MariaDB-replikering är en av de mest populära högtillgänglighetslösningarna för MariaDB och används ofta av toppföretag som Booking.com och Google. Det är väldigt enkelt att ställa in, med vissa kompromisser om det löpande underhållet som mjukvaruuppgraderingar, schemaändringar, topologiändringar, failover och återställning som alltid har varit knepiga. Ändå, med rätt verktygsuppsättning, bör du kunna hantera topologin med lätthet. I det här blogginlägget kommer vi att undersöka några tips för att övervaka MariaDB-replikering effektivt med ClusterControl.
Använda Topology Viewer
En replikeringskonfiguration består av ett antal roller. En nod i en replikeringsinställning kan vara en:
- Mästare - Den primära skribenten/läsaren.
- Backup master - En skrivskyddad slav med semi-synk replikering, enbart för master redundans.
- Mellanmästare – replikera från en master, medan andra slavar replikerar från denna nod.
- Binlog-server – samla in/lagra endast binloggar utan visningsdata.
- Slav – Replikera från en master och vanligtvis inställd som skrivskyddad.
- Slav med flera källor - Replikera från flera masters.
Varje roll har sitt eget ansvar och begränsning och man måste förstå den korrekta topologin när man hanterar databasnoderna. Detta gäller även för applikationen, där applikationen endast måste skriva till huvudnoden vid varje given tidpunkt. Därför är det viktigt att ha en överblick över vilken nod som har vilken roll, så att vi inte förstör vår databas.
I ClusterControl kan Topology Viewer ge dig en översikt över replikeringstopologin och dess tillstånd, som visas i följande skärmdump:
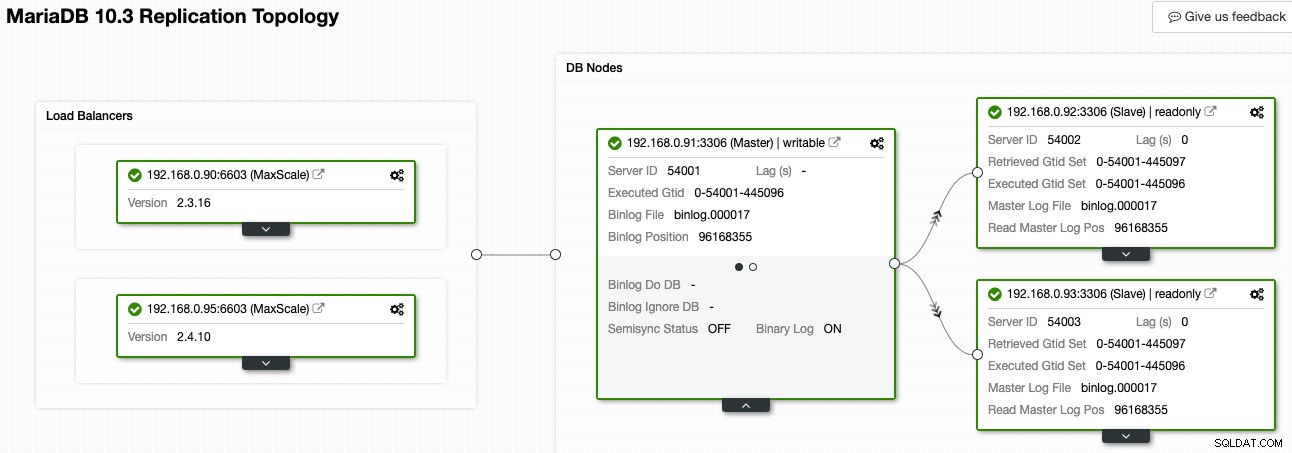
ClusterControl förstår MariaDB-replikering och kan visualisera topologin med korrekt replikeringsdataflöde, som representeras av pilarna som pekar på slavnoderna. Vi kan enkelt urskilja vilken nod som är master, slavar och lastbalanserare (MaxScale) i vår replikeringssetup. Den gröna rutan indikerar att alla viktiga tjänster körs som förväntat med den tilldelade rollen.
Tänk på följande skärmdump där ett antal av våra noder har problem:
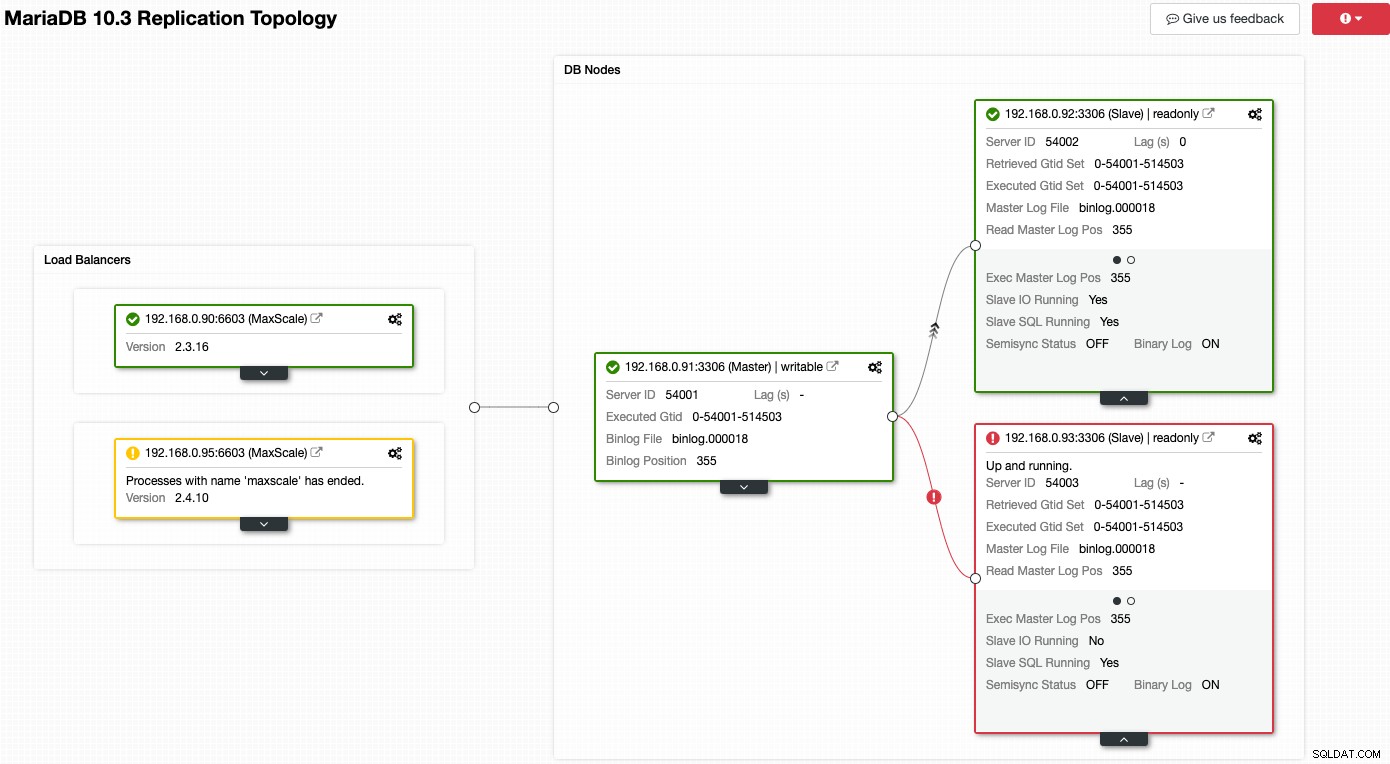
ClusterControl kommer omedelbart att berätta vad som är fel med den aktuella topologin. En av slavarna (röd ruta) visar "Slav IO Running" som Nej, för att indikera något anslutningsproblem att replikera från mastern. Medan den gula rutan visar att vår MaxScale-tjänst inte körs. Vi kan också säga att MaxScale-versionerna inte är identiska för båda noderna. Du kan också utföra hanteringsuppgifter genom att klicka på kugghjulsikonen (överst till höger på varje ruta) direkt, vilket minskar riskerna för att ta upp en fel nod.
replikeringsfördröjning
Detta är det viktigaste om du förlitar dig på datareplikeringskonsistens. Replikeringsfördröjning uppstår när slavarna inte kan hänga med i uppdateringarna som sker på mastern. Ej tillämpade ändringar ackumuleras i slavarnas reläloggar och versionen av databasen på slavarna blir allt mer annorlunda än masterns.
I ClusterControl kan du hitta replikeringsfördröjningshistogrammet under Översikt -> Replikeringsfördröjning där ClusterControl ständigt samplar värdet Seconds_Behind_Master från "VISA SLAVESTATUS"-utdata:
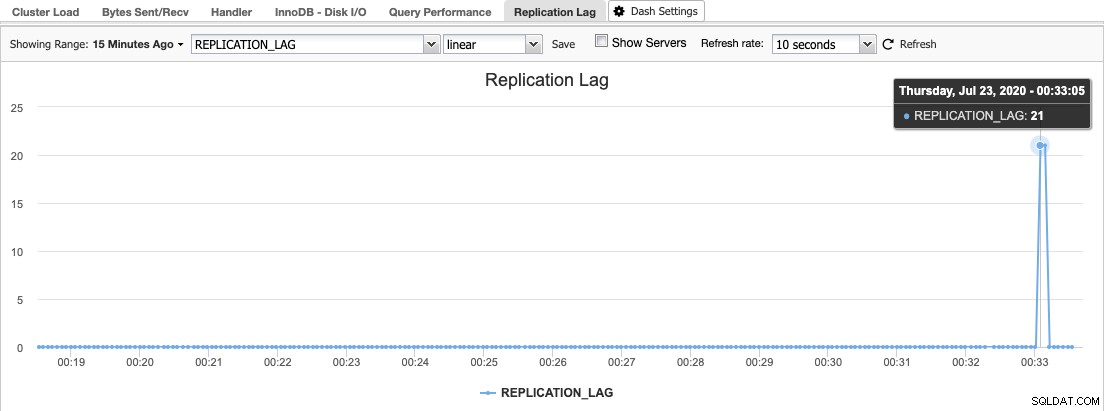
Replikeringsfördröjning inträffar när antingen I/O-tråden eller SQL-tråden inte kan klara de krav som ställs på den. Om I/O-tråden lider betyder det att nätverksanslutningen mellan mastern och dess slavar är långsam eller har problem. Du kanske vill överväga att aktivera slave_compressed_protocol för att komprimera nätverkstrafik eller rapportera till din nätverksadministratör.
Om det är SQL-tråden beror problemet förmodligen på dåligt optimerade frågor som tar för lång tid för slaven att tillämpa. Det kan vara långvariga transaktioner eller för mycket I/O-aktivitet. Att inte ha någon primärnyckel på slavtabellerna när du använder replikeringsformatet ROW eller MIXED är också en vanlig orsak till fördröjning i den här tråden. Kontrollera att master- och slavversionerna av tabeller har en primärnyckel.
Några fler tips och tricks tas upp i det här blogginlägget, How to Reduce Repplication Lag in Multi-Cloud Deployments.
Binär/reläloggstorlek
Det är viktigt att övervaka diskstorleken för binära och reläloggar eftersom den kan förbruka en avsevärd mängd lagringsutrymme på varje nod i ett replikeringskluster. Vanligtvis skulle man ställa in systemvariabeln expire_logs_days så att binära loggfiler löper ut automatiskt efter ett givet antal dagar, till exempel expire_logs_days=7. Storleken på binära loggar är helt beroende av antalet skapade binära händelser (inkommande skrivningar) och lite som vi vet hur mycket diskutrymme det skulle förbruka innan loggarna kommer att förfalla av MariaDB. Tänk på att om du aktiverar log_slave_updates på slavarna kommer storleken på loggarna att nästan fördubblas på grund av att det finns både binära loggar och reläloggar på samma server.
För ClusterControl kan vi ställa in en tröskel för diskutrymmesutnyttjande under ClusterControl -> Inställningar -> Tröskelvärden för att få en varning och viktiga meddelanden enligt nedan:
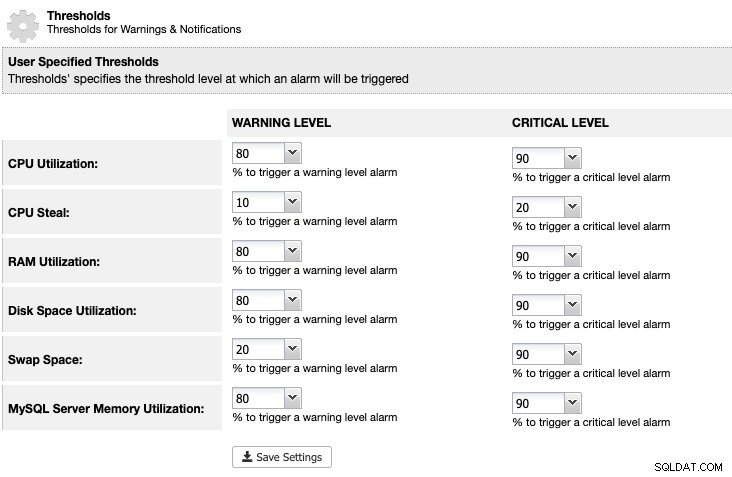
ClusterControl övervakar allt diskutrymme relaterat till MariaDB-tjänster som platsen för MariaDB-data katalogen, katalogen för binära loggar och även rotpartitionen. Om du har nått tröskeln, överväg att rensa de binära loggarna manuellt genom att använda kommandot PURGE BINARY LOGS, som förklaras och diskuteras i den här artikeln.
Aktivera övervakningsinstrumentpaneler
ClusterControl tillhandahåller två övervakningsalternativ för att sampla databasnoderna - agentlösa eller agentbaserade. Standardinställningen är agentlös där sampling sker via SSH i en pull-only mekanism. Agentbaserad övervakning kräver att en Prometheus-server körs och att alla övervakade noder konfigureras med minst tre exportörer:
- Processexportör (port 9011)
- Exportör för nod-/systemstatistik (port 9100)
- MySQL/MariaDB-exportör (port 9104)
För att aktivera den agentbaserade övervakningsinstrumentpanelen måste man gå till ClusterControl -> Dashboards -> Aktivera agentbaserad övervakning. När den är aktiverad kommer du att se en uppsättning instrumentpaneler konfigurerade för vår MariaDB-replikering, vilket ger oss en mycket bättre insikt i vår replikeringsinställning. Följande skärmdump visar vad du skulle se för masternoden:
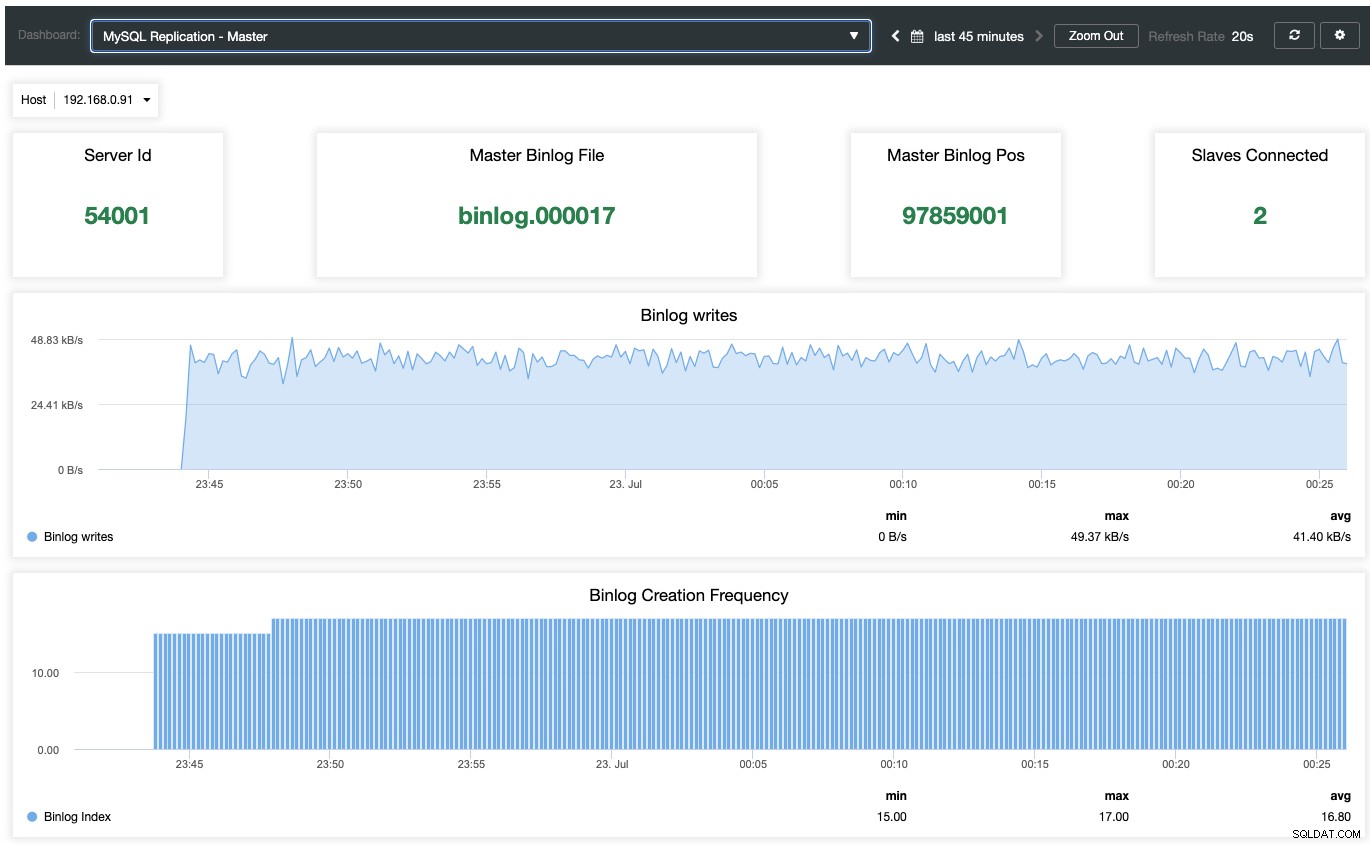
Förutom MariaDB-standardövervakningsinstrumentpaneler som generella, cachar och InnoDB-mått, kan du kommer att presenteras med en replikeringsinstrumentpanel. För masternoden kan vi få mycket användbar information om masterns tillstånd, skrivgenomströmningen och frekvensen för skapande av binlog.
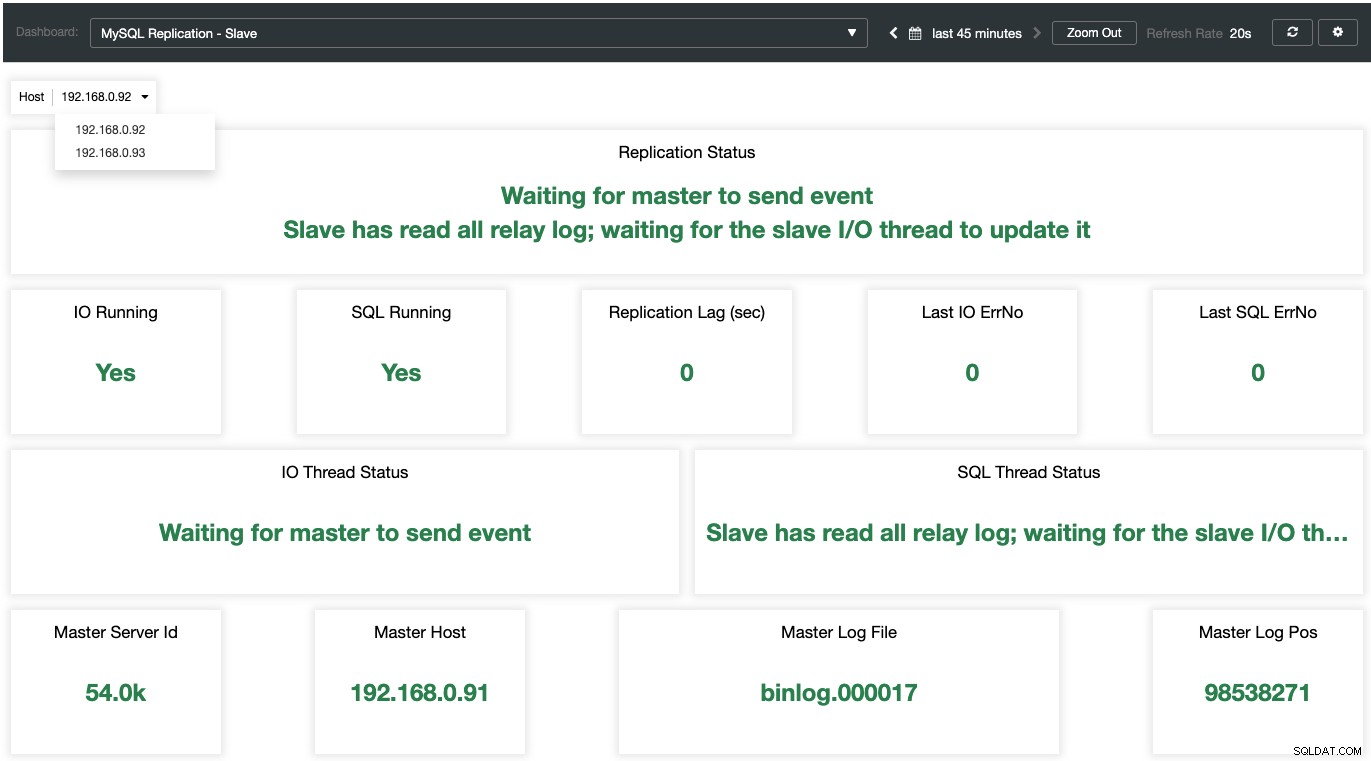
Medan för slavarna samplas alla viktiga tillstånd och sammanfattas som följande skärmdump. om allt är grönt är du i goda händer:
Förstå MariaDB-felloggen
MariaDB loggar sina viktiga händelser i felloggen, vilket är användbart för att förstå vad som pågick med servern, speciellt före, under och efter en topologiändring. ClusterControl ger en centraliserad vy av felloggar under ClusterControl -> Loggar -> Systemloggar genom att dra dem från varje databasnod. Du klickar på "Uppdatera loggar" för att utlösa ett jobb för att hämta de senaste loggarna från servern.
Insamlade filer representeras i en navigeringsträdstruktur och ett textområde med syntaxmarkering för bättre läsbarhet:
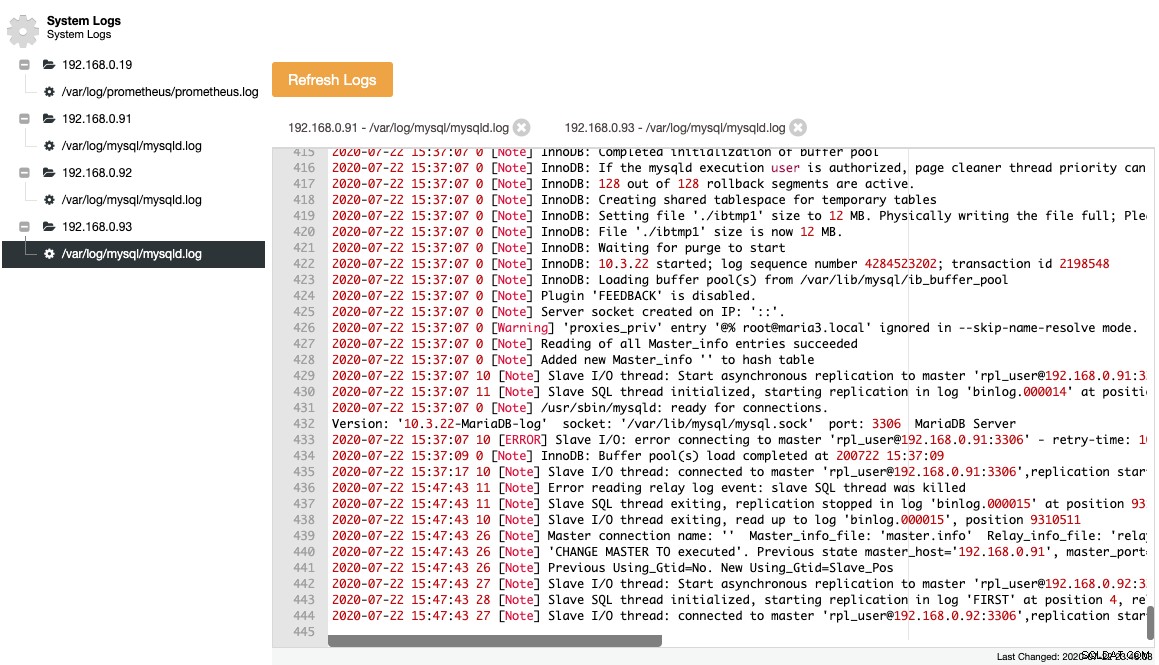
Från ovanstående skärmdump kan vi förstå händelseförloppet och vad som hände med denna nod under en topologiändringshändelse. Från de sista 12 raderna i felloggen ovan hade slaven ett fel när han anslutit till mastern och den sista binära loggfilen och positionen registrerades i loggen innan den stoppades. Sedan kördes ett nyare CHANGE MASTER-kommando med GTID-information, som visas på raden "Previous Using_Gtid=No. New Using_Gtid=Slave_Pos" och sedan återupptas replikeringen som vi ville.
MariaDB Alert and Notifications
Övervakningen är ofullständig utan varningar och meddelanden. Alla händelser och larm som genereras av ClusterControl kan skickas till e-post eller andra tredjepartsverktyg som stöds. För e-postmeddelanden kan man konfigurera om typen av händelser kommer att levereras omedelbart, ignoreras eller sammanfattas (en daglig sammanfattad rapport):

För alla allvarliga händelser rekommenderas att du ställer in allt på "Leverera" så att du får aviseringarna så snart som möjligt. Ställ in "Digest" på varningshändelser så att du är väl medveten om klustrets hälsa och tillstånd.
Du kan integrera dina föredragna kommunikations- och meddelandeverktyg med ClusterControl genom att använda funktionen Notifications Management under ClusterControl -> Integrationer -> Tredjepartsmeddelanden. ClusterControl kan skicka larm och händelser till PagerDuty, VictorOps, OpsGenie, Slack, Telegram, ServiceNow eller andra användarregistrerade webhooks.
Följande skärmdump visar att alla kritiska händelser kommer att skickas till den konfigurerade telegramkanalen för vårt MariaDB 10.3-replikeringskluster:

ClusterControl stöder även chatbotintegration, där du kan interagera med kontrolltjänsten via s9s-klienten direkt från ditt meddelandeverktyg som visas i det här blogginlägget, Automatisera din databas med CCBot:ClusterControl Hubot Integration.
Slutsats
ClusterControl erbjuder en komplett uppsättning proaktiva övervakningsverktyg för dina databaskluster. Använd ClusterControl för att övervaka din MariaDB-replikeringsinställning eftersom de flesta av övervakningsfunktionerna är tillgängliga gratis i community-utgåvan. Missa inte dem!