
Den typiska MySQL DBA kan vara bekant att arbeta och hantera en OLTP-databas (Online Transaction Processing) som en del av deras dagliga rutin. Du kanske är bekant med hur det fungerar och hur man hanterar komplexa operationer. Även om standardlagringsmotorn som MySQL levererar är tillräckligt bra för OLAP (Online Analytical Processing) är den ganska förenklad, särskilt de som vill lära sig artificiell intelligens eller som sysslar med prognoser, datautvinning, dataanalys.
I den här bloggen kommer vi att diskutera MariaDB ColumnStore. Innehållet kommer att skräddarsys till förmån för MySQL DBA som kanske har mindre förståelse för ColumnStore och hur det kan vara tillämpbart för OLAP-applikationer (Online Analytical Processing).
OLTP vs OLAP
OLTP
Relaterade resurser Analytics med MariaDB AX - the Open Source Columnar Datastore An Introduction to Time Series Databases Hybrid OLTP/Analytics Database Workloads in Galera Cluster Using Asynchronous SlavesDen typiska MySQL DBA-aktiviteten för att hantera denna typ av data är att använda OLTP (Online Transaction Processing). OLTP kännetecknas av stora databastransaktioner som gör insättningar, uppdateringar eller borttagningar. Databaser av OLTP-typ är specialiserade för snabb frågebehandling och upprätthållande av dataintegritet samtidigt som de nås i flera miljöer. Dess effektivitet mäts genom antalet transaktioner per sekund (tps). Det är ganska vanligt att relationstabellerna mellan överordnade och barn (efter implementering av normaliseringsformuläret) minskar överflödiga data i en tabell.
Poster i en tabell bearbetas och lagras vanligtvis sekventiellt på ett radorienterat sätt och är mycket indexerade med unika nycklar för att optimera datahämtning eller skrivning. Detta är också vanligt för MySQL, speciellt när det handlar om stora inlägg eller höga samtidiga skrivningar eller bulkinfogningar. De flesta av lagringsmotorerna som MariaDB stöder är tillämpliga för OLTP-applikationer - InnoDB (standardlagringsmotorn sedan 10.2), XtraDB, TokuDB, MyRocks eller MyISAM/Aria.
Applikationer som CMS, FinTech, Web Apps hanterar ofta tunga skrivningar och läsningar och kräver ofta hög genomströmning. För att få dessa applikationer att fungera krävs ofta djup expertis inom hög tillgänglighet, redundans, motståndskraft och återhämtning.
OLAP
OLAP hanterar samma utmaningar som OLTP, men använder ett annat tillvägagångssätt (särskilt när det handlar om datahämtning.) OLAP hanterar större datamängder och är vanligt för datalagring, som ofta används för applikationer av typen Business Intelligence. Det används ofta för Business Performance Management, Planering, Budgetering, Prognoser, Finansiell Rapportering, Analys, Simuleringsmodeller, Knowledge Discovery och Data Warehouse Reporting.
Data som lagras i OLAP är vanligtvis inte lika kritisk som den som lagras i OLTP. Detta beror på att det mesta av data kan simuleras från OLTP och sedan kan matas till din OLAP-databas. Dessa data används vanligtvis för bulkladdning, som ofta behövs för affärsanalyser som så småningom renderas till visuella grafer. OLAP utför också multidimensionell analys av affärsdata och levererar resultat som kan användas för komplexa beräkningar, trendanalys eller sofistikerad datamodellering.
OLAP lagrar vanligtvis data konstant i ett kolumnformat. I MariaDB ColumnStore är posterna uppdelade baserat på dess kolumner och lagras separat i en fil. På så sätt är datahämtning mycket effektiv, eftersom den bara skannar den relevanta kolumnen som hänvisas till i din SELECT-satsförfrågan.
Tänk på det så här, OLTP-bearbetning hanterar dina dagliga och avgörande datatransaktioner som driver din affärsapplikation, medan OLAP hjälper dig att hantera, förutsäga, analysera och bättre marknadsföra din produkt - byggstenarna för att ha en affärsapplikation.
Vad är MariaDB ColumnStore?
MariaDB ColumnStore är en pluggbar kolumnär lagringsmotor som körs på MariaDB Server. Den använder en parallelldistribuerad dataarkitektur samtidigt som den behåller samma ANSI SQL-gränssnitt som används över MariaDB-serverportföljen. Denna lagringsmotor har funnits ett tag, eftersom den ursprungligen porterades från InfiniDB (en nu nedlagd kod som fortfarande är tillgänglig på github.) Den är designad för stordataskalning (för att bearbeta petabyte data), linjär skalbarhet och verklig - tidssvar på analysfrågor. Det utnyttjar I/O-fördelarna med kolumnlagring; komprimering, just-in-time projektion och horisontell och vertikal partitionering för att leverera enastående prestanda vid analys av stora datamängder.
Slutligen är MariaDB ColumnStore ryggraden i deras MariaDB AX-produkt som den huvudsakliga lagringsmotorn som används av denna teknik.
Hur skiljer sig MariaDB ColumnStore från InnoDB?
InnoDB är tillämpligt för OLTP-behandling som kräver att din applikation svarar snabbast möjligt. Det är användbart om din ansökan handlar om den typen. Å andra sidan är MariaDB ColumnStore ett lämpligt val för att hantera stora datatransaktioner eller stora datamängder som involverar komplexa sammanfogningar, aggregering på olika nivåer av dimensionshierarki, projicera en finansiell summa för ett brett spektrum av år eller använda jämlikhet och intervallval . Dessa tillvägagångssätt som använder ColumnStore kräver inte att du indexerar dessa fält, eftersom det kan fungera tillräckligt snabbare. InnoDB kan inte riktigt hantera den här typen av prestanda, även om det inte finns något som hindrar dig från att prova det som är möjligt med InnoDB, men till en kostnad. Detta kräver att du lägger till index, vilket lägger till stora mängder data till din disklagring. Det betyder att det kan ta längre tid att slutföra din fråga, och att den kanske inte avslutas alls om den är instängd i en tidsslinga.
MariaDB ColumnStore-arkitektur
Låt oss titta på MariaDB ColumStore-arkitekturen nedan:
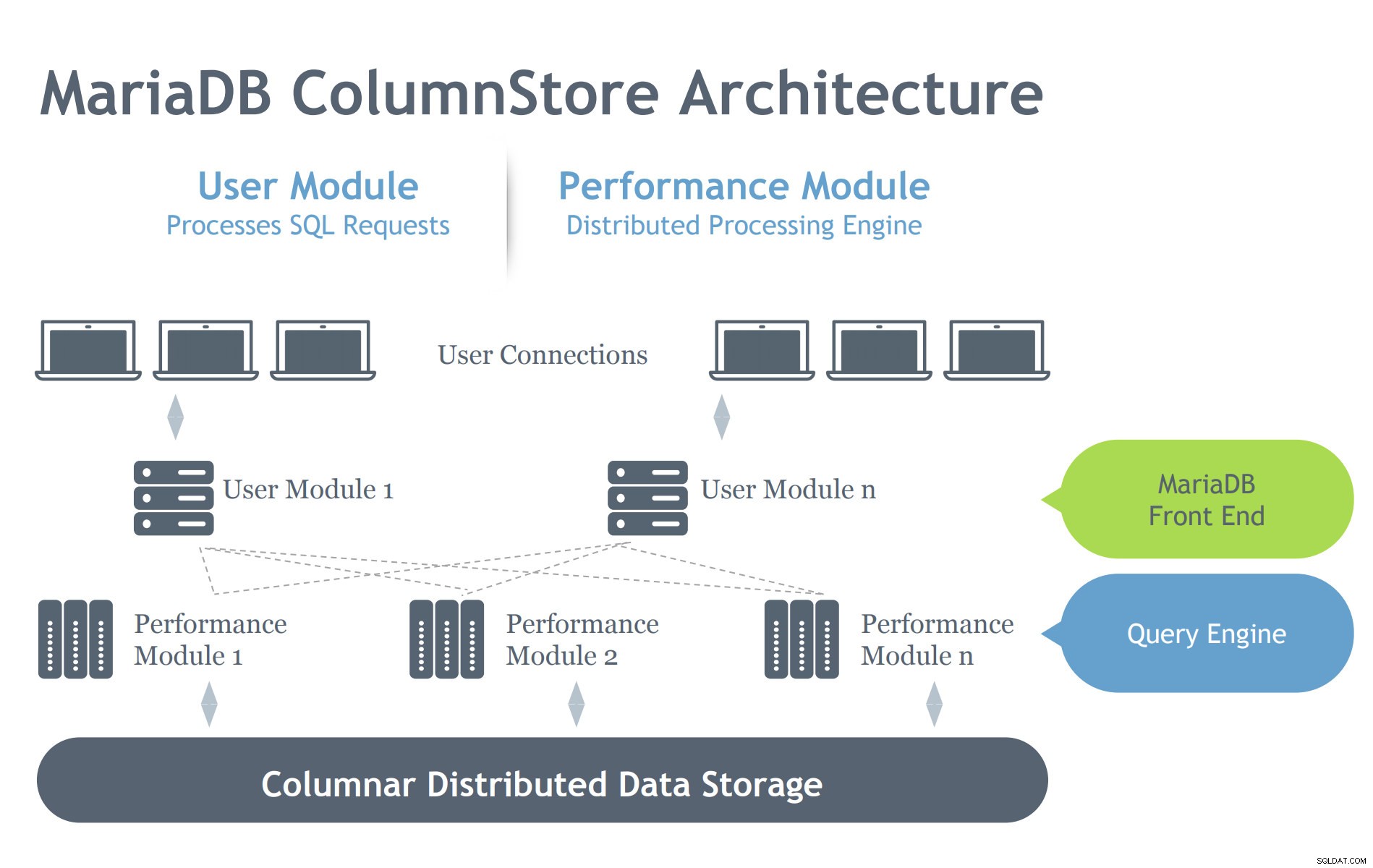 Bild med tillstånd från MariaDB ColumnStore-presentation
Bild med tillstånd från MariaDB ColumnStore-presentation I motsats till InnoDB-arkitekturen innehåller ColumnStore två moduler som anger att dess avsikt är att arbeta effektivt på en distribuerad arkitektonisk miljö. InnoDB är avsett att skala på en server, men spänner över flera sammankopplade noder beroende på en klusterinställning. Därför har ColumnStore flera nivåer av komponenter som tar hand om de processer som begärs till MariaDB-servern. Låt oss gräva på dessa komponenter nedan:
- Användarmodul (UM):UM:n ansvarar för att analysera SQL-förfrågningarna till en optimerad uppsättning primitiva jobbsteg som exekveras av en eller flera PM-servrar. UM är således ansvarig för frågeoptimering och orkestrering av frågekörning av PM-servrarna. Medan flera UM-instanser kan distribueras i en distribution med flera servrar, är en enda UM ansvarig för varje enskild fråga. En databaslastbalanserare, som MariaDB MaxScale, kan användas för att balansera externa förfrågningar mot individuella UM-servrar.
- Performance Module (PM):PM:n kör granulära jobbsteg som tas emot från en UM på ett flertrådigt sätt. ColumnStore tillåter distribution av arbete över många prestationsmoduler. UM består av MariaDB mysqld-processen och ExeMgr-processen.
- Extentkartor:ColumnStore underhåller metadata om varje kolumn i ett delat distribuerat objekt som kallas Extent Map. UM-servern refererar till Extent Map för att hjälpa till att generera de korrekta primitiva jobbstegen. PM-servern refererar till Extent Map för att identifiera rätt diskblock att läsa. Varje kolumn består av en eller flera filer och varje fil kan innehålla flera omfattningar. Så mycket som möjligt försöker systemet allokera sammanhängande fysisk lagring för att förbättra läsprestandan.
- Lagring:ColumnStore kan använda antingen lokal lagring eller delad lagring (t.ex. SAN eller EBS) för att lagra data. Genom att använda delad lagring kan databehandling misslyckas automatiskt till en annan nod i händelse av att en PM-server misslyckas.
Nedan är hur MariaDB ColumnStore behandlar frågan,
- Kunder skickar en fråga till MariaDB-servern som körs på användarmodulen. Servern utför en tabelloperation för alla tabeller som behövs för att uppfylla begäran och hämtar den initiala exekveringsplanen för frågeställningar.
- Med MariaDB-lagringsmotorgränssnittet konverterar ColumnStore servertabellobjektet till ColumnStore-objekt. Dessa objekt skickas sedan till användarmodulens processer.
- Användarmodulen konverterar MariaDB-exekveringsplanen och optimerar de givna objekten till en ColumnStore-exekveringsplan. Den bestämmer sedan stegen som behövs för att köra frågan och i vilken ordning de måste köras.
- Användarmodulen konsulterar sedan Extent Map för att avgöra vilka prestandamoduler som ska konsulteras för den data den behöver, den utför sedan Extent Eliminering, vilket eliminerar alla prestandamoduler från listan som bara innehåller data utanför intervallet för vad frågan kräver.
- Användarmodulen skickar sedan kommandon till en eller flera prestandamoduler för att utföra block I/O-operationer.
- Prestandamodulen eller -modulerna utför predikatfiltrering, sammanfogningsbearbetning, initial aggregering av data från lokal eller extern lagring och skickar sedan tillbaka data till användarmodulen.
- Användarmodulen utför den slutliga resultatuppsättningen och sammanställer resultatuppsättningen för frågan.
- Användarmodulen / ExeMgr implementerar alla fönsterfunktionsberäkningar, såväl som all nödvändig sortering på resultatuppsättningen. Den returnerar sedan resultatuppsättningen till servern.
- MariaDB-servern utför valfria listfunktioner, ORDER BY och LIMIT-operationer på resultatuppsättningen.
- MariaDB-servern returnerar resultatuppsättningen till klienten.
Frågeexekveringsparadigm
Låt oss gräva lite mer hur ColumnStore kör frågan och när den påverkar.
ColumnStore skiljer sig från de vanliga MySQL/MariaDB-lagringsmotorerna som InnoDB eftersom ColumnStore får prestanda genom att endast skanna nödvändiga kolumner, använda systemunderhållen partitionering och använda flera trådar och servrar för att skala svarstid för frågor. Prestanda gynnas när du bara inkluderar kolumner som är nödvändiga för din datahämtning. Det betyder att den giriga asterisken (*) i din urvalsfråga har betydande inverkan jämfört med en SELECT
Samma som med InnoDB och andra lagringsmotorer, datatyp har också betydelse för prestanda på det du använde. Om säg att du har en kolumn som bara kan ha värdena 0 till 100, deklarera detta som en liten int eftersom den kommer att representeras med 1 byte istället för 4 byte för int. Detta kommer att minska I/O-kostnaden med 4 gånger. För strängtyper är en viktig tröskel char(9) och varchar(8) eller högre. Varje kolumnlagringsfil använder ett fast antal byte per värde. Detta möjliggör snabb positionssökning av andra kolumner för att bilda raden. För närvarande är den övre gränsen för kolumnär datalagring 8 byte. Så för strängar längre än detta upprätthåller systemet ytterligare en "ordbok"-omfattning där värdena lagras. Kolumnfilen lagrar sedan en pekare i ordboken. Så det är dyrare att läsa och bearbeta en varchar(8) kolumn än en char(8) kolumn till exempel. Så där det är möjligt kommer du att få bättre prestanda om du kan använda kortare strängar, särskilt om du undviker ordboksuppslagningen. Alla TEXT/BLOB-datatyper i 1.1 och framåt använder en ordbok och gör en 8KB-uppslagning av flera block för att hämta dessa data om det behövs, ju längre data desto fler block hämtas och desto större potentiell påverkan på prestanda.
I ett radbaserat system läggs till överflödiga kolumner till den totala frågekostnaden, men i ett kolumnärt system uppstår en kostnad endast om kolumnen refereras. Därför bör ytterligare kolumner skapas för att stödja olika åtkomstvägar. Lagra till exempel en inledande del av ett fält i en kolumn för att möjliggöra snabbare sökningar men dessutom lagra det långa formuläret som en annan kolumn. Skanningar på en kortare kod eller inledande delkolumn kommer att gå snabbare.
Frågekopplingar är optimerade och redo för storskaliga kopplingar och undviker behovet av index och overhead för kapslad loopbearbetning. ColumnStore upprätthåller tabellstatistik för att bestämma den optimala sammanfogningsordningen. Liknande tillvägagångssätt delas med InnoDB som att om kopplingen är för stor för UM-minnet, använder den diskbaserad koppling för att göra frågan slutförd.
För aggregering distribuerar ColumnStore aggregerad utvärdering så mycket som möjligt. Detta innebär att den delar över UM och PM för att hantera frågor, särskilt eller ett mycket stort antal värden i den eller de aggregerade kolumnerna. Select count(*) är internt optimerad för att välja det minsta antalet byte lagring i en tabell. Detta betyder att den skulle välja CHAR(1)-kolumnen (använder 1 byte) över sin INT-kolumn som tar 4 byte. Implementeringen respekterar fortfarande ANSI-semantik genom att select count(*) kommer att inkludera nollor i det totala antalet i motsats till en explicit select(COL-N) som exkluderar nollor i räkningen.
Order by och limit implementeras för närvarande i slutet av mariadb-serverprocessen på den temporära resultatuppsättningstabellen. Detta har nämnts i steg #9 om hur ColumnStore bearbetar frågan. Så tekniskt sett skickas resultaten till MariaDB Server för sortering av data.
För komplexa frågor som använder underfrågor är det i princip samma tillvägagångssätt där de exekveras i sekvens och hanteras av UM, samma som med fönsterfunktioner som hanteras av UM men den använder en dedikerad snabbare sorteringsprocess, så det är i princip snabbare.
Partitionering av dina data tillhandahålls av ColumnStore som använder Extent Maps som upprätthåller min/max-värdena för kolumndata och ger ett logiskt intervall för partitionering och tar bort behovet av indexering. Extent Maps tillhandahåller också manuell tabellpartitionering, materialiserade vyer, sammanfattningstabeller och andra strukturer och objekt som radbaserade databaser måste implementera för frågeprestanda. Det finns vissa fördelar med kolumnerade värden när de är i ordning eller halvordning eftersom detta möjliggör mycket effektiv datapartitionering. Med min- och maxvärden kommer hela omfattningskartor efter filtret och uteslutningen att elimineras. Se den här sidan i deras manual om Extent Elimination. Detta fungerar i allmänhet särskilt bra för tidsseriedata eller liknande värden som ökar med tiden.
Installera MariaDB ColumnStore
Att installera MariaDB ColumnStore kan vara enkelt och okomplicerat. MariaDB har en serie anteckningar här som du kan referera till. För den här bloggen är vår installationsmålmiljö CentOS 7. Du kan gå till den här länken https://downloads.mariadb.com/ColumnStore/1.2.4/ och kolla in paketen baserade på din OS-miljö. Se de detaljerade stegen nedan för att hjälpa dig snabba upp:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
När du är klar måste du köra postConfigure kommandot för att äntligen installera och konfigurera din MariaDB ColumnStore. I den här exempelinstallationen finns det två noder som jag har konfigurerat på vagrant-maskin:
csnode1:192.168.2.10
csnode2:192.168.2.20
Båda dessa noder är definierade i sina respektive /etc/hosts och båda noderna är inställda på att ha sina användar- och prestandamoduler kombinerade i båda värdarna. Installationen är lite trivial till en början. Därför delar vi hur du kan konfigurera det så att du kan ha en grund. Se detaljerna nedan för exempel på installationsprocessen:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#När installationen och installationen är klar kommer MariaDB att skapa en master/slav-inställning för detta så vad vi än har laddat från csnode1 kommer det att replikeras till csnode2.
Dumpa din Big Data
Efter din installation kanske du inte har några exempeldata att prova. IMDB har delat ett exempel på data som du kan ladda ner på deras webbplats https://www.imdb.com/interfaces/. För den här bloggen skapade jag ett manus som gör allt för dig. Kolla in det här https://github.com/paulnamuag/columnstore-imdb-data-load. Gör det bara körbart och kör sedan skriptet. Det kommer att göra allt för dig genom att ladda ner filerna, skapa schemat och sedan ladda data till databasen. Så enkelt är det.
Köra dina exempelfrågor
Nu ska vi försöka köra några exempelfrågor.
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)I grund och botten är det snabbare och snabbare. Det finns frågor som du inte kan bearbeta på samma sätt som du kör med andra lagringsmotorer, till exempel InnoDB. Till exempel försökte jag leka och göra några dumma frågor och se hur det reagerar och det resulterar i:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.Därför hittade jag MCOL-1620 och MCOL-131 och det pekar på att ställa in infinidb_vtable_mode-variabeln. Se nedan:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.Men inställning av infinidb_vtable_mode=0 , vilket innebär att den behandlar fråga som ett generiskt och mycket kompatibelt rad-för-rad-behandlingsläge. Vissa WHERE-satskomponenter kan bearbetas av ColumnStore, men joins bearbetas helt av mysqld med hjälp av en kapslad loop join-mekanism. Se nedan:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)Det tog dock ett tag eftersom det förklarar att det bearbetades helt av mysqld. Ändå är det bästa sättet att optimera och skriva bra frågor och inte delegera allt till ColumnStore.
Dessutom har du lite hjälp att analysera dina frågor genom att köra kommandon som SELECT calSetTrace(1); eller SELECT calGetStats(); . Du kan använda dessa kommandon, till exempel, optimera de låga och dåliga frågorna eller se dess frågeplan. Kolla in den här för mer information om hur du analyserar frågorna.
Administrera ColumnStore
När du väl har konfigurerat MariaDB ColumnStore, levereras det med verktyget mcsadmin som du kan använda för att utföra vissa administrativa uppgifter. Du kan också använda det här verktyget för att lägga till ytterligare en modul, tilldela eller flytta till DBroots från PM till PM, etc. Kolla in deras manual om detta verktyg.
I grund och botten kan du göra följande, till exempel kontrollera systeminformationen:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0Slutsats
MariaDB ColumnStore är en mycket kraftfull lagringsmotor för din OLAP- och big data-behandling. Detta är helt öppen källkod vilket är mycket fördelaktigt att använda än att använda proprietära och dyra OLAP-databaser som finns tillgängliga på marknaden. Ändå finns det andra alternativ att prova som ClickHouse, Apache HBase eller Citus Datas cstore_fdw. Ingen av dessa använder dock MySQL/MariaDB så det kanske inte är ditt genomförbara alternativ om du väljer att fortsätta med MySQL/MariaDB-varianterna.