Övervakning av dina databasschemaändringar i MySQL/MariaDB ger en enorm hjälp eftersom det sparar tid på att analysera din databastillväxt, tabelldefinitionsändringar, datastorlek, indexstorlek eller radstorlek. För MySQL/MariaDB, att köra en fråga som refererar informationsschema tillsammans med performance_schema ger dig samlade resultat för vidare analys. Sys-schemat ger dig vyer som fungerar som samlade mätvärden som är mycket användbara för att spåra databasändringar eller aktivitet.
Om du har många databasservrar skulle det vara tråkigt att köra en fråga hela tiden. Du måste också smälta det resultatet till ett mer läsbart och lättare att förstå.
I den här bloggen kommer vi att skapa en automatisering som skulle vara användbar som ditt verktyg för att din befintliga databas ska övervakas och samla in statistik om databasändringar eller schemaändringsoperationer.
Skapa automatisering för databasschemaobjektkontroll
I den här övningen kommer vi att övervaka följande mätvärden:
-
Inga primärnyckeltabeller
-
Duplicera index
-
Generera en graf för det totala antalet rader i våra databasscheman
-
Generera ett diagram för den totala storleken på våra databasscheman
Den här övningen kommer att ge dig information och kan modifieras för att samla in mer avancerad statistik från din MySQL/MariaDB-databas.
Använda Puppet för vår IaC och automation
Denna övning ska använda Puppet för att tillhandahålla automatisering och generera förväntade resultat baserat på de mätvärden vi vill övervaka. Vi kommer inte att täcka installationen och inställningarna för Puppet, inklusive server och klient, så jag förväntar mig att du vet hur du använder Puppet. Du kanske vill besöka vår gamla blogg Automated Deployment of MySQL Galera Cluster to Amazon AWS with Puppet, som täcker installationen och installationen av Puppet.
Vi kommer att använda den senaste versionen av Puppet i den här övningen, men eftersom vår kod består av grundläggande syntax, skulle den köras för äldre versioner av Puppet.
Önskad MySQL-databasserver
I den här övningen kommer vi att använda Percona Server 8.0.22-13 eftersom jag föredrar Percona Server mest för testning och några mindre distributioner, antingen för företag eller personligt bruk.
Graphing Tool
Det finns massor av alternativ att använda, speciellt när man använder Linux-miljön. I den här bloggen kommer jag att använda det enklaste jag hittade och ett opensource-verktyg https://quickchart.io/.
Låt oss leka med docka
Antagandet jag har gjort här är att du har konfigurerat huvudservern med registrerad klient som är redo att kommunicera med huvudservern för att ta emot automatiska distributioner.
Innan vi fortsätter, här är min serverinformation:
Masterserver:192.168.40.200
Client/Agent Server:192.168.40.160
I den här bloggen är vår klient-/agentserver där vår databasserver körs. I ett verkligt scenario behöver det inte vara speciellt för övervakning. Så länge den kan kommunicera in i målnoden säkert, så är det också en perfekt inställning.
Ställ in modulen och koden
-
Gå till huvudservern och i sökvägen /etc/puppetlabs/code/environments/production/module, låt oss skapa de nödvändiga katalogerna för denna övning:
mkdir schema_change_mon/{files,manifests}
-
Skapa de filer vi behöver
touch schema_change_mon/files/graphing_gen.sh
touch schema_change_mon/manifests/init.pp
-
Fyll i init.pp-skriptet med följande innehåll:
class schema_change_mon (
$db_provider = "mysql",
$db_user = "root",
$db_pwd = "example@sqldat.com",
$db_schema = []
) {
$dbs = ['pauldb', 'sbtest']
service { $db_provider :
ensure => running,
enable => true,
hasrestart => true,
hasstatus => true
}
exec { "mysql-without-primary-key" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"select concat(tables.table_schema,'.',tables.table_name,', ', tables.engine) from information_schema.tables left join ( select table_schema , table_name from information_schema.statistics group by table_schema , table_name , index_name having sum( case when non_unique = 0 and nullable != 'YES' then 1 else 0 end ) = count(*) ) puks on tables.table_schema = puks.table_schema and tables.table_name = puks.table_name where puks.table_name is null and tables.table_type = 'BASE TABLE' and tables.table_schema not in ('performance_schema', 'information_schema', 'mysql');\" >> /opt/schema_change_mon/assets/no-pk.log"
}
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :
require => Service['mysql'],
command => "/usr/bin/sudo MYSQL_PWD=\"${db_pwd}\" /usr/bin/mysql -u${db_user} -Nse \"SELECT concat(t.table_schema,'.', t.table_name, '.', t.index_name, '(', t.idx_cols,')') FROM ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='${db}' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) t JOIN ( SELECT table_schema, table_name, index_name, Group_concat(column_name) idx_cols FROM ( SELECT table_schema, table_name, index_name, column_name FROM statistics WHERE table_schema='pauldb' ORDER BY index_name, seq_in_index) t GROUP BY table_name, index_name) u where t.table_schema = u.table_schema AND t.table_name = u.table_name AND t.index_name<>u.index_name AND locate(t.idx_cols,u.idx_cols);\" information_schema >> /opt/schema_change_mon/assets/dupe-indexes.log"
}
}
$genscript = "/tmp/graphing_gen.sh"
file { "${genscript}" :
ensure => present,
owner => root,
group => root,
mode => '0655',
source => 'puppet:///modules/schema_change_mon/graphing_gen.sh'
}
exec { "generate-graph-total-rows" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_rows"
}
exec { "generate-graph-total-len" :
require => [Service['mysql'],File["${genscript}"]],
path => [ '/bin/', '/sbin/' , '/usr/bin/', '/usr/sbin/' ],
provider => "shell",
logoutput => true,
command => "/tmp/graphing_gen.sh total_len"
}
}
-
Fyll i filen graphing_gen.sh. Detta skript kommer att köras på målnoden och generera grafer för det totala antalet rader i vår databas och även den totala storleken på vår databas. För det här skriptet, låt oss göra det enklare och endast tillåta databaser av MyISAM- eller InnoDB-typ.
#!/bin/bash
graph_ident="${1:-total_rows}"
unset json myisam innodb nmyisam ninnodb; json='' myisam='' innodb='' nmyisam='' ninnodb='' url=''; json=$(MYSQL_PWD="example@sqldat.com" mysql -uroot -Nse "select json_object('dbschema', concat(table_schema,' - ', engine), 'total_rows', sum(table_rows), 'total_len', sum(data_length+data_length), 'fragment', sum(data_free)) from information_schema.tables where table_schema not in ('performance_schema', 'sys', 'mysql', 'information_schema') and engine in ('myisam','innodb') group by table_schema, engine;" | jq . | sed ':a;N;$!ba;s/\n//g' | sed 's|}{|},{|g' | sed 's/^/[/g'| sed 's/$/]/g' | jq '.' ); innodb=""; myisam=""; for r in $(echo $json | jq 'keys | .[]'); do if [[ $(echo $json| jq .[$r].'dbschema') == *"MyISAM"* ]]; then nmyisam=$(echo $nmyisam || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; myisam=$(echo $myisam || echo '')$(echo $json| jq .[$r].'dbschema')','; else ninnodb=$(echo $ninnodb || echo '')$(echo $json| jq .[$r]."${graph_ident}")','; innodb=$(echo $innodb || echo '')$(echo $json| jq .[$r].'dbschema')','; fi; done; myisam=$(echo $myisam|sed 's/,$//g'); nmyisam=$(echo $nmyisam|sed 's/,$//g'); innodb=$(echo $innodb|sed 's/,$//g');ninnodb=$(echo $ninnodb|sed 's/,$//g'); echo $myisam "|" $nmyisam; echo $innodb "|" $ninnodb; url=$(echo "{type:'bar',data:{labels:['MyISAM','InnoDB'],datasets:[{label:[$myisam],data:[$nmyisam]},{label:[$innodb],data:[$ninnodb]}]},options:{title:{display:true,text:'Database Schema Total Rows Graph',fontSize:20,}}}"); curl -L -o /vagrant/schema_change_mon/assets/db-${graph_ident}.png -g https://quickchart.io/chart?c=$(python -c "import urllib,os,sys; print urllib.quote(os.environ['url'])")
-
Gå till sist till modulsökvägskatalogen eller /etc/puppetlabs/code/environments /produktion i min installation. Låt oss skapa filen manifests/schema_change_mon.pp.
touch manifests/schema_change_mon.pp-
Fyll sedan filen manifests/schema_change_mon.pp med följande innehåll,
node 'pupnode16.puppet.local' { # Applies only to mentioned node. If nothing mentioned, applies to all.
class { 'schema_change_mon':
}
}
Om du är klar bör du ha följande trädstruktur precis som min,
example@sqldat.com:/etc/puppetlabs/code/environments/production/modules# tree schema_change_mon
schema_change_mon
├── files
│ └── graphing_gen.sh
└── manifests
└── init.ppVad gör vår modul?
Vår modul som heter schema_change_mon samlar in följande,
exec { "mysql-without-primary-key" :...
Som kör ett mysql-kommando och kör en fråga för att hämta tabeller utan primärnycklar. Sedan,
$dbs.each |String $db| {
exec { "mysql-duplicate-index-$db" :som samlar in dubbletter av index som finns i databastabellerna.
Därnäst genererar linjerna grafer baserat på insamlade mätvärden. Det här är följande rader,
exec { "generate-graph-total-rows" :
...
exec { "generate-graph-total-len" :
…När frågan har körts, genererar den grafen, som beror på API:et som tillhandahålls av https://quickchart.io/.
Här är följande resultat av grafen:
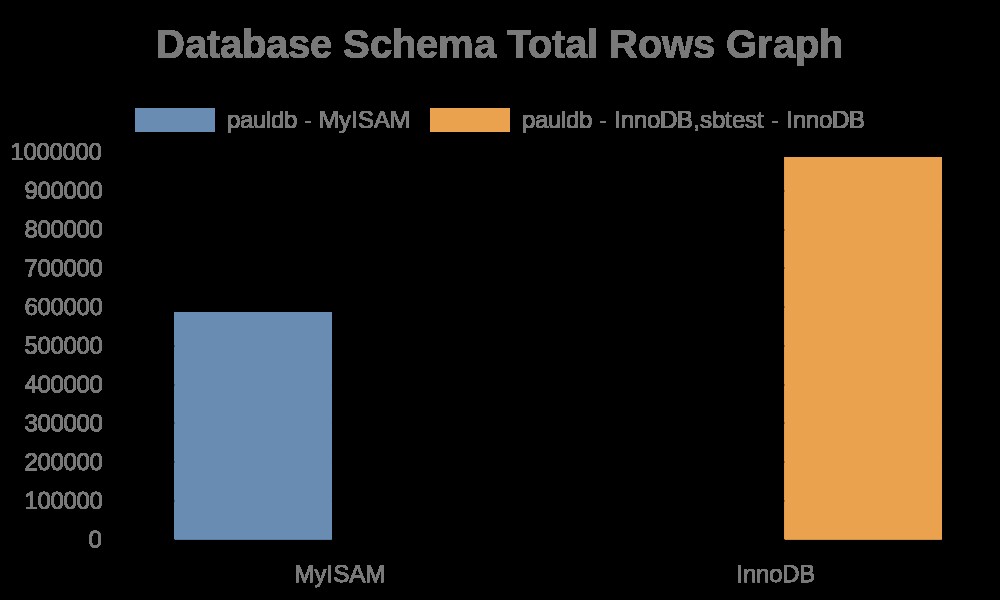
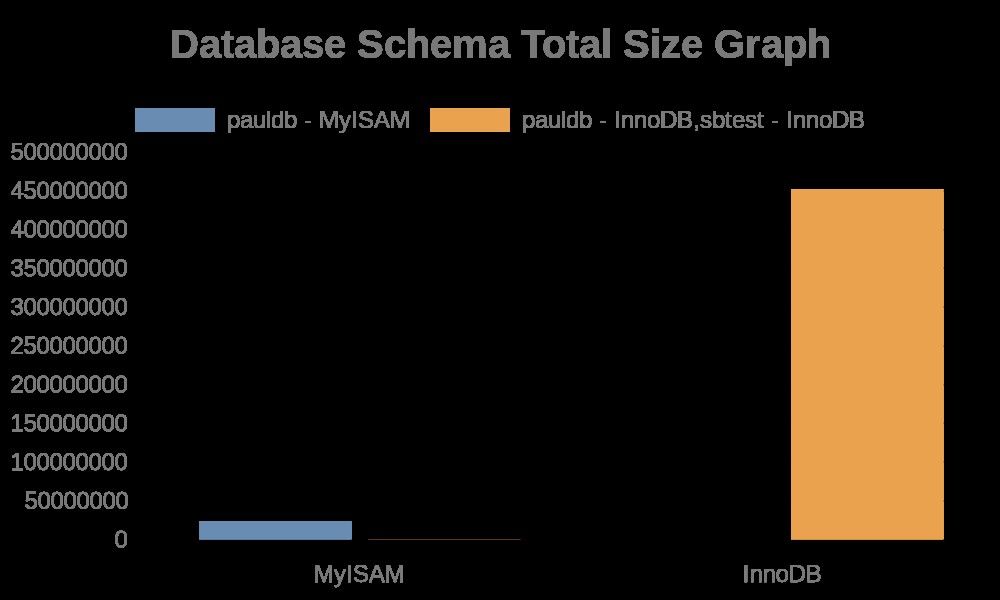
Medan filloggarna helt enkelt innehåller strängar med dess tabellnamn, indexnamn. Se resultatet nedan,
example@sqldat.com:~# tail -n+1 /opt/schema_change_mon/assets/*.log
==> /opt/schema_change_mon/assets/dupe-indexes.log <==
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
pauldb.c.my_index(n,i)
pauldb.c.my_index2(n,i)
pauldb.d.a_b(a,b)
pauldb.d.a_b2(a,b)
pauldb.d.a_b3(a)
pauldb.d.a_b3(a)
pauldb.t3.b(b)
==> /opt/schema_change_mon/assets/no-pk.log <==
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDB
pauldb.b, MyISAM
pauldb.c, InnoDB
pauldb.t2, InnoDB
pauldb.d, InnoDBVarför inte använda ClusterControl?
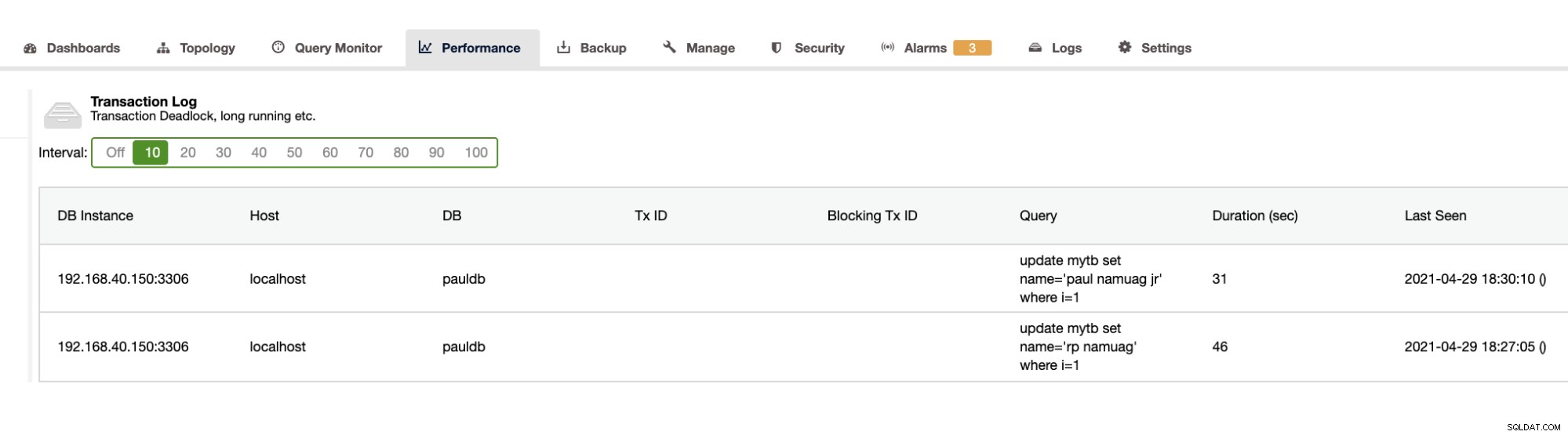
Eftersom vår övning visar upp automatiseringen och få databasschemastatistik såsom ändringar eller operationer, tillhandahåller ClusterControl detta också. Det finns andra funktioner förutom detta och du behöver inte uppfinna hjulet på nytt. ClusterControl kan tillhandahålla transaktionsloggarna såsom dödlägen som visas ovan, eller långvariga frågor som visas nedan:
ClusterControl visar också DB-tillväxten som visas nedan,
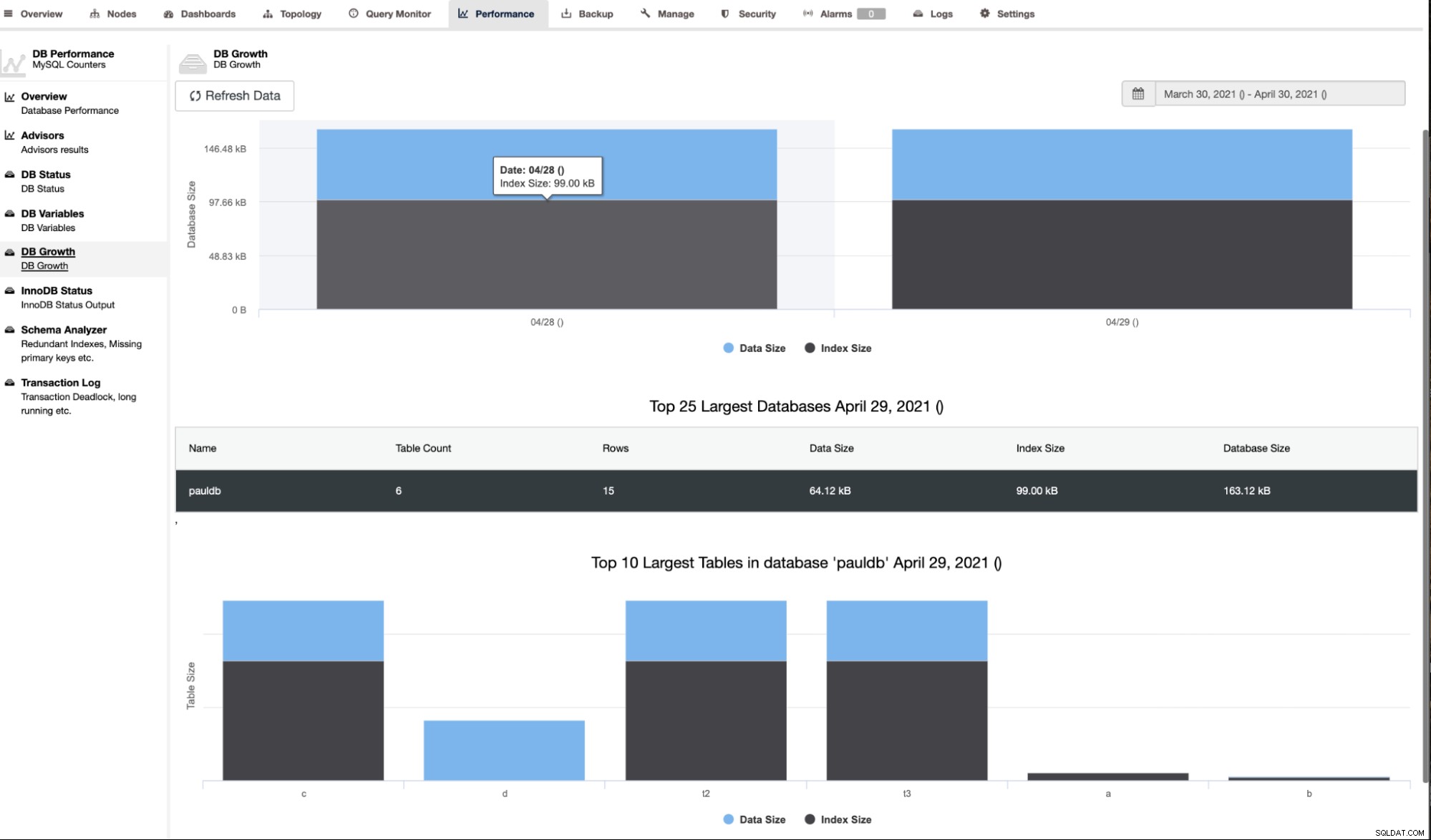
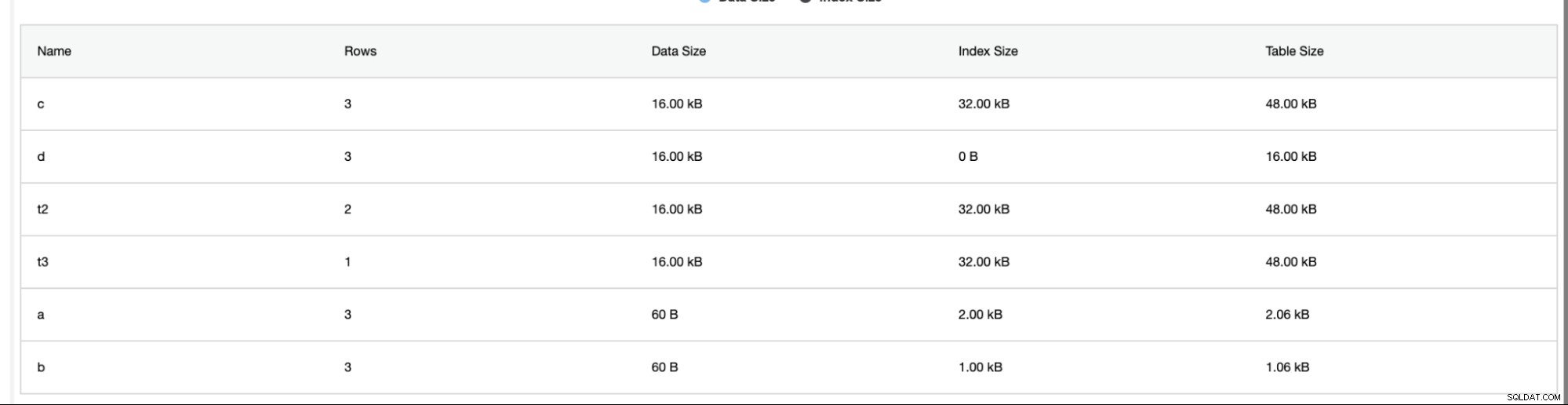
ClusterControl ger också ytterligare information som antal rader, diskstorlek, indexstorlek och total storlek.
Schemaanalysatorn under fliken Performance -> Schema Analyzer är till stor hjälp. Den tillhandahåller tabeller utan primärnycklar, MyISAM-tabeller och dubbletter av index,

Den ger också larm om det upptäcks dubbletter av index eller tabeller utan primära tangenter som nedan,

Du kan kolla in mer information om ClusterControl och dess andra funktioner på vår produktsida.
Slutsats
Att tillhandahålla automatisering för att övervaka dina databasändringar eller annan schemastatistik som skrivningar, dubbletter av index, operationsuppdateringar som DDL-ändringar och många databasaktiviteter är mycket fördelaktigt för DBA:er. Det hjälper till att snabbt identifiera de svaga länkarna och problematiska frågorna som skulle ge dig en översikt över en möjlig orsak till dåliga frågor som skulle låsa din databas eller föråldra din databas.