Med tanke på det nuvarande stora användningsfallet för en databas för att hämta data, blir det mycket viktigt att dess prestanda är mycket hög och det kan bara uppnås om data hämtas på ett så effektivt sätt som möjligt från lagringen. Det har gjorts många framgångsrika uppfinningar och implementeringar för att uppnå samma sak. En av de välkända metoderna som används av de flesta databaser är att ha ett index på bordet.
Vad är ett databasindex?
Databas Index, som namnet antyder, upprätthåller ett index över de faktiska data och förbättrar därmed prestandan för att hämta data från den faktiska tabellen. I en mer databasterminologi tillåter indexet att hämta sida som innehåller indexerad data i en mycket minimal genomgång eftersom data sorteras i specifik ordning. Indexförmån kommer på bekostnad av ytterligare lagringsutrymme för att skriva ytterligare data. Index är specifika för den underliggande tabellen och består av en eller flera nycklar (dvs en eller flera kolumner i den angivna tabellen). Det finns i första hand två typer av indexarkitektur
- Klustrat index – Indexdata lagras tillsammans med andra delar av data och data sorteras baserat på indexnyckel. Som mest kan det bara finnas ett index i denna kategori för en specificerad tabell.
- Icke-klustrade index – Indexdata lagras separat och har en pekare till lagringen där andra delar av data lagras. Detta är också känt som sekundärt index. Det kan finnas så många index av denna kategori som du vill på en specificerad tabell.
Det finns olika datastrukturer som används för att implementera index, några av de allmänt antagna av de flesta databaser är B-Tree och Hash.
Vad är ett PostgreSQL-index?
PostgreSQL stöder endast icke-klustrade index. Det betyder indexera data och fullständiga data (hädanefter kallade högdata ) lagras i ett separat lager. Icke-klustrade index är som "Innehållsförteckning" i vilket dokument som helst, där vi först kontrollerar sidnumret och sedan kontrollerar dessa sidnummer för att läsa hela innehållet. För att få fullständig data baserat på ett index, upprätthåller den en pekare till motsvarande högdata. Det är samma sak som efter att ha vetat sidnumret måste den gå till den sidan och få det faktiska innehållet på sidan.
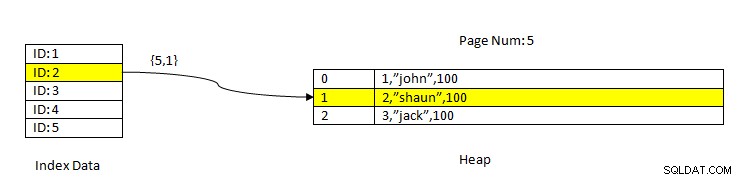 PostgreSQL:Data läses med Index
PostgreSQL:Data läses med Index Tänk till exempel en tabell med tre kolumner och ett index på kolumn ID . För att LÄSA data baserat på nyckeln ID=2, genomsöks först den Indexerade data med ID-värdet 2. Denna innehåller en pekare (kallad som Item Pointer) i termer av sidnummer (dvs blocknummer) och förskjutning av data inom den sidan. I det aktuella exemplet pekar indexet på sidnummer 5 och den andra raden på sidan som i sin tur håller sig offset till hela data(2,”Shaun”,100). Observera att hela data också innehåller indexerade data vilket innebär att samma data upprepas i två lagringar.
Hur hjälper INDEX till att förbättra prestanda? Tja, för att välja en INDEX-post skannar den inte alla sidor sekventiellt, utan behöver bara delvis skanna några av sidorna med den underliggande Index-datastrukturen. Men det finns en twist, eftersom varje post som hittas från indexdata måste leta efter hela data i Heap-data, vilket orsakar mycket slumpmässig I/O och det anses fungera långsammare än Sequential I/O. Så bara om en liten procentandel av poster väljs ut (som bestäms baserat på PostgreSQL-optimeringskostnaden), är det bara PostgreSQL som väljer Index Scan annars, även om det finns ett index på bordet, fortsätter den att använda Sequence Scan.
Sammanfattningsvis, även om indexskapandet påskyndar prestandan, bör det väljas noggrant eftersom det har overhead vad gäller lagring, försämrad INSERT-prestanda.
Nu kanske vi undrar, om vi bara behöver indexdelen av data, kan vi bara hämta från indexlagringssidan? Tja, svaret på detta är direkt relaterat till hur MVCC fungerar på indexlagringen som förklaras härnäst.
Använda MVCC för indexering
Precis som Heap-sidor, upprätthåller indexsidan flera versioner av index tuple men den behåller inte synlighetsinformation. Som förklarats i min tidigare MVCC blogg, för att bestämma lämplig synlig version av tupler, kräver det att jämföra transaktionen. Transaktionen som infogade/uppdaterade/raderade tupel bibehålls tillsammans med heap tupel men detsamma upprätthålls inte med index tupel. Detta görs enbart för att spara lagring och det är en avvägning mellan utrymme och prestanda.
För att nu komma tillbaka till den ursprungliga frågan, eftersom synlighetsinformationen i Index tuple inte finns där, måste den konsultera motsvarande heap tuple för att se om den valda datan är synlig. Så även om andra delar av data från heap tuple inte krävs, måste du fortfarande komma åt heap-sidorna för att kontrollera synlighet. Men återigen, det finns en twist om alla tuplar på en given sida (sida pekad med index, dvs. ItemPointer) är synliga och då inte behöver hänvisa varje artikel på Heap-sidan för "synlighetskontroll" och därför kan data endast returneras från indexsidan. Detta specialfall kallas "Endast indexsökning". För att stödja detta upprätthåller PostgreSQL en synlighetskarta för varje sida för att kontrollera sidnivåns synlighet.
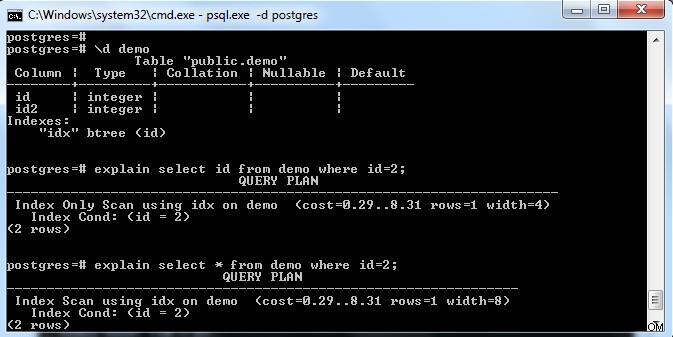
Som visas i bilden ovan finns det ett index i tabellen "demo" med en nyckel på kolumn "id". Om vi försöker välja endast indexfält (dvs. id) så valde den "Endast indexsökning" (med tanke på att hänvisningssidan är helt synlig).
Klustrat index
Det finns inget stöd för direkt klustrade index i PostgreSQL men det finns ett indirekt sätt att delvis uppnå detsamma. Detta uppnås med nedanstående SQL-kommandon:
CLUSTER [VERBOSE] table_name [ USING index_name ]
CLUSTER [VERBOSE]Det första kommandot instruerar databasen att klustra en tabell (d.v.s. att sortera tabell) med hjälp av det givna indexet. Detta index borde redan ha skapats. Denna klustring är endast engångsoperation och dess påverkan kvarstår inte efter den efterföljande operationen på denna tabell, dvs om fler poster infogas/uppdateras kanske tabellen inte förblir i ordning. Om användaren behöver för att fortfarande hålla tabellen klustrad (ordnad) kan de använda det första kommandot utan att ange ett indexnamn.
Det andra kommandot är bara användbart för att klustra om tabellen (dvs tabellen som redan var klustrad med hjälp av något index). Detta kommando grupperar om alla tabeller i den aktuella databasen som är synliga för den aktuella anslutna användaren.
Till exempel i figuren nedan returnerar den första SELECT poster i osorterad ordning eftersom det inte finns något klustrat index. Även om det redan finns icke-klustrade index men posterna väljs från högområdet där posterna inte sorteras.
Den andra SELECT returnerar posterna sorterade efter kolumn "id" eftersom de har klustrats med index som innehåller kolumnen "id".
Den tredje SELECT returnerar partiella poster i sorterad ordning men nyligen infogade poster sorteras inte. Den fjärde SELECT returnerar igen alla poster i sorterad ordning eftersom tabellen har klustrats igen
 PostgreSQL-klusterkommando
PostgreSQL-klusterkommando Indextyp
PostgreSQL tillhandahåller flera typer av index enligt nedan:
- B-träd
- Hash
- GiST
- GIN
- BRIN
Varje indextyp implementerar olika typer av underliggande datastruktur, som är bäst lämpad för olika typer av frågor. Som standard skapas B-Tree index, vilket är mycket använda index. Detaljer om varje indextyp kommer att behandlas i en framtida blogg.
Övrigt:Partiellt och uttrycksindex
Vi har bara diskuterat index på en eller flera kolumner i en tabell men det finns två andra sätt att skapa index på PostgreSQL
- Delvis index: Partiellt index är ett index byggt med hjälp av delmängden av en nyckelkolumn för en viss tabell. Delmängden definieras av det villkorliga uttrycket som ges under skapa index. Så med det partiella indexet sparas lagringsutrymme för lagring av indexdata. Så användaren bör välja villkoret på ett sådant sätt att det inte är särskilt vanliga värden, eftersom för mer frekventa (vanliga) värden ändå inte kommer indexskanning att väljas. Resten av funktionaliteten förblir densamma som för ett normalt index. Exempel:partiellt index
- Uttrycksindex: Uttrycksindex ger en annan typ av flexibilitet i PostgreSQL. Alla index som diskuterats hittills, inklusive partiella index, finns på en viss uppsättning kolumner. Men vad händer om en fråga involverar åtkomst till en tabell baserad på uttrycket (uttryck som involverar en eller flera kolumner), utan ett uttrycksindex kommer den inte att välja indexskanning. Så för att snabbt komma åt den här typen av frågor tillåter PostgreSQL att skapa ett index på ett uttryck. Resten av funktionaliteten förblir densamma som för ett normalt index.
 Exempel:Uttrycksindex
Exempel:Uttrycksindex
Indexlagring i InnoDB
Användningen och funktionaliteten för Index är för det mesta densamma som i PostgreSQL med en stor skillnad när det gäller Clustered Index.
InnoDB stöder två kategorier av index:
- Klustrat index
- Sekundärt index
Klustrat index
Clustered Index är en speciell sorts index i InnoDB. Här lagras inte den indexerade datan separat utan är en del av hela raddata. Med andra ord tvingar det klustrade indexet bara tabelldata att sorteras fysiskt med hjälp av nyckelkolumnen i indexet. Det kan betraktas som "Ordbok", där data sorteras baserat på alfabetet.
Eftersom det klustrade indexet sorterar rader med en indexnyckel, kan det bara finnas ett klustrat index. Dessutom måste det finnas ett klustrat index eftersom InnoDB använder detsamma för att optimalt manipulera data under olika dataoperationer.
Klustrade index skapas automatiskt (som en del av tabellskapandet) med en av tabellkolumnerna enligt nedanstående prioritet:
- Använda primärnyckeln om primärnyckeln nämns som en del av tabellskapandet.
- Väljer en unik kolumn där alla nyckelkolumner INTE är NULL.
- Annars genererar internt ett dolt klustrat index i en systemkolumn som innehåller rad-ID:t för varje rad.
Till skillnad från PostgreSQL icke-klustrade index, får InnoDB tillgång till en rad med hjälp av klustrade index snabbare eftersom indexsökningen leder direkt till sidan med alla raddata och därmed undviker slumpmässig I/O.
Att få tabelldata i sorterad ordning med hjälp av det klustrade indexet går också mycket snabbt eftersom all data redan är sorterad och även hela data är tillgänglig.
Sekundärt index
Indexet som skapats uttryckligen i InnoDB anses vara ett sekundärt index, vilket liknar PostgreSQL icke-klustrade index. Varje post i den sekundära indexlagringen innehåller en primärnyckelkolumn av raderna (som användes för att skapa Clustered Index) och även de kolumner som anges för att skapa ett sekundärt index.
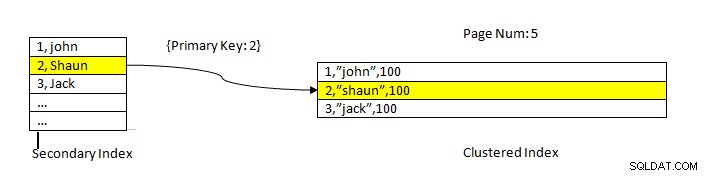 InnoDB:Data läses med index
InnoDB:Data läses med index Hämtning av data med hjälp av ett sekundärt index liknar PostgreSQL förutom att InnoDB sekundär indexsökning ger en primärnyckel som en pekare för att hämta återstående data från det klustrade indexet.
Till exempel, som visas i bilden ovan, finns det klustrade indexet i kolumnen ID, så tabelldata sorteras efter detsamma. Det sekundära indexet finns i kolumnen "namn ”, så som vi kan se har det sekundära indexet både ID- och namnvärde. När vi väl slår upp med hjälp av det sekundära indexet hittar den lämplig plats med motsvarande nyckelvärde. Sedan används motsvarande primärnyckel för att referera till den återstående delen av data från det klustrade indexet.
MVCC för index
Det klustrade indexet MVCC använder den traditionella InnoDB Undo Model (Faktiskt samma som hela data MVCC, eftersom det klustrade indexet inte är annat än hela data).
Men det sekundära Index MVCC använder ett lite annorlunda tillvägagångssätt för att upprätthålla MVCC. Vid uppdatering av det sekundära indexet raderas den gamla indexposten och nya poster infogas i samma lagring, dvs. UPPDATERING är inte på plats. Äntligen rensas gamla indexposter. Vid det här laget kanske du har märkt att InnoDB sekundärt index MVCC är nästan detsamma som för PostgreSQL MVCC-modellen.
Indextyp
InnoDB stöder endast B-Tree typ av index och behöver därför inte specificeras när index skapas.
Övrigt:Adaptiva hashindex
Som nämnts i föregående avsnitt att endast B-Tree typindex stöds av InnoDB men det finns en twist. InnoDB har funktionen att automatiskt upptäcka om frågan kan dra nytta av att bygga ett hashindex och även hela tabellens data kan passa in i minnet, då gör den det automatiskt.
Hashindexet byggs med det befintliga B-Tree-indexet beroende på frågan. Om det finns flera sekundära B-Tree-index, kommer den att välja det som kvalificerar sig enligt frågan. Det byggda hashindexet är inte komplett, det bygger bara ett partiellt index enligt dataanvändningsmönstret.
Detta är en av de riktigt kraftfulla funktionerna för att dynamiskt förbättra frågeprestanda.
Slutsats
Användningen av vilket index som helst i vilken databas som helst är till stor hjälp för att förbättra READ-prestandan, men samtidigt försämrar det INSERT/UPDATE-prestandan eftersom den behöver skriva ytterligare data. Så indexet bör väljas mycket klokt och bör skapas endast om indexnycklarna börjar användas som ett predikat för att hämta data.
InnoDB ger en mycket bra funktion när det gäller det klustrade indexet, vilket kan vara mycket användbart beroende på användningsfallen. Dessutom är dess adaptiva hashindexering mycket kraftfull.
Medan PostgreSQL tillhandahåller olika typer av index, som verkligen kan ge funktionsräckviddsalternativ och en eller alla kan användas beroende på affärsanvändningsfallet. Även partial- och uttrycksindexen är ganska användbara beroende på användningsfallet.