Lastbalanserare är en viktig komponent i databasens hög tillgänglighet; speciellt när man gör topologiändringar transparenta för applikationer och implementerar läs-skriv-delad funktionalitet. ClusterControl tillhandahåller en rad funktioner för att säkert distribuera, övervaka och konfigurera branschens ledande belastningsbalanseringstekniker med öppen källkod.
Under det senaste året har vi lagt till stöd för ProxySQL och lagt till flera förbättringar för HAProxy och MariaDBs Maxscale. Vi fortsätter denna tradition med den senaste versionen av ClusterControl 1.5.
Baserat på feedback vi fått från våra användare har vi förbättrat hur ProxySQL hanteras. Vi har också lagt till stöd för HAProxy och Keepalved för att köras ovanpå PostgreSQL-kluster.
I det här blogginlägget ska vi ta en titt på dessa förbättringar...
ProxySQL - Förbättringar av användarhantering
Tidigare kunde användargränssnittet bara tillåta dig att skapa en ny användare eller lägga till en befintlig, en i taget. En feedback vi fick från våra användare var att det är ganska svårt att hantera ett stort antal användare. Vi lyssnade och i ClusterControl 1.5 är det nu möjligt att importera stora partier av användare. Låt oss ta en titt på hur du kan göra det. Först och främst måste du ha din ProxySQL utplacerad. Gå sedan till ProxySQL-noden och på fliken Användare bör du se knappen "Importera användare".

När du klickar på den öppnas en ny dialogruta:

Här kan du se alla användare som ClusterControl upptäckte på ditt kluster. Du kan bläddra igenom dem och välja de du vill importera. Du kan också välja eller avmarkera alla användare från en aktuell vy.

När du börjar skriva i sökrutan kommer ClusterControl att filtrera bort resultat som inte matchar, vilket begränsar listan till endast användare som är relevanta för din sökning.
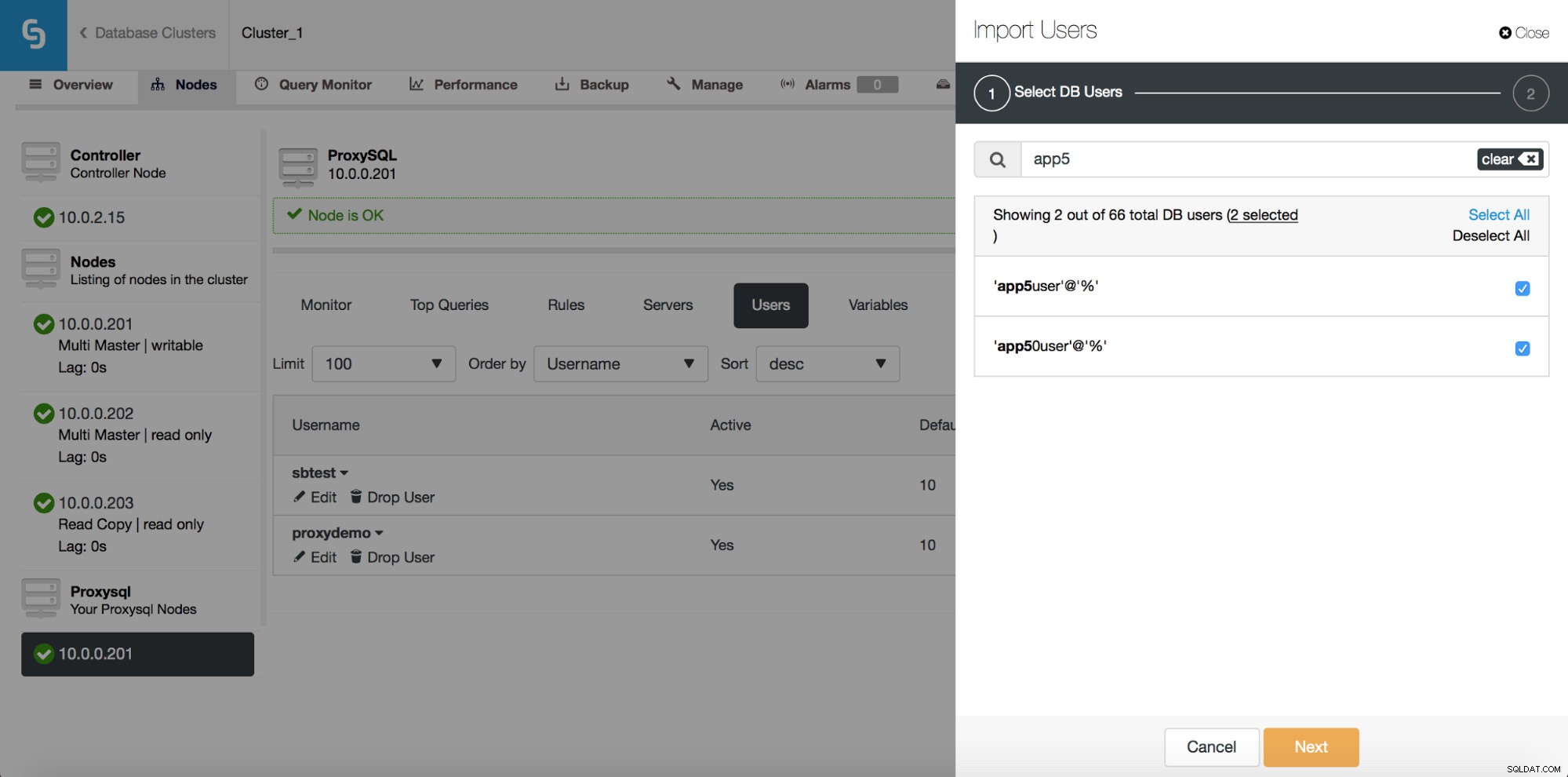
Du kan använda knappen "Välj alla" för att välja alla användare som matchar din sökning. Naturligtvis, efter att du valt användare som du vill importera, kan du rensa sökrutan och starta en ny sökning:

Observera "(7 valda)" - den talar om hur många användare totalt (inte bara från denna sökning) du har valt att importera. Du kan också klicka på den för att bara se de användare du valt att importera.

När du är nöjd med ditt val kan du klicka på "Nästa" för att gå till nästa skärm.

Här måste du bestämma vad som ska vara standardvärdgruppen för varje användare. Du kan göra det per användare eller globalt, för hela uppsättningen eller en delmängd av användare som är resultatet av en sökning.

När du klickar på knappen "Importera användare" kommer användare att importeras och de visas på fliken Användare.
ProxySQL - Schemaläggare
ProxySQL:s schemaläggare är en cron-liknande modul som gör att ProxySQL kan starta externa skript med jämna mellanrum. Schemat kan vara ganska detaljerat - upp till en exekvering varje millisekund. Vanligtvis används schemaläggaren för att exekvera Galera checker-skript (som proxysql_galera_checker.sh), men den kan också användas för att exekvera andra skript som du vill. Tidigare använde ClusterControl schemaläggaren för att distribuera Galera checker-skriptet men detta visades inte i användargränssnittet. När du startar ClusterControl 1.5 har du nu full kontroll.

Som du kan se har ett skript schemalagts att köras varannan sekund (2000 millisekunder) - detta är standardkonfigurationen för Galera-klustret.

Ovanstående skärmdump visar oss alternativ för att redigera befintliga poster. Observera att ProxySQL stöder upp till 5 argument till skripten som den kommer att köra via schemaläggaren.

Om du vill att ett nytt skript ska läggas till i schemaläggaren kan du klicka på knappen "Lägg till nytt skript" och du kommer att presenteras med en skärm som ovan. Du kan också förhandsgranska hur hela skriptet kommer att se ut när det körs. När du har fyllt i alla "Argument"-fält och definierat intervallet kan du klicka på knappen "Lägg till nytt skript".

Som ett resultat kommer ett skript att läggas till i schemaläggaren och det kommer att synas på listan över schemalagda skript.
Ladda ner Whitepaper Today PostgreSQL Management &Automation med ClusterControlLäs om vad du behöver veta för att distribuera, övervaka, hantera och skala PostgreSQLDladda WhitepaperPostgreSQL – Bygga högtillgänglighetsstacken
Att ställa in replikering med automatisk failover är bra, men applikationer behöver ett enkelt sätt att spåra den skrivbara mastern. Så vi lade till stöd för HAProxy och Keepalived ovanpå PostgreSQL-klustren. Detta gör att våra PostgreSQL-användare kan distribuera en full hög tillgänglighetsstack med ClusterControl.

Från underfliken Load Balancer kan du nu distribuera HAProxy - om du är bekant med hur ClusterControl distribuerar MySQL-replikering är det en mycket liknande installation. Vi installerar HAProxy på en given värd, två backends, läser på port 3308 och skriver på port 3307. Den använder tcp-check och förväntar sig att en viss sträng ska återvända. För att producera den strängen exekveras följande steg på alla databasnoder. Först och främst är xinet.d konfigurerad att köra en tjänst på port 9201 (för att undvika förvirring med MySQL-installationen, som använder port 9200).
# default: on
# description: postgreschk
service postgreschk
{
flags = REUSE
socket_type = stream
port = 9201
wait = no
user = root
server = /usr/local/sbin/postgreschk
log_on_failure += USERID
disable = no
#only_from = 0.0.0.0/0
only_from = 0.0.0.0/0
per_source = UNLIMITEDTjänsten kör /usr/local/sbin/postgreschk-skriptet, som validerar tillståndet för PostgreSQL och talar om om en given värd är tillgänglig och vilken typ av värd det är (master eller slav). Om allt är ok returnerar den strängen som förväntas av HAProxy.
Precis som med MySQL, ses HAProxy-noder i PostgreSQL-kluster i användargränssnittet och statussidan kan nås:

Här kan du se båda backends och verifiera att endast mastern är uppe för r/w backend och alla noder kan nås via skrivskyddad backend. Du kan också få lite statistik om trafik och anslutningar.
HAProxy hjälper till att förbättra hög tillgänglighet, men det kan bli ett enda fel. Vi måste gå den extra milen och konfigurera redundans med hjälp av Keepalved.

Under Hantera -> Lastbalanserare -> Keepalved väljer du de HAProxy-värdar du vill använda och Keepalved kommer att distribueras ovanpå dem med en virtuell IP kopplad till det gränssnitt du väljer.
Från och med nu bör all anslutning gå till VIP, som kommer att kopplas till en av HAProxy-noderna. Om den noden går ner kommer Keepalved att ta ner VIP:n på den noden och ta upp den på en annan HAProxy-nod.
Det är allt för lastbalanseringsfunktionerna som introducerades i ClusterControl 1.5. Prova dem och låt oss veta hur du gör