Välja din HA-topologi
Det finns olika sätt att behålla hög tillgänglighet med databaser. Du kan använda virtuella IP-adresser (VRRP) för att hantera värdtillgänglighet, du kan använda resurshanterare som Zookeeper och Etcd för att (om)konfigurera dina applikationer eller använda lastbalanserare/proxyer för att fördela arbetsbelastningen över alla tillgängliga värdar.
De virtuella IP-adresserna behöver antingen en applikation för att hantera dem (MHA, Orchestrator), lite skript (Keepalived, Pacemaker/Corosync) eller en ingenjör för att manuellt misslyckas och beslutsfattandet i processen kan bli komplext. Virtual IP failover är en enkel och enkel process genom att ta bort IP-adressen från en värd, tilldela den till en annan och använda arping för att skicka ett gratis ARP-svar. I teorin kan en virtuell IP flyttas på en sekund men det kommer att ta några sekunder innan applikationen för failover-hantering är säker på att värden har misslyckats och agerar därefter. I verkligheten borde detta vara någonstans mellan 10 och 30 sekunder. En annan begränsning av virtuella IP-adresser är att vissa molnleverantörer inte tillåter dig att hantera dina egna virtuella IP-adresser eller tilldela dem alls. Google tillåter till exempel inte att du gör det på deras datornoder.
Resurshanterare som Zookeeper och Etcd kan övervaka dina databaser och (om)konfigurera dina applikationer när en värd misslyckas eller en slav befordras till master. I allmänhet är detta en bra idé men att implementera dina kontroller med Zookeeper och Etcd är en komplex uppgift.
En lastbalanserare eller proxy kommer att sitta mellan applikationen och databasvärden och fungera transparent som om klienten skulle ansluta till databasvärden direkt. Precis som med virtuella IP- och resurshanterare behöver lastbalanserarna och proxyservrar också övervaka värdarna och dirigera om trafiken om en värd är nere. ClusterControl stöder två proxyservrar:HAProxy och ProxySQL och båda stöds för MySQL master-slave replikering och Galera kluster. HAProxy och ProxySQL har båda sina egna användningsfall, vi kommer att beskriva dem i det här inlägget också.
Varför behöver du en lastbalanserare?
I teorin behöver du ingen lastbalanserare men i praktiken kommer du att föredra en. Vi förklarar varför.
Om du har konfigurerat virtuella IP-adresser är allt du behöver göra att peka din applikation till den korrekta (virtuella) IP-adressen och allt borde vara bra anslutningsmässigt. Men anta att du har skalat ut antalet lästa repliker, kanske du vill tillhandahålla virtuella IP-adresser för var och en av dessa lästa repliker också på grund av underhålls- eller tillgänglighetsskäl. Detta kan bli en mycket stor pool av virtuella IP-adresser som du måste hantera. Om en av dessa läsrepliker hade ett misslyckande måste du tilldela den virtuella IP-adressen till en annan värd, annars kommer din applikation att ansluta till antingen en värd som är nere eller i värsta fall, en server som släpar efter med inaktuella data. Det är därför nödvändigt att behålla replikeringstillståndet till applikationen som hanterar de virtuella IP-adresserna.
Även för Galera finns det en liknande utmaning:du kan i teorin lägga till så många värdar som du vill till din applikationskonfiguration och välja en slumpmässigt. Samma problem uppstår när denna värd är nere:du kan sluta ansluta till en otillgänglig värd. Att använda alla värdar för både läsning och skrivning kan också orsaka återställning på grund av den optimistiska låsningen i Galera. Om två anslutningar försöker skriva till samma rad samtidigt, kommer en av dem att få en återställning. Om din arbetsbelastning har sådana samtidiga uppdateringar, rekommenderas det att du bara använder en nod i Galera att skriva till. Därför vill du ha en chef som håller reda på det interna tillståndet för ditt databaskluster.
Både HAProxy och ProxySQL kommer att erbjuda dig funktionaliteten för att övervaka MySQL/MariaDB-databasvärdarna och bevara ditt kluster och dess topologi. För replikeringsinställningar, om en slavreplik är nere, kan både HAProxy och ProxySQL omfördela anslutningarna till en annan värd. Men om en replikeringsmaster är nere kommer HAProxy att neka anslutningen och ProxySQL kommer att ge tillbaka ett korrekt fel till klienten. För Galera-inställningar kan båda lastbalanserarna välja en huvudnod från Galera-klustret och bara skicka skrivoperationerna till den specifika noden.
På ytan kan HAProxy och ProxySQL tyckas vara liknande lösningar, men de skiljer sig mycket åt i funktioner och hur de distribuerar anslutningar och frågor. HAProxy stöder ett antal balanseringsalgoritmer som minsta anslutningar, source, random och round-robin medan ProxySQL distribuerar anslutningar med den viktbaserade round-robin-algoritmen (lika vikt betyder lika fördelning). Eftersom ProxySQL är en intelligent proxy, är den databasmedveten och kan även analysera dina frågor. ProxySQL kan göra läs/skrivdelning baserat på frågeregler där du kan vidarebefordra frågorna till de utsedda slavarna eller mastern i ditt kluster. ProxySQL innehåller ytterligare funktioner som omskrivning av frågor, cachning och brandvägg för frågor med djupgående statistikgenerering i realtid om arbetsbelastningen.
Det borde vara tillräckligt med bakgrundsinformation om detta ämne, så låt oss se hur du kan distribuera både belastningsbalanserare för MySQL-replikering och Galera-topologier.
Distribuera HAProxy
Det är enkelt att använda ClusterControl för att distribuera HAProxy på ett Galera-kluster:gå till relevant kluster och välj "Lägg till lastbalanserare":
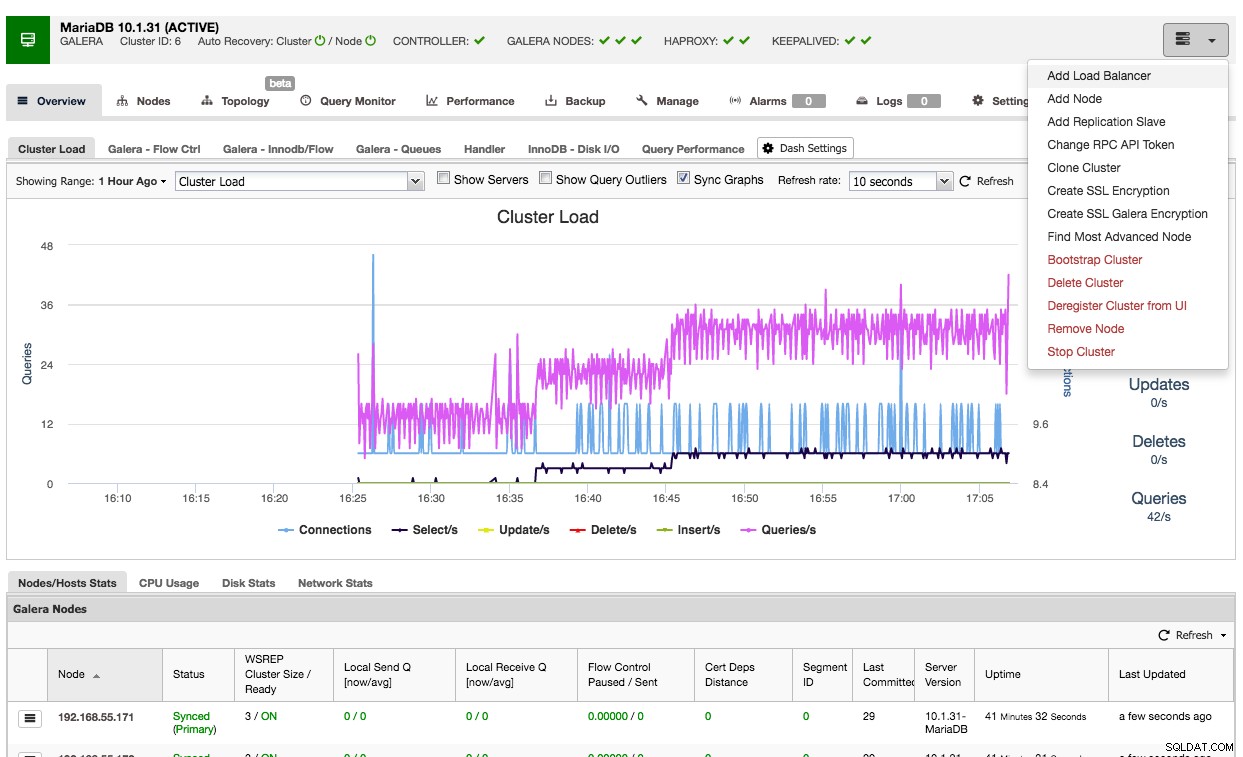
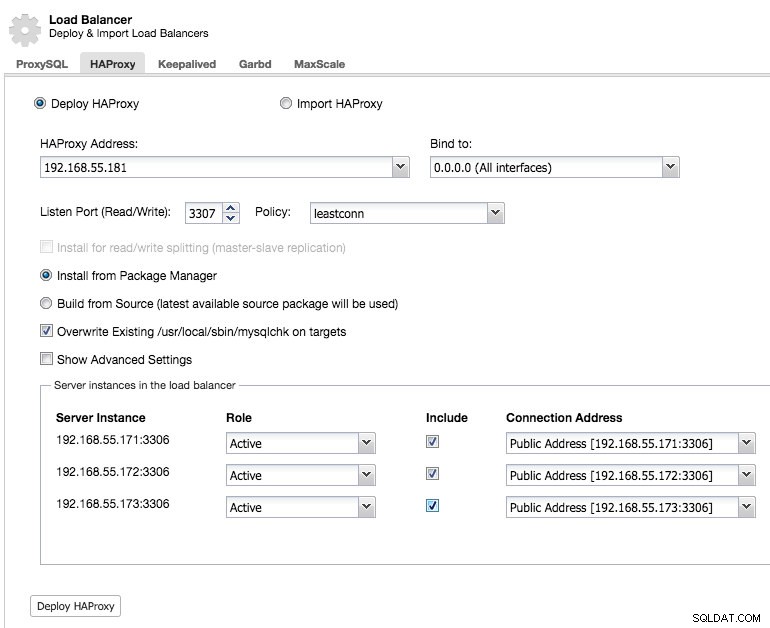
Och du kommer att kunna distribuera en HAProxy-instans genom att lägga till värdadressen och välja de serverinstanser som du vill inkludera i konfigurationen:
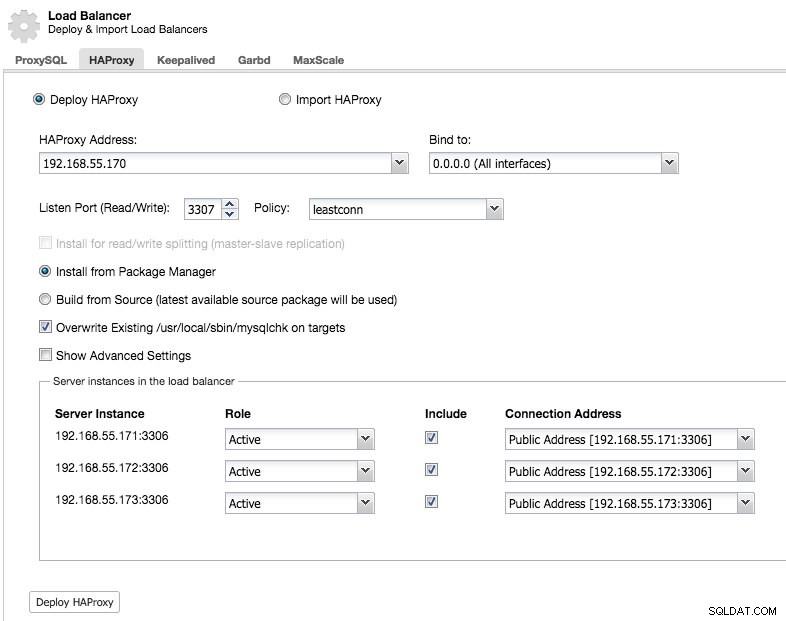
Som standard kommer HAProxy-instansen att konfigureras för att skicka anslutningar till serverinstanserna som tar emot det minsta antalet anslutningar, men du kan ändra den policyn till antingen round robin eller source.
Under avancerade inställningar kan du ställa in timeouts, maximalt antal anslutningar och till och med säkra proxyn genom att vitlista ett IP-intervall för anslutningarna.
Under nodfliken i det klustret kommer HAProxy-noden att visas:
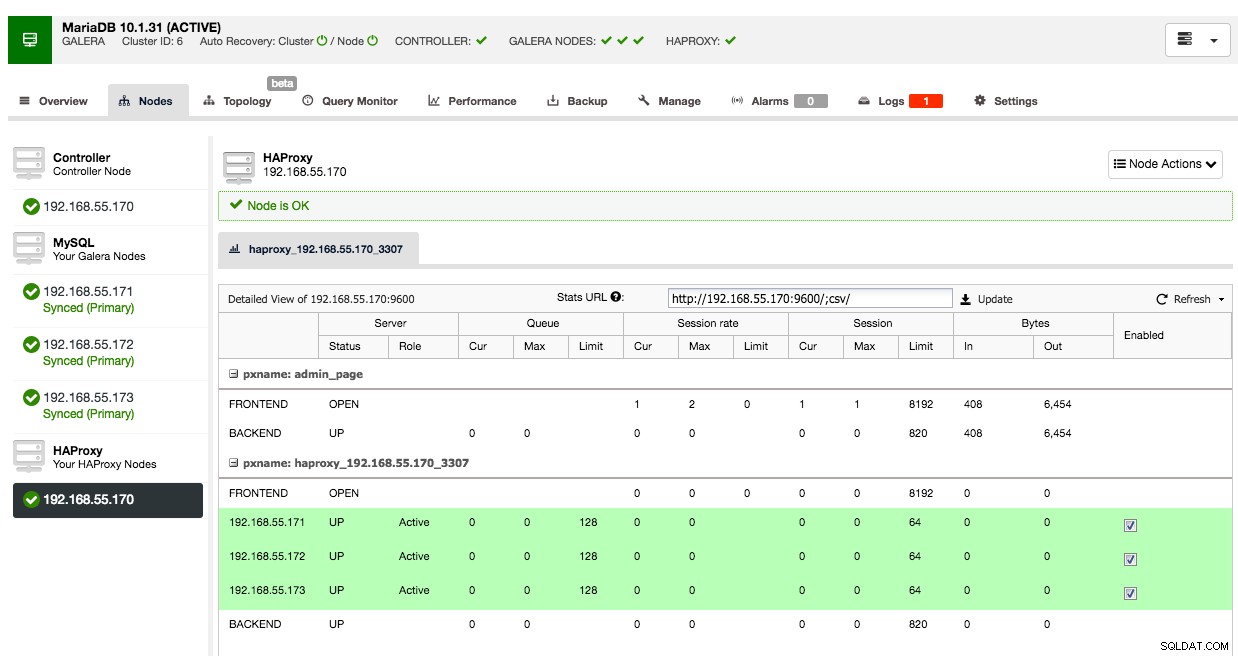
Nu är ditt Galera-kluster också tillgängligt via den nyligen utplacerade HAProxy-noden på port 3307. Glöm inte att GE din applikationsåtkomst från HAProxy IP, eftersom trafiken nu kommer in från proxyn istället för applikationsvärdarna. Kom också ihåg att peka din applikationsanslutning till HAProxy-noden.
Anta nu att en serverinstans skulle gå ner, HAProxy kommer att märka detta inom några sekunder och sluta skicka trafik till denna instans:
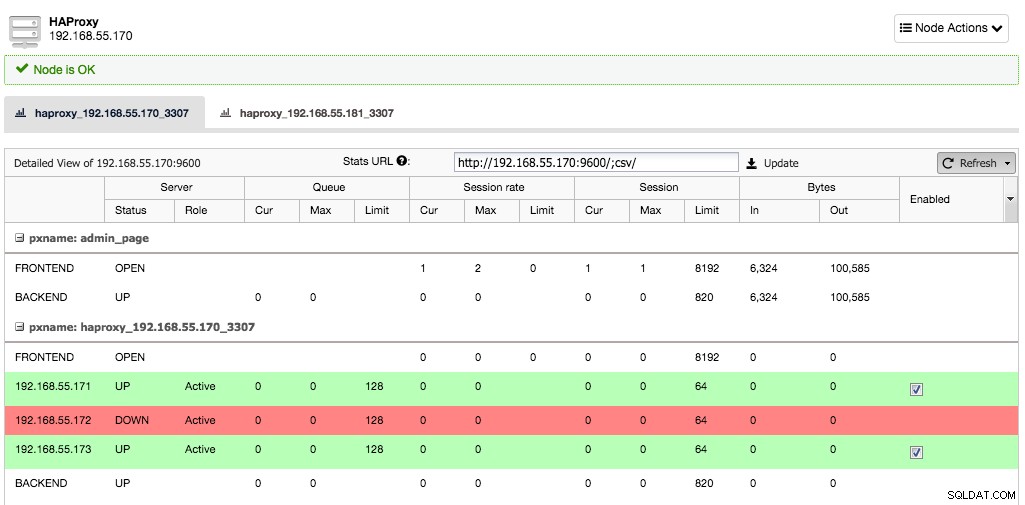
De två andra noderna är fortfarande bra och kommer att fortsätta att ta emot trafik. Detta behåller klustret mycket tillgängligt utan att klienten ens märker skillnaden.
Distribuera en sekundär HAProxy-nod
Nu när vi har flyttat ansvaret för att bibehålla hög tillgänglighet över databasanslutningarna från klienten till HAProxy, vad händer om proxynoden dör? Svaret är att skapa en annan HAProxy-instans och använda en virtuell IP som kontrolleras av Keepalived som visas i detta diagram:
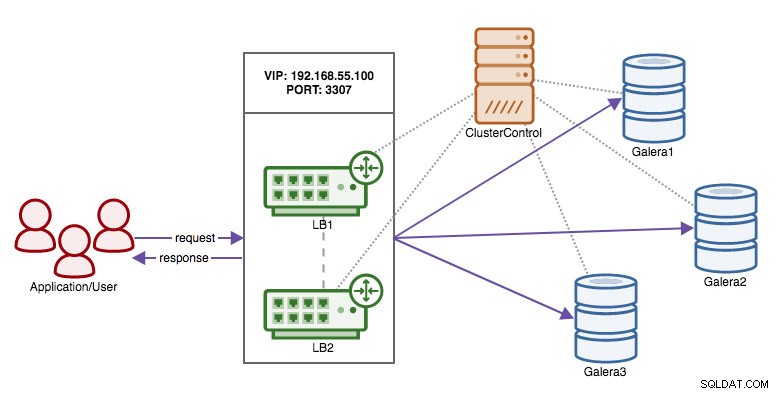
Fördelen jämfört med att använda virtuella IP-adresser på databasnoderna är att logiken för MySQL är på proxynivå och failover för proxyerna är enkel.
Så låt oss distribuera en sekundär HAProxy-nod:
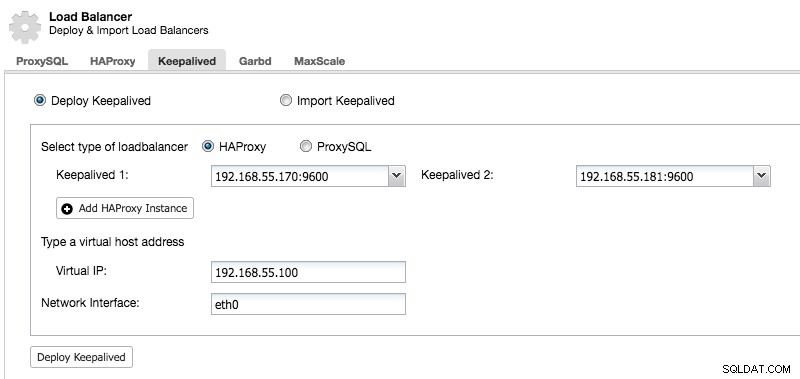
Efter att vi har distribuerat en sekundär HAProxy-nod måste vi lägga till Keepalived:
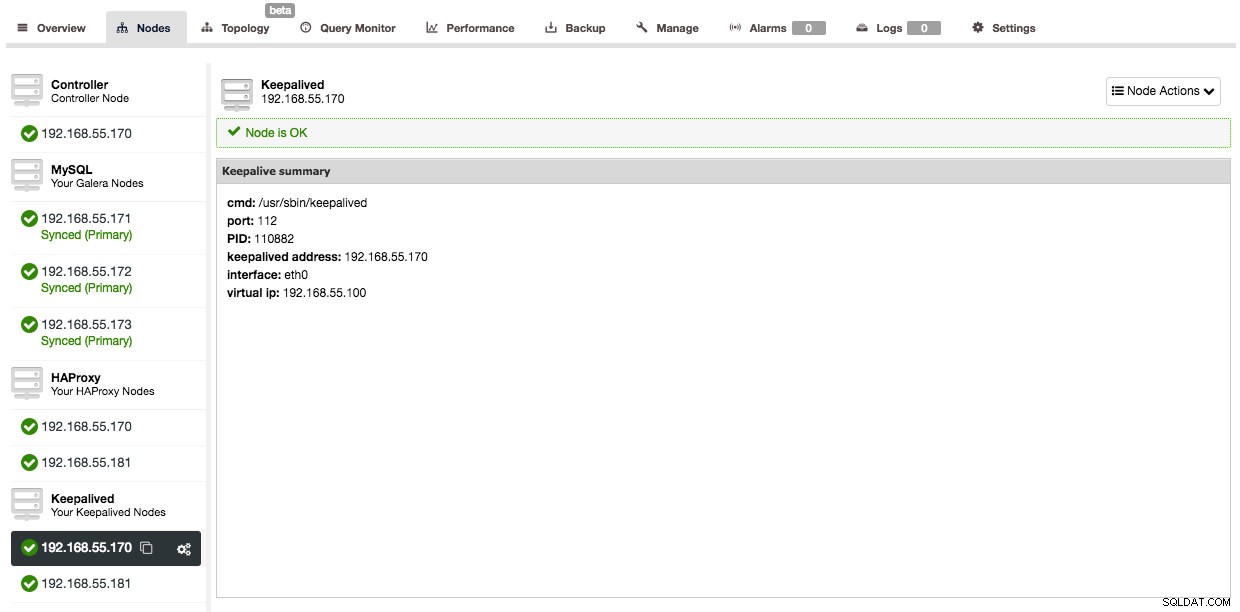
Och efter att Keepalved har lagts till kommer din nodöversikt att se ut så här:
Så nu istället för att peka dina applikationsanslutningar till HAProxy-noden direkt måste du peka dem till den virtuella IP:n istället.
I exemplet här använde vi separata värdar för att köra HAProxy på, men du kan enkelt lägga till dem i befintliga serverinstanser också. HAProxy medför inte mycket overhead, även om du bör komma ihåg att i händelse av ett serverfel kommer du att förlora både databasnoden och proxyn.
Distribuera ProxySQL
Att distribuera ProxySQL till ditt kluster görs på liknande sätt som HAProxy:"Lägg till lastbalanserare" i klusterlistan under fliken ProxySQL.
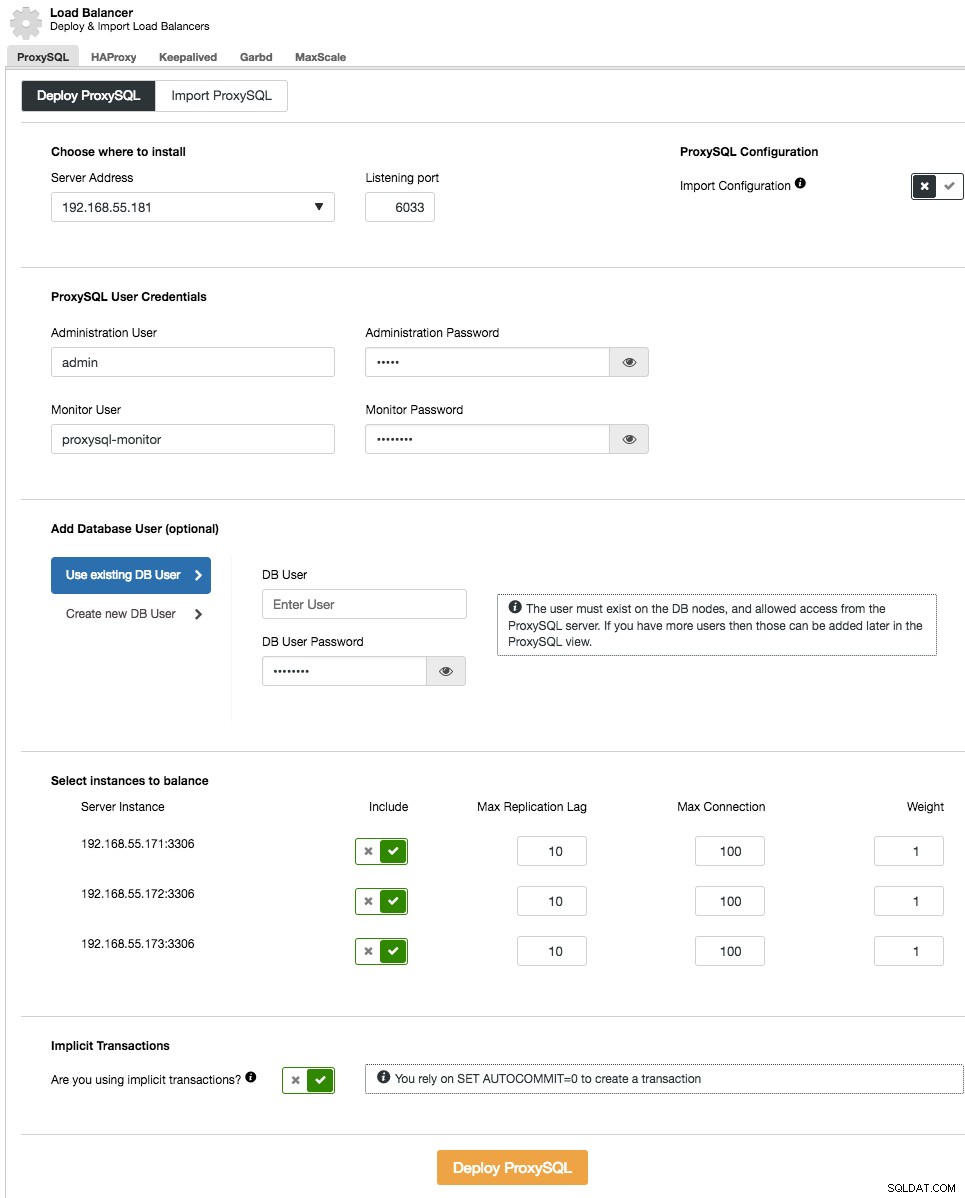
I distributionsguiden, ange var ProxySQL ska installeras, administratörsanvändaren/lösenordet, övervakningsanvändaren/lösenordet för att ansluta till MySQL-backends. Från ClusterControl kan du antingen skapa en ny användare som ska användas av applikationen (användaren kommer att skapas på både MySQL och ProxySQL) eller använda befintliga databasanvändare (användaren skapas endast på ProxySQL). Ange om du använder implicita transaktioner eller inte. I grund och botten, om du inte använder SET autocommit=0 för att skapa en ny transaktion, kommer ClusterControl att konfigurera läs/skrivdelning.
Efter att ProxySQL har distribuerats kommer den att vara tillgänglig under fliken Noder:
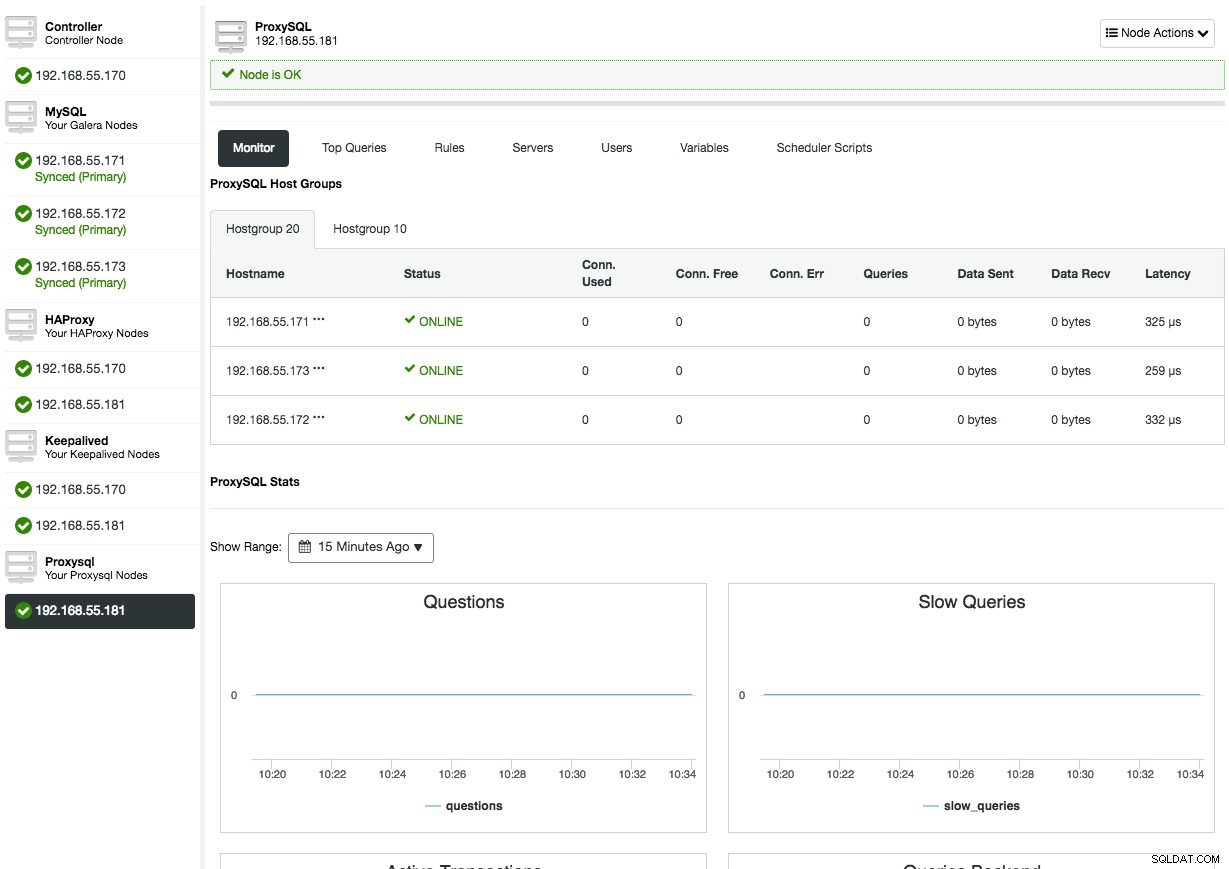
Genom att öppna ProxySQL-nodöversikten kommer du att presentera ProxySQL-övervaknings- och hanteringsgränssnittet, så det finns ingen anledning att logga in på ProxySQL på noden längre. ClusterControl täcker det mesta av ProxySQL-viktiga statistik som minnesanvändning, frågecache, frågeprocessor och så vidare, såväl som andra mätvärden som värdgrupper, backend-servrar, frågeregelträffar, toppfrågor och ProxySQL-variabler. I ProxySQL-hanteringsaspekten kan du hantera frågeregler, backend-servrar, användare, konfiguration och schemaläggare direkt från användargränssnittet.
Kolla in vår ProxySQL handledningssida som täcker utförligt hur man utför databasbelastningsbalansering för MySQL och MariaDB med ProxySQL.
Distribuera Garbd
Galera implementerar en kvorumbaserad algoritm för att välja en primär komponent genom vilken den upprätthåller konsekvens. Den primära komponenten måste ha en majoritet av rösterna (50 % + 1 nod), så i ett system med 2 noder skulle det inte finnas någon majoritet vilket resulterar i splittrad hjärna. Lyckligtvis är det möjligt att lägga till en garbd (Galera Arbitrator Daemon), som är en lättviktig statslös demon som kan fungera som den udda noden. Den extra fördelen med att lägga till Galera Arbitrator är att du nu kan göra med bara två noder i ditt kluster.
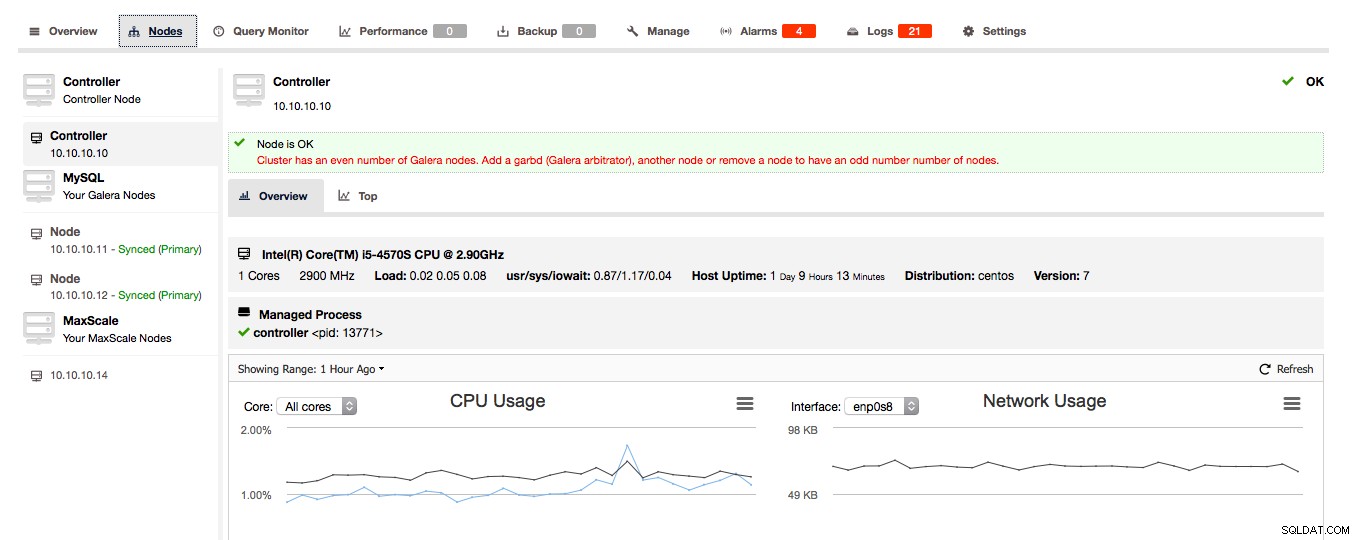
Om ClusterControl upptäcker att ditt Galera-kluster består av ett jämnt antal noder, kommer du att få en varning/råd från ClusterControl att utöka klustret till ett udda antal noder:
Välj klokt värden att distribuera garbd på, eftersom den kommer att ta emot all replikerad data. Se till att nätverket kan hantera trafiken och är tillräckligt säkert. Du kan välja en av HAProxy- eller ProxySQL-värdarna att distribuera garbd på, som i exemplet nedan:
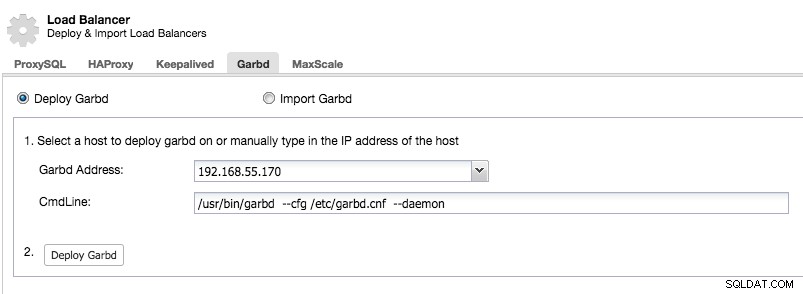
Observera att från och med ClusterControl 1.5.1 kan garbd inte installeras på samma värd som ClusterControl på grund av risken för paketkonflikter.
När du har installerat garbd kommer du att se det visas bredvid dina två Galera-noder:

Sluta tankar
Vi visade dig hur du gör dina MySQL master-slave och Galera-klusterinställningar mer robusta och bibehåller hög tillgänglighet med HAProxy och ProxySQL. Garbd är också en trevlig demon som kan spara den extra tredje noden i ditt Galera-kluster.
Detta avslutar distributionssidan av ClusterControl. I vår nästa blogg kommer vi att visa dig hur du integrerar ClusterControl inom din organisation genom att använda grupper och tilldela vissa roller till användare.