InnoDB är en av de mest använda lagringsmotorerna i MySQL. Denna lagringsmotor är känd som en högtillförlitlig och högpresterande lagringsmotor och dess viktigaste fördelar inkluderar stöd för radnivålåsning, främmande nycklar och att följa ACID-modellen. InnoDB ersätter MyISAM som standardlagringsmotor sedan MySQL 5.5, som släpptes 2010.
Denna lagringsmotor kan vara otroligt prestanda och kraftfull om den optimeras på rätt sätt - idag tittar vi på de saker vi kan göra för att få den att prestera på bästa sätt, men innan vi dyker i InnoDB bör vi dock förstå vad den tidigare nämnda ACID-modellen är.
Vad är ACID och varför är det viktigt?
ACID är en uppsättning egenskaper för databastransaktioner. Akronymen översätts till fyra ord:Atomicitet, Konsistens, Isolering och Hållbarhet. Kort sagt säkerställer dessa egenskaper att databastransaktioner bearbetas tillförlitligt och garanterar datagiltighet trots fel, strömavbrott eller liknande problem. Ett databashanteringssystem som följer dessa principer sägs vara ett ACID-kompatibelt DBMS. Så här fungerar allt i InnoDB:
- Atomicitet säkerställer att uttalandena i en transaktion fungerar som en odelbar enhet och att deras effekter ses kollektivt eller inte alls;
- Konsistens hanteras av MySQL:s loggningsmekanismer som registrerar alla ändringar i databasen;
- Isolering avser InnoDB:s radnivålåsning;
- Hållbarheten bibehålls också eftersom InnoDB har en loggfil som spårar alla ändringar i systemet.
Förstå InnoDB
Nu när vi har täckt ACID borde vi nog titta på hur InnoDB ser ut under huven. Så här ser InnoDB ut från insidan (bild med tillstånd av Percona):
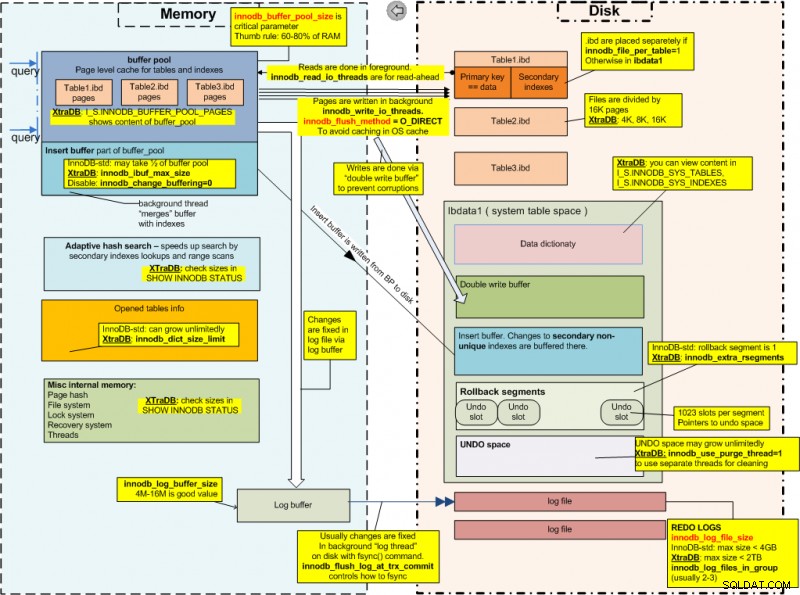 InnoDB Internals
InnoDB InternalsFrån bilden ovan kan vi tydligt se att InnoDB har några parametrar som är avgörande för dess prestanda och dessa är följande:
- Parametern innodb_data_file_path beskriver systemtabellutrymmet (systemtabellutrymmet är lagringsområdet för InnoDB-datalexikonet, dubbla skriv- och ändringsbuffertar och ångraloggar). Parametern visar filen där data som härrör från InnoDB-tabeller kommer att lagras;
- Parametern innodb_buffer_pool_size är en minnesbuffert som InnoDB använder för att cachelagra data och index för sina tabeller;
- Parametern innodb_log_file_size visar storleken på InnoDB-loggfiler;
- parametern innodb_log_buffer_size används för att skriva till loggfilerna på disken;
- Innodb_flush_log_at_trx_commit-parametern kontrollerar balansen mellan strikt ACID-efterlevnad och högre prestanda;
- parametern innodb_lock_wait_timeout är hur lång tid i sekunder en InnoDB-transaktion väntar på en radlås innan den ger upp;
- Parametern innodb_flush_method definierar metoden som används för att spola data till InnoDB-datafiler och loggfiler som kan påverka I/O-genomströmningen.
InnoDB lagrar också data från sina tabeller i en fil som heter ibdata1 - loggarna lagras dock i två separata filer som heter ib_logfile0 och ib_logfile1:alla dessa tre filer finns i /var/lib/mysql katalog.
För att göra InnoDB så presterande som möjligt måste vi finjustera dessa parametrar och optimera dem så mycket vi kan genom att titta på våra tillgängliga hårdvaruresurser.
Justera InnoDB för hög prestanda
Följ dessa steg för att justera InnoDB:s prestanda på din hårdvara:
-
För att utöka innodb_data_file_path automatiskt, ange autoextend-attributet i inställningen och starta om servern. Till exempel:
innodb_data_file_path=ibdata1:10M:autoextendNär parametern autoextend används, ökar datafilen automatiskt i storlek med 8MB steg varje gång utrymme krävs. En ny automatiskt förlängande datafil kan också specificeras så (i detta fall kallas den nya datafilen ibdata2):
innodb_data_file_path=ibdata1:10M;ibdata2:10M:autoextend-
När du använder InnoDB är den huvudsakliga mekanismen som används buffertpoolen. InnoDB är starkt beroende av buffertpoolen och som en tumregel bör parametern innodb_buffer_pool_size vara cirka 60 % till 80 % av det totala tillgängliga RAM-minnet på servern. Tänk på att du bör lämna lite RAM-minne för de processer som körs i operativsystemet också;
-
InnoDB:s innodb_log_file_size bör vara så stor som möjligt, men inte större än nödvändigt. Tänk i det här fallet på att en större loggfilstorlek är bättre för prestanda, men ju större den är, desto längre återhämtningstid efter en krasch krävs. Som sådan finns det ingen "one size fits all"-lösning, men det sägs att den kombinerade storleken på loggfilerna ska vara tillräckligt stor. Detta hjälper MySQL-servern att regelbundet arbeta med kontrollpunkter och diskrensningsaktivitet. Detta sparar för mycket CPU och disk-IO och kan köras smidigt under sin topptid eller hög arbetsbelastning. Även om det rekommenderade tillvägagångssättet är att testa och experimentera själv och hitta det optimala värdet själv;
-
Värdet för innodb_log_buffer_size bör ställas in på minst 16M. En stor loggbuffert gör att stora transaktioner kan köras utan att loggen behöver skrivas till disken innan transaktionerna begår att spara några disk I/O;
-
När du ställer in innodb_flush_log_at_trx_commit, tänk på att den här parametern accepterar tre värden - 0, 1 och 2. Med ett värde på 1 får du ACID-kompatibilitet och med värdena 0 eller 2 får du mer prestanda, men mindre tillförlitlighet eftersom transaktioner för vilka loggar ännu inte har spolas till disken kan gå förlorade vid en krasch;
-
För att sätta innodb_lock_wait_timeout till ett korrekt värde, kom ihåg att denna parameter definierar tiden i sekunder (standardvärdet är 50) före utfärdar följande fel och återställer den aktuella satsen:
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction-
I InnoDB finns det flera spolningsmetoder tillgängliga. Som standard är den här inställningen inställd på "async_unbuffered" på Windows-datorer om värdet är satt till NULL och till "fsync" i Linux-maskiner. Här är vad metoderna är och vad de gör:
| InnoDB Flush Method | Syfte |
| normal | InnoDB kommer att använda simulerad asynkron I/O och buffrad I/O. |
| obuffrad | InnoDB kommer att använda simulerad asynkron I/O och icke-buffrad I/O. |
| async_unbuffered | InnoDB kommer att använda Windows asynkron I/O och icke-buffrad I/O. Standardinställningar på Windows-datorer. |
| fsync | InnoDB kommer att använda funktionen fsync() för att rensa data och loggfiler. Standardinställning på Linux-datorer. |
| O_DSYNC | InnoDB kommer att använda O_SYNC för att öppna och spola loggfilerna och fsync()-funktionen för att spola datafilerna. O_DSYNC är snabbare än O_DIRECT, men data kan eller kanske inte är konsekventa på grund av latens eller en direkt krasch. |
| nosync | Används för intern prestandatestning - stöds inte. |
| littlesync | Används för intern prestandatestning - stöds inte. |
| O_DIRECT | InnoDB kommer att använda O_DIRECT för att öppna datafilerna och fsync()-funktionen för att tömma både data och loggfiler. I jämförelse med O_DSYNC är O_DIRECT stabilare och mer datakonsekvent, men långsammare. OS-cachen undviks med den här inställningen - den här inställningen är den rekommenderade inställningen på Linux-datorer. |
| O_DIRECT_NO_FSYNC | InnoDB kommer att använda O_DIRECT under spolning av I/O - "NO_FSYNC"-delen definierar att funktionen fsync() kommer att hoppas över. |
- Du bör också överväga att aktivera inställningen innodb_file_per_table. Denna parameter är PÅ som standard i MySQL 5.6 och högre. Den här parametern befriar dig från hanteringsproblem relaterade till InnoDB-tabeller genom att lagra dem i separata filer och undvika uppsvällda huvudordböcker och systemtabeller. Genom att aktivera den här variabeln undviker du också dataåterställningskomplexiteten när en viss tabell är skadad
- Nu när du ändrade dessa inställningar enligt instruktionerna ovan borde du vara nästan redo att börja! Innan du kommer igång bör du förmodligen hålla ett öga på den mest trafikerade filen i hela InnoDB-infrastrukturen - ibdata1.
Hantera ibdata1
Det finns flera klasser av information som lagras i ibdata1:
- Data från InnoDB-tabeller;
- Indexen för InnoDB-tabeller;
- InnoDB-tabellmetadata;
- Multiversion Concurrency Control (MVCC)-data;
- Dubbelskrivningsbufferten - en sådan buffert gör det möjligt för InnoDB att återhämta sig från halvskrivna sidor. Syftet med en sådan buffert är att förhindra datakorruption;
- Infogningsbufferten - en sådan buffert används av InnoDB för att buffra uppdateringar till samma sida så att de kan utföras på en gång och inte en efter en.
När man hanterar stora datamängder kan ibdata1-filen bli extremt stor och detta kan vara kärnan i ett mycket frustrerande problem - filen kan bara växa och som standard kan den inte krympa. Du kan stänga av MySQL och ta bort den här filen men detta rekommenderas inte om du inte vet vad du gör. När den raderas kommer MySQL inte att fungera korrekt eftersom ordboken och systemtabellerna är borta, vilket gör att huvudsystemtabellen är skadad.
För att förminska ibdata1 en gång för alla, följ dessa steg:
- Dumpa all data från InnoDB-databaser. Du kan använda mysqldump eller mysqlpump för denna åtgärd;
- Släpp alla databaser utom databaserna mysql, performance_schema och information_schema;
- Stoppa MySQL;
- Lägg till följande till din my.cnf-fil:
[mysqld] innodb_file_per_table = 1 innodb_flush_method = O_DIRECT innodb_log_file_size = 25% of innodb_buffer_pool_size innodb_buffer_pool_size = up to 60-80% of available RAM. - Ta bort filerna ibdata1 och ib_logfile* (dessa kommer att återskapas vid nästa omstart av MySQL);
- Starta MySQL och återställ data från dumpen du tog tidigare. Efter att ha utfört stegen som beskrivs ovan kommer filen ibdata1 fortfarande att växa, men den kommer inte längre att innehålla data från InnoDB-tabeller - filen kommer bara att innehålla metadata och varje InnoDB-tabell kommer att existera utanför ibdata1. Nu, om du går till katalogen /var/lib/mysql, kommer du att se två filer som representerar varje tabell du har med InnoDB-motorn. Filerna kommer att se ut så här:
- degraderbar.frm
- demotable.ibd
.frm-filen innehåller lagringsmotorhuvudet och .ibd-filen innehåller tabelldata och index för din tabell.
Innan du implementerar ändringarna, se till att finjustera parametrarna enligt din infrastruktur. Dessa parametrar kan göra eller bryta InnoDB-prestanda så se till att hålla ett öga på dem hela tiden. Nu borde du vara igång!
Sammanfattning
För att sammanfatta, att optimera prestandan för InnoDB kan vara en stor fördel om du utvecklar applikationer som kräver dataintegritet och hög prestanda på samma gång - InnoDB låter dig ändra hur mycket minne motorn tillåts konsumera, för att ändra loggfilens storlek, spolningsmetoden som motorn använder och så vidare - dessa ändringar kan få InnoDB att prestera extremt bra om de är korrekt inställda. Innan du utför några förbättringar bör du dock akta dig för konsekvenserna av dina handlingar för både din server och MySQL.
Som alltid, innan du optimerar något för prestanda alltid ta (och testa!) säkerhetskopior så att du kan återställa din data om det behövs och alltid testa eventuella ändringar på en lokal server innan du rullar ut ändringarna till produktionen.