I en tidigare blogg tillkännagav vi en ny ClusterControl 1.7.4-funktion som heter Cluster-to-Cluster Replication. Det automatiserar hela processen med att konfigurera ett DR-kluster utanför ditt primära kluster, med replikering däremellan. För mer detaljerad information, se ovan nämnda blogginlägg.
Nu i den här bloggen kommer vi att ta en titt på hur man konfigurerar den här nya funktionen för ett befintligt kluster. För den här uppgiften antar vi att du har ClusterControl installerat och att Master Cluster har distribuerats med det.
Krav för Master Cluster
Det finns några krav för att Master Cluster ska få det att fungera:
- Percona XtraDB Cluster version 5.6.x och senare, eller MariaDB Galera Cluster version 10.x och senare.
- GTID aktiverat.
- Binär loggning aktiverad på minst en databasnod.
- Referensuppgifterna för säkerhetskopiering måste vara desamma i huvudklustret och slavklustret.
Förbereder masterklustret
Masterklustret måste förberedas för att använda den här nya funktionen. Det kräver konfiguration från både ClusterControl- och Databassidan.
ClusterControl-konfiguration
I databasnoden, kontrollera användaruppgifterna för säkerhetskopiering lagrade i /etc/my.cnf.d/secrets-backup.cnf (för RedHat-baserat OS) eller i /etc/mysql/secrets-backup .cnf (för Debian-baserat operativsystem).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElI ClusterControl-noden, redigera /etc/cmon.d/cmon_ID.cnf-konfigurationsfilen (där ID är kluster-ID-numret) och se till att den innehåller samma referenser lagrade i secrets-backup. cnf.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Alla ändringar i den här filen kräver en omstart av cmon-tjänsten:
$ service cmon restartKontrollera databasreplikeringsparametrarna för att se till att du har aktiverat GTID och binär loggning.
Databaskonfiguration
I databasnoden, kontrollera filen /etc/my.cnf (för RedHat-baserat OS) eller /etc/mysql/my.cnf (för Debian-baserat OS) för att se konfigurationen relaterad till replikeringsprocessen.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7MariaDB Galera Cluster:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Om du vill kontrollera konfigurationsfilerna kan du verifiera om det är aktiverat i ClusterControl-gränssnittet. Gå till ClusterControl -> Välj Cluster -> Noder. Där borde du ha något sånt här:

"Master"-rollen som läggs till i den första noden innebär att binär loggning är aktiverad.
Aktivera binär loggning
Om du inte har den binära loggningen aktiverad, gå till ClusterControl -> Välj kluster -> Noder -> Nodåtgärder -> Aktivera binär loggning.
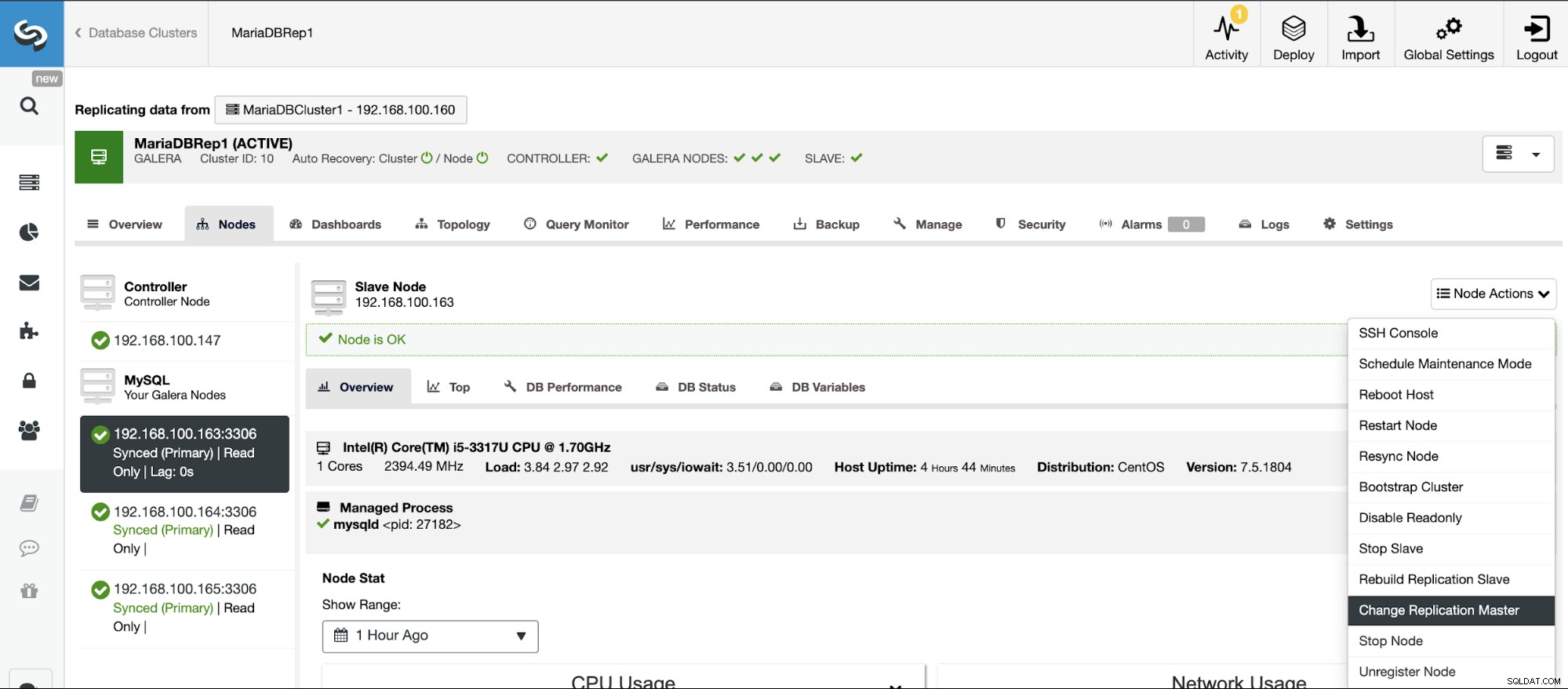
Då måste du ange den binära logglagringen och sökvägen till lagring Det. Du bör också ange om du vill att ClusterControl ska starta om databasnoden efter att ha konfigurerat den, eller om du föredrar att starta om den själv.
Tänk på att aktivering av binär loggning alltid kräver en omstart av databastjänsten .
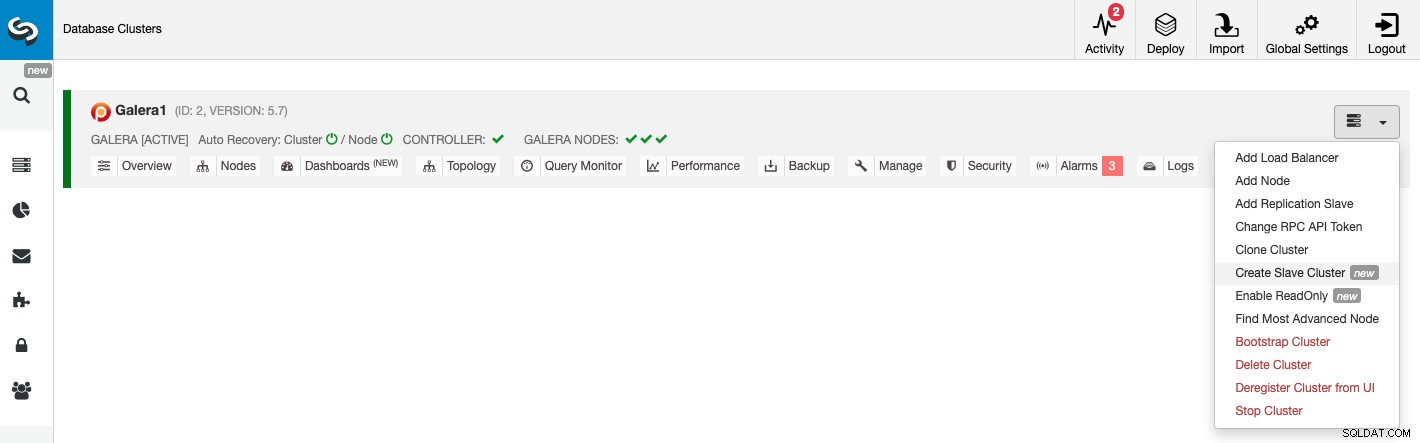
Skapa slavklustret från ClusterControl GUI
För att skapa ett nytt slavkluster, gå till ClusterControl -> Välj kluster -> Cluster Actions -> Create slavcluster.
Slavklustret kan skapas genom att strömma data från det aktuella masterklustret eller genom att använda en befintlig säkerhetskopia.
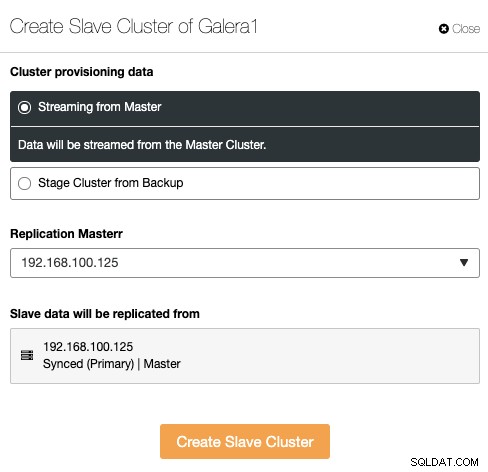
I det här avsnittet måste du också välja huvudnoden för det aktuella klustret från vilken data kommer att replikeras.
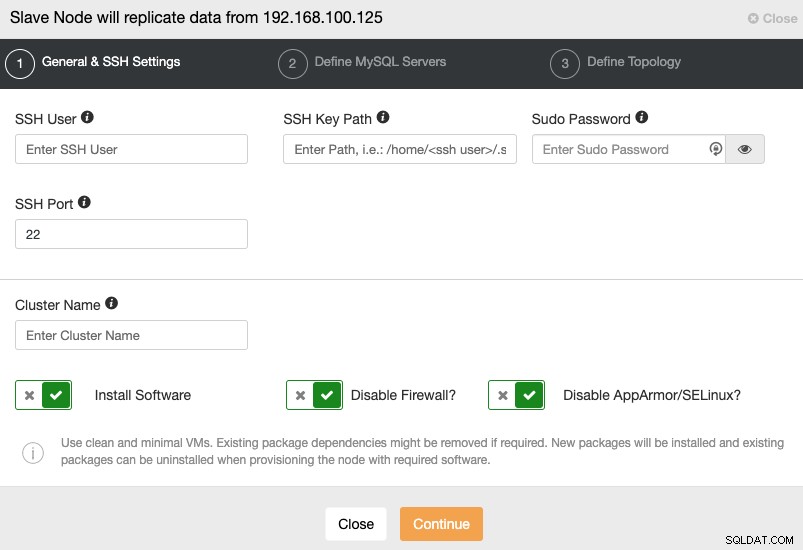
När du går till nästa steg måste du ange Användare, Nyckel eller Lösenord och port för att ansluta med SSH till dina servrar. Du behöver också ett namn för ditt slavkluster och om du vill att ClusterControl ska installera motsvarande programvara och konfigurationer åt dig.
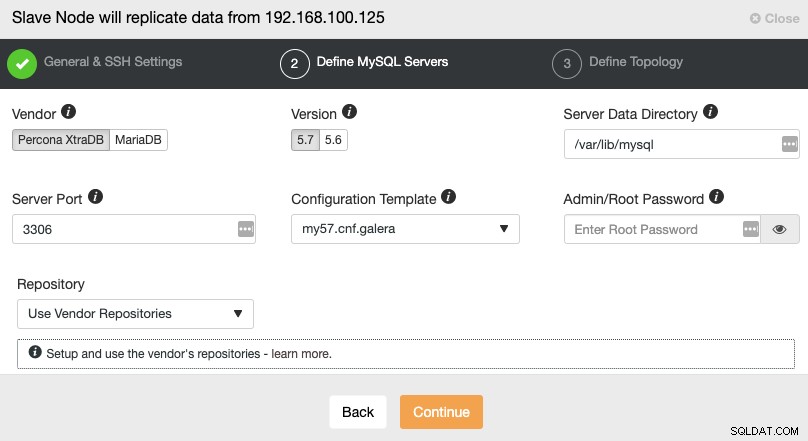
När du har ställt in SSH-åtkomstinformationen måste du definiera databasleverantören och version, datadir, databasport och administratörslösenordet. Se till att du använder samma leverantör/version och referenser som används av Master Cluster. Du kan också ange vilket arkiv som ska användas.
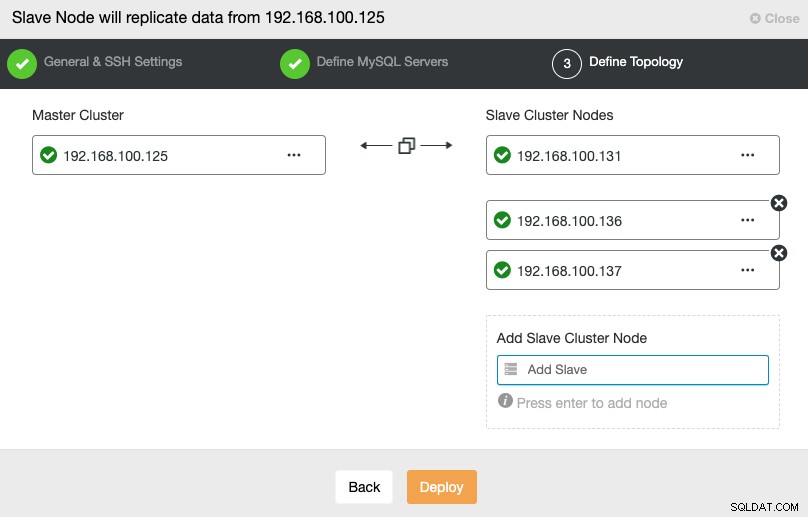
I det här steget måste du lägga till servrar till det nya slavklustret. För den här uppgiften kan du ange både IP-adress eller värdnamn för varje databasnod.
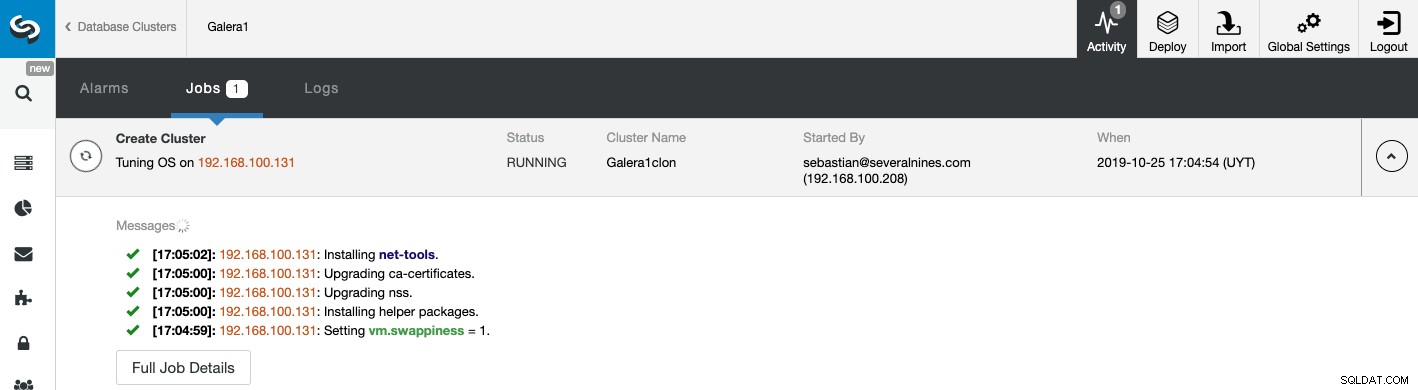
Du kan övervaka statusen för skapandet av ditt nya slavkluster från ClusterControl aktivitetsmonitor. När uppgiften är klar kan du se klustret på huvudskärmen för ClusterControl.
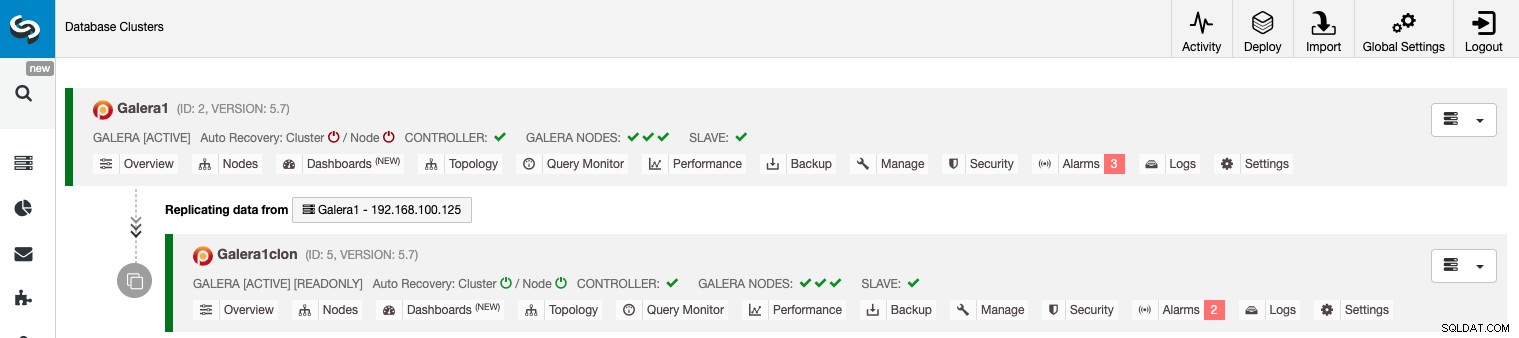
Hantera kluster-till-kluster-replikering med ClusterControl GUI
Nu har du din Cluster-to-Cluster-replikering igång, det finns olika åtgärder att utföra på denna topologi med ClusterControl.
Konfigurera Active-Active Clusters
Som du kan se är slavklustret som standard inställt i skrivskyddat läge. Det är möjligt att inaktivera skrivskyddad flagga på noderna en efter en från ClusterControl UI, men tänk på att Active-Active klustring endast rekommenderas om applikationer endast rör disjunct datauppsättningar på något kluster eftersom MySQL/MariaDB inte gör det. erbjuda någon konfliktupptäckt eller lösning.
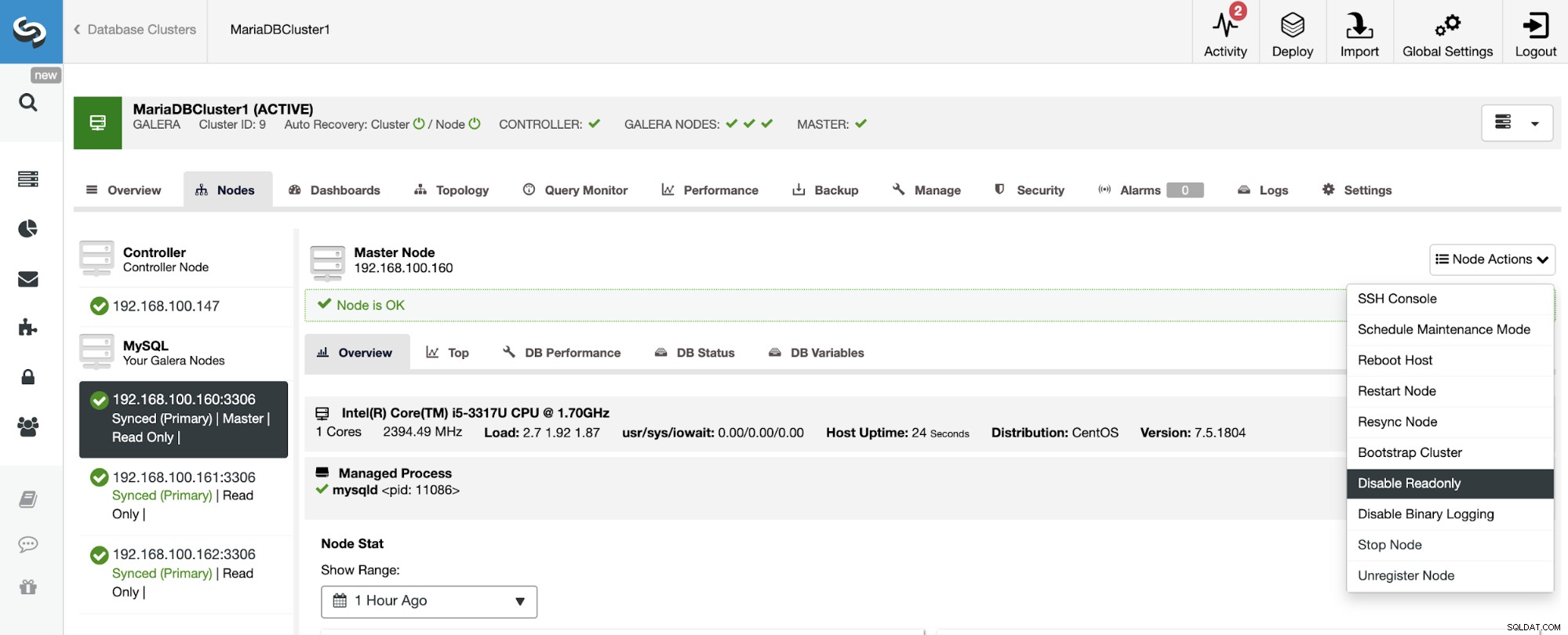
För att inaktivera skrivskyddat läge, gå till ClusterControl -> Välj slav Kluster -> Noder. I det här avsnittet, välj varje nod och använd alternativet Inaktivera skrivskyddad.
Återbygga ett slavkluster
För att undvika inkonsekvenser, om du vill bygga om ett slavkluster, måste detta vara ett skrivskyddat kluster, detta betyder att alla noder måste vara i skrivskyddat läge.
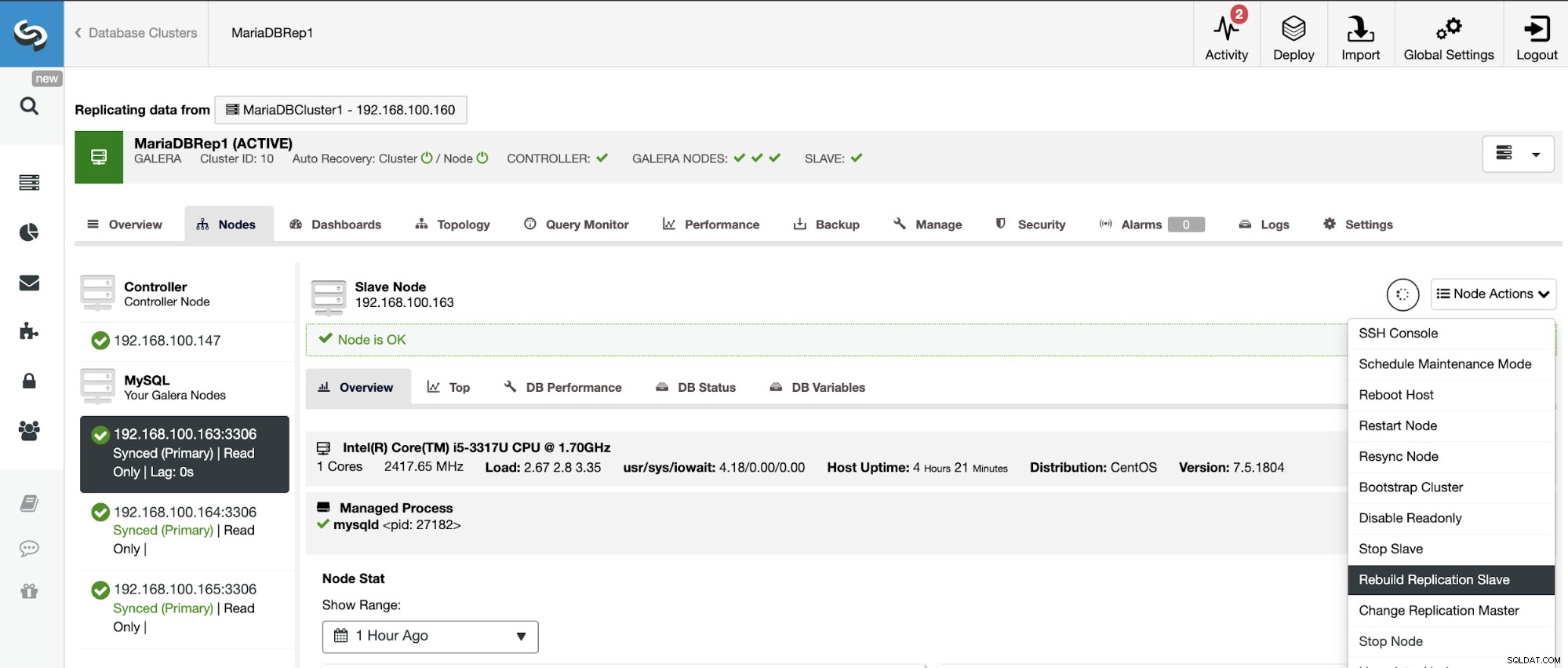
Gå till ClusterControl -> Välj slavkluster -> Noder -> Välj Nod ansluten till huvudklustret -> Nodåtgärder -> Bygg om replikeringsslav.
Topologiändringar
Om du har följande topologi:
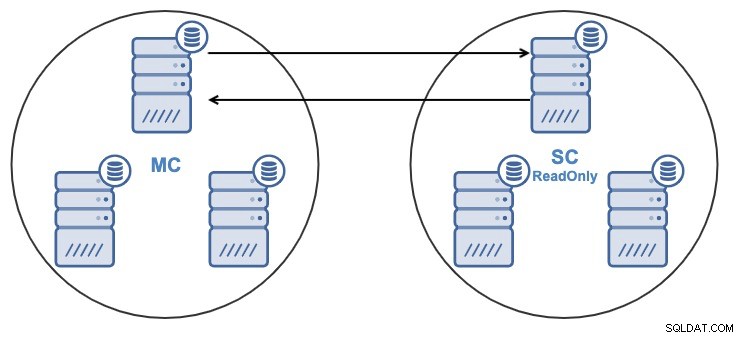
Och av någon anledning vill du ändra replikeringsnoden i mastern Klunga. Det är möjligt att ändra masternoden som används av slavklustret till en annan masternod i masterklustret.
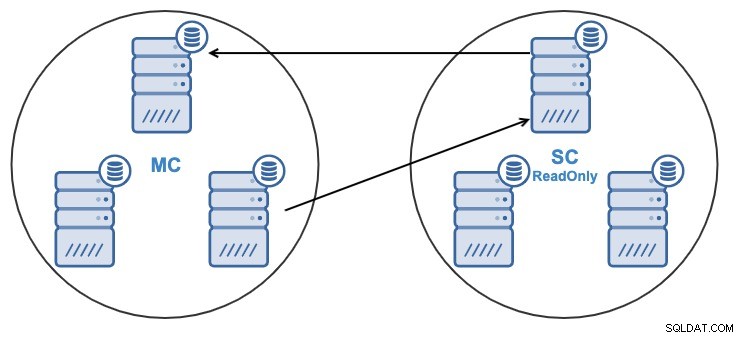
För att betraktas som en huvudnod måste den ha den binära loggningen aktiverad .
Gå till ClusterControl -> Välj slavkluster -> Noder -> Välj Nod ansluten till masterklustret -> Nodåtgärder -> Stoppa slav/Starta slav.
Stoppa/starta replikeringsslav
Du kan stoppa och starta replikeringsslavar på ett enkelt sätt med ClusterControl.
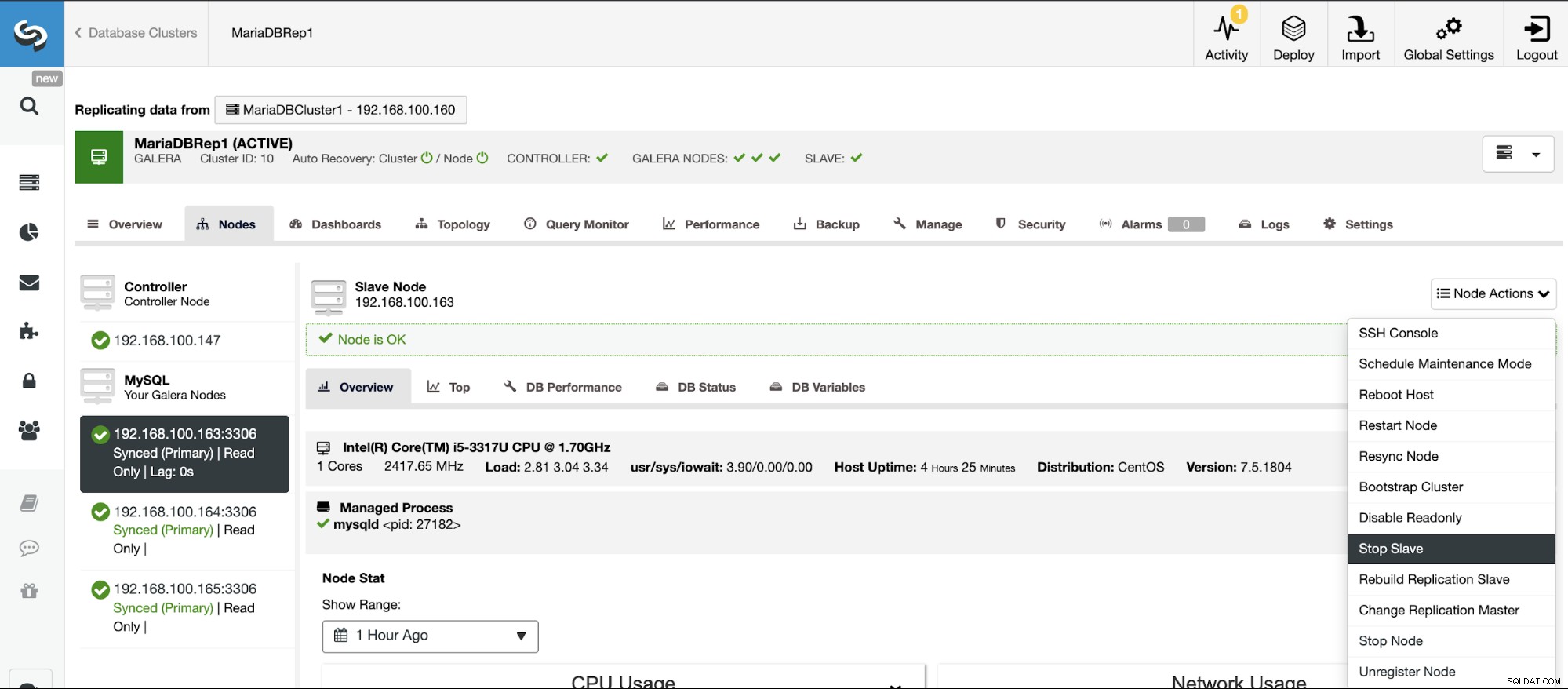
Gå till ClusterControl -> Välj slavkluster -> Noder -> Välj Nod ansluten till masterklustret -> Nodåtgärder -> Stoppa slav/Starta slav.
Återställ replikeringsslav
Med den här åtgärden kan du återställa replikeringsprocessen med RESET SLAVE eller RESET SLAVE ALL. Skillnaden mellan dem är att RESET SLAVE inte ändrar någon replikeringsparameter som huvudvärd, port och referenser. För att radera denna information måste du använda RESET SLAVE ALL som tar bort all replikeringskonfiguration, så med detta kommando kommer länken Cluster-to-Cluster Replikering att förstöras.
Innan du använder den här funktionen måste du stoppa replikeringsprocessen (se föregående funktion).
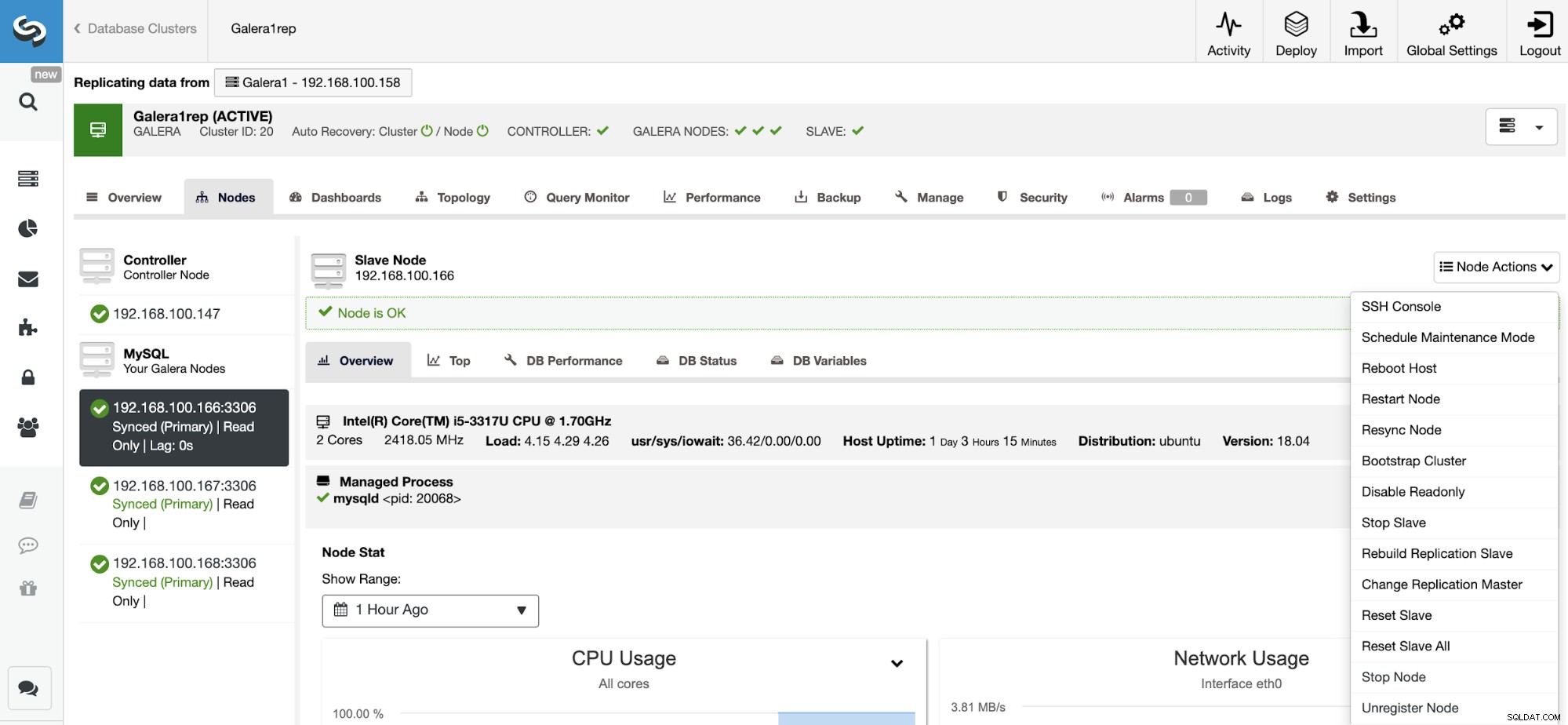
Gå till ClusterControl -> Välj slavkluster -> Noder -> Välj Nod ansluten till Master Cluster -> Nodåtgärder -> Återställ slav/Återställ slav alla.
Hantera kluster-till-kluster-replikering med ClusterControl CLI
I föregående avsnitt kunde du se hur du hanterar en kluster-till-kluster-replikering med ClusterControl-gränssnittet. Låt oss nu se hur man gör det genom att använda kommandoraden.
Obs:Som vi nämnde i början av den här bloggen, antar vi att du har ClusterControl installerat och att Master Cluster har distribuerats med det.
Skapa slavklustret
Låt oss först se ett exempel på kommando för att skapa ett slavkluster genom att använda ClusterControl CLI:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logNu har du din skapa-slavprocess igång, låt oss se varje använd parameter:
- Kluster:För att lista och manipulera kluster.
- Skapa:Skapa och installera ett nytt kluster.
- Klusternamn:Namnet på det nya slavklustret.
- Klustertyp:Typen av kluster som ska installeras.
- Provider-version:Programvaruversionen.
- Noder:Lista över de nya noderna i slavklustret.
- Os-user:Användarnamnet för SSH-kommandon.
- Os-key-file:Nyckelfilen som ska användas för SSH-anslutning.
- Db-admin:Databasadministratörens användarnamn.
- Db-admin-passwd:Lösenordet för databasadministratören.
- Remote-cluster-id:Master Cluster ID för kluster-till-kluster-replikeringen.
- Logg:Vänta och övervaka jobbmeddelanden.
Med flaggan --log kommer du att kunna se loggarna i realtid:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Konfigurera Active-Active Clusters
Som du kunde se tidigare kan du inaktivera skrivskyddat läge i det nya klustret genom att inaktivera det i varje nod, så låt oss se hur du gör det från kommandoraden.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logLåt oss se varje parameter:
- Nod:För att hantera noder.
- Set-read-write:Ställ in noden på Read-Write-läge.
- Noder:Noden där den ska ändras.
- Kluster-id:ID för klustret där noden finns.
Då ser du:
192.168.100.166:3306: Setting read_only=OFF.Återbygga ett slavkluster
Du kan bygga om ett slavkluster med följande kommando:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logPametrarna är:
- Replikering:För att övervaka och kontrollera datareplikering.
- Stage:Stage/bygga om en replikeringsslav.
- Master:Replikeringsmastern i masterklustret.
- Slav:Replikeringsslaven i slavklustret.
- Kluster-id:Slavkluster-ID.
- Remote-cluster-id:Master Cluster ID.
- Logg:Vänta och övervaka jobbmeddelanden.
Jobbloggen bör vara liknande den här:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Topologiändringar
Du kan ändra din topologi med en annan nod i Master Cluster från vilken du replikerar data, så att du till exempel kan köra:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logLåt oss kontrollera de använda parametrarna.
- Replikering:För att övervaka och kontrollera datareplikering.
- Failover:Ta rollen som mästare från en misslyckad/gammal mästare.
- Master:Den nya replikeringsmastern i Master Cluster.
- Slav:Replikeringsslaven i slavklustret.
- Kluster-id:ID för slavklustret.
- Remote-Cluster-id:Master-klustrets ID.
- Logg:Vänta och övervaka jobbmeddelanden.
Du kommer att se denna logg:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Stoppa/starta replikeringsslav
Du kan sluta replikera data från Master Cluster på detta sätt:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logDu kommer att se detta:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.Och nu kan du starta det igen:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logDu kommer alltså att se:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Låt oss nu kontrollera de använda parametrarna.
- Replikering:För att övervaka och kontrollera datareplikering.
- Stopp/Start:För att få slaven att sluta/börja replikera.
- Slav:Replikeringsslavnoden.
- Kluster-id:ID för klustret där slavnoden finns.
- Logg:Vänta och övervaka jobbmeddelanden.
Återställ replikeringsslav
Med detta kommando kan du återställa replikeringsprocessen med RESET SLAVE eller RESET SLAVE ALL. För mer information om det här kommandot, kontrollera användningen av detta i föregående avsnitt för ClusterControl UI.
Innan du använder den här funktionen måste du stoppa replikeringsprocessen (se föregående kommando).
ÅTERSTÄLL SLAV:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logLoggen ska se ut så här:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.ÅTERSTÄLL SLAVA ALLA:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logOch den här loggen bör vara:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Låt oss se vilka parametrar som används för både RESET SLAVE och RESET SLAVE ALL.
- Replikering:För att övervaka och kontrollera datareplikering.
- Återställ:Återställ slavnoden.
- Force:Genom att använda denna flagga kommer du att använda kommandot RESET SLAVE ALL på slavnoden.
- Slav:Replikeringsslavnoden.
- Kluster-id:Slavkluster-ID.
- Logg:Vänta och övervaka jobbmeddelanden.
Slutsats
Den här nya ClusterControl-funktionen låter dig skapa kluster-till-kluster-replikering snabbt och hantera den på ett enkelt och vänligt sätt. Den här miljön kommer att förbättra din databas/klustertopologi och den skulle vara användbar för en katastrofåterställningsplan, testmiljö och ännu fler alternativ som nämns i översiktsbloggen.