Ända sedan ClusterControl 1.2.11 släpptes 2015 har MariaDB MaxScale stötts som en databaslastbalanserare. Under åren har MaxScale vuxit och mognat och lagt till flera rika funktioner. Nyligen släpptes MariaDB MaxScale 2.2 och den introducerar flera nya funktioner, inklusive hantering av failover för replikeringskluster.
MariaDB MaxScale möjliggör master/slav-distributioner med hög tillgänglighet, automatisk failover, manuell övergång och automatisk återanslutning. Om mastern misslyckas kan MariaDB MaxScale automatiskt marknadsföra den mest uppdaterade slaven till master. Om den misslyckade mastern återställs kan MariaDB MaxScale automatiskt omkonfigurera den som en slav till den nya mastern. Dessutom kan administratörer utföra en manuell övergång för att ändra mastern på begäran.
I våra tidigare bloggar diskuterade vi hur man distribuerar MaxScale med ClusterControl samt hur man distribuerar MariaDB MaxScale på Docker. För dem som ännu inte är bekanta med MariaDB MaxScale är det en avancerad, plug-in, databasproxy för MariaDB databasservrar. Maxscale sitter mellan klientapplikationer och databasservrarna och dirigerar klientfrågor och serversvar. Den övervakar också servrarna och märker snabbt eventuella förändringar i serverstatus eller replikeringstopologi.
Även om Maxscale delar några av egenskaperna hos andra lastbalanserande teknologier som ProxySQL, sticker den här nya failover-funktionen (som är en del av dess övervaknings- och autodetektionsmekanism) ut. I den här bloggen kommer vi att diskutera denna spännande nya funktion hos Maxscale.
Översikt över MariaDB MaxScale Failover Mechanism
Master Detection
Det är nu mindre sannolikt att monitorn plötsligt byter masterserver, även om en annan server har fler slavar än den nuvarande mastern. DBA:n kan tvinga fram ett omval av master genom att ställa in den nuvarande mastern som skrivskyddad, eller genom att ta bort alla dess slavar om mastern är nere.
Endast en server kan ha huvudstatusflaggan åt gången, även i en multimaster-inställning. Andra servrar i multimastergruppen får statusflaggor för Relay Master och Slave.
Switchover New Master Autoselection
Switchover-kommandot kan nu anropas med bara monitorinstansens namn som parameter. I detta fall kommer monitorn automatiskt att välja en server för marknadsföring.
Replication Lag Detection
Replikeringsfördröjningsmätningen läser nu helt enkelt Seconds_Behind_Master -fält för slavstatusutgången för slavar. Slaven beräknar detta värde genom att jämföra tidsstämpeln i binlog-händelsen som slaven för närvarande bearbetar med slavens egen klocka. Om en slav har flera slavanslutningar används den minsta fördröjningen.
Automatisk övergång efter upptäckt av litet diskutrymme
Med de senaste MariaDB Server-versionerna kan monitorn nu kontrollera diskutrymmet på backend och upptäcka om servern håller på att ta slut. När detta händer kan monitorn ställas in för att automatiskt byta från en master med lågt diskutrymme. Slavar kan också ställas in i underhållsläge. Diskutrymmet är också en faktor som beaktas när man väljer vilken ny master som ska marknadsföras.
Se switchover_on_low_disk_space och maintenance_on_low_disk_space för mer information.
Replication Reset Feature
reset-replikeringen monitorkommandot tar bort alla slavanslutningar och binära loggar och ställer sedan in replikering. Användbart när data är synkroniserade men inte gtid.
Hantering av schemalagda händelser i failover/switchover/rejoin
Serverhändelser som startas av händelseschemaläggningstråden hanteras nu under klustermodifieringsoperationer. Se handle_server_events för mer information.
Extern mastersupport
Monitorn kan upptäcka om en server i klustret replikerar från en extern master (en server som inte övervakas av MaxScale-monitorn). Om den replikerande servern är klusterhuvudservern, anses själva klustret ha en extern master.
Om en failover/växling inträffar är den nya huvudservern inställd på att replikera från klustrets externa huvudserver. Användarnamnet och lösenordet för replikeringen definieras i replikeringsanvändare och replikeringslösenord. Adressen och porten som används är de som visas av VISA ALLA SLAVARSTATUS på den gamla klustermasterservern. I fallet med omställning slutar även den gamla mastern att replikera från den externa servern för att bevara topologin.
Efter failover replikerar den nya mastern från den externa mastern. Om den misslyckade gamla mastern kommer tillbaka online replikeras den också från den externa servern. För att normalisera situationen, antingen ha auto_rejoin på eller manuellt exekvera en rejoin. Detta kommer att omdirigera den gamla mastern till den nuvarande klustermastern.
Hur failover är användbart och tillämpligt?
Failover hjälper dig att minimera stillestånd, utföra dagligt underhåll eller hantera katastrofalt och oönskat underhåll som ibland kan inträffa vid olyckliga tillfällen. Med MaxScales förmåga att isolera klientapplikationer från backend-databasservrar, lägger den till värdefull funktionalitet som hjälper till att minimera driftstopp.
MaxScale övervakningsplugin övervakar kontinuerligt tillståndet för backend-databasservrarna. MaxScales routingplugin använder sedan denna statusinformation för att alltid dirigera frågor till backend-databasservrar som är i drift. Den kan sedan skicka frågor till backend-databasklustren, även om några av servrarna i ett kluster går igenom underhåll eller upplever fel.
MaxScales höga konfigurerbarhet gör att ändringar i klusterkonfigurationen förblir transparenta för klientapplikationer. Till exempel, om en ny server måste läggas till administrativt till eller tas bort från ett master-slave-kluster, kan du helt enkelt lägga till MaxScale-konfigurationen till serverlistan över monitor- och routerplugins via maxadmin CLI-konsolen. Klientapplikationen kommer att vara helt omedveten om denna förändring och kommer att fortsätta att skicka databasfrågor till MaxScales lyssningsport.
Att ställa in en databasserver i underhåll är enkelt och enkelt. Gör bara följande kommando med maxctrl och MaxScale kommer att sluta skicka några frågor till denna server. Till exempel,
maxctrl: set server DB_785 maintenance
OKKontrollera sedan servrarnas status enligt följande,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬──────────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-70 │
├────────┼───────────────┼──────┼─────────────┼──────────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Maintenance, Running │ 0-43001-70 │
└────────┴───────────────┴──────┴─────────────┴──────────────────────┴────────────┘Väl i underhållsläge kommer MaxScale att sluta dirigera nya förfrågningar till servern. För aktuella förfrågningar, kommer MaxScale inte att döda dessa sessioner, utan snarare tillåta den att slutföra sin exekvering och kommer inte att avbryta några pågående frågor i underhållsläge. Observera också att underhållsläget inte är beständigt. Om MaxScale startar om när en nod är i underhållsläge, kommer en ny instans av MariaDB MaxScale inte att uppfylla detta läge. Om flera MariaDB MaxScale-instanser är konfigurerade för att använda noden måste underhållsläget ställas in inom varje MariaDB MaxScale-instans. Men om flera tjänster inom en MariaDB MaxScale-instans använder servern behöver du bara ställa in underhållsläget en gång på servern för att alla tjänster ska kunna notera lägesändringen.
När du är klar med ditt underhåll, rensa bara servern med följande kommando. Till exempel,
maxctrl: clear server DB_785 maintenance
OKKontrollera om det är återställt till normalt, kör bara kommandot lista servrar .
Du kan också tillämpa vissa administrativa åtgärder genom ClusterControl UI också. Se exemplet på skärmdumpen nedan:
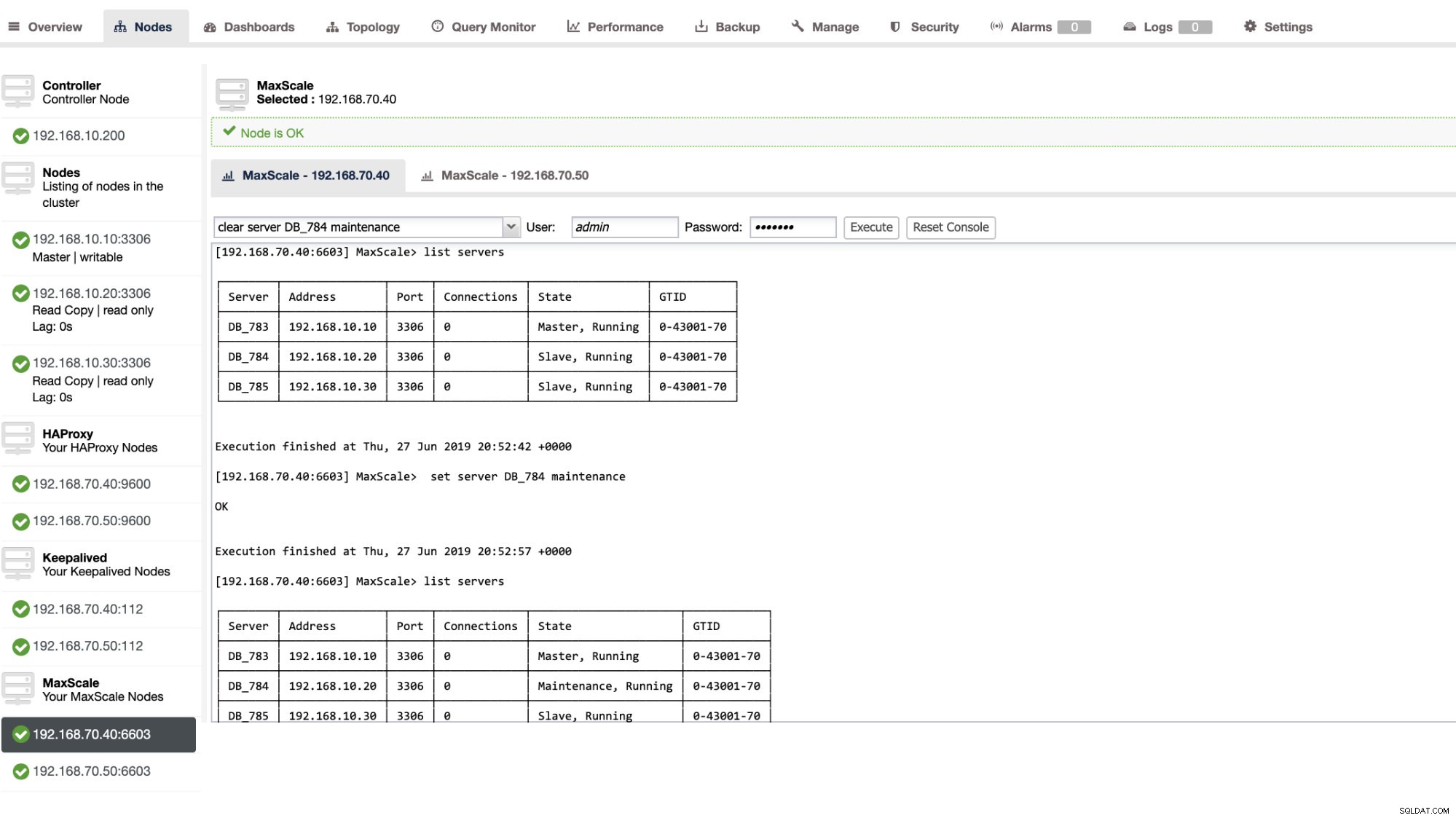
MaxScale Failover i aktion
Den automatiska failover
MariaDB:s MaxScale-failover fungerar mycket effektivt och konfigurerar om slaven enligt förväntan. I det här testet har vi följande konfigurationsfiluppsättning som skapades och hanterades av ClusterControl. Se nedan:
[replication_monitor]
type=monitor
servers=DB_783,DB_784,DB_785
disk_space_check_interval=1000
disk_space_threshold=/:85
detect_replication_lag=true
enforce_read_only_slaves=true
failcount=3
auto_failover=1
auto_rejoin=true
monitor_interval=300
password=725DE70F196694B277117DC825994D44
user=maxscalecc
replication_password=5349E1268CC4AF42B919A42C8E52D185
replication_user=rpl_user
module=mariadbmonObservera att endast auto_failover och auto_rejoin är variablerna som jag har lagt till eftersom ClusterControl inte kommer att lägga till detta som standard när du väl har ställt in en MaxScale load balancer (kolla in den här bloggen om hur du ställer in MaxScale med ClusterControl). Glöm inte att du måste starta om MariaDB MaxScale när du har tillämpat ändringarna i din konfigurationsfil. Kör bara,
systemctl restart maxscaleoch du är klar.
Innan vi fortsätter med failover-testet, låt oss först kontrollera klustrets hälsa:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ser bra ut!
Jag dödade mastern med bara det rena killer-kommandot KILL -9 $(pidof mysqld) i min masternod och ser, till ingen överraskning, monitorn har varit snabb att märka detta och utlöser failover. Se loggarna enligt följande:
2019-06-28 06:39:14.306 error : (mon_log_connect_error): Monitor was unable to connect to server DB_783[192.168.10.10:3306] : 'Can't connect to MySQL server on '192.168.10.10' (115)'
2019-06-28 06:39:14.329 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: master_down. [Master, Running] -> [Down]
2019-06-28 06:39:14.329 warning: (handle_auto_failover): Master has failed. If master status does not change in 2 monitor passes, failover begins.
2019-06-28 06:39:15.011 notice : (select_promotion_target): Selecting a server to promote and replace 'DB_783'. Candidates are: 'DB_784', 'DB_785'.
2019-06-28 06:39:15.011 warning: (warn_replication_settings): Slave 'DB_784' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 warning: (warn_replication_settings): Slave 'DB_785' has gtid_strict_mode disabled. Enabling this setting is recommended. For more information, see https://mariadb.com/kb/en/library/gtid/#gtid_strict_mode
2019-06-28 06:39:15.012 notice : (select_promotion_target): Selected 'DB_784'.
2019-06-28 06:39:15.012 notice : (handle_auto_failover): Performing automatic failover to replace failed master 'DB_783'.
2019-06-28 06:39:15.017 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_784' instead of 'DB_783'.
2019-06-28 06:39:15.024 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 06:39:15.527 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_784'.
2019-06-28 06:39:15.527 notice : (handle_auto_failover): Failover 'DB_783' -> 'DB_784' performed.
2019-06-28 06:39:15.634 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 06:39:20.165 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: slave_up. [Down] -> [Slave, Running]Låt oss nu ta en titt på dess klusters hälsa,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Down │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Noden 192.168.10.10 som tidigare var master har varit nere. Jag försökte starta om och se om auto-rejoin skulle utlösas, och som du märkte i loggen vid tidpunkten 2019-06-28 06:39:20.165, det har gått så snabbt att fånga nodens tillstånd och sedan konfigurera konfigurationen automatiskt utan krångel för DBA att slå på den.
Nu, när vi slutligen kollar på dess tillstånd, ser det ut att fungera perfekt som förväntat. Se nedan:
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Min ex-Master har blivit fixad och återställd och jag vill byta över
Att byta till din tidigare master är inte heller något krångel. Du kan använda detta med maxctrl (eller maxadmin i tidigare versioner av MaxScale) eller genom ClusterControl UI (som tidigare visat).
Låt oss bara hänvisa till det tidigare tillståndet för replikeringsklustrets hälsa tidigare, och ville byta tillbaka 192.168.10.10 (för närvarande slav) till dess huvudtillstånd. Innan vi fortsätter kan du behöva identifiera först vilken bildskärm du ska använda. Du kan verifiera detta med följande kommando nedan:
maxctrl: list monitors
┌─────────────────────┬─────────┬────────────────────────┐
│ Monitor │ State │ Servers │
├─────────────────────┼─────────┼────────────────────────┤
│ replication_monitor │ Running │ DB_783, DB_784, DB_785 │
└─────────────────────┴─────────┴────────────────────────┘När du har det kan du göra följande kommando nedan för att växla över:
maxctrl: call command mariadbmon switchover replication_monitor DB_783 DB_784
OKKontrollera sedan igen tillståndet för klustret,
maxctrl: list servers
┌────────┬───────────────┬──────┬─────────────┬─────────────────┬────────────┐
│ Server │ Address │ Port │ Connections │ State │ GTID │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_783 │ 192.168.10.10 │ 3306 │ 0 │ Master, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_784 │ 192.168.10.20 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
├────────┼───────────────┼──────┼─────────────┼─────────────────┼────────────┤
│ DB_785 │ 192.168.10.30 │ 3306 │ 0 │ Slave, Running │ 0-43001-75 │
└────────┴───────────────┴──────┴─────────────┴─────────────────┴────────────┘Ser perfekt ut!
Loggar kommer detaljerat att visa dig hur det gick och dess serie av åtgärder under övergången. Se detaljerna nedan:
2019-06-28 07:03:48.064 error : (switchover_prepare): 'DB_784' is not a valid promotion target for switchover because it is already the master.
2019-06-28 07:03:48.064 error : (manual_switchover): Switchover cancelled.
2019-06-28 07:04:30.700 notice : (create_start_slave): Slave connection from DB_784 to [192.168.10.10]:3306 created and started.
2019-06-28 07:04:30.700 notice : (redirect_slaves_ex): Redirecting 'DB_785' to replicate from 'DB_783' instead of 'DB_784'.
2019-06-28 07:04:30.708 notice : (redirect_slaves_ex): All redirects successful.
2019-06-28 07:04:31.209 notice : (wait_cluster_stabilization): All redirected slaves successfully started replication from 'DB_783'.
2019-06-28 07:04:31.209 notice : (manual_switchover): Switchover 'DB_784' -> 'DB_783' performed.
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_783[192.168.10.10:3306]: new_master. [Slave, Running] -> [Master, Running]
2019-06-28 07:04:31.318 notice : (mon_log_state_change): Server changed state: DB_784[192.168.10.20:3306]: new_slave. [Master, Running] -> [Slave, Running]I fallet med en felaktig övergång kommer den inte att fortsätta och därför genererar den ett fel som visas i loggen ovan. Så du kommer att vara säker och inga läskiga överraskningar alls.
Göra din MaxScale mycket tillgänglig
Även om det är lite off-topic när det gäller failover, ville jag lägga till några värdefulla punkter här med avseende på hög tillgänglighet och hur det relaterade till MariaDB MaxScale failover.
Att göra din MaxScale mycket tillgänglig är en viktig del i händelse av att ditt system kraschar, upplever diskkorruption eller virtuell maskinkorruption. Dessa situationer är oundvikliga och kan påverka tillståndet för din automatiska failover-konfiguration när dessa oväntade underhållscykler inträffar.
För en miljö av replikeringskluster är detta mycket fördelaktigt och rekommenderas starkt för en specifik MaxScale-installation. Syftet med detta är att endast en MaxScale-instans ska tillåtas att modifiera klustret vid varje given tidpunkt. Om du har konfigurerat med Keepalved är det här instanserna med statusen MASTER. MaxScale själv känner inte till dess tillstånd, men med maxctrl (eller maxadmin i tidigare versioner) kan ställa in en MaxScale-instans till passivt läge. Från och med version 2.2.2, beter sig en passiv MaxScale på samma sätt som en aktiv med skillnaden att den inte kommer att utföra failover, switchover eller rejoin. Även manuella versioner av dessa kommandon kommer att sluta med misstag. Skillnaderna i passivt/aktivt läge kan komma att utökas i framtiden, så håll utkik efter sådana förändringar i MaxScale. För att göra detta, gör bara följande:
maxctrl: alter maxscale passive true
OKDu kan verifiera detta i efterhand genom att köra kommandot nedan:
[example@sqldat.com vagrant]# maxctrl -u admin -p mariadb -h 127.0.0.1:8989 show maxscale|grep 'passive'
│ │ "passive": true, │Om du vill kolla in hur du ställer in högt tillgängligt med Keepalived, vänligen kolla det här inlägget från MariaDB.
VIP-hantering
Dessutom, eftersom MaxScale inte har VIP-hantering inbyggd, kan du använda Keepalved för att hantera det åt dig. Du kan bara använda den virtuella_ipadress som är tilldelad MASTER-tillståndsnoden. Detta kommer sannolikt att komma med virtuell IP-hantering precis som MHA gör med variabeln master_failover_script. Som nämnts tidigare, kolla in detta Keepalived with MaxScale setup blogginlägg av MariaDB.
Slutsats
MariaDB MaxScale är funktionsrik och har massor av möjligheter, inte bara begränsad till att vara en proxy och lastbalanserare, utan den erbjuder också failover-mekanismen som stora organisationer letar efter. Det är nästan en mjukvara som passar alla, men kommer naturligtvis med begränsningar som en viss applikation kan behöva för att till skillnad från andra lastbalanserare som ProxySQL.
ClusterControl erbjuder också en auto-failover och en huvudmekanism för autodetektering, plus kluster- och nodåterställning med möjligheten att distribuera Maxscale och andra lastbalanseringstekniker.
Vart och ett av dessa verktyg har sina olika funktioner och funktioner, men MariaDB MaxScale stöds väl inom ClusterControl och kan implementeras med hjälp av Keepalved, HAProxy för att hjälpa dig att påskynda din dagliga rutinuppgift.