Det finns många molnleverantörer nu för tiden. De kan vara små eller stora, lokala eller med datacenter spridda över hela världen. Många av dessa molnleverantörer erbjuder någon form av en hanterad relationsdatabaslösning. De databaser som stöds tenderar att vara MySQL eller PostgreSQL eller någon annan variant av relationsdatabas.
När du designar någon form av databasinfrastruktur är det viktigt att förstå dina affärsbehov och bestämma vilken typ av tillgänglighet du skulle behöva uppnå.
I det här blogginlägget kommer vi att undersöka hög tillgänglighetsalternativ för MySQL-baserade lösningar från en av de största molnleverantörerna - Google Cloud Platform.
Distribuera en mycket tillgänglig miljö med GCP SQL-instans
För den här bloggen vill vi ha en väldigt enkel miljö - en databas, med kanske en eller två repliker. Vi vill kunna göra failover enkelt och återställa driften så snart som möjligt om mastern misslyckas. Vi kommer att använda MySQL 5.7 som valfri version och börjar med instansdistributionsguiden:
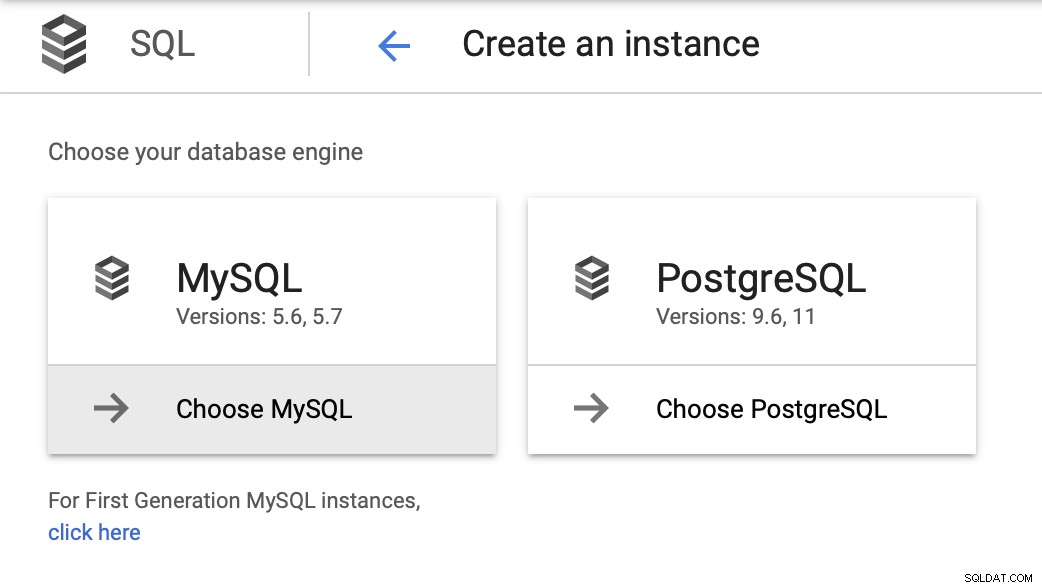
Vi måste sedan skapa root-lösenordet, ange instansnamnet och bestämma var den ska placeras:
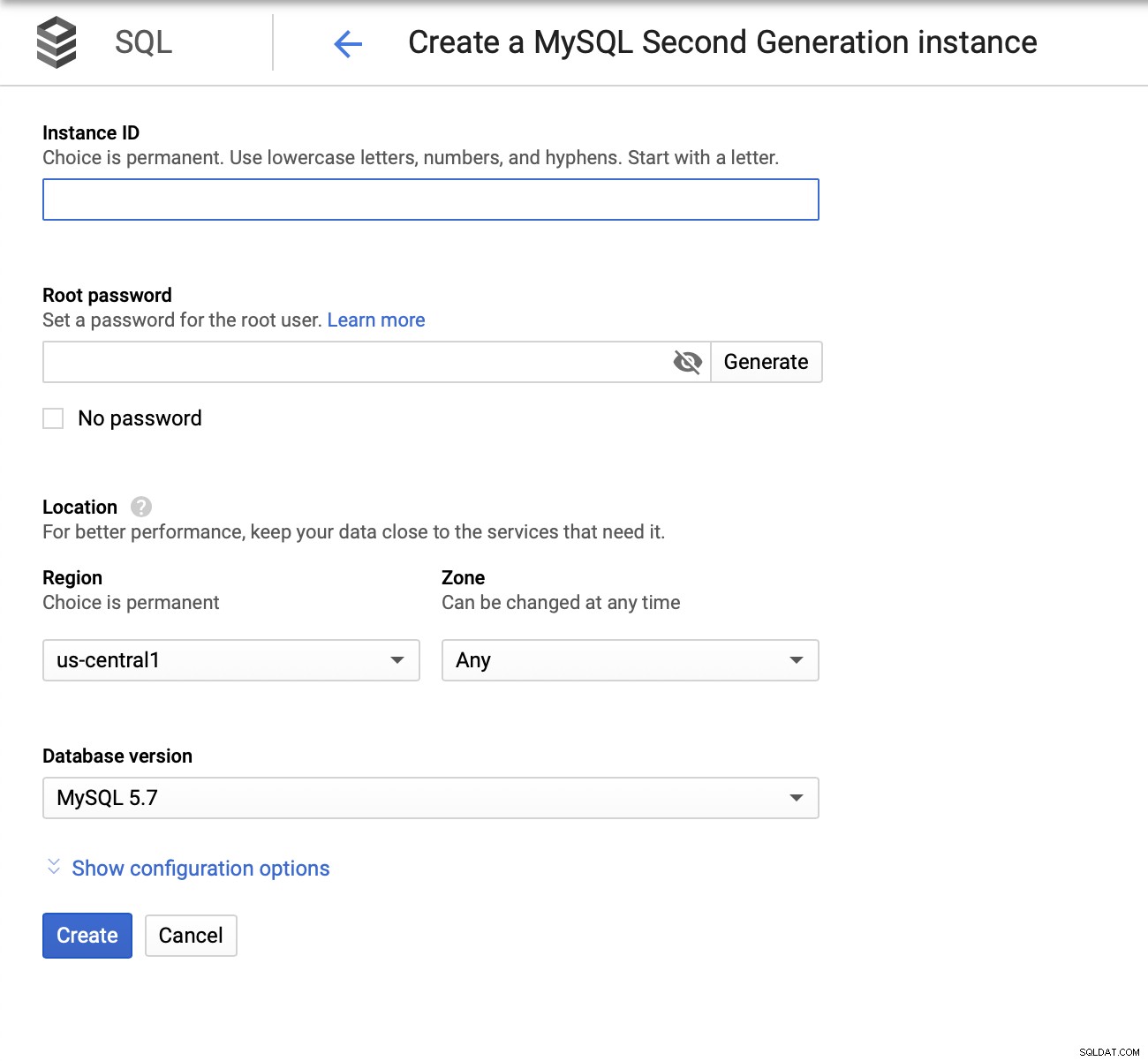
Närnäst kommer vi att undersöka konfigurationsalternativen:
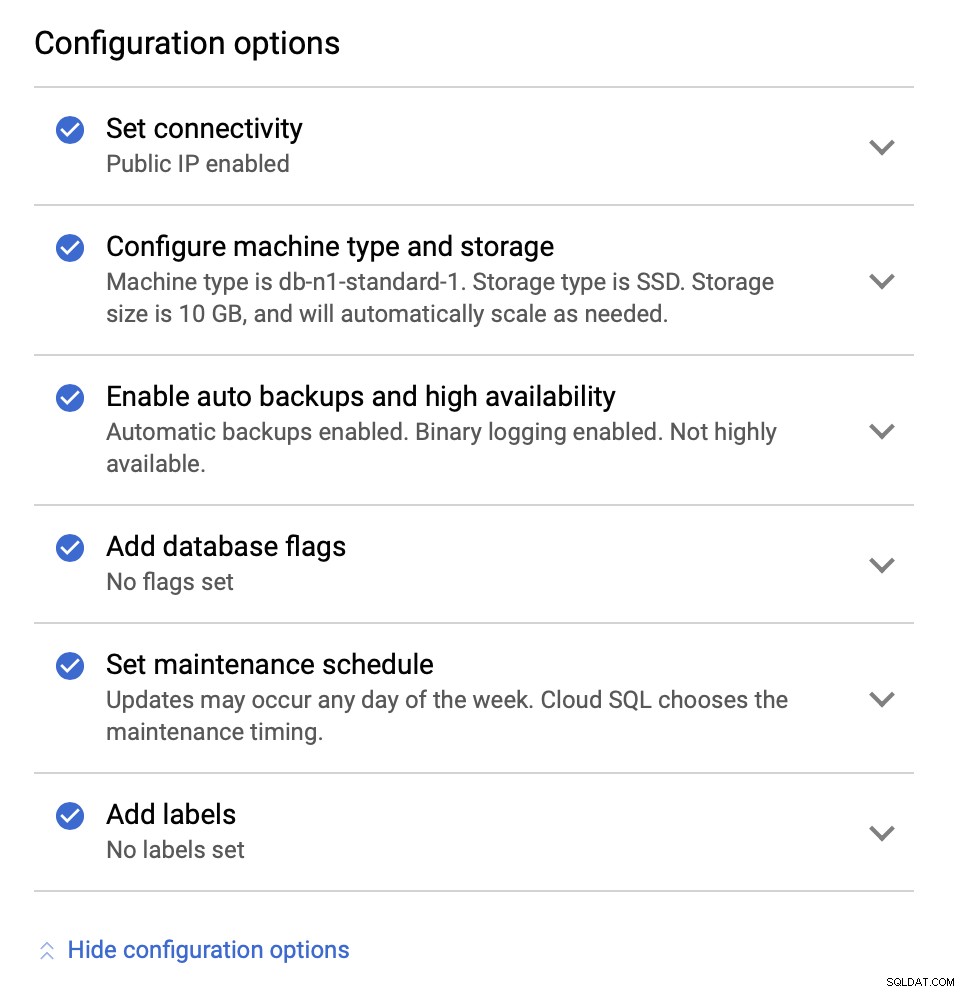
Vi kan göra ändringar när det gäller instansstorleken (vi kommer att gå med db-n1-standard-4), lagrings- och underhållsschema. Det som är viktigast för oss i den här installationen är alternativen för hög tillgänglighet:
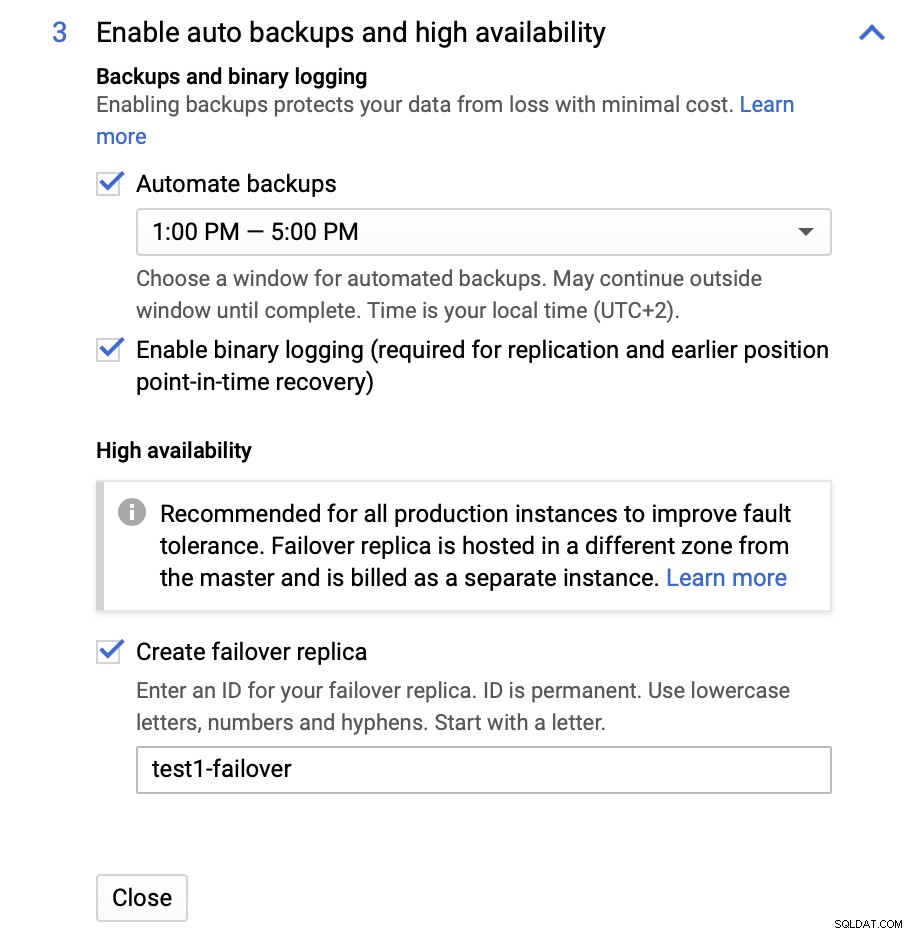
Här kan vi välja att skapa en failover-replik. Denna replik kommer att befordras till en master om den ursprungliga mastern misslyckas.

När vi har distribuerat installationen, låt oss lägga till en replikeringsslav:
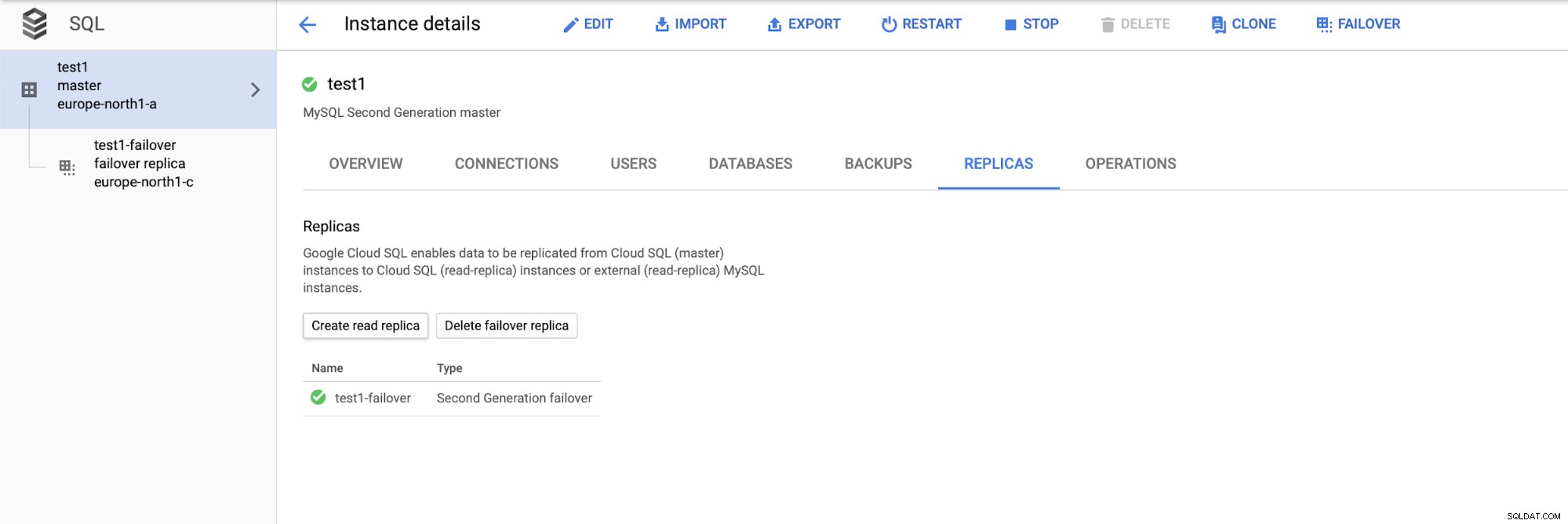
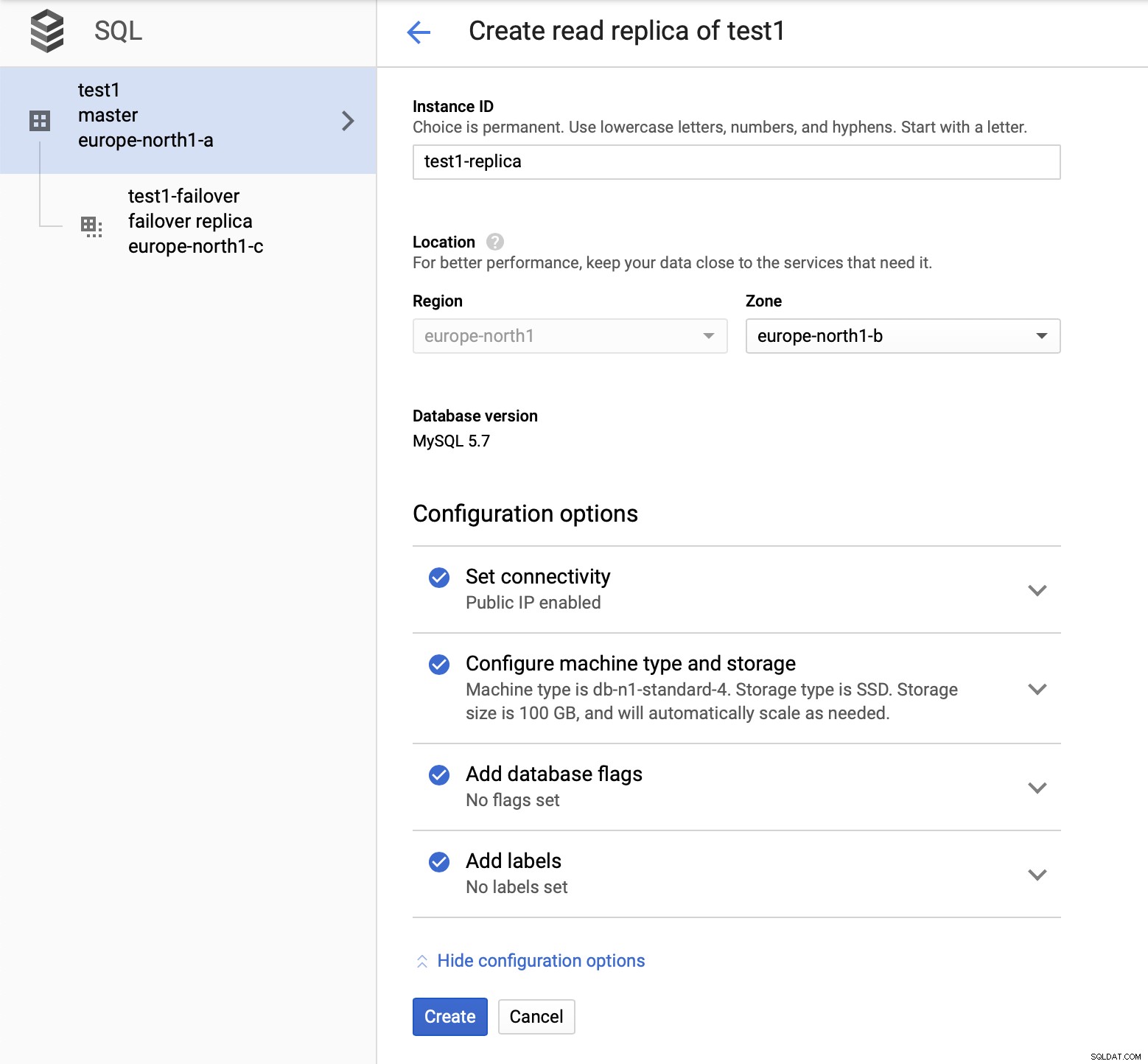
När processen att lägga till repliken är klar är vi redo för lite tester. Vi kommer att köra testarbetsbelastning med Sysbench på vår master, failover-replik och läsa replika för att se hur detta kommer att fungera. Vi kommer att köra tre instanser av Sysbench och använda slutpunkterna för alla tre typer av noder.
Då kommer vi att utlösa den manuella övergången via användargränssnittet:
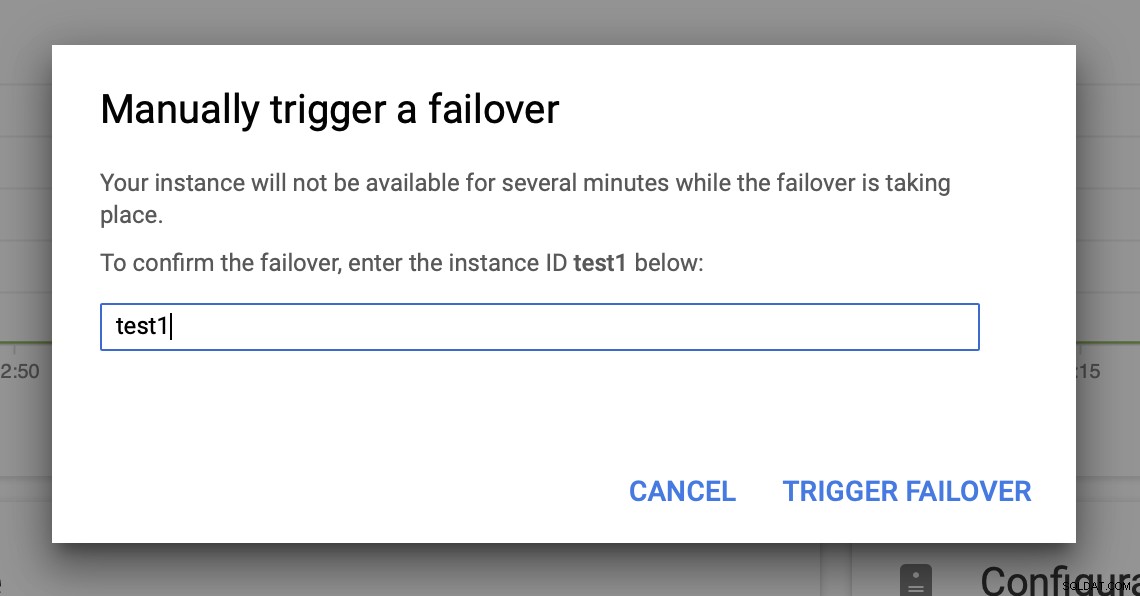
Testar du MySQL-failover på Google Cloud Platform?
Jag har kommit till denna punkt utan någon detaljerad kunskap om hur SQL-noderna i GCP fungerar. Jag hade dock vissa förväntningar baserat på tidigare MySQL-erfarenhet och vad jag har sett hos de andra molnleverantörerna. Till att börja med bör failover till failovernoden vara mycket snabb. Vad vi skulle vilja är att hålla replikeringsslavarna tillgängliga, utan att behöva byggas om. Vi skulle också vilja se hur snabbt vi kan utföra failover en andra gång (eftersom det inte är ovanligt att problemet sprider sig från en databas till en annan).
Vad vi bestämde under våra tester...
- Medan det misslyckades blev mastern tillgänglig igen efter 75 - 80 sekunder.
- Replika av fel var inte tillgänglig på 5–6 minuter.
- Läs replika var tillgänglig under failover-processen, men den blev otillgänglig i 55 - 60 sekunder efter att failover-repliken blev tillgänglig
Vad vi inte är säkra på...
Vad händer när failover-repliken inte är tillgänglig? Baserat på tiden ser det ut som att failover-repliken håller på att byggas om. Detta är vettigt, men då skulle återställningstiden vara starkt relaterad till storleken på instansen (särskilt I/O-prestanda) och storleken på datafilen.
Vad händer med läsreplika efter att failover-repliken skulle ha byggts om? Ursprungligen var den lästa repliken kopplad till mastern. När mastern misslyckades förväntar vi oss att läsreplikan ger en föråldrad vy av datasetet. När den nya mastern dyker upp bör den återansluta via replikering till instansen (som brukade vara failover-replik och som har flyttats upp till master). Det finns inget behov av en minuts stillestånd när CHANGE MASTER exekveras.
Ännu viktigare, under failover-processen finns det inget sätt att utföra en annan failover (vilket är rimligt):
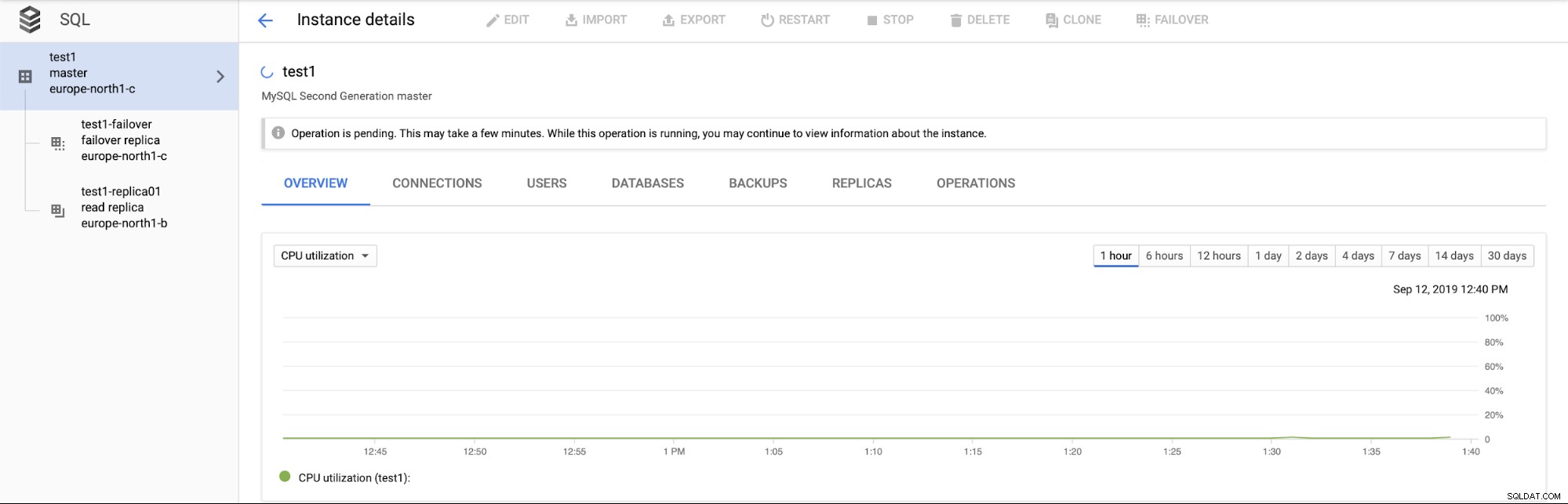
Det är inte heller möjligt att marknadsföra läsreplika (vilket inte nödvändigtvis är vettigt - vi förväntar oss att kunna marknadsföra läsrepliker när som helst).

Det är viktigt att notera att du litar på de lästa replikerna för att ge hög tillgänglighet (utan att skapa en failover-replik) är inte en gångbar lösning. Du kan marknadsföra en läsreplika för att bli en master, men ett nytt kluster skulle skapas; frikopplad från resten av noderna.
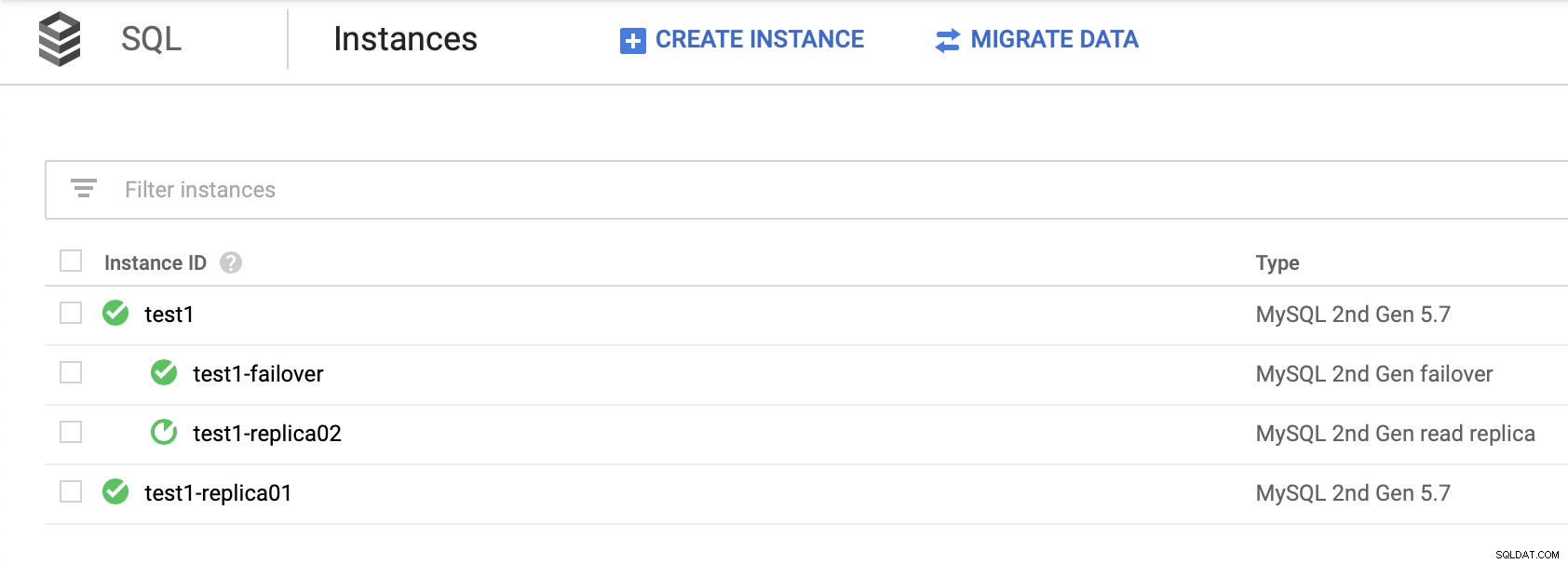
Det finns inget sätt att ta bort dina andra repliker från det nya klustret. Det enda sättet att göra detta skulle vara att skapa nya repliker, men detta är en tidskrävande process. Det är också praktiskt taget oanvändbart, vilket gör failover-repliken till det enda verkliga alternativet för hög tillgänglighet för SQL-noder i Google Cloud Platform.
Slutsats
Även om det är möjligt att skapa en mycket tillgänglig miljö för SQL-noder i GCP, kommer mastern inte att vara tillgänglig förrän efter ungefär en och en halv minut. Hela processen (inklusive återuppbyggnad av failover-repliken och några åtgärder på de lästa replikerna) tog flera minuter. Under den tiden kunde vi inte utlösa en ytterligare failover, och vi kunde inte heller marknadsföra en läsreplika.
Har vi några GCP-användare där ute? Hur uppnår du hög tillgänglighet?