I våra tidigare bloggar har vi motiverat varför du behöver en databas-failover och har förklarat hur en failover-mekanism fungerar. Jag delar detta om du har frågor om varför du ska ställa in en failover-mekanism för din MySQL-databas. Om du gör det, läs våra tidigare blogginlägg.
Hur man ställer in automatisk failover
Fördelen med att använda MySQL eller MariaDB för att automatiskt hantera din failover är att det finns tillgängliga verktyg du kan använda och implementera i din miljö. Från öppen källkod till lösningar i företagsklass. De flesta verktyg är inte bara failover-kapabla, det finns andra funktioner som switchover, övervakning och avancerade funktioner som kan erbjuda fler hanteringsmöjligheter för ditt MySQL-databaskluster. Nedan går vi igenom de vanligaste som du kan använda.
Använder MHA (Master High Availability)
Vi har tagit detta ämne med MHA med dess vanligaste problem och hur man åtgärdar dem. Vi har även jämfört MHA med MRM eller med MaxScale.
Inställning med MHA för hög tillgänglighet kanske inte är lätt men det är effektivt att använda och flexibelt eftersom det finns inställbara parametrar som du kan definiera för att anpassa din failover. MHA har testats och använts. Men allt eftersom tekniken går framåt har MHA släpat efter eftersom det inte stöder GTID för MariaDB och det har inte drivit några uppdateringar de senaste 2 eller 3 åren.
Genom att köra masterha_manager-skriptet
masterha_manager --conf=/etc/app1.cnfDär ett exempel /etc/app1.cnf ska se ut enligt följande,
[server default]
user=cmon
password=pass
ssh_user=root
# working directory on the manager
manager_workdir=/var/log/masterha/app1
# working directory on MySQL servers
remote_workdir=/var/log/masterha/app1
[server1]
hostname=node1
candidate_master=1
[server2]
hostname=node2
candidate_master=1
[server3]
hostname=node3
no_master=1Parametrar som no_master och candidate_master ska vara avgörande när du ställer in att vitlista önskade noder ska vara din målmästare och noder som du inte vill ska vara en master.
När du har ställt in, är du redo att ha failover för din MySQL-databas om ett fel på den primära eller mastern uppstår. Skriptet masterha_manager hanterar failover (automatisk eller manuell), fattar beslut om när och var failover ska ske, och hanterar slavåterställning under marknadsföring av kandidatmastern för tillämpning av differentiella reläloggar. Om masterdatabasen dör kommer MHA Manager att samordna med MHA Node-agenten eftersom den tillämpar differentiella reläloggar till slavarna som inte har de senaste binlog-händelserna från mastern.
Ta reda på vad MHA Node-agenten gör och dess inblandade skript. I grund och botten är det skriptet som MHA Manager kommer att anropa när failover inträffar. Den kommer att vänta på sitt mandat från MHA Manager när den söker efter den senaste slaven som innehåller binlog-händelserna och kopierar saknade händelser från slaven med hjälp av scp och tillämpar dem på sig själv. Som nämnts tillämpar den reläloggar, rensa reläloggar eller spara binära loggar.
Om du vill veta mer om inställbara parametrar och hur du anpassar din failover-hantering, kolla in Parameters wiki-sidan för MHA.
Använda Orchestrator
Orchestrator är ett MySQL- och MariaDB-verktyg för hög tillgänglighet och replikeringshantering. Den släpps av Shlomi Noach under villkoren i Apache-licensen, version 2.0. Det här är en programvara med öppen källkod och hanterar automatisk failover men det finns massor av saker du kan anpassa eller göra för att hantera din MySQL/MariaDB-databas förutom återställning eller automatisk failover.
Installation av Orchestrator kan vara enkelt eller okomplicerat. När du har laddat ner de specifika paket som krävs för din målmiljö är du redo att registrera ditt kluster och noder för att övervakas av Orchestrator. Den tillhandahåller ett användargränssnitt för vilket det är mycket lätt att hantera men har massor av justerbara parametrar eller uppsättning kommandon som du kan använda för att uppnå din failover-hantering.
Låt oss tänka på att du äntligen har konfigurerat och Registrering av klustret genom att lägga till vår primära eller huvudnod kan göras med kommandot nedan,
$ orchestrator -c discover -i pupnode21:3306
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: pupnode21
2021-01-07 12:32:31 DEBUG Cache hostname resolve pupnode21 as pupnode21
2021-01-07 12:32:31 DEBUG Connected to orchestrator backend: orchestrator:example@sqldat.com(127.0.0.1:3306)/orchestrator?timeout=1s
2021-01-07 12:32:31 DEBUG Orchestrator pool SetMaxOpenConns: 128
2021-01-07 12:32:31 DEBUG Initializing orchestrator
2021-01-07 12:32:31 INFO Connecting to backend 127.0.0.1:3306: maxConnections: 128, maxIdleConns: 32
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.222
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.222 as 192.168.40.222
2021-01-07 12:32:31 DEBUG Hostname unresolved yet: 192.168.40.223
2021-01-07 12:32:31 DEBUG Cache hostname resolve 192.168.40.223 as 192.168.40.223
pupnode21:3306Nu har vi lagt till vårt kluster.
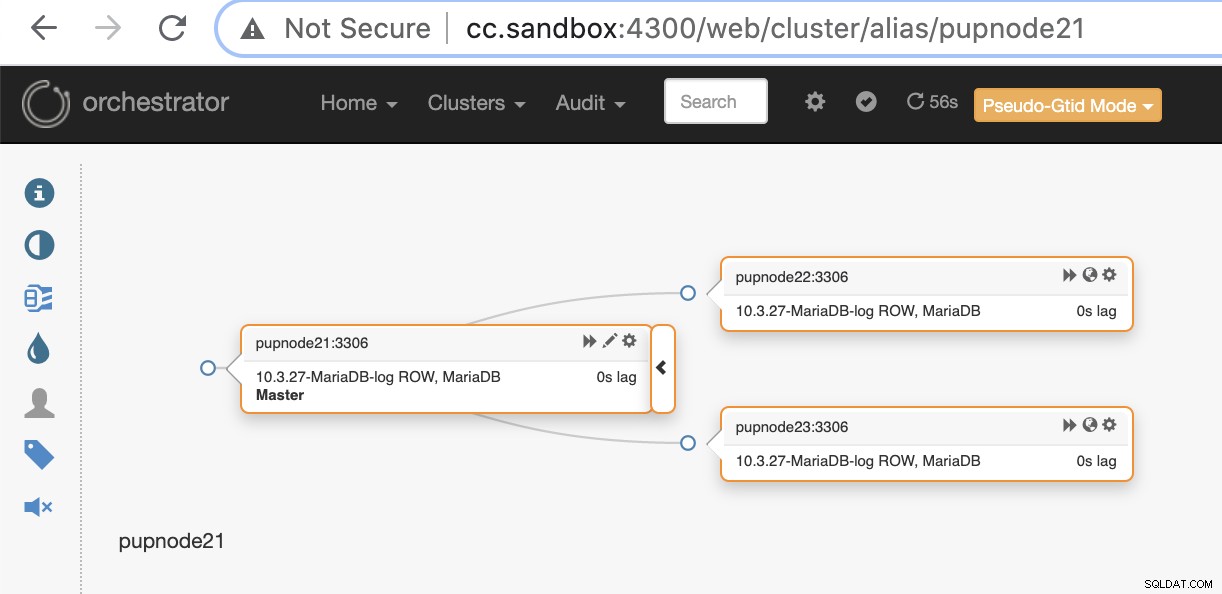
Om en primär nod misslyckas (maskinvarufel eller påträffad kraschad), kommer Orchestrator att upptäcka och hitta den mest avancerade noden som ska marknadsföras som primär- eller masternod.
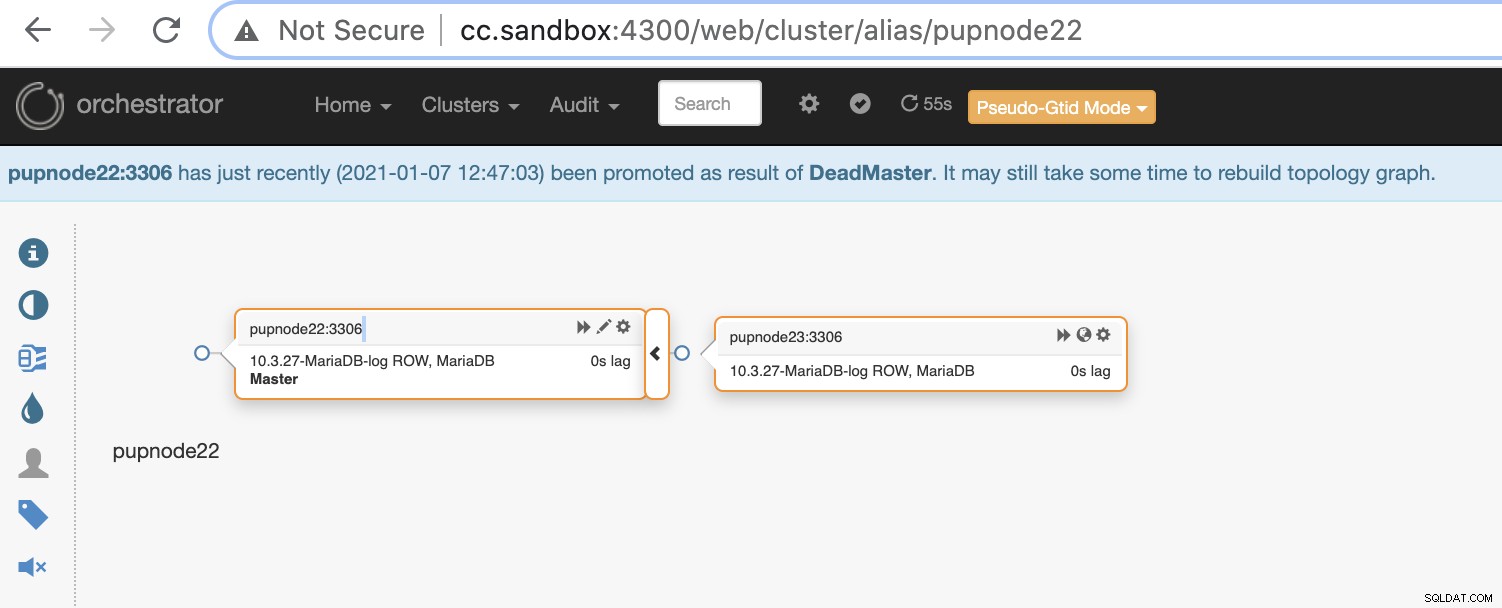
Nu har vi två noder kvar i klustret medan den primära är nere .
$ orchestrator-client -c topology -i pupnode21:3306
pupnode21:3306 [unknown,invalid,10.3.27-MariaDB-log,rw,ROW,>>,downtimed]
$ orchestrator-client -c topology -i pupnode22:3306
pupnode22:3306 [0s,ok,10.3.27-MariaDB-log,rw,ROW,>>]
+ pupnode23:3306 [0s,ok,10.3.27-MariaDB-log,ro,ROW,>>,GTID]Använda MaxScale
MariaDB MaxScale har stöds som en databaslastbalanserare. Under åren har MaxScale växt och mognat, utökat med flera rika funktioner och det inkluderar automatisk failover. Sedan MariaDB MaxScale 2.2 släpptes introducerar den flera nya funktioner, inklusive hantering av failover för replikeringskluster. Du kan läsa vår tidigare blogg om MaxScale failover-mekanism.
Att använda MaxScale är under BSL även om programvaran är fritt tillgänglig men kräver att du åtminstone köper tjänst med MariaDB. Det kanske inte är lämpligt men om du har skaffat MariaDB företagstjänster kan detta vara en stor fördel om du behöver failover-hantering och dess andra funktioner.
Installationen av MaxScale är enkel men att ställa in den nödvändiga konfigurationen och definiera dess parametrar är det inte, och det kräver att du måste förstå programvaran. Du kan se deras konfigurationsguide.
För snabb och snabb implementering kan du använda ClusterControl för att installera MaxScale åt dig i din befintliga MySQL/MariaDB-miljö.
När den är installerad kan du konfigurera din Moodle-databas genom att peka din värd på MaxScale IP eller värdnamn och läs-skrivporten. Till exempel,
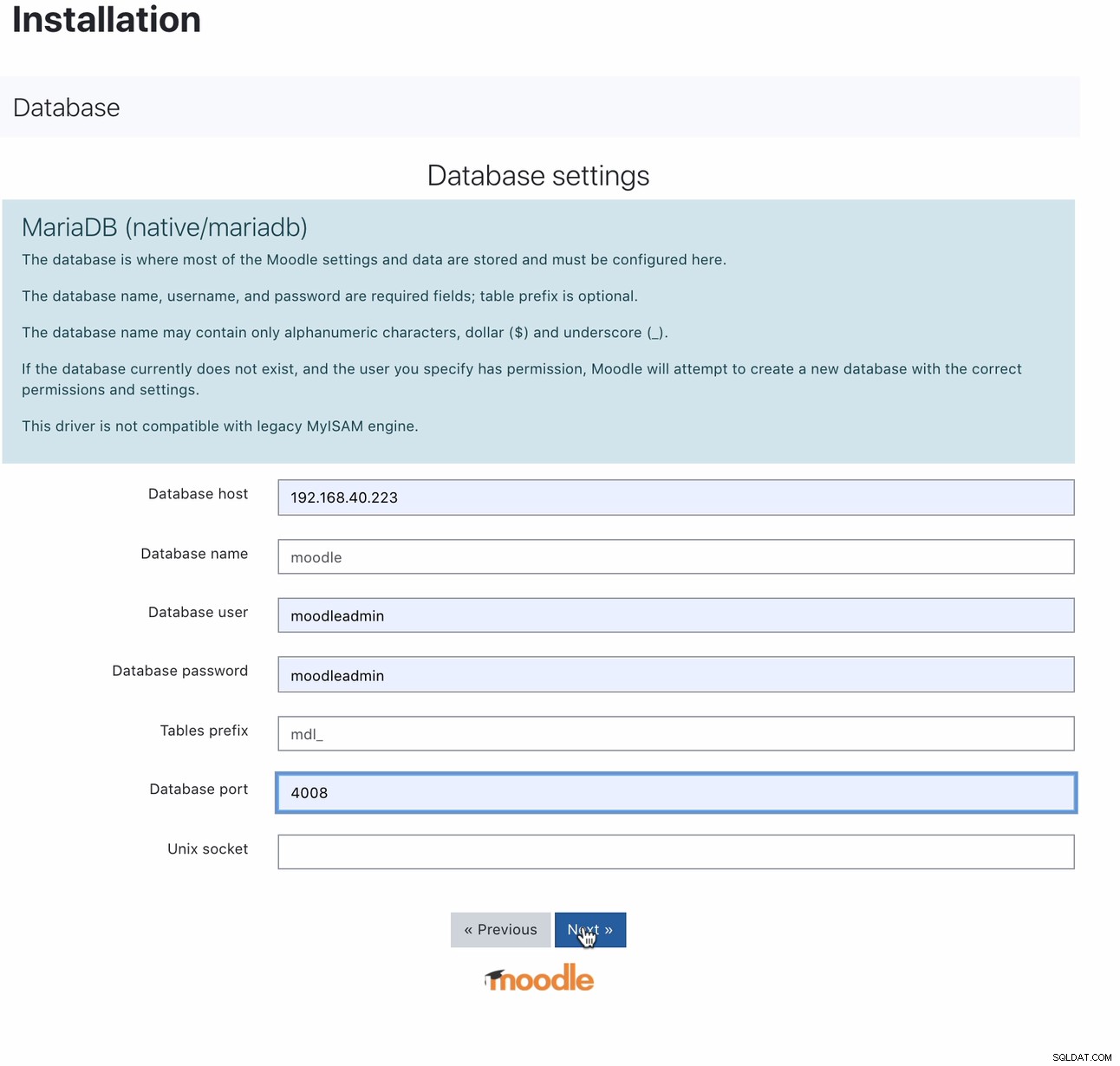
För vilken port 4008 är din läs-skriva för din tjänstavlyssnare. Till exempel, här är följande tjänst och lyssnarkonfiguration för min MaxScale.
$ cat maxscale.cnf.d/rw-listener.cnf
[rw-listener]
type=listener
protocol=mariadbclient
service=rw-service
address=0.0.0.0
port=4008
authenticator=MySQLAuth
$ cat maxscale.cnf.d/rw-service.cnf
[rw-service]
type=service
servers=DB_123,DB_122,DB_124
router=readwritesplit
user=maxscale_adm
password=42BBD2A4DC1BF9BE05C41A71DEEBDB70
max_slave_connections=100%
max_sescmd_history=15000000
causal_reads=true
causal_reads_timeout=10
transaction_replay=true
transaction_replay_max_size=32Mi
delayed_retry=true
master_reconnection=true
max_connections=0
connection_timeout=0
use_sql_variables_in=master
master_accept_reads=true
disable_sescmd_history=falseMedan du är i din bildskärmskonfiguration får du inte glömma att aktivera den automatiska övergången eller även aktivera automatisk återanslutning om du vill att den tidigare mastern ska misslyckas med att automatiskt gå med igen när du går online igen. Det går så här,
$ egrep -r 'auto|^\[' maxscale.cnf.d/replication_monitor.cnf
[replication_monitor]
auto_failover=true
auto_rejoin=1Observera att variablerna jag har angett inte är avsedda för produktionsanvändning utan endast för detta blogginlägg och teständamål. Det som är bra med MaxScale, när den primära eller mastern går ner, är MaxScale smart nog att marknadsföra den ideala eller bästa kandidaten att ta rollen som master. Därför behöver du inte ändra din IP och port eftersom vi har använt värden/IP för vår MaxScale-nod och dess port som vår slutpunkt när mastern går ner. Till exempel,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Noden DB_123 som pekar på 192.168.40.221 är den nuvarande mastern. Att avsluta noden DB_123 kommer att trigga MaxScale att utföra en failover och det ska se ut så här,
[192.168.40.223:6603] MaxScale> list servers
┌────────┬────────────────┬──────┬─────────────┬─────────────────┬──────────────────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_124 │ 192.168.40.223 │ 3306 │ 0 │ Slave, Running │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_123 │ 192.168.40.221 │ 3306 │ 0 │ Down │ 3-2003-876,5-2001-219541 │
├────────┼────────────────┼──────┼─────────────┼─────────────────┼──────────────────────────┤
│ DB_122 │ 192.168.40.222 │ 3306 │ 0 │ Master, Running │ 3-2003-876,5-2001-219541 │
└────────┴────────────────┴──────┴─────────────┴─────────────────┴──────────────────────────┘Medan vår Moodle-databas fortfarande är igång eftersom vår MaxScale pekar på den senaste mästaren som marknadsfördes.
$ mysql -hmaxscale.local.domain -umoodleuser -pmoodlepassword -P4008
Welcome to the MariaDB monitor. Commands end with ; or \g.
Your MariaDB connection id is 9
Server version: 10.3.27-MariaDB-log MariaDB Server
Copyright (c) 2000, 2018, Oracle, MariaDB Corporation Ab and others.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
MariaDB [(none)]> select @@hostname;
+------------+
| @@hostname |
+------------+
| 192.168.40.222 |
+------------+
1 row in set (0.001 sec)Använda ClusterControl
ClusterControl kan laddas ner gratis och erbjuder licenser för Community, Advance och Enterprise. Den automatiska failover är endast tillgänglig på Advance och Enterprise. Automatisk failover täcks av vår Auto-Recovery-funktion som försöker återställa ett misslyckat kluster eller en misslyckad nod. Om du vill ha mer information om hur du utför detta, kolla in vårt tidigare inlägg How ClusterControl Performs Automatic Database Recovery and Failover. Den erbjuder inställbara parametrar som är mycket bekväma och lätta att använda. Läs även vårt tidigare inlägg om hur man automatiserar databasfel med ClusterControl.
Hantera din automatiska failover för din Moodle-databas måste åtminstone kräva en virtuell IP (VIP) som din slutpunkt för din Moodle-applikationsklient som gränsar till din databasbackend. För att göra detta kan du distribuera Keepalved med HAProxy (eller ProxySQL – beroende på ditt val av lastbalanserare) ovanpå. I det här fallet ska din Moodle-databas slutpunkt peka på den virtuella IP-adressen, som i princip tilldelas av Keepalved när du har distribuerat den, samma som vi visade dig tidigare när du satte upp MaxScale. Du kan också läsa den här bloggen om hur du gör det.
Som nämnts ovan är inställbara parametrar tillgängliga som du bara kan ställa in via din /etc/cmon.d/cmon_
- replication_check_binlog_filtration_bf_failover
- replication_check_external_bf_failover
- replication_failed_reslave_failover_script
- replication_failover_blacklist
- replication_failover_events
- replication_failover_wait_to_apply_timeout
- replication_failover_whitelist
- replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_unsuccessful_failover_script
- replication_pre_failover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
ClusterControl är mycket flexibel när du hanterar failover så att du kan utföra vissa pre-failover eller post-failover uppgifter.
Slutsats
Det finns andra bra val när du ställer in och automatiskt hanterar din failover för din MySQL-databas för Moodle. Det beror på din budget och vad du sannolikt måste spendera pengar på. Att använda sådana med öppen källkod kräver expertis och kräver flera tester för att bli bekant eftersom det inte finns någon support du kan köra när du behöver hjälp annat än gemenskapen. Med företagslösningar kommer det med ett pris men ger dig stöd och enkelhet eftersom det tidskrävande arbetet kan minskas. Observera att om failover används av misstag kan det kosta skada på din databas om den inte hanteras och hanteras på rätt sätt. Fokusera på det som är viktigare och hur du är kapabel till de lösningar du använder för att hantera din Moodle-databas failover.