Dålig frågeprestanda är det vanligaste problemet som DBA:s har att hantera. Det finns många sätt att samla in, bearbeta och analysera data relaterad till frågeprestanda - vi har täckt ett av de mest populära verktygen, pt-query-digest, i några av våra tidigare blogginlägg:
Bli en MySQL DBA-bloggserie
- Analysera din SQL-arbetsbelastning med pt-query-digest
- Deep Dive SQL Workload Analysis med pt-query-digest
När du använder ClusterControl är detta inte alltid nödvändigt. Du kan använda den information som finns tillgänglig i ClusterControl för att lösa ditt problem. I det här blogginlägget kommer vi att undersöka hur ClusterControl kan hjälpa dig att lösa problem relaterade till frågeprestanda.
Det kan hända att en förfrågan inte kan slutföras i tid. Frågan kan ha fastnat på grund av vissa låsningsproblem, den kanske inte är optimal eller inte korrekt indexerad eller så kan den vara för tung att slutföra inom en rimlig tid. Tänk på att ett par ej indexerade kopplingar lätt kan skanna miljarder rader om du har en stor produktionsdatabas. Vad som än hände använder frågan förmodligen en del av resurserna - vare sig det är CPU eller I/O för en icke-optimerad fråga eller till och med bara radlås. Dessa resurser krävs även för andra frågor och det kan på allvar sakta ner saker och ting. En av de mycket enkla men viktiga uppgifterna skulle vara att lokalisera den kränkande frågan och stoppa den.
Det görs ganska enkelt från ClusterControl-gränssnittet. Gå till fliken Query Monitor -> Running Queries-avsnittet - du bör se en utdata som liknar skärmdumpen nedan.
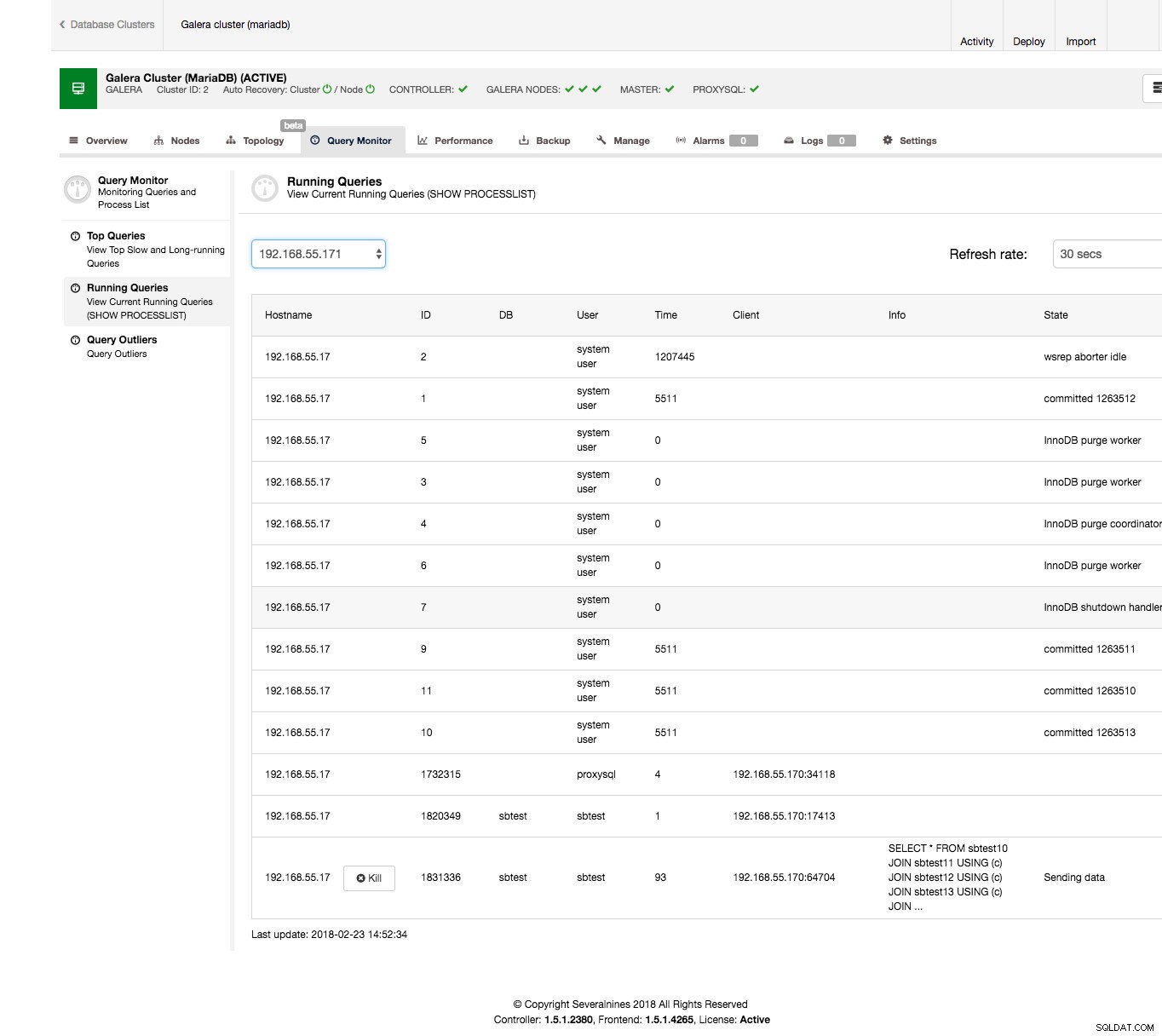
Som du kan se har vi en hög med frågor som fastnat. Vanligtvis är den stötande frågan den som tar lång tid, du kanske vill döda den. Du kanske också vill undersöka det ytterligare för att se till att du väljer rätt. I vårt fall ser vi tydligt ett VÄLJ … FÖR UPPDATERING som sammanfogar ett par tabeller och som är i tillståndet "Skicka data", vilket betyder att den bearbetar data under de senaste 90 sekunderna.
En annan typ av fråga som en DBA kan behöva besvara är - vilka frågor tar mest tid att utföra? Detta är en vanlig fråga, eftersom sådana frågor kan vara en lågt hängande frukt - de kan vara optimerbara, och ju mer exekveringstid en given fråga är ansvarig för i en hel frågemix, desto större är vinsten från dess optimering. Det är en enkel ekvation - om en fråga är ansvarig för 50 % av den totala körningstiden, kommer att göra den 10 gånger snabbare ge mycket bättre resultat än att optimera en fråga som är ansvarig för bara 1 % av den totala körningstiden.
ClusterControl kan hjälpa dig att svara på sådana frågor, men först måste vi se till att Query Monitor är aktiverad. Du kan växla Query Monitor till PÅ under sidan Query Monitor. Dessutom kan du konfigurera "Lång frågetid" och "Logga frågor som inte använder index" under Inställningar för att passa din arbetsbelastning:
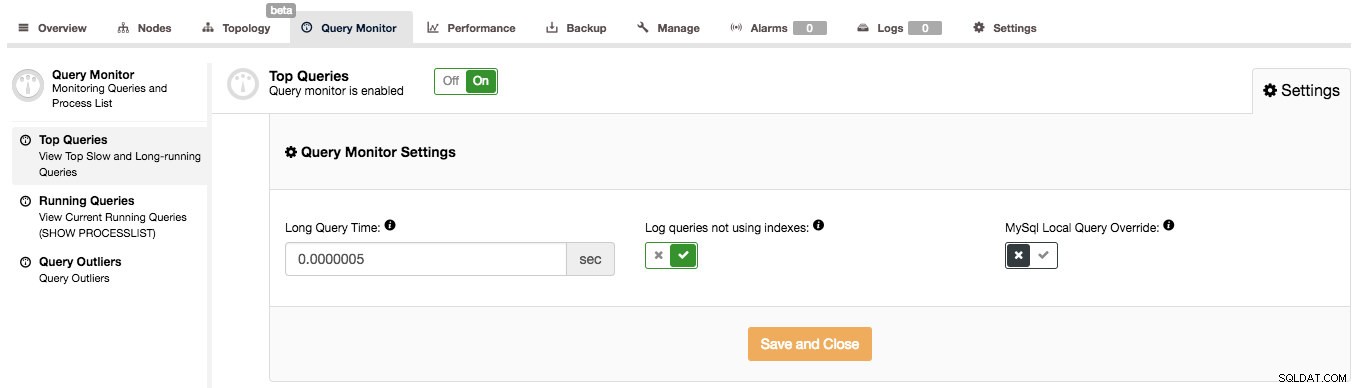
Frågeövervakaren i ClusterControl fungerar i två lägen, beroende på om du har prestandaschemat tillgängligt med nödvändiga data om de körande frågorna eller inte. Om det är tillgängligt (och detta är sant som standard i MySQL 5.6 och senare), kommer Performance Schema att användas för att samla in frågedata, vilket minimerar påverkan på systemet. Annars kommer den långsamma frågeloggen att användas och alla inställningar som är synliga i skärmdumpen ovan används. De är ganska väl förklarade i användargränssnittet, så det finns inget behov av att göra det här. När Query Monitor använder Performance Schema, används inte dessa inställningar (förutom att växla PÅ/AV Query Monitor för att aktivera/inaktivera datainsamling).
När du bekräftat att Query Monitor är aktiverad i ClusterControl kan du gå till Query Monitor -> Top Queries, där du kommer att presenteras med en skärm som liknar nedan:
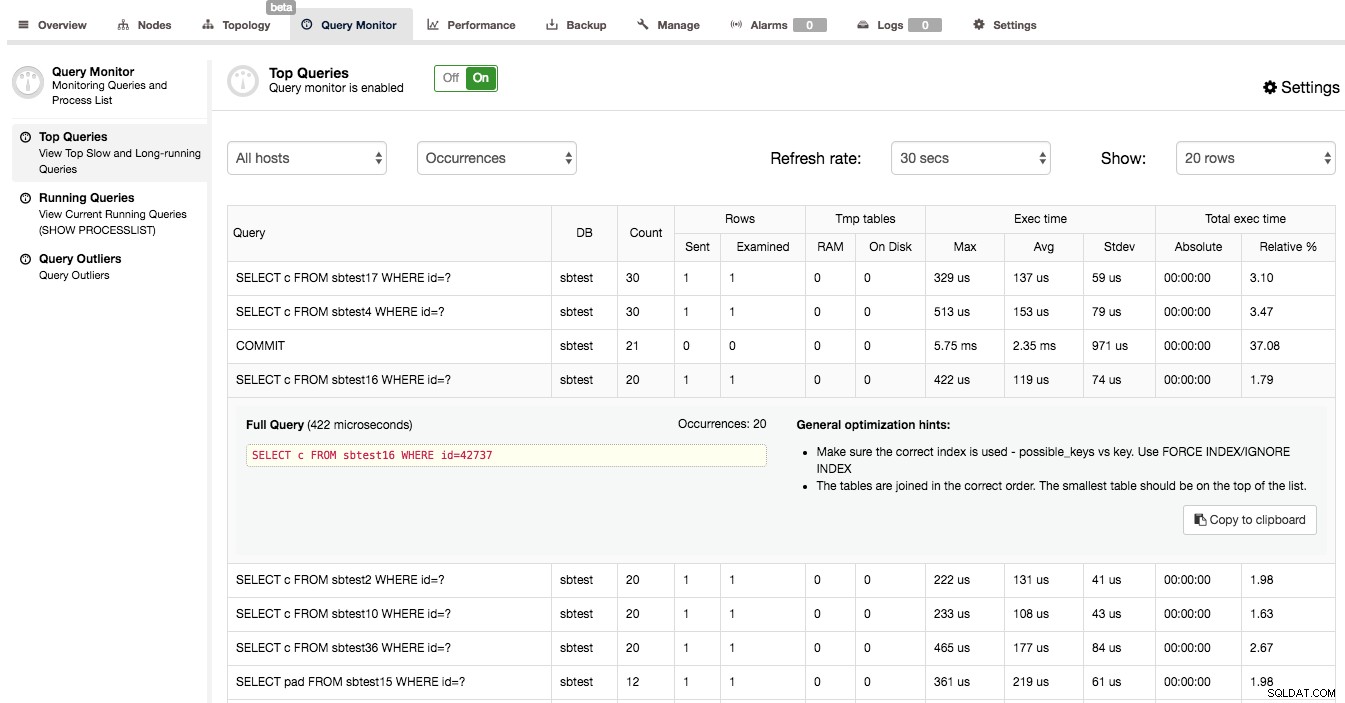
Det du kan se här är en lista över de dyraste frågorna (i termer av exekveringstid) som träffade vårt kluster. Var och en av dem har några ytterligare detaljer - hur många gånger den kördes, hur många rader som undersöktes eller skickades till klienten, hur exekveringstiden varierade, hur mycket tid klustret spenderade på att köra en viss typ av fråga. Frågor är grupperade efter frågetyp och schema.
Du kanske blir förvånad över att ta reda på att den huvudsakliga platsen där körtiden spenderas är en "COMMIT"-fråga. Egentligen är detta ganska typiskt för snabba OLTP-frågor som körs på Galera-klustret. Att genomföra en transaktion är en dyr process eftersom certifiering måste ske. Detta leder till att COMMIT är en av de mest tidskrävande frågorna i frågemixen.
När du klickar på en fråga kan du se hela frågan, maximal körningstid, antal förekomster, några allmänna optimeringstips och en EXPLAIN-utdata för den - ganska användbart för att identifiera om något är fel med den. I vårt exempel har vi markerat ett VÄLJ … FÖR UPPDATERING med ett högt antal rader undersökta. Som förväntat är denna fråga ett exempel på hemsk SQL - en JOIN som inte använder något index. Du kan se på EXPLAIN-utgången att inget index används, inte ett enda ansågs ens möjligt att använda. Inte konstigt att den här frågan påverkade vårt klusters prestanda allvarligt.
Ett annat sätt att få lite insikt i frågeprestanda är att titta på Query Monitor -> Query Outliers. Detta är i grunden en lista över frågor vars prestanda avsevärt skiljer sig från deras genomsnitt.
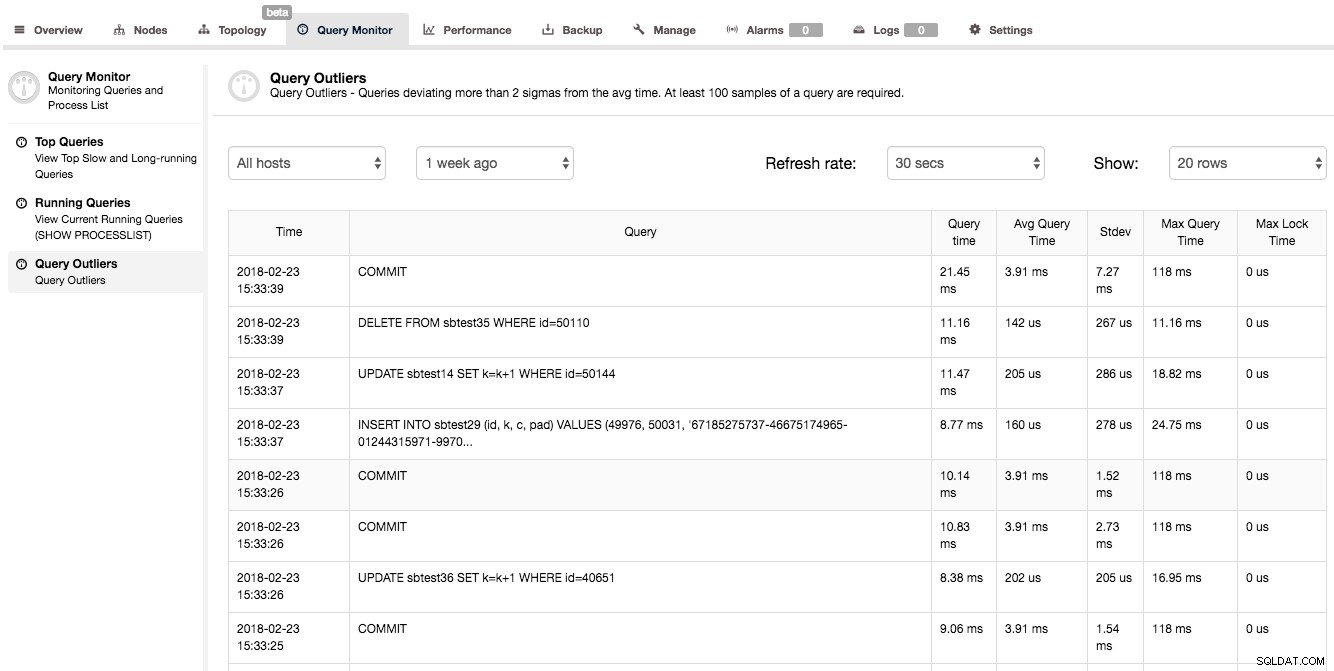
Som du kan se i skärmdumpen ovan tog den andra frågan 0,01116s (tiden visas i millisekunder) där den genomsnittliga exekveringstiden för den frågan är mycket lägre (0,000142s). Vi har också lite ytterligare statistisk information om standardavvikelse och maximal söktid. En sådan lista med frågor kan tyckas inte vara särskilt användbar - det är inte riktigt sant. När du ser en fråga på den här listan betyder det att något var annorlunda än det vanliga - frågan slutfördes inte inom ordinarie tid. Det kan vara en indikation på vissa prestandaproblem på ditt system och en signal om att du bör undersöka andra mätvärden och kontrollera om något mer hände vid den tiden.
Människor tenderar att fokusera på att uppnå maximal prestanda, glömma att det inte räcker med hög genomströmning - det måste också vara konsekvent. Användare gillar att prestandan är stabil - du kanske kan pressa ut fler transaktioner per sekund från ditt system men om det betyder att vissa transaktioner kommer att börja stanna i sekunder är det inte värt det. Att titta på frågehistogrammet i ClusterControl hjälper dig att identifiera sådana konsistensproblem i din frågemix.
Lycka till med frågeövervakning!
PS.:För att komma igång med ClusterControl, klicka här!