MySQL är lätt att installera och använda, det har alltid varit populärt bland utvecklare och systemadministratörer. Å andra sidan är det en annan historia att distribuera en produktionsklar MySQL-miljö för en affärskritisk arbetsbelastning. Det kan vara lite av en utmaning, och kräver djupgående kunskaper om databasen. I det här blogginlägget kommer vi att diskutera några av de steg som måste tas innan vi kan överväga att vår MySQL-distribution är produktionsklar.
Hög tillgänglighet

Om du tillhör de lyckliga som kan acceptera timmar av driftstopp kan du sluta läsa här och hoppa till nästa stycke. För 99,999 % av affärskritiska system skulle det inte vara acceptabelt. Därför måste en produktionsfärdig implementering inkludera åtgärder för hög tillgänglighet. Automatisk failover av databasinstanserna, såväl som ett proxylager som upptäcker förändringar i topologi och tillstånd för MySQL och dirigerar trafiken därefter, skulle vara ett huvudkrav. Det finns många verktyg som kan användas för att bygga sådana miljöer, till exempel MHA, MRM eller ClusterControl.
Proxylager
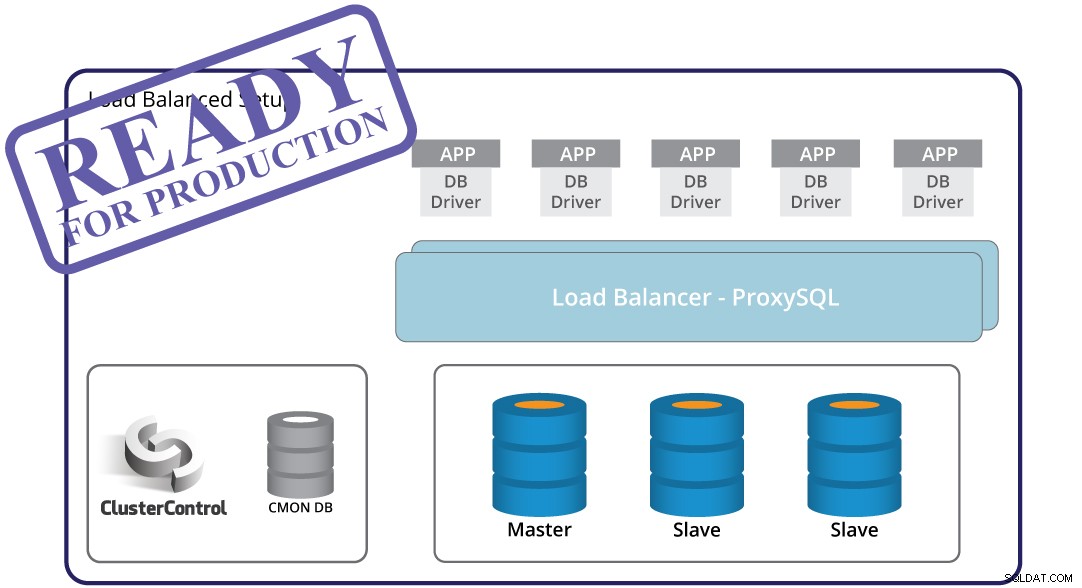
Master feldetektering, automatiserad failover och återställning - dessa är avgörande när man bygger en produktionsklar infrastruktur. Men på egen hand räcker det inte. Det finns fortfarande en applikation som måste anpassa sig till topologiförändringen som utlöses av failover. Naturligtvis är det möjligt att koda applikationen så att den är medveten om instansfel. Detta är dock ett besvärligt och oflexibelt sätt att hantera topologiförändringar. Här kommer databasproxyn - ett mellanlager mellan applikation och databas. En proxy kan dölja komplexiteten i ditt databasskikt från applikationen - allt applikationen gör är att ansluta till proxyn och proxyn tar hand om resten. Proxyn dirigerar frågor till en databasinstans, den hanterar topologiändringar och dirigerar om vid behov. En proxy kan också användas för att implementera läs-skrivdelning, vilket avlastar applikationen från ett mer komplext fall att täcka. Detta skapar ytterligare en utmaning - vilken proxy ska man använda? Hur konfigurerar man det? Hur övervakar man det? Hur gör man det mycket tillgängligt så att det inte blir en SPOF?
ClusterControl kan hjälpa dig här. Den kan användas för att distribuera olika proxyservrar för att bilda ett proxylager:ProxySQL, HAProxy och MaxScale. Den förkonfigurerar proxyservrar för att se till att de kommer att hantera trafiken korrekt. Det gör det också enkelt att implementera alla konfigurationsändringar om du behöver anpassa proxyinställningarna för din applikation. Läs- och skrivdelning kan konfigureras med någon av de proxyservrar som ClusterControl stöder. ClusterControl övervakar också proxyservrar och kommer att återställa dem i händelse av fel. Proxylagret kan bli en enda felpunkt, eftersom automatiserad återställning kanske inte räcker - för att åtgärda det kan ClusterControl distribuera Keepalved och konfigurera Virtual IP för att automatisera failover.
Säkerhetskopiering
Även om du inte behöver implementera hög tillgänglighet måste du förmodligen fortfarande bry dig om din data. Säkerhetskopiering är ett måste för nästan varje produktionsdatabas. Ingenting annat än en säkerhetskopia kan rädda dig från en oavsiktlig DROP TABLE eller DROP SCHEMA (tja, kanske en fördröjd replikeringsslav, men bara under en viss tid). MySQL erbjuder flera metoder för att ta säkerhetskopior - mysqldump, xtrabackup, olika typer av ögonblicksbilder (vissa endast tillgängliga med speciell hårdvara eller molnleverantör). Det är inte lätt att designa rätt säkerhetskopieringsstrategi, bestämma vilka verktyg som ska användas och sedan skripta hela processen så att den körs korrekt. Det är inte heller raketvetenskap och kräver noggrann planering och testning. När en säkerhetskopia väl har tagits är du inte klar. Är du säker på att säkerhetskopian kan återställas och att data inte är skräp? Att verifiera dina säkerhetskopior är tidskrävande, och kanske inte det mest spännande du kommer att ha på din att göra-lista. Men det är fortfarande viktigt och måste göras regelbundet.
ClusterControl har omfattande säkerhetskopierings- och återställningsfunktioner. Den stöder mysqldump för logisk säkerhetskopiering och Percona Xtrabackup för fysisk säkerhetskopiering - dessa verktyg kan användas i nästan alla miljöer, antingen moln eller lokalt. Det är möjligt att bygga en säkerhetskopieringsstrategi med en blandning av logiska och fysiska säkerhetskopior, inkrementella eller fullständiga, online.
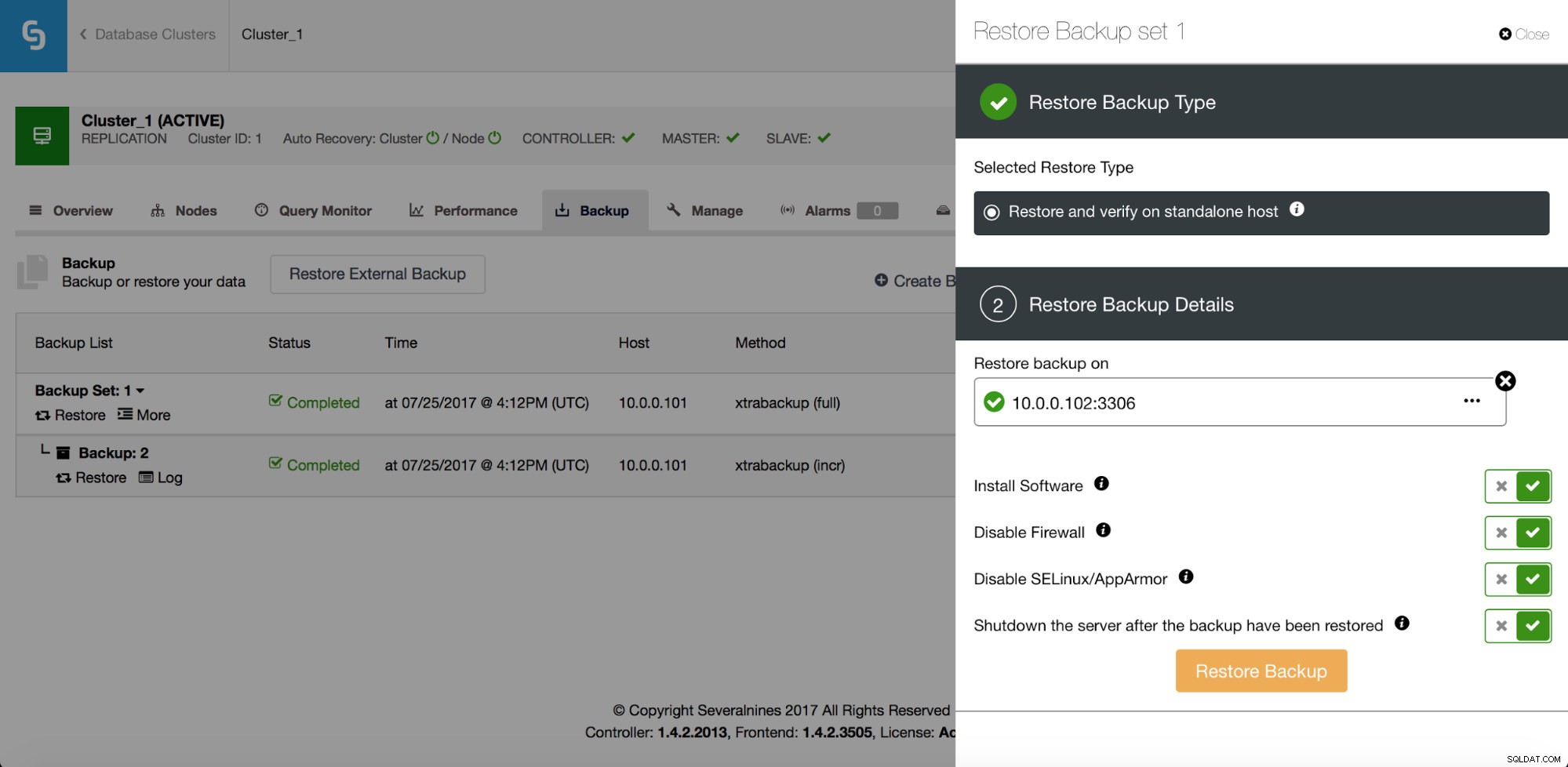
Förutom återställning har den också alternativ för att verifiera en säkerhetskopia - till exempel återställa den på en separat värd för att verifiera om säkerhetskopieringsprocessen fungerar ok eller inte.
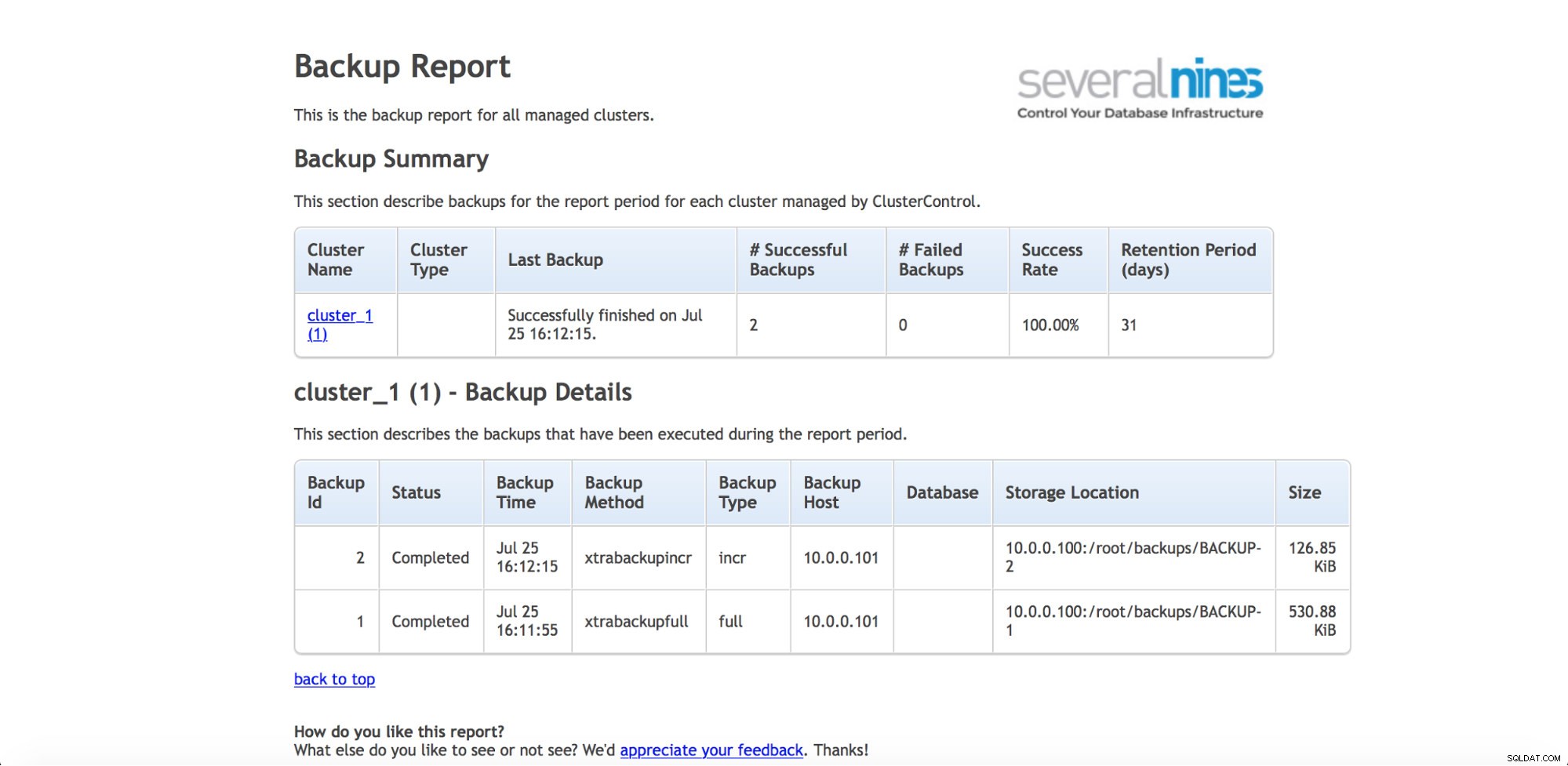
Om du vill hålla ett öga på säkerhetskopiorna regelbundet (och du skulle förmodligen vilja göra detta), har ClusterControl förmågan att generera driftsrapporter. Säkerhetskopieringsrapporten hjälper dig att spåra utförda säkerhetskopior och informerar om det fanns några problem när du tog dem.
Severalnines DevOps Guide to Database ManagementLär dig om vad du behöver veta för att automatisera och hantera dina databaser med öppen källkod Ladda ner gratisÖvervakning och trend

Ingen driftsättning är produktionsklar utan korrekt övervakning av tjänsterna. Du vill vara säker på att du blir varnad om vissa tjänster blir otillgängliga så att du kan vidta en åtgärd, undersöka eller starta återställningsprocedurer. Naturligtvis vill du också ha en trendig lösning också. Det kan inte nog betonas hur viktigt det är att ha övervakningsdata för att bedöma tillståndet för infrastrukturen eller för någon utredning, antingen obduktion eller realtidsövervakning av tjänsternas tillstånd. Mätvärden är inte lika viktiga - om du inte är så bekant med en viss databasprodukt kommer du troligen inte att veta vilka som är de viktigaste mätvärdena att samla in och titta på. Visst, du kanske kan samla in allt men när det kommer till att granska data är det knappast möjligt att gå igenom hundratals mätvärden per värd - du måste veta vilken av dem du ska fokusera på.
Världen med öppen källkod är full av verktyg utformade för att övervaka och samla in mätvärden från olika databaser - de flesta av dem skulle kräva att du integrerar dem med din övergripande övervakningsinfrastruktur, chatops-plattform eller oncall-supportverktyg (som PagerDuty). Det kan också krävas att installera och integrera flera komponenter - lagring (någon sorts tidsseriedatabas), presentationslager och verktyg för datainsamling.
ClusterControl är lite av ett annat tillvägagångssätt, eftersom det är en enda produkt med realtidsövervakning, trender och instrumentpaneler som visar de viktigaste detaljerna. Databasrådgivare, som kan vara allt från enkla konfigurationsråd, varningar om trösklar eller mer komplexa regler för förutsägelser, skulle i allmänhet ge omfattande rekommendationer.
Förmåga att skala upp

Databaser tenderar att växa i storlek, och det är inte osannolikt att de skulle växa i form av transaktionsvolymer eller antal användare. Förmågan att skala ut eller upp kan vara avgörande för produktionen. Även om du gör ett bra jobb med att uppskatta dina hårdvarukrav i början av produktens livscykel, kommer du förmodligen att behöva hantera en tillväxtfas - så länge din produkt är framgångsrik, det vill säga (men det är vad vi alla planerar för, eller hur ?). Du måste ha medel för att enkelt skala upp din infrastruktur för att klara av inkommande belastning. För tillståndslösa tjänster som webbservrar är detta ganska enkelt - du behöver bara tillhandahålla fler instanser med den senaste produktionsbilden eller koden från ditt versionskontrollverktyg. För statliga tjänster som databaser är det mer knepigt. Du måste tillhandahålla nya instanser med din nuvarande produktionsdata, ställa in replikering eller någon form av klustring mellan den nuvarande och de nya instanserna. Detta kan vara en komplex process och för att få det rätt måste du ha mer djupgående kunskap om den valda klustrings- eller replikeringsmodellen.
ClusterControl, som namnet antyder, ger omfattande stöd för att bygga ut klustrade eller replikerade databasinställningar. Metoderna som används är stridstestade genom tusentals utplaceringar. Den levereras med ett kommandoradsgränssnitt (CLI) så att den enkelt kan integreras med konfigurationshanteringssystem. Kom dock ihåg att du kanske inte vill göra ändringar i din pool av databaser för ofta - att tillhandahålla en ny instans tar tid och lägger till en del overhead i befintliga databaser. Därför kanske du vill stanna på en "överprovisionerad" sida lite så att du har lite tid på dig att snurra upp en ny instans innan ditt kluster blir överbelastat.
Sammantaget finns det flera steg du fortfarande måste ta efter den första driftsättningen, för att se till att din miljö är redo för produktion. Med rätt verktyg är det mycket lättare att ta sig dit.