivning, om vi har någon, procentandelen service_discount och is_active flagga. Servicerabatten ska användas för alla uppgifter som ingår i denna tjänst.
Därefter kommer vi att definiera uppgifter. Arbetsuppgifter är en del av våra tjänster. De är den grundläggande åtgärden som skulle kunna göras fristående. Varje uppgift definieras av dessa värden i task_catalog tabell:
task_name&service_catalog_id– Ett namn som vi kommer att använda för att beskriva denna uppgift och tjänsten den tillhör. Detta attributpar bildar tabellens unika nyckel.description– Den eventuella ytterligare textbeskrivningen som används för att beskriva denna uppgift.ref_interval– En flagga som anger om vi ska mäta intervall för denna uppgift.ref_interval_min&ref_interval_max– Den minimala och maximala gränsen för referensområdet.describe– En flagga som anger om vi ska lägga till en textkommentar för denna uppgift.task_price– Ett aktuellt pris, utan servicerabatter, för denna uppgift.is_active– En flagga som anger om uppgiften för närvarande är aktiv (i vårt erbjudande) eller inte.
Efter kontakten med kunder ger vi erbjudanden till dem. Erbjudandet kan vara en komplett tjänst, med alla dess uppgifter eller en uppsättning uppgifter. Alla erbjudanden lagras i offer tabell. För varje erbjudande lagrar vi:
customer_id– Ett id för den relaterade kunden.contact_id– Ett id för den relaterade kontakten, om det fanns någon. Detta kan vara viktig information för att avgöra hur många erbjudanden som kom som ett resultat av tidigare kontakter.offer_description– En ytterligare textbeskrivning av detta erbjudande.service_catalog_id– Ett ID för den tjänst vi har erbjudit kunden. Detta ID kan vara NULL om vi inte har erbjudit honom en komplett tjänst, men en eller flera uppgifter som inte är en del av tjänsten.service_discount– Tjänsterabatten just nu erbjudandet skapades. Detta värde ska innehålla NULL om erbjudandet inte var relaterat till tjänsten.offer_price– Ett slutpris på det erbjudandet. Det kan beräknas som summan av alla uppgifter minus servicerabatt.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Den sista tabellen i detta ämnesområde är offer_task tabell. För varje erbjudande, oavsett om vi erbjöd en komplett tjänst eller inte, lagrar vi uppsättningen av alla uppgifter. Vi måste lagra följande detaljer:
offer_id– Ett id för det relaterade erbjudandet.task_catalog_id– Ett ID för den relaterade uppgiften. Tillsammans medoffer_id, den utgör den unika/alternativa nyckeln för denna tabelltask_price– Ett aktuellt pris för den uppgiften i det ögonblick som denna post infogades.insert_ts- En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Avsnitt 5:Besök
Det sista ämnesområdet i vår modell används för att lagra faktiska kundbesök på vår verkstad. Även om det ser komplicerat ut, har vi bara två nya tabeller här, visit och visit_task .
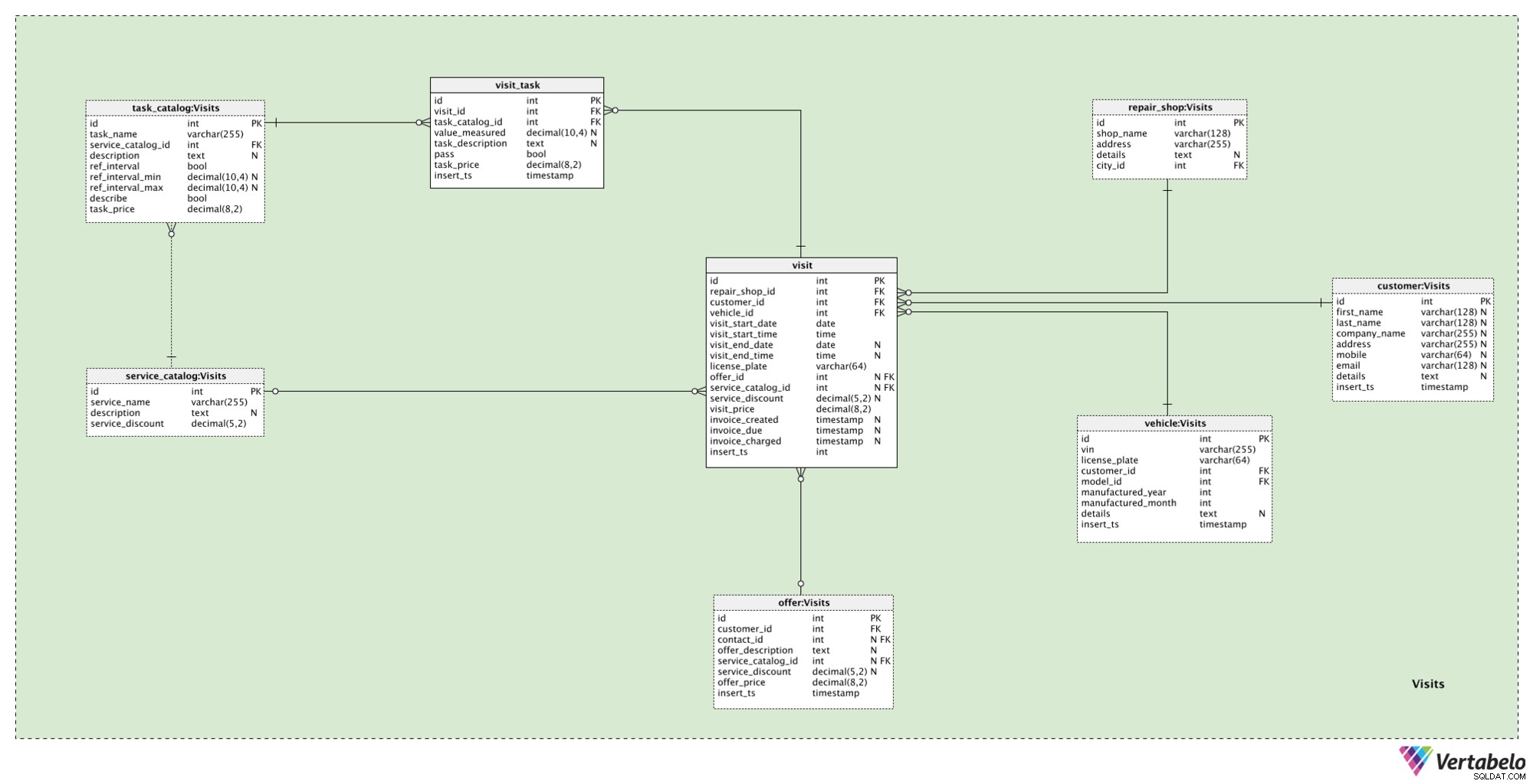
När kunden accepterar vårt erbjudande eller bara kommer till vår butik, behandlar vi det som ett visit . För varje sådan händelse lagrar vi följande information:
repair_shop_id– En referens till den relaterade verkstaden.customer_id– En referens till kunden som detta besök är relaterat till.vehicle_id– En hänvisning till fordonet detta besök är relaterat till.visit_start_date– Ett startdatum för besöket (planerat).visit_start_time– En starttid för besöket (planerad).visit_end_date– Ett startdatum för besöket (faktiskt). Detta värde ska ställas in när besöket faktiskt slutar.visit_end_time– Ett besöks starttid (faktisk). Detta värde ska ställas in när besöket faktiskt slutar.license_plate– Ett registreringsnummer när besöket inträffade. Observera att registreringsskyltar ändras under tiden.offer_id– Ett id för det relaterade erbjudandet, om något.service_catalog_id– Ett ID för den relaterade tjänsten, om någon.service_discount– Ett procentuellt rabattbelopp i det ögonblick som denna post lades till och om vi erbjuder en komplett tjänst.visit_price– Ett totalpris som en kund ska betala för det besöket.invoice_created– En tidsstämpel när fakturan genererades.invoice_due– En tidsstämpel när fakturan förföll.invoice_charged– En tidsstämpel när fakturan debiterades.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Den sista tabellen i vår modell är visit_task tabell. Det här är platsen för att lagra alla uppgifter som faktiskt var en del av det besöket. För varje post här lagrar vi följande värden:
visit_id– En referens till det besöket.task_catalog_id– En referens till den relaterade uppgiftenvalue_measured– Ett värde som mättes under denna uppgift, om uppgiften krävde mätning.task_description– En beskrivning relaterad till den uppgiften om uppgiften krävde en beskrivning.pass– En flagga som anger om denna uppgift var i det förväntade intervallet eller inte.task_price– Ett faktiskt pris för den uppgiften för tillfället infogat i den här tabellen.insert_ts– En tidsstämpel som anger det ögonblick då denna post infogades i tabellen.
Även om den här modellen är ganska förenklad innehåller den alla nödvändiga element som du behöver för att bygga en komplett modell runt den. Delar som kräver förbättringar är definitivt material som används och betalningshantering. Skulle du lägga till något mer till den här modellen?