I den första delen av den här bloggen täckte vi en implementeringsgenomgång av MySQL InnoDB Cluster med ett exempel på hur applikationerna kan ansluta till klustret via en dedikerad läs/skrivport.
I den här operationsgenomgången kommer vi att visa exempel på hur man övervakar, hanterar och skalar InnoDB-klustret som en del av den pågående klusterunderhållsverksamheten. Vi kommer att använda samma kluster som vi distribuerade i den första delen av bloggen. Följande diagram visar vår arkitektur:
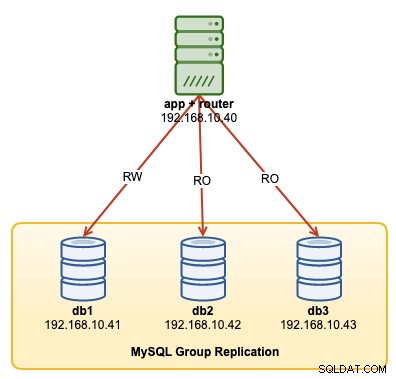
Vi har en MySQL-gruppreplikering med tre noder och en applikationsserver som körs med MySQL-router. Alla servrar körs på Ubuntu 18.04 Bionic.
MySQL InnoDB Cluster Command Options
Innan vi går vidare med några exempel och förklaringar är det bra att veta att du kan få en förklaring av varje funktion i MySQL-kluster för klusterkomponent genom att använda hjälp()-funktionen, som visas nedan:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.help()Följande lista visar tillgängliga funktioner på MySQL Shell 8.0.18, för MySQL Community Server 8.0.18:
- addInstance(instance[, options])- Lägger till en instans i klustret.
- checkInstanceState(instance)- Verifierar instansens gtid-tillstånd i förhållande till klustret.
- describe()- Beskriv strukturen för klustret.
- disconnect()- Kopplar bort alla interna sessioner som används av klusterobjektet.
- dissolve([options])- Inaktiverar replikering och avregistrerar ReplicaSets från klustret.
- forceQuorumUsingPartitionOf(instans[, lösenord])- Återställer klustret från kvorumförlust.
- getName()- Hämtar namnet på klustret.
- hjälp([medlem])- Ger hjälp om den här klassen och dess medlemmar
- options([options])- Listar klusterkonfigurationsalternativen.
- rejoinInstance(instance[, options])- Återansluter en instans till klustret.
- removeInstance(instance[, options])- Tar bort en instans från klustret.
- skanna om([options])- Sökar om klustret.
- resetRecoveryAccountsPassword(options)- Återställ lösenordet för klustrets återställningskonton.
- setInstanceOption(instans, alternativ, värde)- Ändrar värdet på ett konfigurationsalternativ i en klustermedlem.
- setOption(option, value)- Ändrar värdet på ett konfigurationsalternativ för hela klustret.
- setPrimaryInstance(instance) – Väljer en specifik klustermedlem som ny primär.
- status([options])- Beskriv klustrets status.
- switchToMultiPrimaryMode()- Växlar klustret till multiprimärt läge.
- switchToSinglePrimaryMode([instans])- Växlar klustret till enkelprimärt läge.
Vi kommer att undersöka de flesta funktioner som är tillgängliga för att hjälpa oss att övervaka, hantera och skala klustret.
Övervaka MySQL InnoDB Cluster Operations
Klusterstatus
För att kontrollera klusterstatusen, använd först MySQL-skalets kommandorad och anslut sedan som exempel@sqldat.com{one-of-the-db-nodes}:
$ mysqlsh
MySQL|localhost:3306 ssl|JS> shell.connect("example@sqldat.com:3306");Skapa sedan ett objekt som heter "kluster" och förklara det som "dba" globalt objekt som ger åtkomst till InnoDB-klusteradministrationsfunktioner med AdminAPI (kolla in MySQL Shell API-dokument):
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster();
<Cluster:my_innodb_cluster>Sedan kan vi använda objektnamnet för att anropa API-funktionerna för "dba"-objekt:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db1:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.061918",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": "00:00:09.447804",
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db1:3306"
}Utmatningen är ganska lång men vi kan filtrera bort den genom att använda kartstrukturen. Om vi till exempel bara vill se replikeringsfördröjningen för db3 kan vi göra så här:
MySQL|db1:3306 ssl|JS> cluster.status().defaultReplicaSet.topology["db3:3306"].replicationLag
00:00:09.447804Observera att replikeringsfördröjning är något som kommer att hända i gruppreplikering, beroende på skrivintensiteten för den primära medlemmen i replikuppsättningen och variablerna group_replication_flow_control_*. Vi kommer inte att täcka detta ämne i detalj här. Kolla in det här blogginlägget för att förstå mer om gruppreplikeringsprestanda och flödeskontroll.
En annan liknande funktion är funktionen describe(), men den här är lite enklare. Den beskriver strukturen för klustret inklusive all dess information, ReplicaSets och Instances:
MySQL|db1:3306 ssl|JS> cluster.describe(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"topology": [
{
"address": "db1:3306",
"label": "db1:3306",
"role": "HA"
},
{
"address": "db2:3306",
"label": "db2:3306",
"role": "HA"
},
{
"address": "db3:3306",
"label": "db3:3306",
"role": "HA"
}
],
"topologyMode": "Single-Primary"
}
}På liknande sätt kan vi filtrera JSON-utdata med hjälp av kartstruktur:
MySQL|db1:3306 ssl|JS> cluster.describe().defaultReplicaSet.topologyMode
Single-PrimaryNär den primära noden gick ner (i det här fallet är db1), returnerade utgången följande:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK_NO_TOLERANCE",
"statusText": "Cluster is NOT tolerant to any failures. 1 member is not active",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "n/a",
"readReplicas": {},
"role": "HA",
"shellConnectError": "MySQL Error 2013 (HY000): Lost connection to MySQL server at 'reading initial communication packet', system error: 104",
"status": "(MISSING)"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Var uppmärksam på statusen OK_NO_TOLERANCE, där klustret fortfarande är igång men det kan inte tolerera fler fel efter att en nod över tre inte är tillgänglig. Den primära rollen har tagits över av db2 automatiskt, och databasanslutningarna från programmet kommer att omdirigeras till rätt nod om de ansluter via MySQL Router. När db1 är online igen bör vi se följande status:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"primary": "db2:3306",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/O",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Single-Primary"
},
"groupInformationSourceMember": "db2:3306"
}Det visar att db1 nu är tillgängligt men fungerade som sekundärt med skrivskyddat aktiverat. Den primära rollen är fortfarande tilldelad till db2 tills något går fel till noden, där den automatiskt misslyckas till nästa tillgängliga nod.
Kontrollera instansstatus
Vi kan kontrollera tillståndet för en MySQL-nod innan vi planerar att lägga till den i klustret genom att använda funktionen checkInstanceState(). Den analyserar instansens exekverade GTID med exekverade/rensade GTID på klustret för att avgöra om instansen är giltig för klustret.
Följande visar instanstillståndet för db3 när det var i fristående läge, före en del av klustret:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' is a standalone instance but is part of a different InnoDB Cluster (metadata exists, instance does not belong to that metadata, and Group Replication is not active).Om noden redan är en del av klustret bör du få följande:
MySQL|db1:3306 ssl|JS> cluster.checkInstanceState("db3:3306")
Cluster.checkInstanceState: The instance 'db3:3306' already belongs to the ReplicaSet: 'default'.Övervaka alla "Frågbara" tillstånd
Med MySQL Shell kan vi nu använda det inbyggda kommandot \show and \watch för att övervaka alla administrativa frågor i realtid. Till exempel kan vi få realtidsvärdet för trådar som är anslutna genom att använda:
MySQL|db1:3306 ssl|JS> \show query SHOW STATUS LIKE '%thread%';Eller hämta den aktuella MySQL-proceslistan:
MySQL|db1:3306 ssl|JS> \show query SHOW FULL PROCESSLISTVi kan sedan använda kommandot \watch för att köra en rapport på samma sätt som kommandot \show, men det uppdaterar resultaten med jämna mellanrum tills du avbryter kommandot med Ctrl + C. Som visas i följande exempel:
MySQL|db1:3306 ssl|JS> \watch query SHOW STATUS LIKE '%thread%';
MySQL|db1:3306 ssl|JS> \watch query --interval=1 SHOW FULL PROCESSLISTStandarduppdateringsintervallet är 2 sekunder. Du kan ändra värdet genom att använda flaggan --interval och ange ett värde från 0,1 upp till 86400.
MySQL InnoDB Cluster Management Operations
Primär övergång
Primär instans är den nod som kan betraktas som ledare i en replikeringsgrupp, som har förmågan att utföra läs- och skrivoperationer. Endast en primär instans per kluster tillåts i enkelprimärt topologiläge. Denna topologi är också känd som replikuppsättning och är det rekommenderade topologiläget för gruppreplikering med skydd mot låsningskonflikter.
För att utföra primär instansbyte, logga in på en av databasnoderna som clusteradmin-användare och ange databasnoden som du vill främja genom att använda funktionen setPrimaryInstance():
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster.setPrimaryInstance("db1:3306");
Setting instance 'db1:3306' as the primary instance of cluster 'my_innodb_cluster'...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' remains SECONDARY.
Instance 'db1:3306' was switched from SECONDARY to PRIMARY.
WARNING: The cluster internal session is not the primary member anymore. For cluster management operations please obtain a fresh cluster handle using <Dba>.getCluster().
The instance 'db1:3306' was successfully elected as primary.Vi marknadsförde just db1 som den nya primära komponenten, och ersatte db2 medan db3 förblir den sekundära noden.
Stänga av klustret
Det bästa sättet att stänga av klustret på ett elegant sätt genom att först stoppa MySQL Router-tjänsten (om den körs) på applikationsservern:
$ myrouter/stop.shOvanstående steg ger klusterskydd mot oavsiktliga skrivningar av applikationerna. Stäng sedan av en databasnod i taget med standardkommandot MySQL stopp, eller utför systemets avstängning som du vill:
$ systemctl stop mysqlStarta klustret efter en avstängning
Om ditt kluster lider av ett fullständigt avbrott eller om du vill starta klustret efter en ren avstängning, kan du se till att det är omkonfigurerat korrekt med dba.rebootClusterFromCompleteOutage()-funktionen. Det tar helt enkelt tillbaka ett kluster ONLINE när alla medlemmar är OFFLINE. I händelse av att ett kluster har stoppats helt måste instanserna startas och först då kan klustret startas.
Se till att alla MySQL-servrar startas och körs. På varje databasnod, se om mysqld-processen körs:
$ ps -ef | grep -i mysqlVälj sedan en databasserver som primär nod och anslut till den via MySQL-skal:
MySQL|JS> shell.connect("example@sqldat.com:3306");Kör följande kommando från den värden för att starta dem:
MySQL|db1:3306 ssl|JS> cluster = dba.rebootClusterFromCompleteOutage()Du kommer att presenteras med följande frågor:
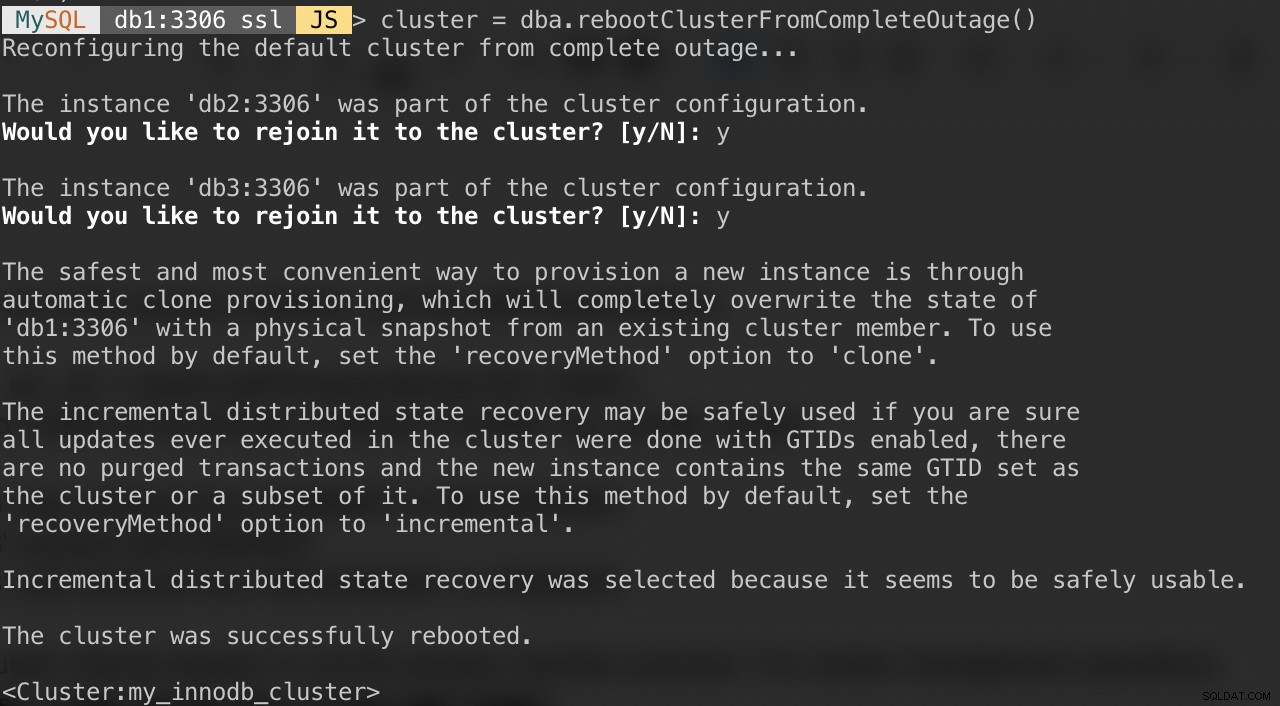
När ovanstående är klart kan du verifiera klusterstatusen:
MySQL|db1:3306 ssl|JS> cluster.status()Vid denna punkt är db1 den primära noden och skrivaren. Resten kommer att vara de sekundära medlemmarna. Om du vill starta klustret med db2 eller db3 som primär kan du använda funktionen shell.connect() för att ansluta till motsvarande nod och utföra rebootClusterFromCompleteOutage() från just den noden.
Du kan sedan starta MySQL Router-tjänsten (om den inte har startat) och låta applikationen ansluta till klustret igen.
Ställa in medlems- och klusteralternativ
För att få de klusteromfattande alternativen, kör helt enkelt:
MySQL|db1:3306 ssl|JS> cluster.options()Ovanstående listar de globala alternativen för replikuppsättningen och även individuella alternativ per medlem i klustret. Den här funktionen ändrar ett InnoDB-klusterkonfigurationsalternativ i alla medlemmar i klustret. De alternativ som stöds är:
- clusterName:strängvärde för att definiera klusternamnet.
- exitStateAction:strängvärde som indikerar gruppreplikeringens utgångslägesåtgärd.
- memberWeight:heltalsvärde med en procentuell vikt för automatiskt primärval vid failover.
- failoverConsistency:strängvärde som anger konsistensgarantierna som klustret tillhandahåller.
- konsistens: strängvärde som anger konsistensgarantierna som klustret tillhandahåller.
- expelTimeout:heltalsvärde för att definiera tidsperioden i sekunder som klustermedlemmar ska vänta på en icke-svarande medlem innan de kastar den från klustret.
- autoRejoinTries:heltalsvärde för att definiera antalet gånger en instans kommer att försöka gå med i klustret igen efter att ha blivit utvisad.
- disableClone:booleskt värde som används för att inaktivera klonanvändningen i klustret.
I likhet med andra funktioner kan utdata filtreras i kartstruktur. Följande kommando visar bara alternativen för db2:
MySQL|db1:3306 ssl|JS> cluster.options().defaultReplicaSet.topology["db2:3306"]Du kan också få listan ovan genom att använda help()-funktionen:
MySQL|db1:3306 ssl|JS> cluster.help("setOption")Följande kommando visar ett exempel för att ställa in ett alternativ som heter memberWeight till 60 (från 50) för alla medlemmar:
MySQL|db1:3306 ssl|JS> cluster.setOption("memberWeight", 60)
Setting the value of 'memberWeight' to '60' in all ReplicaSet members ...
Successfully set the value of 'memberWeight' to '60' in the 'default' ReplicaSet.Vi kan också utföra konfigurationshantering automatiskt via MySQL Shell genom att använda funktionen setInstanceOption() och skicka databasvärden, alternativnamnet och värdet därefter:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.setInstanceOption("db1:3306", "memberWeight", 90)De alternativ som stöds är:
- exitStateAction: strängvärde som indikerar åtgärden för gruppreplikeringens utgångsläge.
- memberWeight:heltalsvärde med en procentuell vikt för automatiskt primärval vid failover.
- autoRejoinTries:heltalsvärde för att definiera antalet gånger en instans kommer att försöka gå med i klustret igen efter att ha blivit utvisad.
- märk en strängidentifierare för instansen.
Växla till Multi-Primary/Single-Primary Mode
Som standard är InnoDB Cluster konfigurerat med en primär, endast en medlem som kan utföra läsning och skrivning vid en given tidpunkt. Detta är det säkraste och rekommenderade sättet att köra klustret och passar för de flesta arbetsbelastningar.
Men om applikationslogiken kan hantera distribuerade skrivningar är det förmodligen en bra idé att byta till multiprimärt läge, där alla medlemmar i klustret kan bearbeta läsningar och skrivningar samtidigt. För att växla från enkelprimärt till multiprimärt läge, använd helt enkelt switchToMultiPrimaryMode()-funktionen:
MySQL|db1:3306 ssl|JS> cluster.switchToMultiPrimaryMode()
Switching cluster 'my_innodb_cluster' to Multi-Primary mode...
Instance 'db2:3306' was switched from SECONDARY to PRIMARY.
Instance 'db3:3306' was switched from SECONDARY to PRIMARY.
Instance 'db1:3306' remains PRIMARY.
The cluster successfully switched to Multi-Primary mode.Verifiera med:
MySQL|db1:3306 ssl|JS> cluster.status(){
"clusterName": "my_innodb_cluster",
"defaultReplicaSet": {
"name": "default",
"ssl": "REQUIRED",
"status": "OK",
"statusText": "Cluster is ONLINE and can tolerate up to ONE failure.",
"topology": {
"db1:3306": {
"address": "db1:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db2:3306": {
"address": "db2:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
},
"db3:3306": {
"address": "db3:3306",
"mode": "R/W",
"readReplicas": {},
"replicationLag": null,
"role": "HA",
"status": "ONLINE",
"version": "8.0.18"
}
},
"topologyMode": "Multi-Primary"
},
"groupInformationSourceMember": "db1:3306"
}I multiprimärt läge är alla noder primära och kan bearbeta läsningar och skrivningar. När du skickar en ny anslutning via MySQL Router på single-writer-porten (6446), kommer anslutningen att skickas till endast en nod, som i detta exempel, db1:
(app-server)$ for i in {1..3}; do mysql -usbtest -p -h192.168.10.40 -P6446 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Om applikationen ansluter till multi-writer-porten (6447), kommer anslutningen att lastbalanseras via round robin-algoritm till alla medlemmar:
(app-server)$ for i in {1..3}; do mysql -usbtest -ppassword -h192.168.10.40 -P6447 -e 'select @@hostname, @@read_only, @@super_read_only'; done
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db2 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db3 | 0 | 0 |
+------------+-------------+-------------------+
+------------+-------------+-------------------+
| @@hostname | @@read_only | @@super_read_only |
+------------+-------------+-------------------+
| db1 | 0 | 0 |
+------------+-------------+-------------------+Som du kan se från utgången ovan kan alla noder bearbeta läsningar och skrivningar med read_only =OFF. Du kan distribuera säkra skrivningar till alla medlemmar genom att ansluta till multi-writer-porten (6447) och skicka de motstridiga eller tunga skrivningarna till single-writer-porten (6446).
För att växla tillbaka till det enkla primära läget, använd switchToSinglePrimaryMode()-funktionen och ange en medlem som primär nod. I det här exemplet valde vi db1:
MySQL|db1:3306 ssl|JS> cluster.switchToSinglePrimaryMode("db1:3306");
Switching cluster 'my_innodb_cluster' to Single-Primary mode...
Instance 'db2:3306' was switched from PRIMARY to SECONDARY.
Instance 'db3:3306' was switched from PRIMARY to SECONDARY.
Instance 'db1:3306' remains PRIMARY.
WARNING: Existing connections that expected a R/W connection must be disconnected, i.e. instances that became SECONDARY.
The cluster successfully switched to Single-Primary mode.Vid denna tidpunkt är db1 nu den primära noden konfigurerad med skrivskyddad inaktiverad och resten kommer att konfigureras som sekundär med skrivskyddad aktiverad.
MySQL InnoDB Cluster Scaling Operations
Skala upp (lägga till en ny DB-nod)
När du lägger till en ny instans måste en nod tillhandahållas först innan den tillåts delta i replikeringsgruppen. Provisioneringsprocessen kommer att hanteras automatiskt av MySQL. Du kan också kontrollera instanstillståndet först om noden är giltig för att gå med i klustret genom att använda funktionen checkInstanceState() som tidigare förklarats.
För att lägga till en ny DB-nod, använd funktionen addInstances() och ange värden:
MySQL|db1:3306 ssl|JS> cluster.addInstance("db3:3306")Följande är vad du skulle få när du lägger till en ny instans:
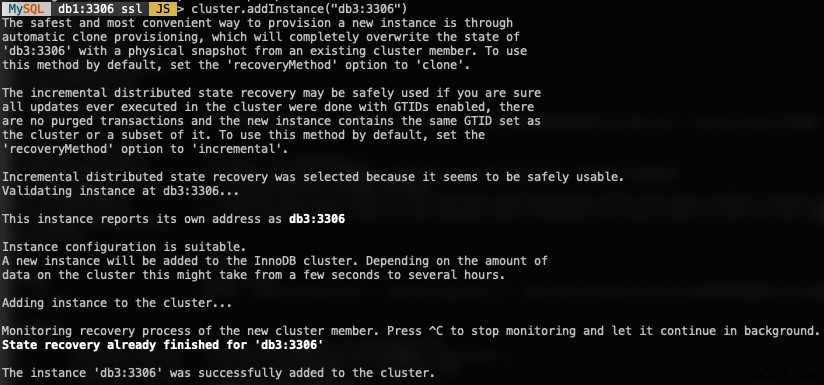
Verifiera den nya klusterstorleken med:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router kommer automatiskt att inkludera den tillagda noden, db3 i lastbalanseringsuppsättningen.
Skala ner (ta bort en nod)
För att ta bort en nod, anslut till någon av DB-noderna förutom den som vi ska ta bort och använd funktionen removeInstance() med databasinstansens namn:
MySQL|db1:3306 ssl|JS> shell.connect("example@sqldat.com:3306");
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
MySQL|db1:3306 ssl|JS> cluster.removeInstance("db3:3306")Följande är vad du skulle få när du tar bort en instans:
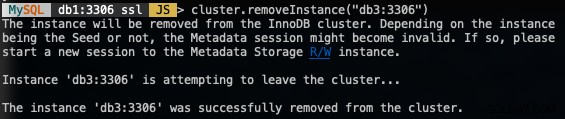
Verifiera den nya klusterstorleken med:
MySQL|db1:3306 ssl|JS> cluster.status() //or cluster.describe()MySQL Router kommer automatiskt att utesluta den borttagna noden, db3 från lastbalanseringsuppsättningen.
Lägga till en ny replikeringsslav
Vi kan skala ut InnoDB-klustret med asynkrona replikeringsslavreplikat från vilken som helst av klusternoderna. En slav är löst kopplad till klustret och kommer att kunna hantera en tung belastning utan att påverka klustrets prestanda. Slaven kan också vara en levande kopia av databasen för katastrofåterställning. I multiprimärt läge kan du använda slaven som den dedikerade MySQL-skrivskyddade processorn för att skala ut läsarbetsbelastningen, utföra analysoperationer eller som en dedikerad backupserver.
På slavservern, ladda ner det senaste APT-konfigurationspaketet, installera det (välj MySQL 8.0 i konfigurationsguiden), installera APT-nyckeln, uppdatera repolist och installera MySQL-servern.
$ wget https://repo.mysql.com/apt/ubuntu/pool/mysql-apt-config/m/mysql-apt-config/mysql-apt-config_0.8.14-1_all.deb
$ dpkg -i mysql-apt-config_0.8.14-1_all.deb
$ apt-key adv --recv-keys --keyserver ha.pool.sks-keyservers.net 5072E1F5
$ apt-get update
$ apt-get -y install mysql-server mysql-shellÄndra MySQL-konfigurationsfilen för att förbereda servern för replikeringsslav. Öppna konfigurationsfilen via textredigerare:
$ vim /etc/mysql/mysql.conf.d/mysqld.cnfOch lägg till följande rader:
server-id = 1044 # must be unique across all nodes
gtid-mode = ON
enforce-gtid-consistency = ON
log-slave-updates = OFF
read-only = ON
super-read-only = ON
expire-logs-days = 7Starta om MySQL-servern på slaven för att tillämpa ändringarna:
$ systemctl restart mysqlPå en av InnoDB Cluster-servrarna (vi valde db3), skapa en replikeringsslavanvändare och följt av en fullständig MySQL-dump:
$ mysql -uroot -p
mysql> CREATE USER 'repl_user'@'192.168.0.44' IDENTIFIED BY 'password';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.0.44';
mysql> exit
$ mysqldump -uroot -p --single-transaction --master-data=1 --all-databases --triggers --routines --events > dump.sqlÖverför dumpfilen från db3 till slaven:
$ scp dump.sql example@sqldat.com:~Och utför återställningen på slaven:
$ mysql -uroot -p < dump.sqlMed master-data=1 kommer vår MySQL-dumpfil automatiskt att konfigurera det GTID som körs och rensas bort. Vi kan verifiera det med följande uttalande på slavservern efter återställningen:
$ mysql -uroot -p
mysql> show global variables like '%gtid_%';
+----------------------------------+----------------------------------------------+
| Variable_name | Value |
+----------------------------------+----------------------------------------------+
| binlog_gtid_simple_recovery | ON |
| enforce_gtid_consistency | ON |
| gtid_executed | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
| gtid_executed_compression_period | 1000 |
| gtid_mode | ON |
| gtid_owned | |
| gtid_purged | d4790339-0694-11ea-8fd5-02f67042125d:1-45886 |
+----------------------------------+----------------------------------------------+Ser bra ut. Vi kan sedan konfigurera replikeringslänken och starta replikeringstrådarna på slaven:
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.10.43', MASTER_USER = 'repl_user', MASTER_PASSWORD = 'password', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Verifiera replikeringstillståndet och se till att följande status returnerar 'Ja':
mysql> show slave status\G
...
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
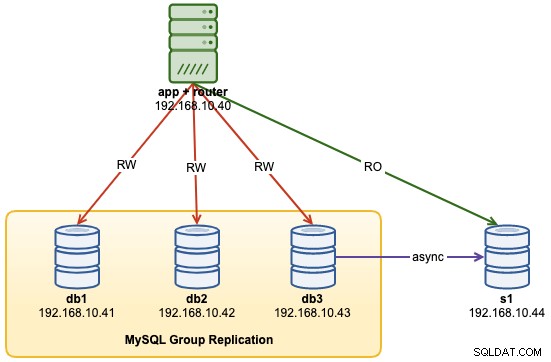
...Vid det här laget ser vår arkitektur nu ut så här:
Vanliga problem med MySQL InnoDB-kluster
Minnesutmattning
När vi använde MySQL Shell med MySQL 8.0 fick vi ständigt följande fel när instanserna konfigurerades med 1 GB RAM:
Can't create a new thread (errno 11); if you are not out of available memory, you can consult the manual for a possible OS-dependent bug (MySQL Error 1135)Att uppgradera varje värds RAM till 2 GB RAM löste problemet. Tydligen kräver MySQL 8.0-komponenter mer RAM-minne för att fungera effektivt.
Förlorad anslutning till MySQL-server
In case the primary node goes down, you would probably see the "lost connection to MySQL server error" when trying to query something on the current session:
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: Lost connection to MySQL server during query (MySQL Error 2013)
MySQL|db1:3306 ssl|JS> cluster.status()
Cluster.status: MySQL server has gone away (MySQL Error 2006)The solution is to re-declare the object once more:
MySQL|db1:3306 ssl|JS> cluster = dba.getCluster()
<Cluster:my_innodb_cluster>
MySQL|db1:3306 ssl|JS> cluster.status()At this point, it will connect to the newly promoted primary node to retrieve the cluster status.
Node Eviction and Expelled
In an event where communication between nodes is interrupted, the problematic node will be evicted from the cluster without any delay, which is not good if you are running on a non-stable network. This is what it looks like on db2 (the problematic node):
2019-11-14T07:07:59.344888Z 0 [ERROR] [MY-011505] [Repl] Plugin group_replication reported: 'Member was expelled from the group due to network failures, changing member status to ERROR.'
2019-11-14T07:07:59.371966Z 0 [ERROR] [MY-011712] [Repl] Plugin group_replication reported: 'The server was automatically set into read only mode after an error was detected.'Meanwhile from db1, it saw db2 was offline:
2019-11-14T07:07:44.086021Z 0 [Warning] [MY-011493] [Repl] Plugin group_replication reported: 'Member with address db2:3306 has become unreachable.'
2019-11-14T07:07:46.087216Z 0 [Warning] [MY-011499] [Repl] Plugin group_replication reported: 'Members removed from the group: db2:3306'
To tolerate a bit of delay on node eviction, we can set a higher timeout value before a node is being expelled from the group. The default value is 0, which means expel immediately. Use the setOption() function to set the expelTimeout value:
Thanks to Frédéric Descamps from Oracle who pointed this out:
Instead of relying on expelTimeout, it's recommended to set the autoRejoinTries option instead. The value represents the number of times an instance will attempt to rejoin the cluster after being expelled. A good number to start is 3, which means, the expelled member will try to rejoin the cluster for 3 times, which after an unsuccessful auto-rejoin attempt, the member waits 5 minutes before the next try.
To set this value cluster-wide, we can use the setOption() function:
MySQL|db1:3306 ssl|JS> cluster.setOption("autoRejoinTries", 3)
WARNING: Each cluster member will only proceed according to its exitStateAction if auto-rejoin fails (i.e. all retry attempts are exhausted).
Setting the value of 'autoRejoinTries' to '3' in all ReplicaSet members ...
Successfully set the value of 'autoRejoinTries' to '3' in the 'default' ReplicaSet.
Slutsats
For MySQL InnoDB Cluster, most of the management and monitoring operations can be performed directly via MySQL Shell (only available from MySQL 5.7.21 and later).