I ClusterControl 1.5 lade vi till stöd för MySQL NDB Cluster 7.5. I det här blogginlägget kommer vi att titta på några av funktionerna som gör ClusterControl till ett bra verktyg för att hantera MySQL NDB Cluster. Först och främst, eftersom det finns många produkter med "Cluster" i deras namn, skulle vi vilja säga några ord om själva MySQL NDB Cluster och hur det skiljer sig från andra lösningar.
MySQL NDB-kluster
MySQL NDB Cluster är ett delat-ingenting-synkront kluster för MySQL, baserat på NDB-motorn. Det är en produkt med sin egen lista över funktioner och helt annorlunda än Galera Cluster eller MySQL InnoDB Cluster. En huvudskillnad är användningen av NDB-motorn, inte InnoDB, som är standardmotorn för MySQL. I NDB-kluster partitioneras data över flera datanoder medan Galera Cluster eller MySQL InnoDB Cluster innehåller hela datamängden på var och en av noderna. Detta har allvarliga återverkningar på hur MySQL NDB Cluster hanterar frågor som använder JOINs och stora delar av datamängden.
När det kommer till arkitektur består MySQL NDB Cluster av tre olika nodtyper. Datanoder lagrar data med hjälp av NDB-motorn. Data speglas för redundans, med upp till 4 repliker av data. Observera att ClusterControl kommer att distribuera 2 repliker per nodgrupp, eftersom detta är den mest testade och stabila konfigurationen. Managementnoder är avsedda att styra klustret - av hög tillgänglighetsskäl har du vanligtvis två sådana noder. SQL-noder används som ingångspunkter till klustret. De analyserar SQL, ber om data från datanoderna och samlar resultatuppsättningar vid behov.
ClusterControl-funktioner för MySQL NDB Cluster
Implementering
ClusterControl 1.5 stöder distribution av MySQL NDB Cluster 7.5. Det görs genom samma distributionsguide som med de återstående klustertyperna.
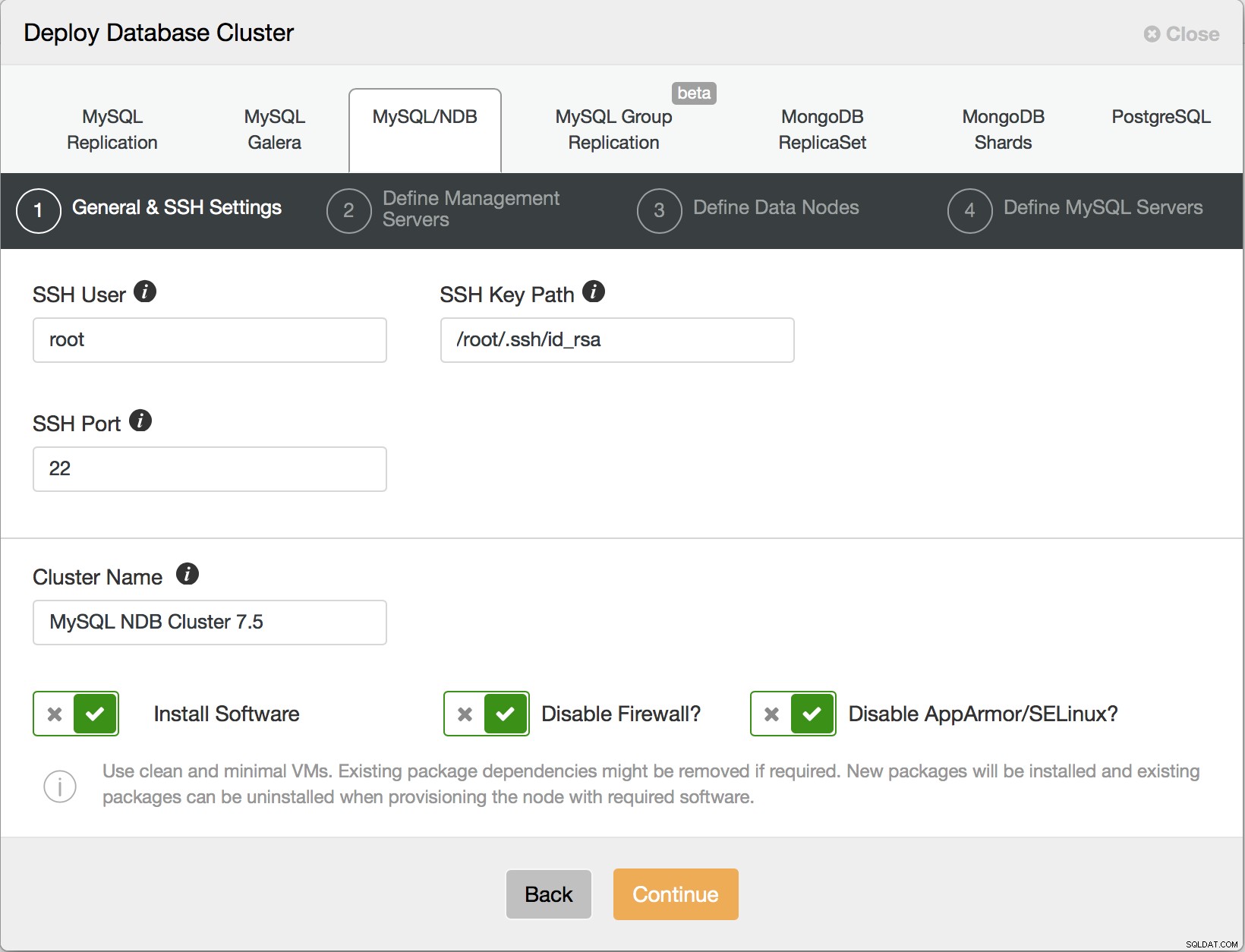
I det första steget måste du konfigurera hur ClusterControl kan logga in via SSH till värdarna - detta är ett standardkrav för ClusterControl - det är agentlöst så det kräver root-SSH-åtkomst antingen direkt, till root-kontot eller via (lösenord eller lösenordslöst) sudo.
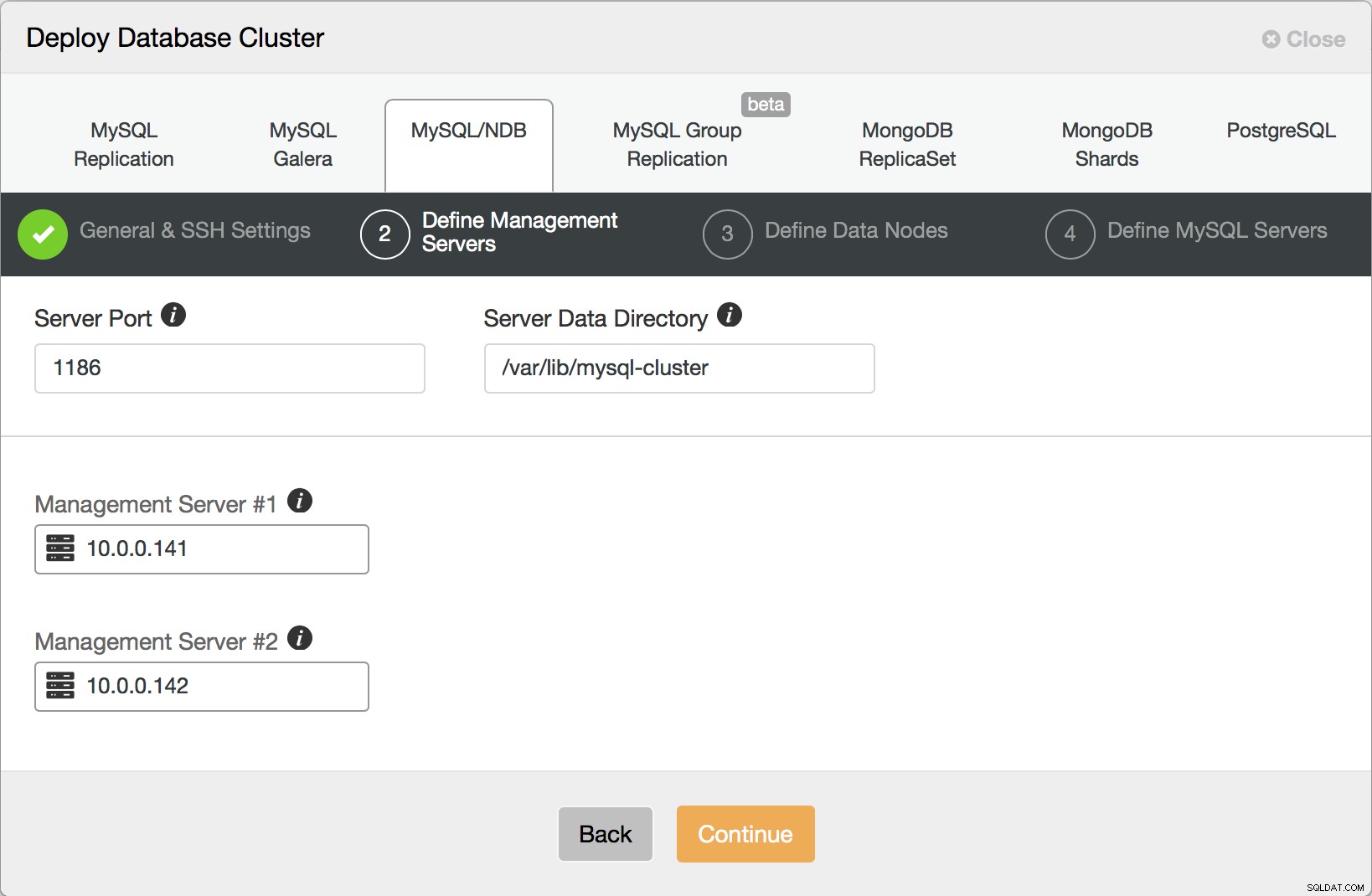
I nästa steg definierar du hanteringsnoder för ditt kluster.
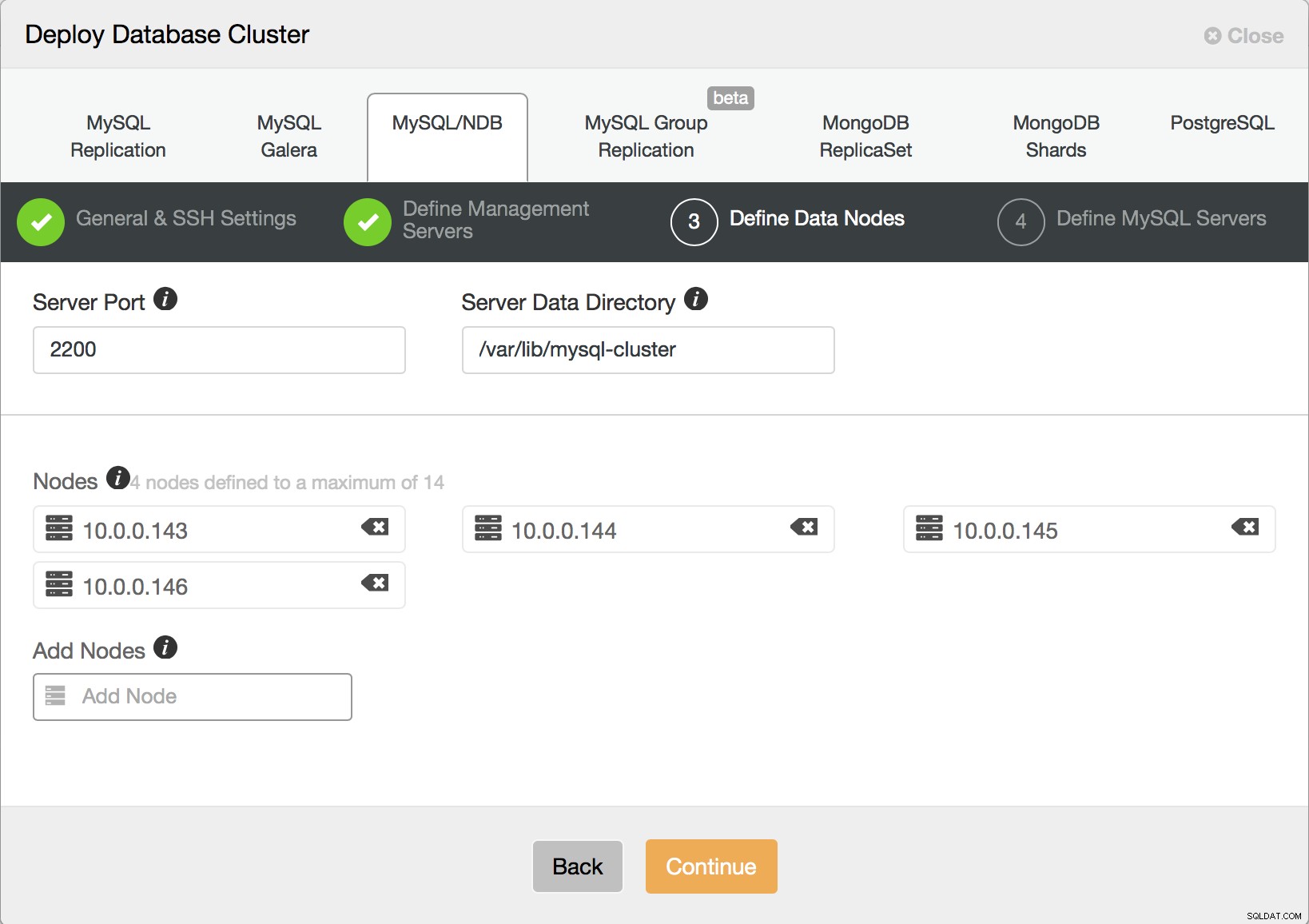
Här måste du bestämma hur många datanoder du vill ha. Som vi tidigare nämnt kommer varannan nod att ingå i en nodgrupp så detta bör vara ett jämnt tal.
Slutligen måste du bestämma hur många SQL-noder du vill distribuera i ditt kluster. När du klickar på distribuera kommer ClusterControl att ansluta till värdarna, installera programvaran och konfigurera alla tjänster. Efter ett tag bör du se ditt kluster distribuerat.
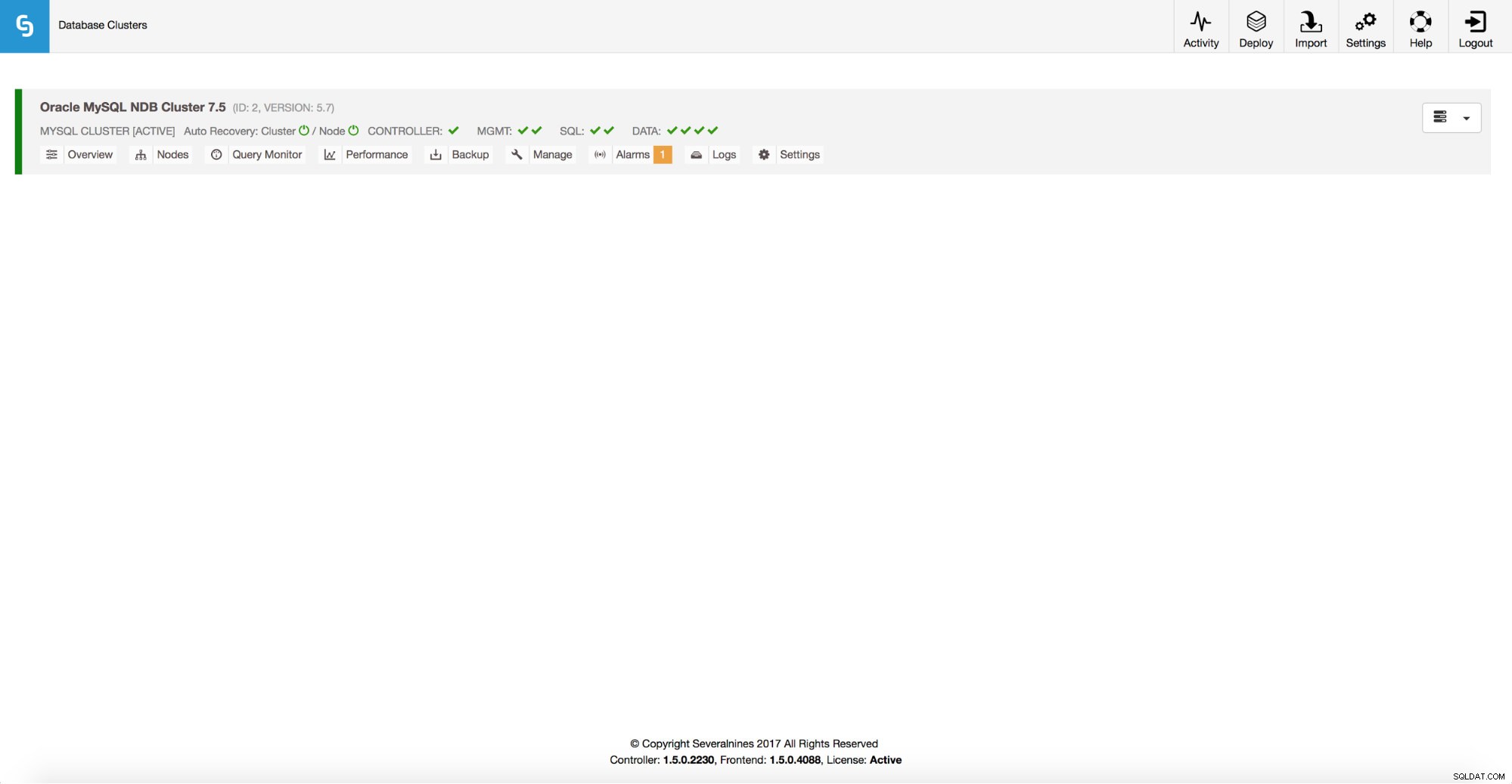
Skalning av MySQL NDB-kluster
För MySQL NDB Cluster stöder ClusterControl 1.5.0 skalning av SQL-noder. Du kan komma åt jobbet från rullgardinsmenyn Klusterjobb.
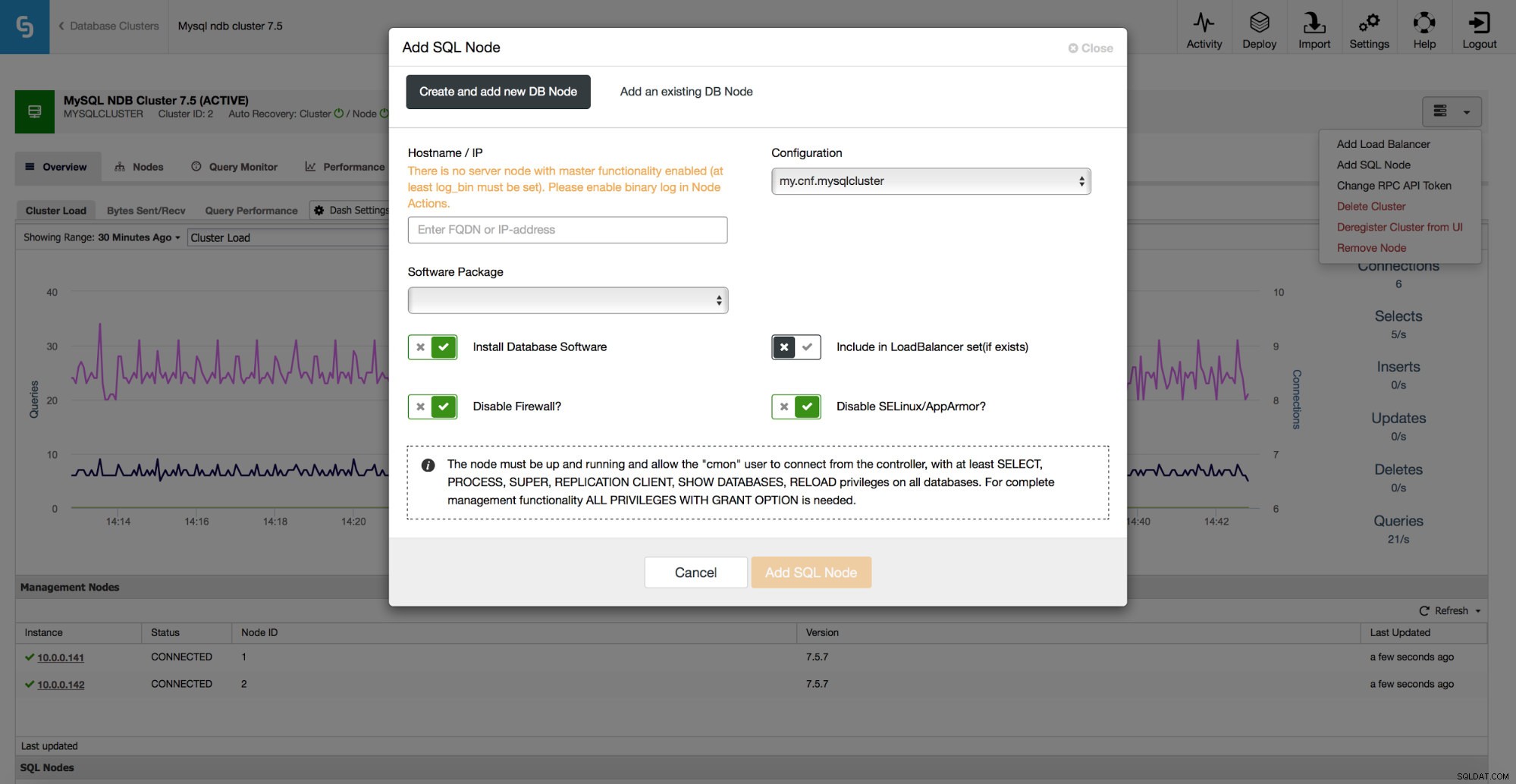
Där kan du fylla i värdnamnet för den nod du vill lägga till och det är allt du behöver - ClusterControl tar hand om resten.
Hantering av MySQL NDB-kluster
ClusterControl hjälper dig att hantera MySQL NDB Cluster. I det här avsnittet vill vi gå igenom några av de hanteringsfunktioner vi har.
Säkerhetskopiering
Säkerhetskopiering är avgörande för alla produktionsmiljöer. I händelse av en katastrof kan endast en bra säkerhetskopiering minimera dataförlusten och hjälpa dig att snabbt återställa problemet. Replikering kanske inte alltid är en lösning som fungerar - DROP TABLE kommer att släppa tabellen på alla värdar i topologin. Till och med en försenad slav kan fördröja det oundvikliga bara så mycket.
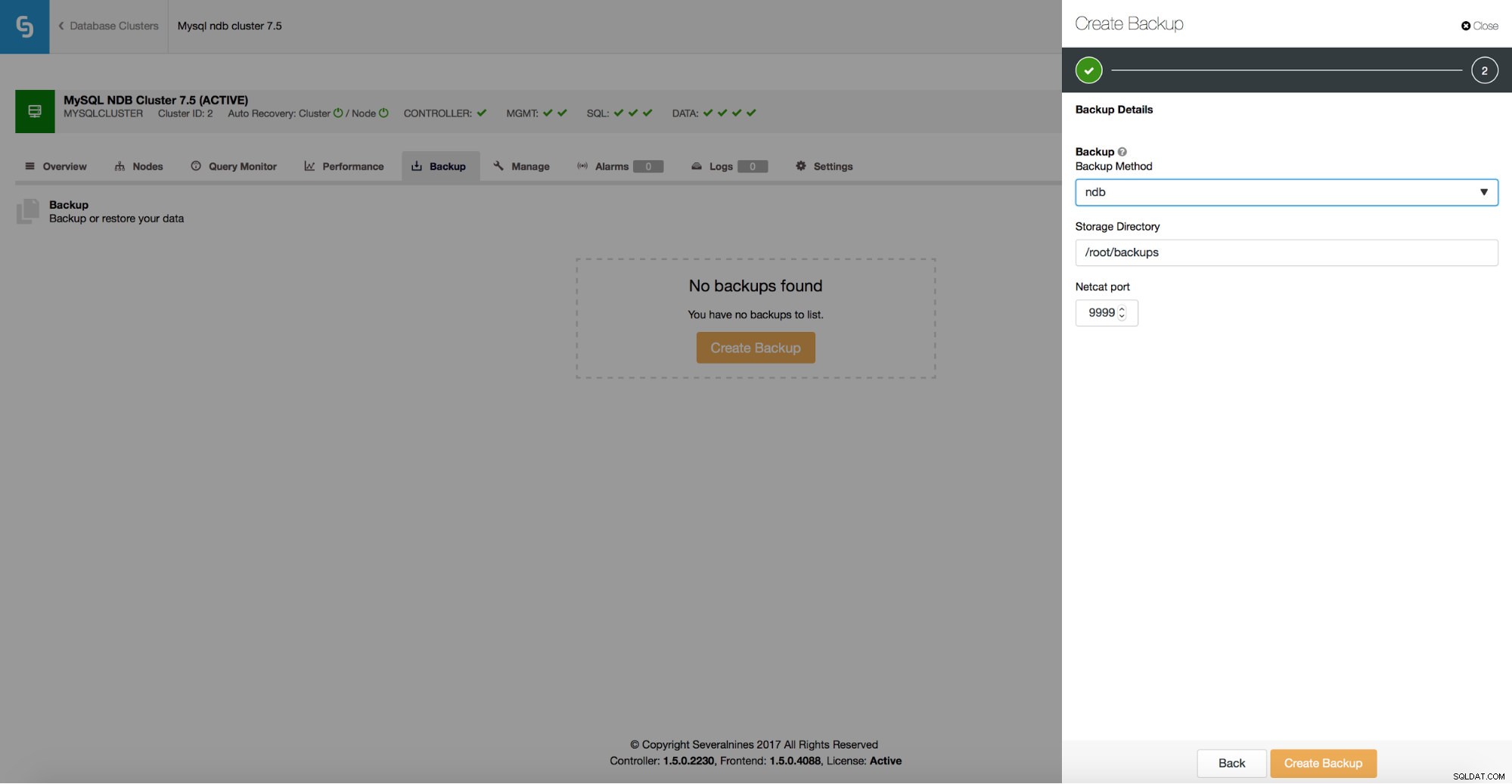
ClusterControl stöder ndb backup för MySQL NDB Cluster.
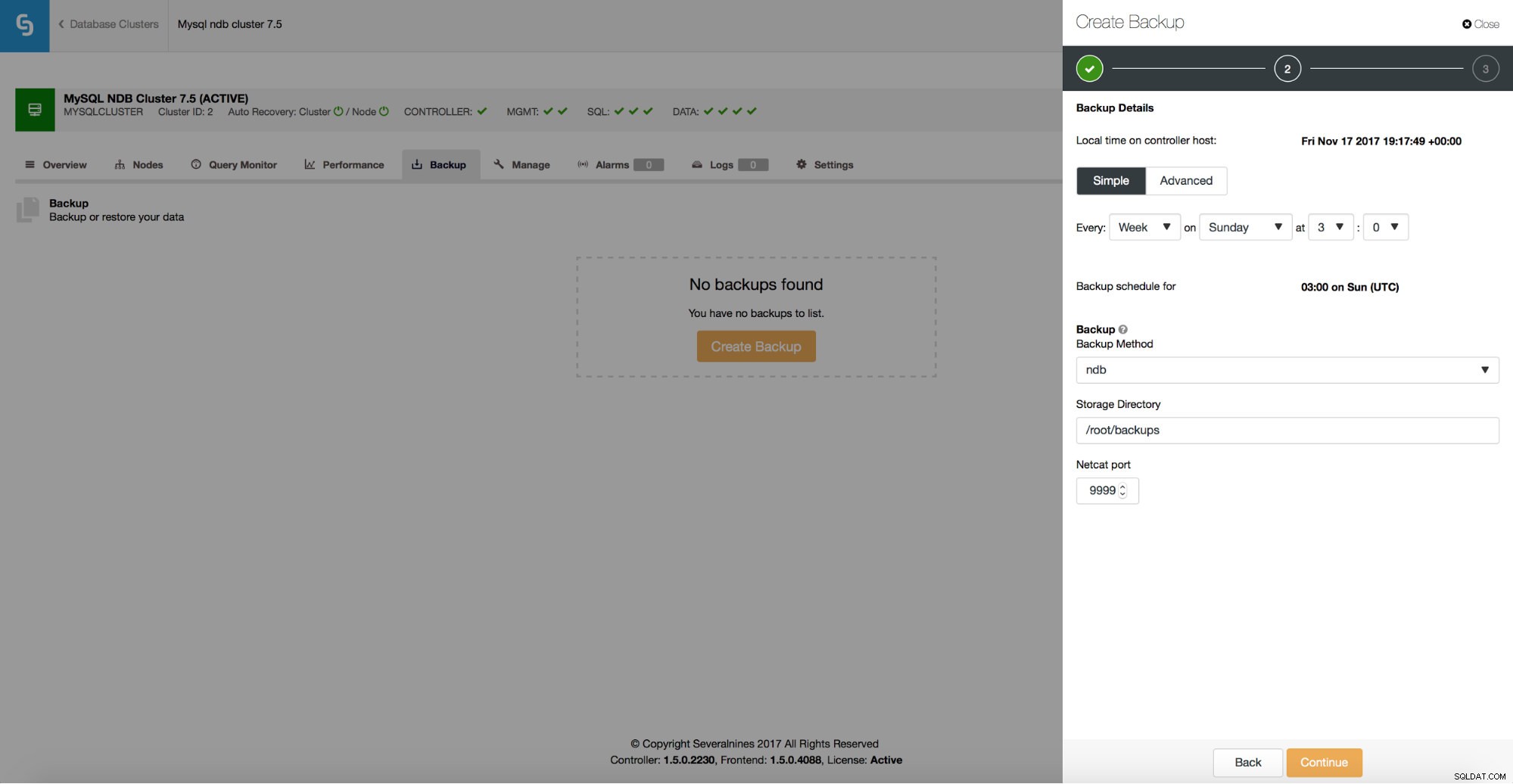
Du kan enkelt skapa ett säkerhetskopieringsschema som ska köras av ClusterControl.
Proxylager
ClusterControl låter dig distribuera en full hög tillgänglighetsstack ovanpå MySQL NDB-klustret. För proxylagret stöder vi distribution av HAProxy och MaxScale.
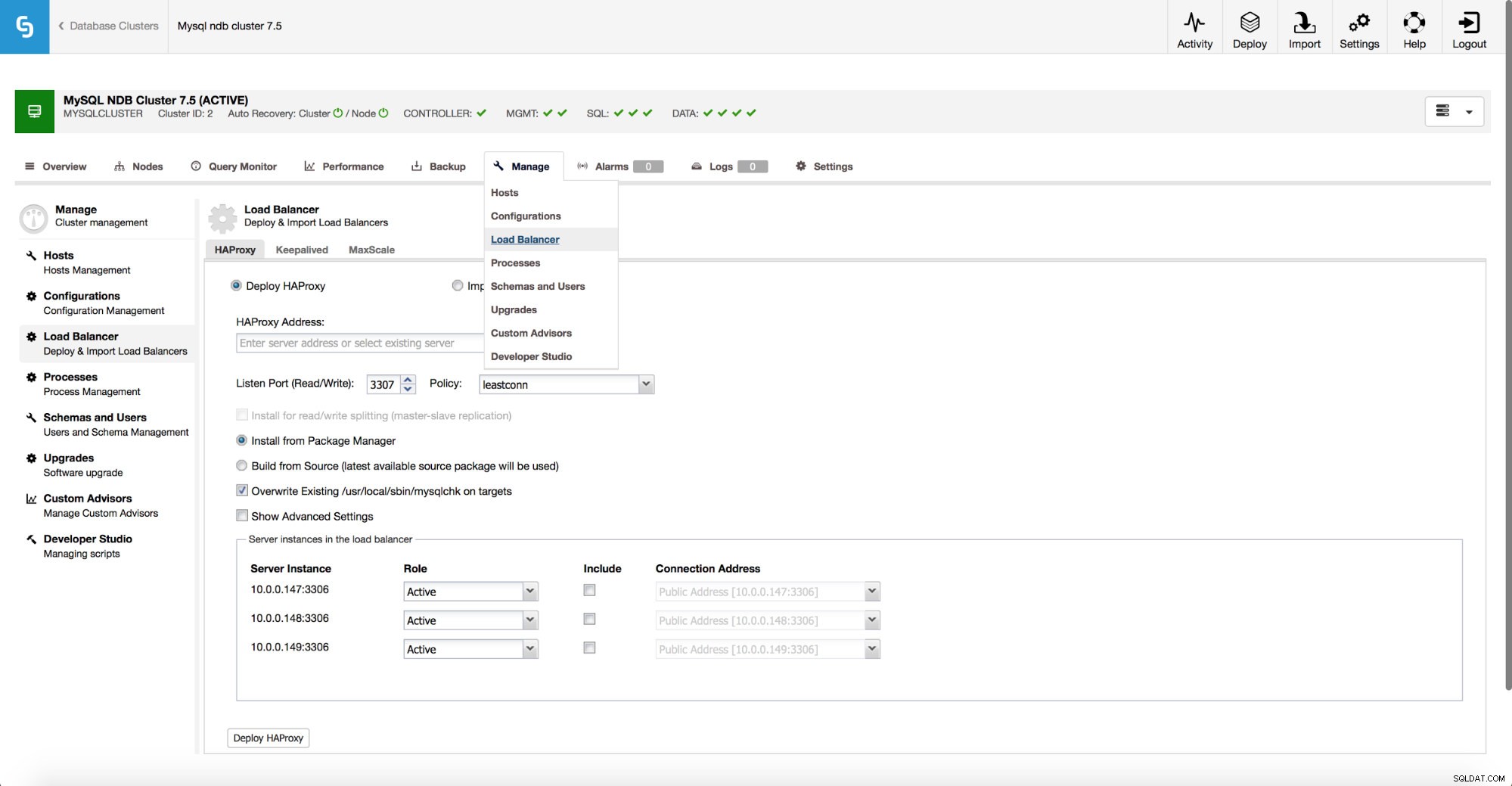
Som visas på skärmdumpen ovan ser implementeringen väldigt lik de andra klustertyperna. Du måste bestämma om du vill använda en befintlig HAProxy eller distribuera en ny. Sedan måste du göra ett val hur du installerar det - med hjälp av paket från förråd som är tillgängliga på noden eller kompilera det från källkoden för den senaste utgåvan.
Om du bestämmer dig för att använda HAProxy har du möjlighet att konfigurera hög tillgänglighet med Keepalved och Virtual IP.
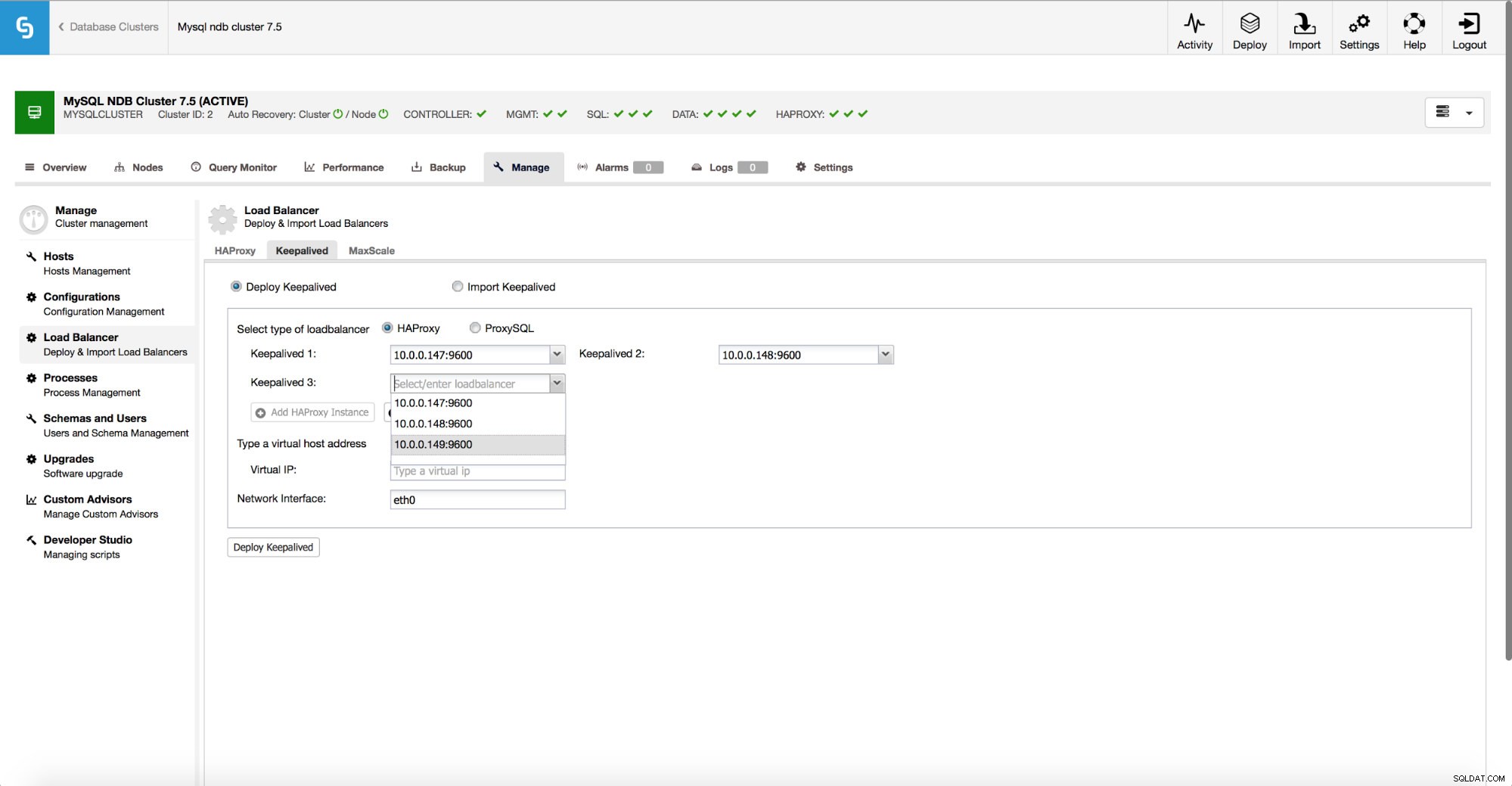
Processen är följande - du definierar en virtuell IP och gränssnittet som den ska tas upp på. Sedan kan du distribuera den för varje HAProxy som du har installerat. En av Keepalved-processerna kommer att bestämmas som en "master" och den kommer att aktivera VIP på sin nod. Din applikation ansluter sedan till just denna IP. När en aktuell aktiv HAProxy inte är tillgänglig, kommer VIP:n att flyttas till en annan tillgänglig HAProxy, vilket återställer anslutningen.
Återställningshantering
Medan MySQL NDB Cluster kan tolerera fel i enskilda noder, är det viktigt att reagera snabbt på dessa. ClusterControl tillhandahåller automatisk återställning för alla komponenter i klustret. Oavsett vad som misslyckas (hanteringsnod, datanod eller SQL-nod), kommer ClusterControl att starta om dem automatiskt.
Övervakning av MySQL NDB-klustret
Alla produktionsklara miljöer måste övervakas. ClusterControl ger dig en rad mätvärden att övervaka. På sidan "Översikt" visar vi diagram baserade på de viktigaste mätvärdena för ditt kluster. Du kan också skapa dina egna instrumentpaneler som visar ytterligare data som skulle vara användbar i din miljö.
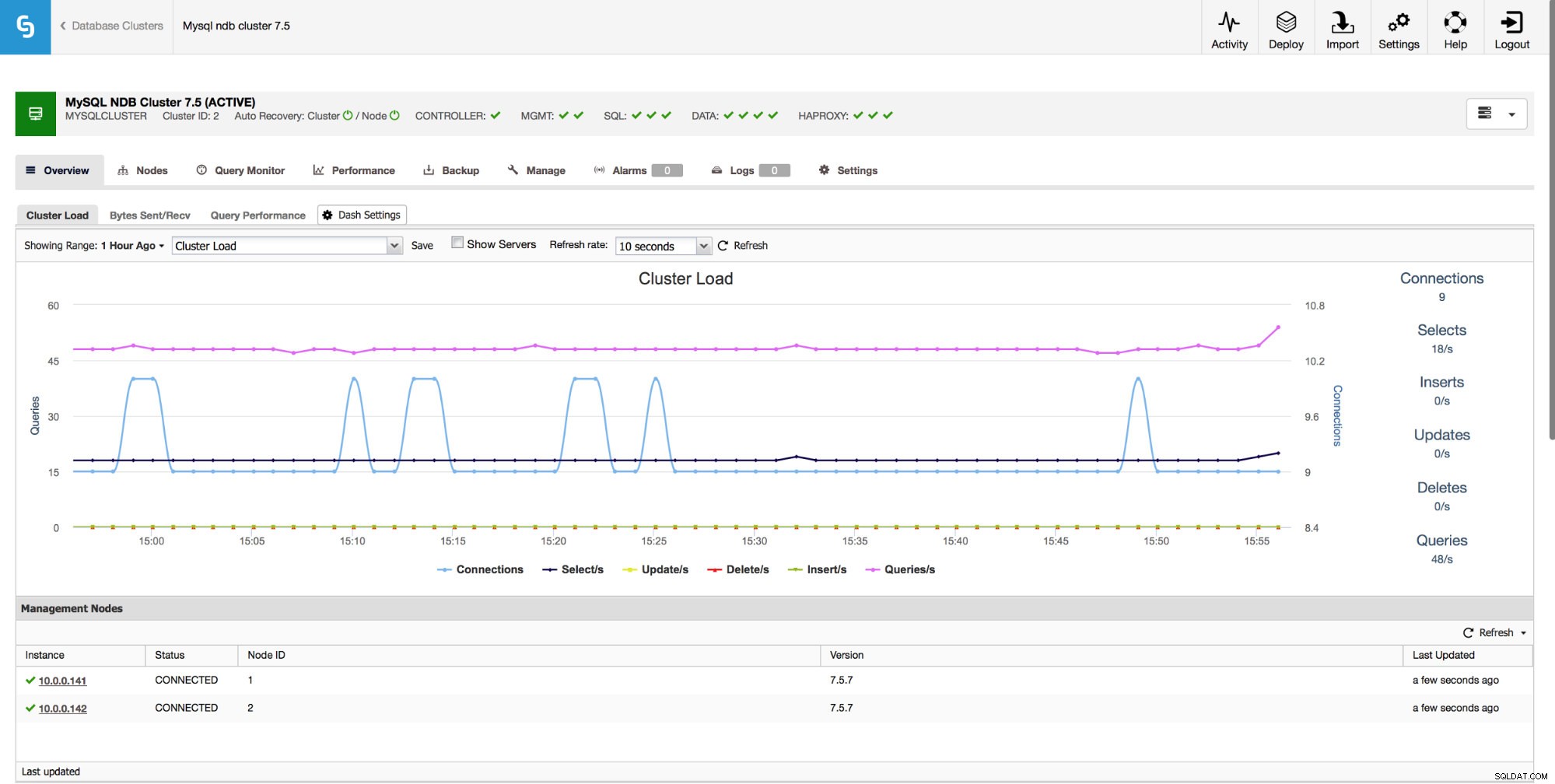
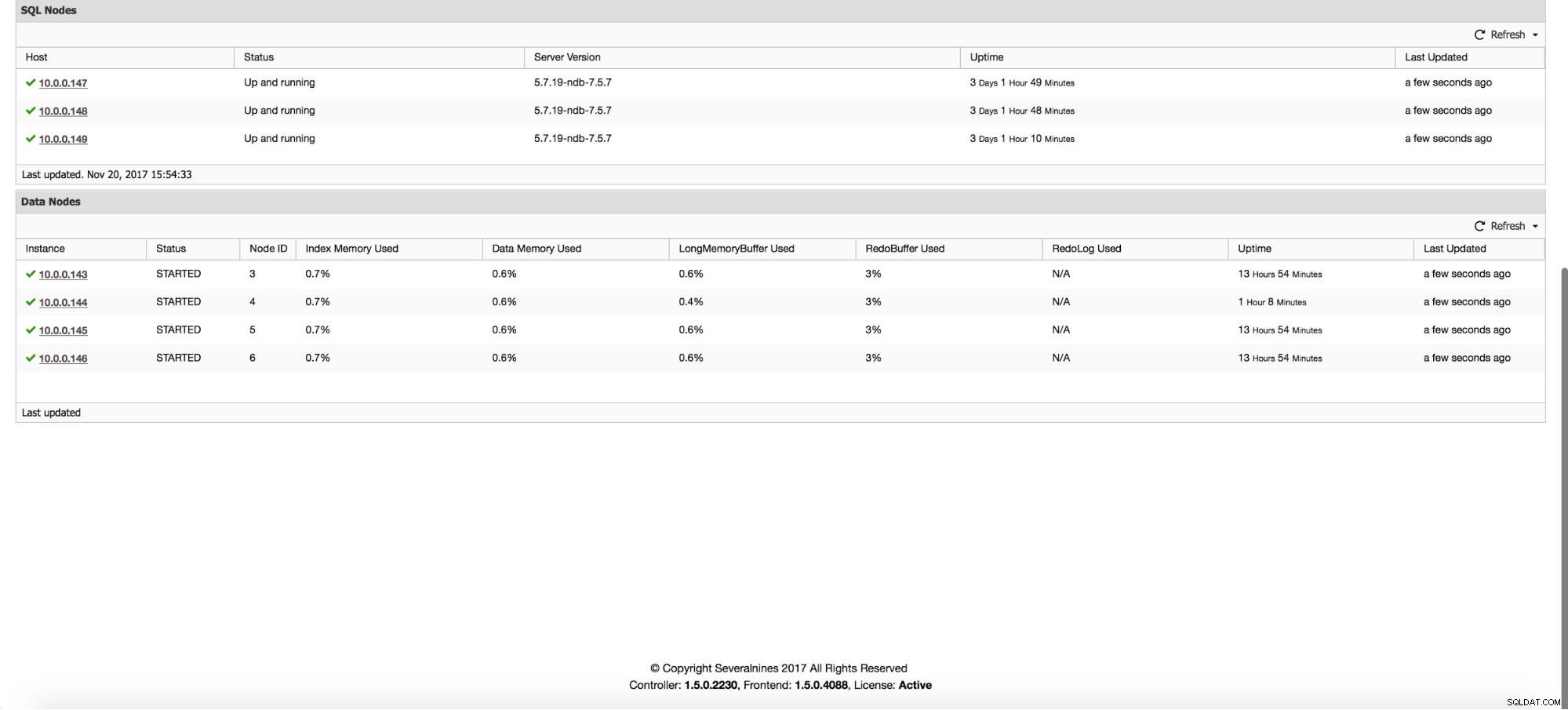
Förutom graferna ger sidan "Översikt" dig insikter i klustrets tillstånd baserat på vissa MySQL NDB-klustermått som använt indexminne, dataminne och tillstånd för vissa buffertar.
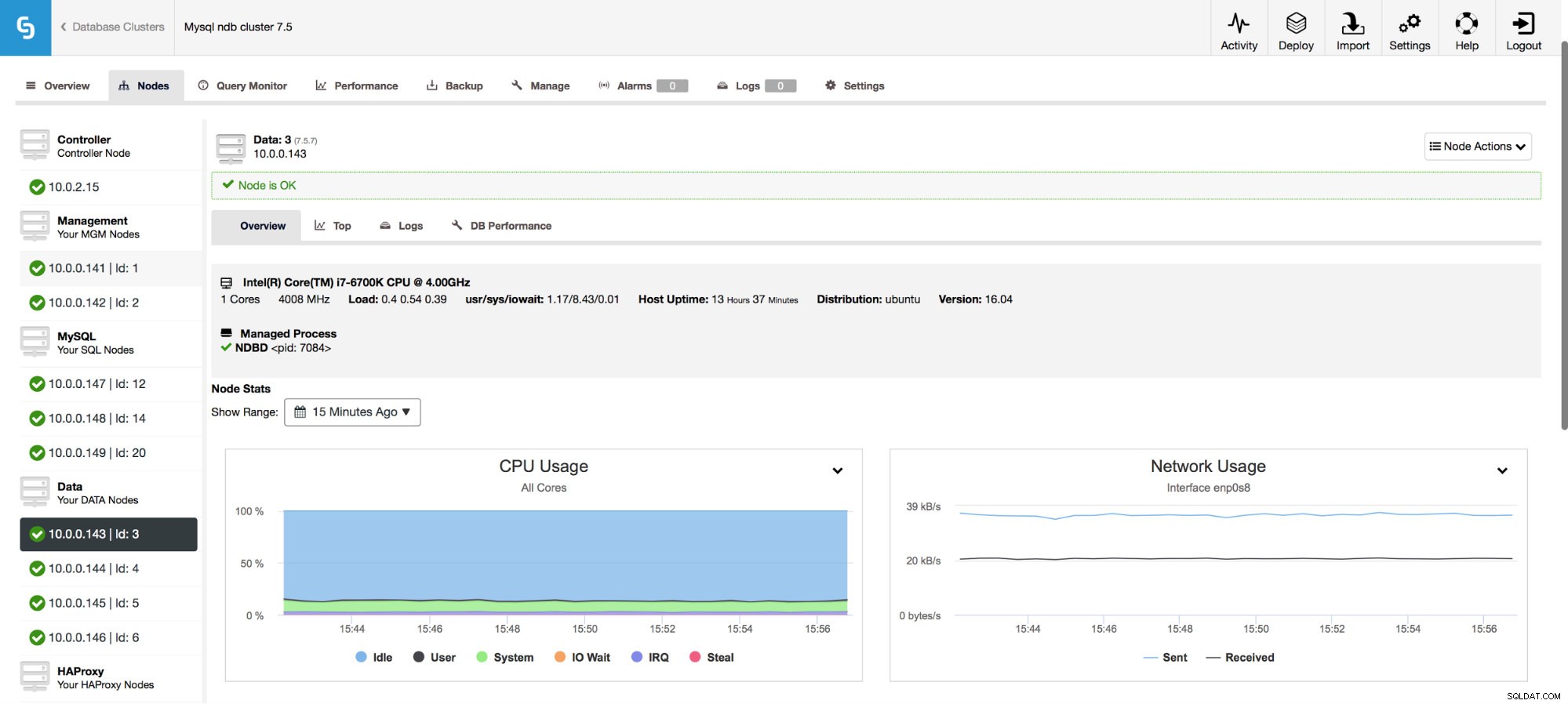
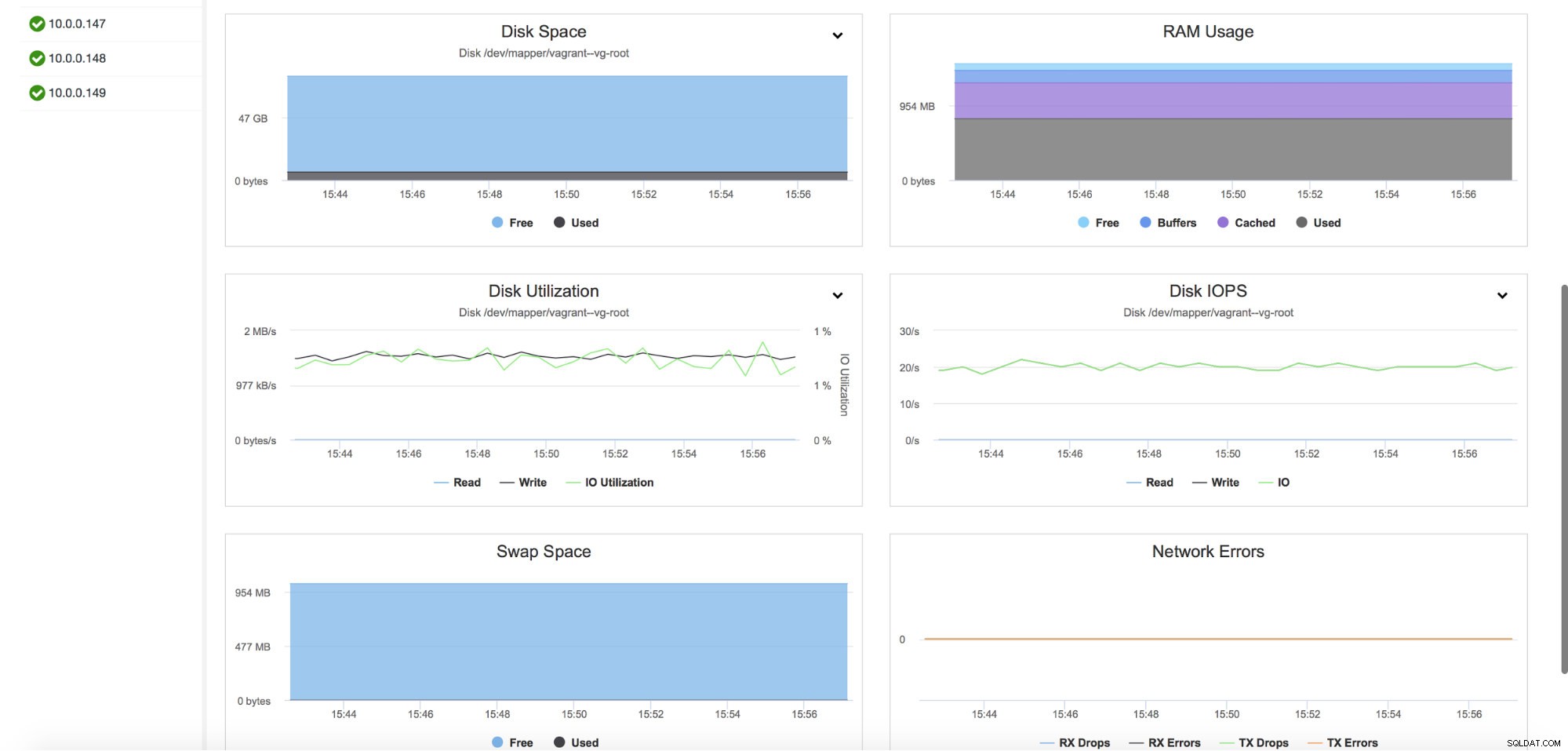
Det ger också övervakning av värdvärden, inklusive CPU-användning, RAM-minne, disk- eller nätverksstatistik. Dessa grafer är också avgörande för att skapa en bild av klustrets hälsa.
ClusterControl kan också hjälpa dig att förbättra dina databasers prestanda genom att ge dig tillgång till Query Monitor, som innehåller statistik om din trafik.
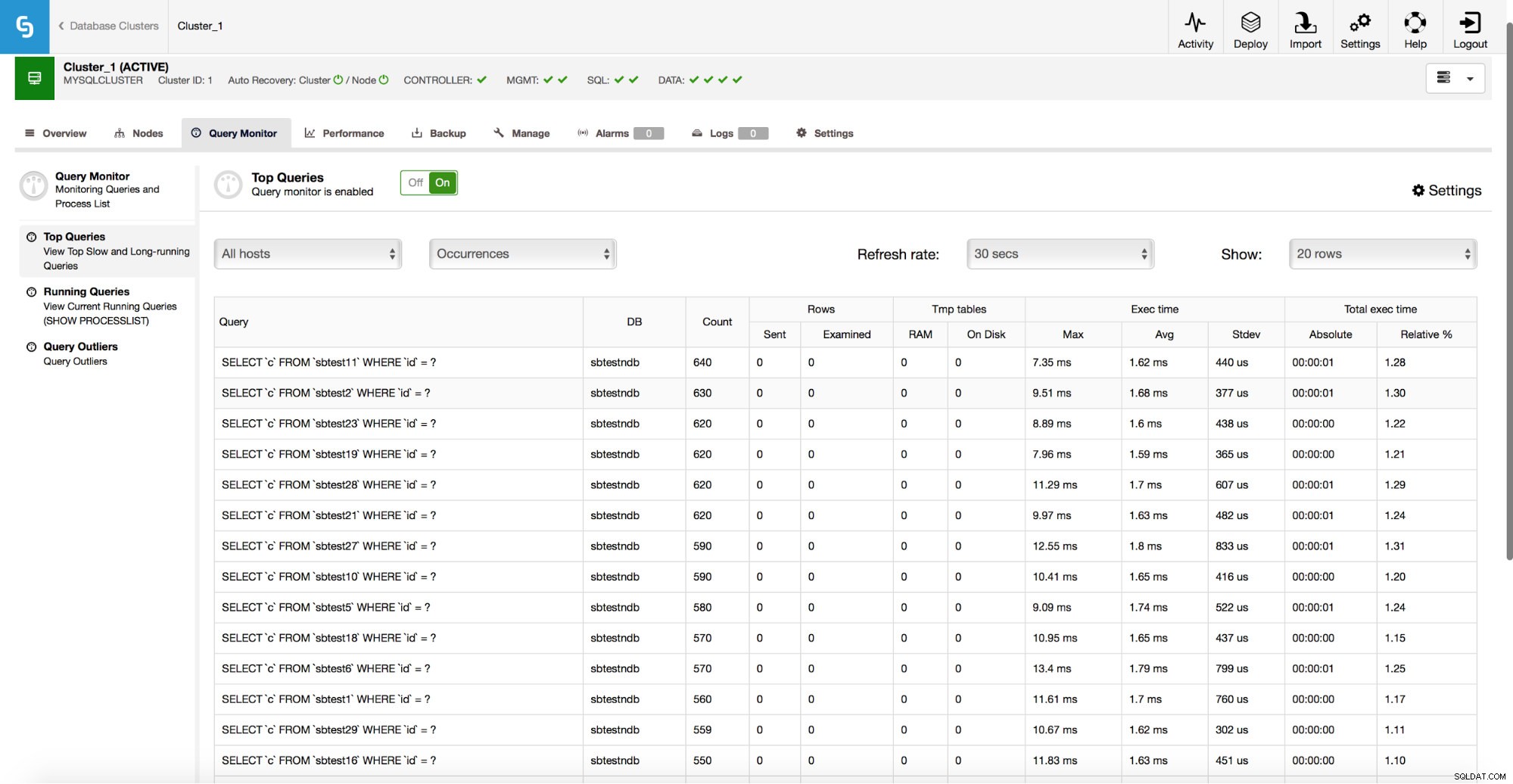
Som framgår av skärmdumpen ovan kan du se vilken typ av frågor som körs mot ditt kluster, hur många frågor av en given typ, vad är deras körningstider och totala körningstider. Detta hjälper till att identifiera vilka frågor som är långsamma och vilka av dem som ansvarar för majoriteten av trafiken. Du kan sedan fokusera på de frågor som kan ge dig den största prestandaförbättringen.