Ansible är helt enkelt fantastiskt och PostgreSQL är verkligen fantastiskt, låt oss se hur de fungerar fantastiskt tillsammans!

=====================Meddelande på bästa sändningstid! =====================
PGConf Europe 2015 kommer att äga rum den 27-30 oktober i Wien i år.
Jag antar att du möjligen är intresserad av konfigurationshantering, serverorkestrering, automatiserad distribution (det är därför du läser det här blogginlägget, eller hur?) och att du gillar att arbeta med PostgreSQL (säkert) på AWS (valfritt), då kanske du vill gå med i mitt föredrag "Hantera PostgreSQL med Ansible" den 28 oktober, 15-15:50.
Kontrollera det fantastiska schemat och missa inte chansen att delta i Europas största PostgreSQL-evenemang!
Hoppas vi ses där, ja jag gillar att dricka kaffe efter samtal 🙂
====================Meddelande på bästa sändningstiden! =====================
Vad är Ansible och hur det fungerar?
Ansibles motto är "senkel, agentlös och kraftfull IT-automatisering med öppen källkod ” genom att citera från Ansible docs.
Som det kan ses av figuren nedan anger Ansibles hemsida att de huvudsakliga användningsområdena för Ansible är:provisionering, konfigurationshantering, app-distribution, kontinuerlig leverans, säkerhet och efterlevnad, orkestrering. Översiktsmenyn visar också på vilka plattformar vi kan integrera Ansible, dvs AWS, Docker, OpenStack, Red Hat, Windows.
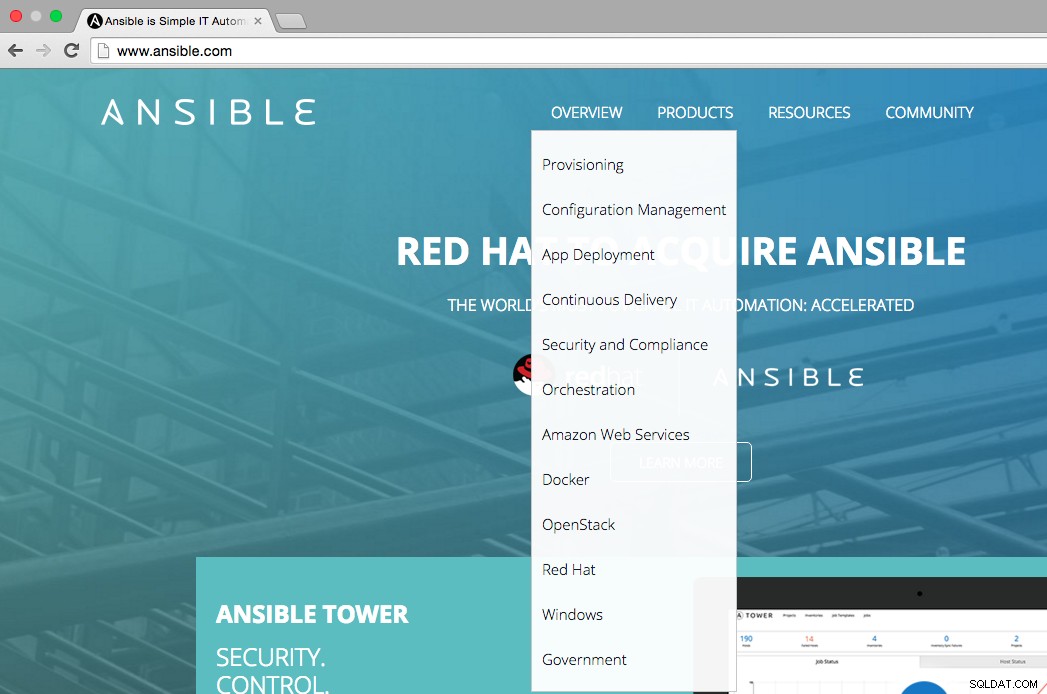
Låt oss titta på huvudanvändningsfallen för Ansible för att förstå hur det fungerar och hur användbart det är för IT-miljöer.
Provisionering
Ansible är din lojala vän när du vill automatisera allt i ditt system. Det är agentlöst och du kan helt enkelt hantera dina saker (dvs servrar, lastbalanserare, switchar, brandväggar) via SSH. Oavsett om dina system körs på bare-metal- eller molnservrar kommer Ansible att finnas där och hjälpa dig att tillhandahålla dina instanser. Dess idempotenta egenskaper säkerställer att du alltid kommer att vara i det tillstånd du önskat (och förväntat dig) ska vara.
Konfigurationshantering
En av de svåraste sakerna är att inte upprepa sig i repetitiva operativa uppgifter och här kommer Ansible att tänka på igen som en räddare. På den gamla goda tiden när tiderna var dåliga skrev sysadmins många många skript och kopplade till många många servrar för att tillämpa dem och det var uppenbarligen inte det bästa i deras liv. Som vi alla vet är manuella uppgifter felbenägna och de leder till heterogen miljö istället för en homogen och mer hanterbar sådan och gör definitivt vårt liv mer stressigt.
Med Ansible kan du skriva enkla spelböcker (med hjälp av mycket informativ dokumentation och stöd från dess enorma community) och när du väl har skrivit dina uppgifter kan du anropa ett brett utbud av moduler (t.ex. AWS, Nagios, PostgreSQL, SSH, APT, File moduler). Som ett resultat kan du fokusera på mer kreativa aktiviteter än att hantera konfigurationer manuellt.
App-distribution
Med artefakterna redo är det superenkelt att distribuera dem till ett antal servrar. Eftersom Ansible kommunicerar över SSH, finns det inget behov av att hämta från ett arkiv på varje server eller krångla med uråldriga metoder som att kopiera filer över FTP. Ansible kan synkronisera artefakter och se till att endast nya eller uppdaterade filer överförs och föråldrade filer tas bort. Detta gör också filöverföringar snabbare och sparar mycket bandbredd.
Förutom att överföra filer hjälper Ansible även till att göra servrar redo för produktionsanvändning. Innan överföringen kan den pausa övervakning, ta bort servrar från lastbalanserare och stoppa tjänster. Efter implementeringen kan den starta tjänster, lägga till servrar till lastbalanserare och återuppta övervakningen.
Allt detta behöver inte ske på en gång för alla servrar. Ansible kan arbeta på en delmängd av servrar åt gången för att tillhandahålla driftsättningar utan driftstopp. Till exempel vid en enda gång kan den distribuera 5 servrar samtidigt, och sedan kan den distribuera till nästa 5 servrar när de är klara.
Efter att ha implementerat detta scenario kan det köras var som helst. Utvecklare eller medlemmar i QA-teamet kan göra distributioner på sina egna maskiner för teständamål. Dessutom, för att återställa en distribution av någon anledning, är alla Ansible-behov platsen för de senast kända arbetsartefakterna. Det kan sedan enkelt omdistribuera dem på produktionsservrar för att återställa systemet i ett stabilt tillstånd.
Kontinuerlig leverans
Kontinuerlig leverans innebär att anta ett snabbt och enkelt tillvägagångssätt för releaser. För att uppnå det målet är det avgörande att använda de bästa verktygen som möjliggör frekventa släpp utan stillestånd och kräver så lite mänskligt ingripande som möjligt. Eftersom vi har lärt oss om applikationsdistributionsfunktioner för Ansible ovan, är det ganska enkelt att utföra distributioner utan driftstopp. Det andra kravet för kontinuerlig leverans är mindre manuella processer och det innebär automatisering. Ansible kan automatisera alla uppgifter från att tillhandahålla servrar till att konfigurera tjänster för att bli produktionsklara. Efter att ha skapat och testat scenarier i Ansible blir det trivialt att sätta dem framför ett kontinuerligt integrationssystem och låta Ansible göra sitt jobb.
Säkerhet och efterlevnad
Säkerhet anses alltid vara det viktigaste men att hålla system säkra är en av de svåraste sakerna att uppnå. Du måste vara säker på säkerheten för din data samt säkerheten för din kunds data. För att vara säker på säkerheten för dina system räcker det inte med att definiera säkerhet, du måste kunna tillämpa den säkerheten och ständigt övervaka dina system för att säkerställa att de förblir kompatibla med den säkerheten.
Ansible är lätt att använda oavsett om det handlar om att sätta upp brandväggsregler, låsa användare och grupper eller tillämpa anpassade säkerhetspolicyer. Det är säkert till sin natur eftersom du kan använda samma konfiguration upprepade gånger, och det kommer bara att göra de nödvändiga ändringarna för att återställa systemet i överensstämmelse.
Orkestrering
Ansible ser till att alla givna uppgifter är i rätt ordning och upprättar en harmoni mellan alla resurser som den hanterar. Orkestrering av komplexa flerskiktsdistributioner är enklare med Ansibles konfigurationshantering och distributionsmöjligheter. Till exempel, med tanke på distributionen av en mjukvarustack, problem som att se till att alla databasservrar är redo innan du aktiverar applikationsservrar eller att ha nätverket konfigurerat innan du lägger till servrar till lastbalanseraren är inte längre komplicerade problem.
Ansible hjälper också till med orkestrering av andra orkestreringsverktyg som Amazons CloudFormation, OpenStack’s Heat, Docker’s Swarm, etc. På detta sätt, istället för att lära sig olika plattformar, språk och regler; användare kan bara koncentrera sig på Ansibles YAML-syntax och kraftfulla moduler.
Vad är en Ansible-modul?
Moduler eller modulbibliotek tillhandahåller Ansible sätt att kontrollera eller hantera resurser på lokala eller fjärrservrar. De utför en mängd olika funktioner. Till exempel kan en modul vara ansvarig för att starta om en maskin eller så kan den helt enkelt visa ett meddelande på skärmen.
Ansible låter användare skriva sina egna moduler och tillhandahåller även färdiga kärn- eller extramoduler.
Vad sägs om Ansible-spelböcker?
Ansible låter oss organisera vårt arbete på olika sätt. I sin mest direkta form kan vi arbeta med Ansible-moduler med hjälp av "ansible ” kommandoradsverktyget och inventeringsfilen.
Inventering
Ett av de viktigaste koncepten är inventeringen . Vi behöver en inventeringsfil för att låta Ansible veta vilka servrar den behöver för att ansluta med SSH, vilken anslutningsinformation den kräver och eventuellt vilka variabler som är associerade med dessa servrar.
Inventeringsfilen är i ett INI-liknande format. I inventeringsfilen kan vi specificera mer än en värd och gruppera dem under mer än en värdgrupp.
Vårt exempel på inventeringsfilen hosts.ini ser ut som följande:
[dbservers]
db.example.com
Här har vi en enda värd som heter "db.example.com" i en värdgrupp som heter "dbservers". I inventeringsfilen kan vi även inkludera anpassade SSH-portar, SSH-användarnamn, SSH-nycklar, proxyinformation, variabler etc.
Eftersom vi har en inventeringsfil redo, för att se drifttiderna för våra databasservrar, kan vi anropa Ansibles "kommando ”-modulen och kör “upptid ” kommandot på dessa servrar:
ansible dbservers -i hosts.ini -m command -a "uptime"
Här instruerade vi Ansible att läsa värdar från hosts.ini-filen, ansluta dem med SSH, köra "upptid ” på var och en av dem och skriv sedan ut deras utdata på skärmen. Denna typ av modulkörning kallas ett ad-hoc-kommando .
Utdata för kommandot kommer att se ut som:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Men om vår lösning innehåller mer än ett enda steg, blir det svårt att hantera dem endast genom att använda ad-hoc-kommandon.
Här kommer Ansible playbooks. Det låter oss organisera vår lösning i en playbook-fil genom att integrera alla steg med hjälp av uppgifter, variabler, roller, mallar, hanterare och en inventering.
Låt oss ta en kort titt på några av dessa termer för att förstå hur de kan hjälpa oss.
Uppgifter
Ett annat viktigt begrepp är uppgifter. Varje Ansible-uppgift innehåller ett namn, en modul som ska anropas, modulparametrar och eventuellt för-/eftervillkor. De tillåter oss att ringa Ansible-moduler och skicka information till på varandra följande uppgifter.
Variabler
Det finns också variabler. De är mycket användbara för att återanvända information vi tillhandahållit eller samlat in. Vi kan antingen definiera dem i inventeringen, i externa YAML-filer eller i spelböcker.
Playbook
Ansible playbooks är skrivna med YAML-syntaxen. Den kan innehålla mer än en pjäs. Varje pjäs innehåller namn på värdgrupper att ansluta till och uppgifter som den behöver utföra. Den kan också innehålla variabler/roller/hanterare, om de definieras.
Nu kan vi titta på en mycket enkel spelbok för att se hur den kan struktureras:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeI denna mycket enkla spelbok sa vi till Ansible att den skulle fungera på servrar definierade i värdgruppen "dbservers". Vi skapade en variabel som heter "vem" och sedan definierade vi våra uppgifter. Lägg märke till att i den första uppgiften där vi skriver ut ett felsökningsmeddelande använde vi variabeln "who" och fick Ansible att skriva ut "Hello World" på skärmen. I den andra uppgiften sa vi till Ansible att ansluta till varje värd och sedan utföra kommandot "upptid" där.
Ansible PostgreSQL-moduler
Ansible tillhandahåller ett antal moduler för PostgreSQL. Vissa av dem finns under kärnmoduler medan andra finns under extramoduler.
Alla PostgreSQL-moduler kräver att Python psycopg2-paketet installeras på samma maskin som PostgreSQL-servern. Psycopg2 är en PostgreSQL-databasadapter i programmeringsspråket Python.
På Debian/Ubuntu-system kan paketet psycopg2 installeras med följande kommando:
apt-get install python-psycopg2
Nu kommer vi att undersöka dessa moduler i detalj. Till exempel kommer vi att arbeta på en PostgreSQL-server på värd db.example.com på port 5432 med postgres användare och ett tomt lösenord.
postgresql_db
Denna kärnmodul skapar eller tar bort en given PostgreSQL-databas. I Ansible terminologi säkerställer det att en given PostgreSQL-databas finns eller saknas.
Det viktigaste alternativet är den obligatoriska parametern "namn ”. Det representerar namnet på databasen i en PostgreSQL-server. En annan viktig parameter är "tillstånd ”. Det kräver ett av två värden:present eller frånvarande . Detta tillåter oss att skapa eller ta bort en databas som identifieras av värdet som anges i namnet parameter.
Vissa arbetsflöden kan också kräva specifikation av anslutningsparametrar såsom login_host , port , login_user och login_password .
Låt oss skapa en databas som heter "module_test ” på vår PostgreSQL-server genom att lägga till nedanstående rader i vår playbook-fil:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Här kopplade vi till vår testdatabasserver på db.example.com med användaren; postgres . Det behöver dock inte vara postgres användare som användarnamn kan vara vad som helst.
Att ta bort databasen är lika enkelt som att skapa den:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Notera värdet "frånvarande" i parametern "tillstånd".
postgresql_ext
PostgreSQL är känt för att ha mycket användbara och kraftfulla tillägg. Till exempel, ett nyligen tillägg är tsm_system_rows vilket hjälper till att hämta det exakta antalet rader i tabellsampling. (För ytterligare information kan du kolla mitt tidigare inlägg om tabellsamplingsmetoder.)
Denna extramodul lägger till eller tar bort PostgreSQL-tillägg från en databas. Det kräver två obligatoriska parametrar:db och namn . db parametern refererar till databasnamnet och namnet parametern hänvisar till tilläggsnamnet. Vi har också staten parameter som behöver presenteras eller frånvarande värden och samma anslutningsparametrar som i postgresql_db-modulen.
Låt oss börja med att skapa tillägget vi pratade om:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Denna kärnmodul tillåter att lägga till eller ta bort användare och roller från en PostgreSQL-databas.
Det är en mycket kraftfull modul för samtidigt som den säkerställer att en användare finns i databasen, tillåter den samtidigt modifiering av privilegier eller roller.
Låt oss börja med att titta på parametrarna. Den enda obligatoriska parametern här är "namn ”, som hänvisar till en användare eller ett rollnamn. Dessutom, som i de flesta Ansible-moduler, "tillstånd " parametern är viktig. Den kan ha en av närvarande eller frånvarande värden och dess standardvärde är nu .
Förutom anslutningsparametrar som i tidigare moduler, är några av andra viktiga valfria parametrar:
- db :Namn på databasen där behörigheter kommer att beviljas
- lösenord :Användarens lösenord
- privat :Behörigheter i "priv1/priv2" eller tabellprivilegier i formatet "table:priv1,priv2,..."
- role_attr_flags :Rollattribut. Möjliga värden är:
- [NEJ]SUPERANVÄNDARE
- [NEJ]KREATEROL
- [NEJ]SKAPAANVÄNDARE
- [NEJ]SKAPADEDB
- [NEJ]ÄRV
- [NEJ]LOGGA IN
- [INGEN]REPLIKATION
För att skapa en ny användare som heter ada med lösenordet lovelace och ett anslutningsprivilegium till databasen module_test , kan vi lägga till följande i vår spelbok:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Nu när vi har användaren redo kan vi tilldela henne några roller. För att tillåta "ada" att logga in och skapa databaser:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Vi kan också ge globala eller tabellbaserade privilegier som "INSERT ”, “UPPDATERA ”, “VÄLJ ” och ”RADERA ” med hjälp av privat parameter. En viktig punkt att tänka på är att en användare inte kan tas bort förrän alla beviljade rättigheter återkallas först.
postgresql_privs
Den här kärnmodulen beviljar eller återkallar privilegier på PostgreSQL-databasobjekt. Objekt som stöds är:tabell , sekvens , funktion , databas , schema , språk , tabellutrymme , och grupp .
Nödvändiga parametrar är "databas"; namnet på databasen att bevilja/återkalla privilegier på, och "roller"; en kommaseparerad lista med rollnamn.
De viktigaste valfria parametrarna är:
- typ :Typ av objektet att sätta behörigheter på. Kan vara en av:tabell, sekvens, funktion, databas, schema, språk, tabellutrymme, grupp . Standardvärdet är tabell .
- objs :Databasobjekt att ställa in privilegier på. Kan ha flera värden. I så fall separeras objekt med ett kommatecken.
- privat :Kommaseparerad lista över privilegier att bevilja eller återkalla. Möjliga värden inkluderar:ALLA , VÄLJ , UPPDATERA , INSERT .
Låt oss se hur detta fungerar genom att bevilja alla privilegier på "public " schema till "ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
En av de mycket kraftfulla funktionerna i PostgreSQL är dess stöd för praktiskt taget alla språk som ska användas som ett procedurspråk. Denna extramodul lägger till, tar bort eller ändrar procedurspråk med en PostgreSQL-databas.
Den enda obligatoriska parametern är "lang ”; namnet på det procedurspråk som ska läggas till eller tas bort. Andra viktiga alternativ är "db ”; namnet på databasen där språket läggs till eller tas bort från, och "trust ”; alternativet för att göra språket tillförlitligt eller otillförlitligt för den valda databasen.
Låt oss aktivera PL/Python-språket för vår databas:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Sammanlägger allt
Nu när vi vet hur en Ansible-spelbok är uppbyggd och vilka PostgreSQL-moduler som är tillgängliga för oss att använda, kan vi nu kombinera vår kunskap i en Ansible-spelbok.
Den slutliga formen av vår spelbok main.yml är följande:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Nu kan vi köra vår spelbok med kommandot "ansible-playbook":
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Du kan hitta inventeringen och playbook-filen på mitt GitHub-arkiv som skapats för det här blogginlägget. Det finns också en annan spelbok som heter "remove.yml" som ångrar allt vi gjorde i huvudspelboken.
För mer information om Ansible:
- Kolla in deras välskrivna dokument.
- Titta på Ansible-snabbstartsvideon som är en väldigt användbar självstudie.
- Följ deras webinarschema, det finns några coola kommande webbseminarier på listan.