Galera Cluster, med sin (nästan) synkrona replikering, används ofta i många olika typer av miljöer. Det är inte svårt att skala den genom att lägga till nya noder (eller lika enkelt ett par klick när du använder ClusterControl).
Det största problemet med synkron replikering är, ja, den synkrona delen som ofta resulterar i att hela klustret bara är lika snabbt som dess långsammaste nod. Alla skrivningar som exekveras på ett kluster måste replikeras till alla noder och certifieras på dem. Om, av någon anledning, denna process saktar ner, kan det allvarligt påverka klustrets förmåga att ta emot skrivningar. Flödeskontroll kommer då att slå in, detta för att säkerställa att den långsammaste noden fortfarande kan hålla jämna steg med belastningen. Detta gör det ganska svårt för några av de vanliga scenarierna som händer i en verklig miljö.
Först och främst, låt oss diskutera geografiskt distribuerad katastrofåterställning. Visst, du kan köra kluster över ett Wide Area Network, men den ökade latensen kommer att ha en betydande inverkan på klustrets prestanda. Detta begränsar allvarligt möjligheten att använda en sådan installation, särskilt över längre avstånd när latensen är högre.
Ett annat ganska vanligt användningsfall - en testmiljö för större versionsuppgradering. Det är ingen bra idé att blanda olika versioner av MariaDB Galera Cluster-noder i samma kluster, även om det är möjligt. Å andra sidan kräver migrering till den nyare versionen detaljerade tester. Helst skulle både läsning och skrivning ha testats. Ett sätt att uppnå det är att skapa ett separat Galera-kluster och köra testerna, men du skulle vilja köra tester i en miljö så nära produktionen som möjligt. När det väl har tillhandahållits kan ett kluster användas för tester med verkliga frågor, men det skulle vara svårt att generera en arbetsbelastning som skulle ligga nära produktionens. Du kan inte flytta en del av produktionstrafiken till ett sådant testsystem, detta beror på att data inte är aktuella.
Slutligen, själva migrationen. Återigen, vad vi sa tidigare, även om det är möjligt att blanda gamla och nya versioner av Galera-noder i samma kluster, är det inte det säkraste sättet att göra det.
Lyckligtvis skulle den enklaste lösningen för alla dessa tre problem vara att ansluta separata Galera-kluster med en asynkron replikering. Vad gör det till en så bra lösning? Tja, det är asynkront vilket gör att det inte påverkar Galera-replikeringen. Det finns ingen flödeskontroll, så prestandan för "master"-klustret kommer inte att påverkas av prestandan för "slav"-klustret. Som med varje asynkron replikering kan en fördröjning dyka upp, men så länge den håller sig inom acceptabla gränser kan den fungera alldeles utmärkt. Du måste också komma ihåg att nuförtiden kan asynkron replikering parallelliseras (flera trådar kan arbeta tillsammans för att öka bandbredden) och minska replikeringsfördröjningen ytterligare.
I det här blogginlägget kommer vi att diskutera vad som är stegen för att distribuera asynkron replikering mellan MariaDB Galera-kluster.
Hur konfigurerar man asynkron replikering mellan MariaDB Galera-kluster?
Först måste vi distribuera ett kluster. För våra syften konfigurerar vi ett kluster med tre noder. Vi kommer att hålla inställningen till ett minimum, så vi kommer inte att diskutera komplexiteten i applikationen och proxylagret. Proxylager kan vara mycket användbart för att hantera uppgifter för vilka du vill distribuera asynkron replikering - omdirigera en delmängd av den skrivskyddade trafiken till testklustret, vilket hjälper till i katastrofåterställningssituationen när "huvud"-klustret inte är tillgängligt genom att omdirigera trafik till DR-klustret. Det finns många proxyservrar du kan prova, beroende på vad du föredrar - HAProxy, MaxScale eller ProxySQL - alla kan användas i sådana inställningar och, beroende på fallet, kan vissa av dem hjälpa dig att hantera din trafik.
Konfigurera källklustret
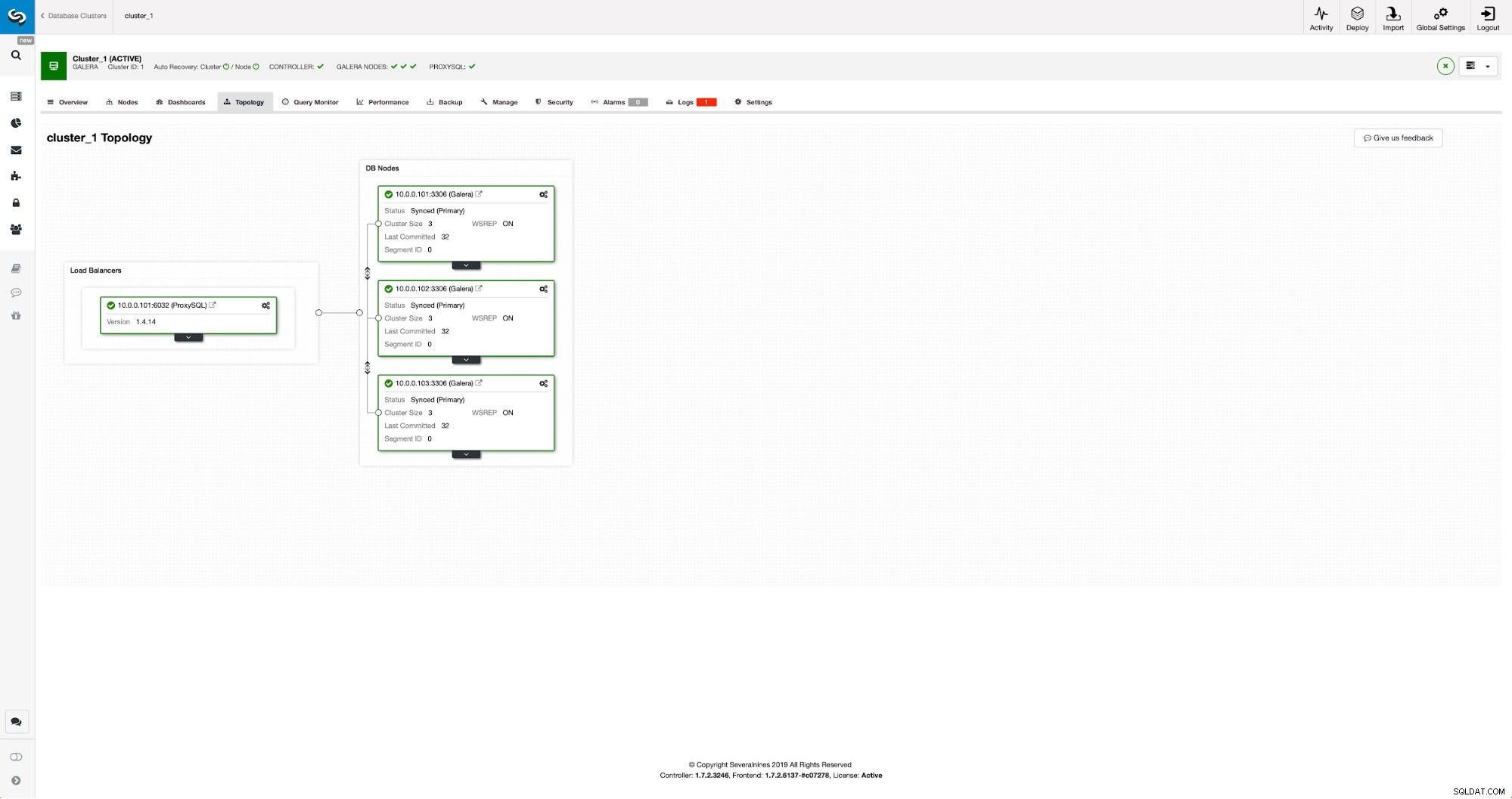
Vårt kluster består av tre MariaDB 10.3-noder, vi distribuerade även ProxySQL för att göra läs-skriv-delningen och distribuera trafiken över alla noder i klustret. Det här är inte en distribution i produktionsklass, för det skulle vi behöva distribuera fler ProxySQL-noder och en Keepalived ovanpå dem. Det räcker fortfarande för våra syften. För att ställa in asynkron replikering måste vi ha en binär logg aktiverad på vårt kluster. Åtminstone en nod men det är bättre att hålla den aktiverad på dem alla ifall den enda noden med binlog aktiverad går ner - då vill du ha en annan nod i klustret igång som du kan slavav.
När du aktiverar binär logg, se till att du konfigurerar den binära loggrotationen så att de gamla loggarna tas bort någon gång. Du kommer att använda ROW binärt loggformat. Du bör också se till att du har GTID konfigurerat och används - det kommer att vara väldigt praktiskt när du skulle behöva omslava ditt "slav"-kluster eller om du skulle behöva aktivera flertrådsreplikering. Eftersom detta är ett Galera-kluster vill du ha 'wsrep_gtid_domain_id' konfigurerat och 'wsrep_gtid_mode' aktiverat. Dessa inställningar kommer att säkerställa att GTID:n kommer att genereras för trafiken som kommer från Galera-klustret. Mer information finns i dokumentationen. När allt är klart kan du fortsätta med att ställa in det andra klustret.
Konfigurera målklustret
Med tanke på att det för närvarande inte finns något målkluster måste vi börja med att distribuera det. Vi kommer inte att täcka dessa steg i detalj, du kan hitta instruktioner i dokumentationen. Generellt sett består processen av flera steg:
- Konfigurera MariaDB-förråd
- Installera MariaDB 10.3-paket
- Konfigurera noder för att bilda ett kluster
I början börjar vi med bara en nod. Du kan ställa in dem alla för att bilda ett kluster men sedan bör du stoppa dem och använda bara en för nästa steg. Den ena noden kommer att bli en slav till det ursprungliga klustret. Vi kommer att använda mariabackup för att tillhandahålla det. Sedan konfigurerar vi replikeringen.
Först måste vi skapa en katalog där vi lagrar säkerhetskopian:
mkdir /mnt/mariabackupSedan kör vi säkerhetskopian och skapar den i katalogen som förbereddes i steget ovan. Se till att du använder rätt användare och lösenord för att ansluta till databasen:
mariabackup --backup --user=root --password=pass --target-dir=/mnt/mariabackup/Därefter måste vi kopiera säkerhetskopiorna till den första noden i det andra klustret. Vi använde scp för det, du kan använda vad du vill - rsync, netcat, allt som fungerar.
scp -r /mnt/mariabackup/* 10.0.0.104:/root/mariabackup/Efter att säkerhetskopian har kopierats måste vi förbereda den genom att använda loggfilerna:
mariabackup --prepare --target-dir=/root/mariabackup/
mariabackup based on MariaDB server 10.3.16-MariaDB debian-linux-gnu (x86_64)
[00] 2019-06-24 08:35:39 cd to /root/mariabackup/
[00] 2019-06-24 08:35:39 This target seems to be not prepared yet.
[00] 2019-06-24 08:35:39 mariabackup: using the following InnoDB configuration for recovery:
[00] 2019-06-24 08:35:39 innodb_data_home_dir = .
[00] 2019-06-24 08:35:39 innodb_data_file_path = ibdata1:100M:autoextend
[00] 2019-06-24 08:35:39 innodb_log_group_home_dir = .
[00] 2019-06-24 08:35:39 InnoDB: Using Linux native AIO
[00] 2019-06-24 08:35:39 Starting InnoDB instance for recovery.
[00] 2019-06-24 08:35:39 mariabackup: Using 104857600 bytes for buffer pool (set by --use-memory parameter)
2019-06-24 8:35:39 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
2019-06-24 8:35:39 0 [Note] InnoDB: Uses event mutexes
2019-06-24 8:35:39 0 [Note] InnoDB: Compressed tables use zlib 1.2.8
2019-06-24 8:35:39 0 [Note] InnoDB: Number of pools: 1
2019-06-24 8:35:39 0 [Note] InnoDB: Using SSE2 crc32 instructions
2019-06-24 8:35:39 0 [Note] InnoDB: Initializing buffer pool, total size = 100M, instances = 1, chunk size = 100M
2019-06-24 8:35:39 0 [Note] InnoDB: Completed initialization of buffer pool
2019-06-24 8:35:39 0 [Note] InnoDB: page_cleaner coordinator priority: -20
2019-06-24 8:35:39 0 [Note] InnoDB: Starting crash recovery from checkpoint LSN=3448619491
2019-06-24 8:35:40 0 [Note] InnoDB: Starting final batch to recover 759 pages from redo log.
2019-06-24 8:35:40 0 [Note] InnoDB: Last binlog file '/var/lib/mysql-binlog/binlog.000003', position 865364970
[00] 2019-06-24 08:35:40 Last binlog file /var/lib/mysql-binlog/binlog.000003, position 865364970
[00] 2019-06-24 08:35:40 mariabackup: Recovered WSREP position: e79a3494-964f-11e9-8a5c-53809a3c5017:25740
[00] 2019-06-24 08:35:41 completed OK!Vid eventuella fel kan du behöva köra om säkerhetskopian. Om allt gick ok, kan vi ta bort den gamla datan och ersätta den med säkerhetskopieringsinformationen
rm -rf /var/lib/mysql/*
mariabackup --copy-back --target-dir=/root/mariabackup/
…
[01] 2019-06-24 08:37:06 Copying ./sbtest/sbtest10.frm to /var/lib/mysql/sbtest/sbtest10.frm
[01] 2019-06-24 08:37:06 ...done
[00] 2019-06-24 08:37:06 completed OK!Vi vill också ställa in rätt ägare till filerna:
chown -R mysql.mysql /var/lib/mysql/Vi kommer att förlita oss på GTID för att hålla replikeringen konsekvent, så vi måste se vad som var det senast använda GTID i denna säkerhetskopia. Den informationen finns i filen xtrabackup_info som är en del av säkerhetskopian:
example@sqldat.com:~/mariabackup# cat /var/lib/mysql/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000003', position '865364970', GTID of the last change '9999-1002-23012'Vi måste också se till att slavnoden har binära loggar aktiverade tillsammans med 'log_slave_updates'. Helst kommer detta att vara aktiverat på alla noder i det andra klustret - ifall "slav"-noden misslyckades och du skulle behöva ställa in replikeringen med en annan nod i slavklustret.
Den sista biten vi behöver göra innan vi kan ställa in replikeringen är att skapa en användare som vi kommer att använda för att köra replikeringen:
MariaDB [(none)]> CREATE USER 'repuser'@'10.0.0.104' IDENTIFIED BY 'reppass';
Query OK, 0 rows affected (0.077 sec)MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO 'repuser'@'10.0.0.104';
Query OK, 0 rows affected (0.012 sec)Det är allt vi behöver. Nu kan vi starta den första noden i det andra klustret, vår to-be-slave:
galera_new_clusterNär den väl har startat kan vi gå in i MySQL CLI och konfigurera den för att bli en slav, med hjälp av GITD-positionen vi hittade några steg tidigare:
mysql -ppassMariaDB [(none)]> SET GLOBAL gtid_slave_pos = '9999-1002-23012';
Query OK, 0 rows affected (0.026 sec)När det är gjort kan vi äntligen ställa in replikeringen och starta den:
MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.016 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Vid det här laget har vi ett Galera-kluster som består av en nod. Den noden är också en slav av det ursprungliga klustret (i synnerhet dess master är nod 10.0.0.101). För att gå med i andra noder kommer vi att använda SST men för att få det att fungera först måste vi se till att SST-konfigurationen är korrekt - kom ihåg att vi just ersatt alla användare i vårt andra kluster med innehållet i källklustret. Vad du måste göra nu är att se till att 'wsrep_sst_auth'-konfigurationen för det andra klustret matchar den i det första klustret. När det är gjort kan du starta återstående noder en efter en och de ska gå med i den befintliga noden (10.0.0.104), hämta data över SST och bilda Galera-klustret. Så småningom bör du sluta med två kluster, tre noder vardera, med asynkron replikeringslänk över dem (från 10.0.0.101 till 10.0.0.104 i vårt exempel). Du kan bekräfta att replikeringen fungerar genom att kontrollera värdet på:
MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 106 |
+----------------------+-------+
1 row in set (0.001 sec)MariaDB [(none)]> show global status like 'wsrep_last_committed';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| wsrep_last_committed | 114 |
+----------------------+-------+
1 row in set (0.001 sec)Hur konfigurerar man asynkron replikering mellan MariaDB Galera-kluster med ClusterControl?
Vid tidpunkten för den här bloggen har ClusterControl inte funktionen för att konfigurera asynkron replikering över flera kluster, vi arbetar med det medan jag skriver detta. Icke desto mindre kan ClusterControl vara till stor hjälp i denna process - vi kommer att visa dig hur du kan påskynda de mödosamma manuella stegen med hjälp av automatisering som tillhandahålls av ClusterControl.
Av det vi visade tidigare kan vi dra slutsatsen att det är de allmänna stegen att ta när du ställer in replikering mellan två Galera-kluster:
- Distribuera ett nytt Galera-kluster
- Tillhandahålla nytt kluster med hjälp av data från det gamla
- Konfigurera nytt kluster (SST-konfiguration, binära loggar)
- Ställ in replikeringen mellan det gamla och det nya klustret
De tre första punkterna är något du enkelt kan göra med ClusterControl redan nu. Vi kommer att visa dig hur du gör det.
Distribuera och tillhandahålla ett nytt MariaDB Galera Cluster med ClusterControl
Utgångsläget är liknande - vi har ett kluster igång. Vi måste sätta upp den andra. En av de nyare funktionerna i ClusterControl är ett alternativ att distribuera ett nytt kluster och tillhandahålla det med hjälp av data från säkerhetskopieringen. Detta är mycket användbart för att skapa testmiljöer, det är också ett alternativ som vi kommer att använda för att tillhandahålla vårt nya kluster för replikeringsinställningarna. Därför är det första steget vi tar att skapa en säkerhetskopia med hjälp av mariabackup:
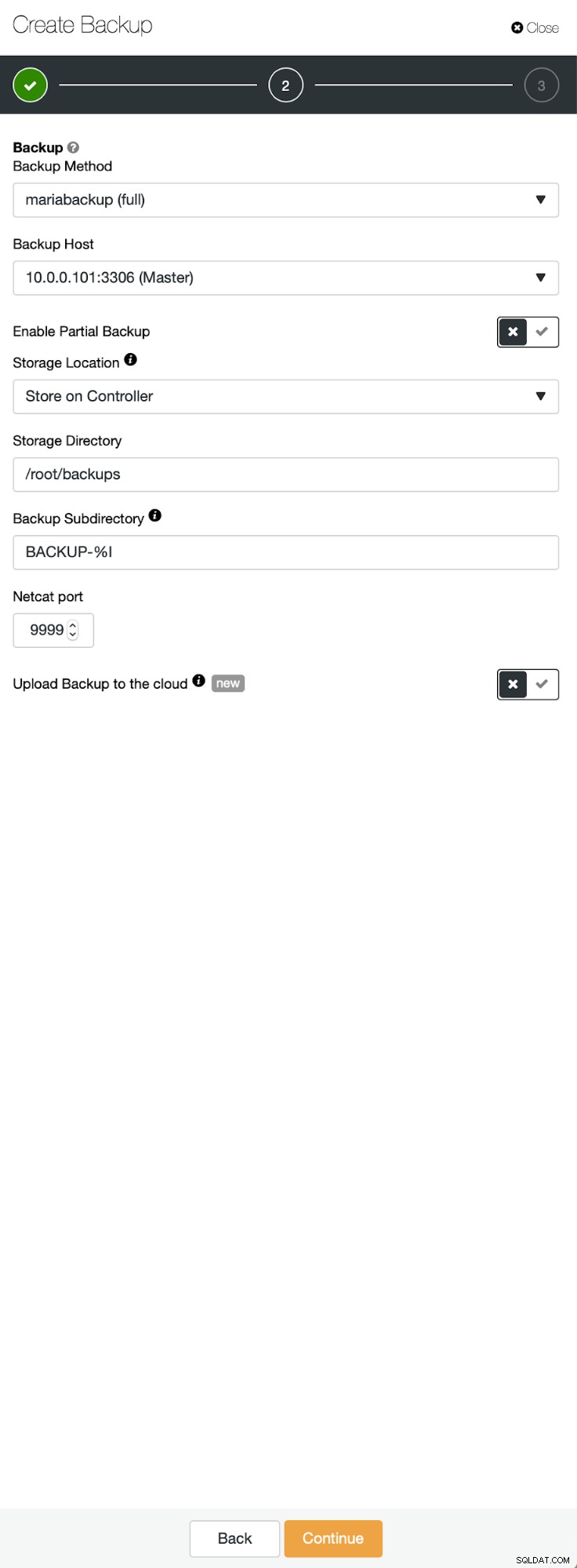
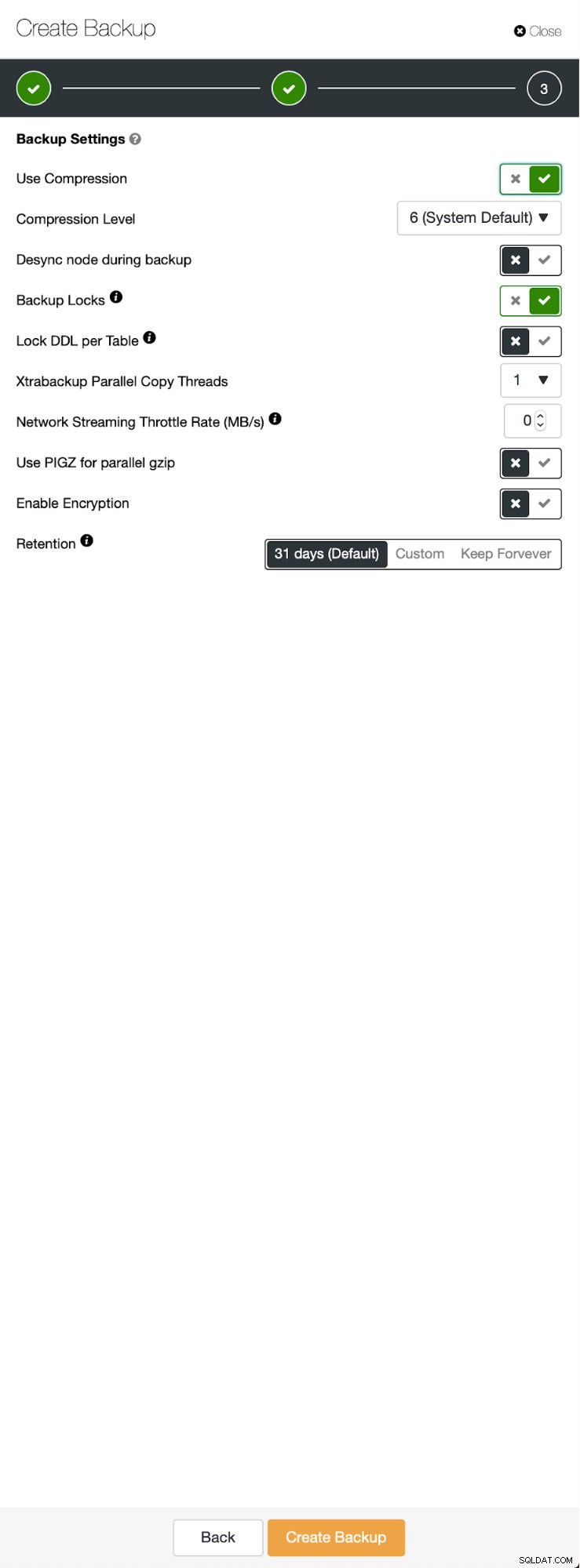
Tre steg där vi valde noden för att ta säkerhetskopian från den. Denna nod (10.0.0.101) kommer att bli en master. Den måste ha binära loggar aktiverade. I vårt fall har alla noder binlog aktiverat, men om de inte hade det är det väldigt lätt att aktivera det från ClusterControl - vi kommer att visa stegen senare, när vi gör det för det andra klustret.
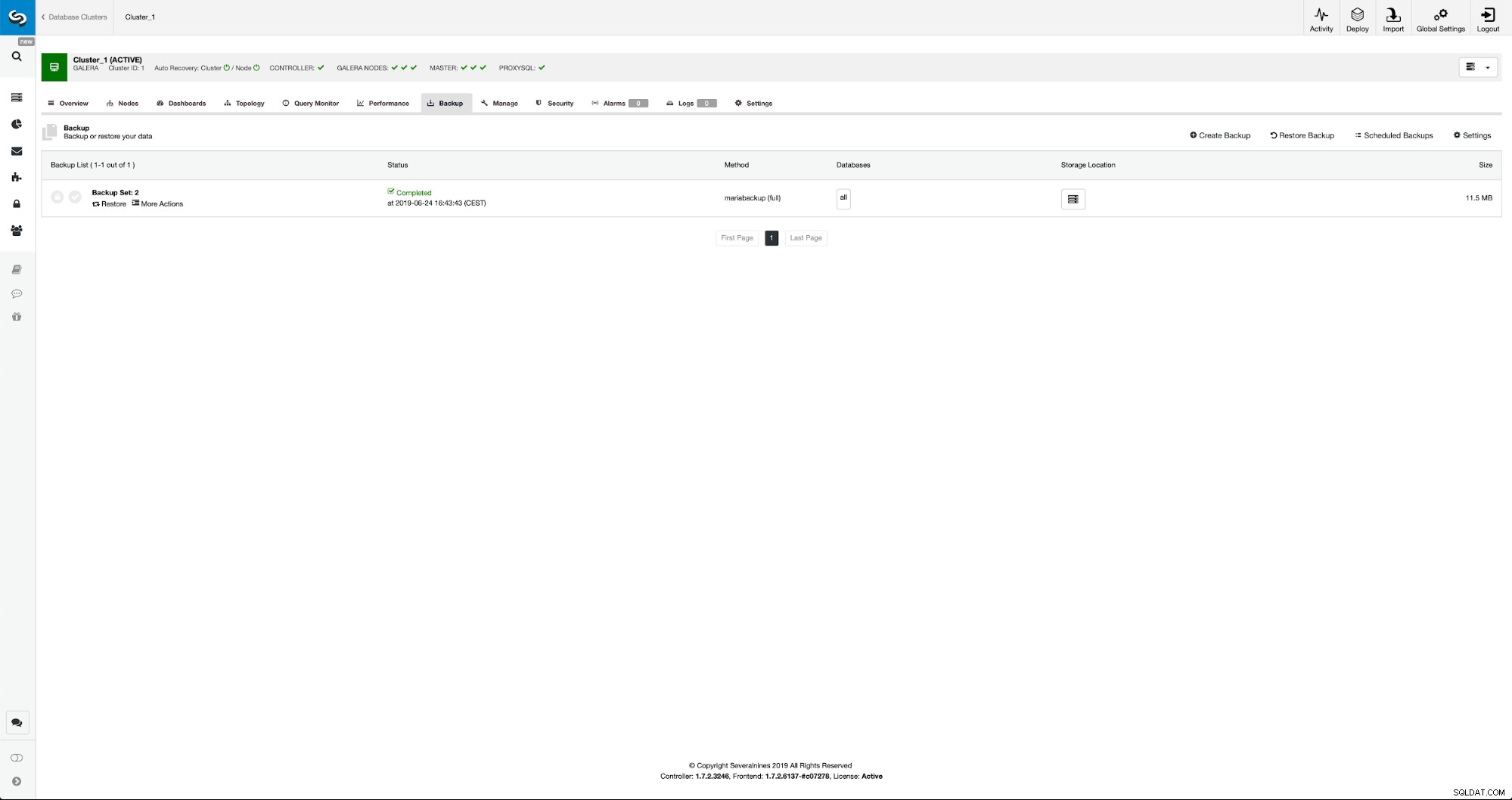
När säkerhetskopieringen är klar kommer den att synas på listan. Vi kan sedan fortsätta och återställa det:

Om vi skulle vilja det kan vi till och med göra Point-In-Time Recovery, men i vårt fall spelar det ingen roll:när replikeringen väl har konfigurerats kommer alla nödvändiga transaktioner från binlogs att tillämpas på det nya klustret.

Sedan väljer vi alternativet att skapa ett kluster från säkerhetskopian. Detta öppnar en annan dialogruta:
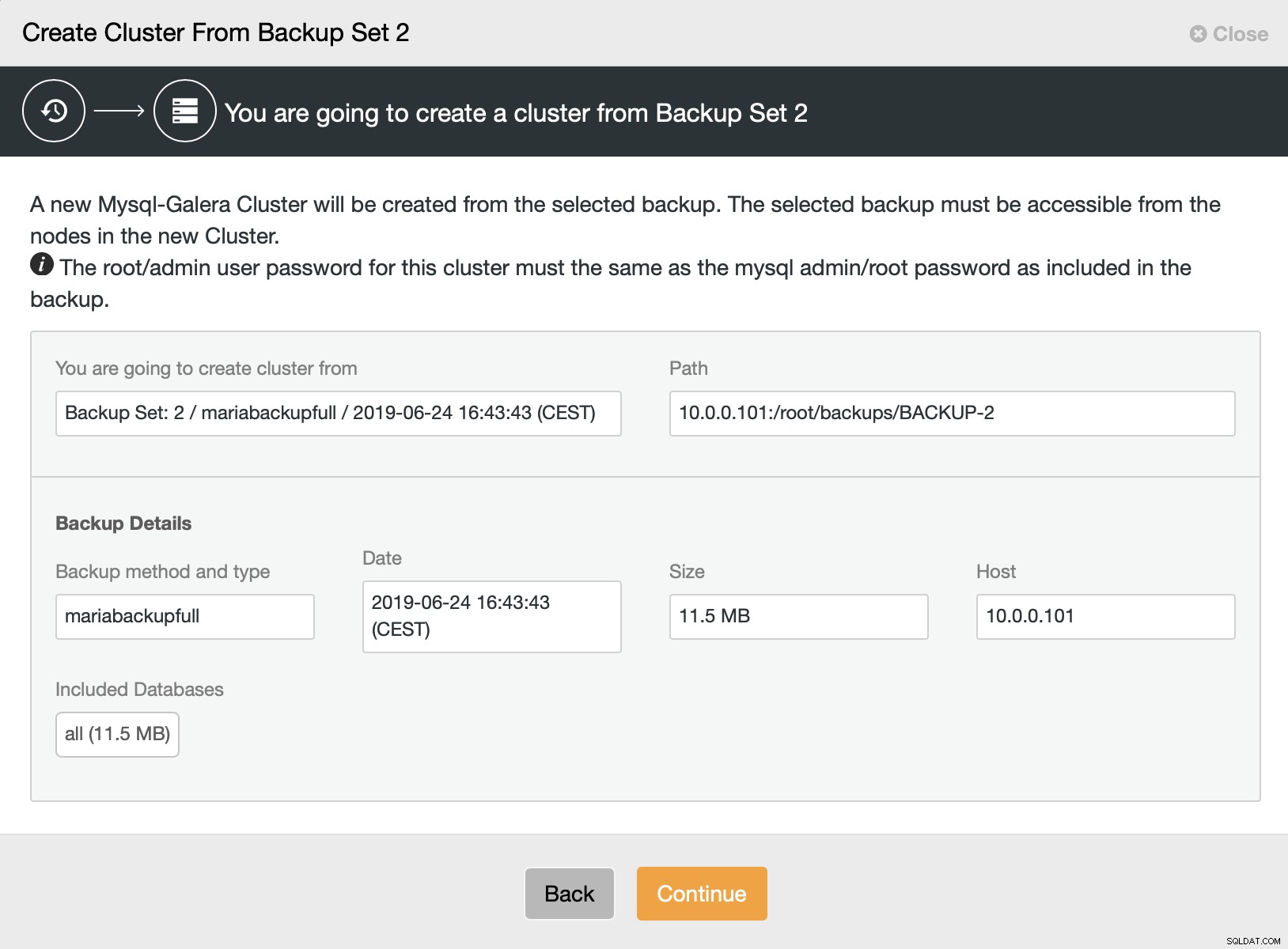
Det är en bekräftelse på vilken säkerhetskopia som kommer att användas, vilken värd säkerhetskopian togs från, vilken metod som användes för att skapa den och lite metadata för att verifiera om säkerhetskopian ser bra ut.
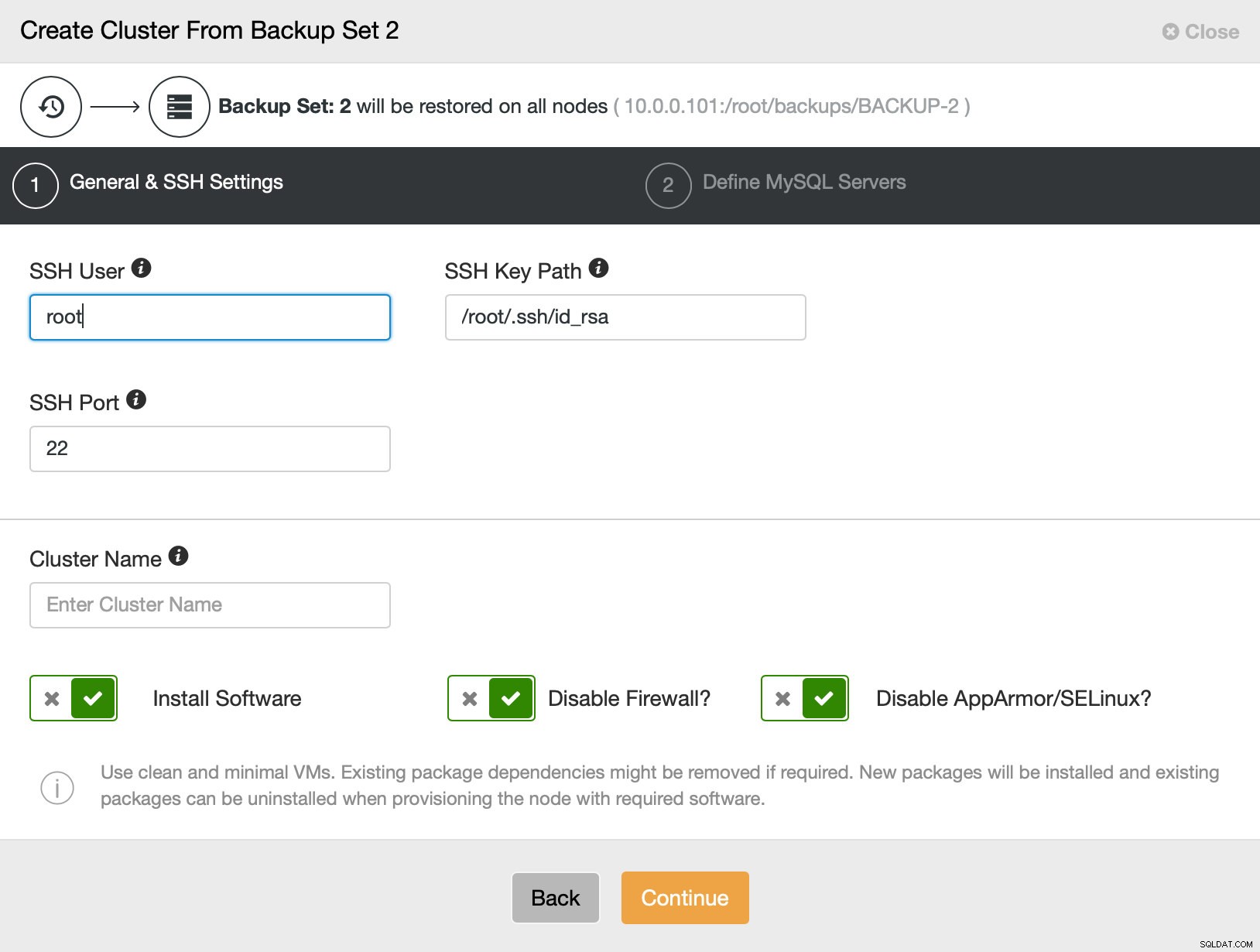
Sedan går vi i princip till den vanliga distributionsguiden där vi måste definiera SSH-anslutning mellan ClusterControl-värden och noderna att distribuera klustret på (kravet för ClusterControl) och, i det andra steget, leverantör, version, lösenord och noder att distribuera på:
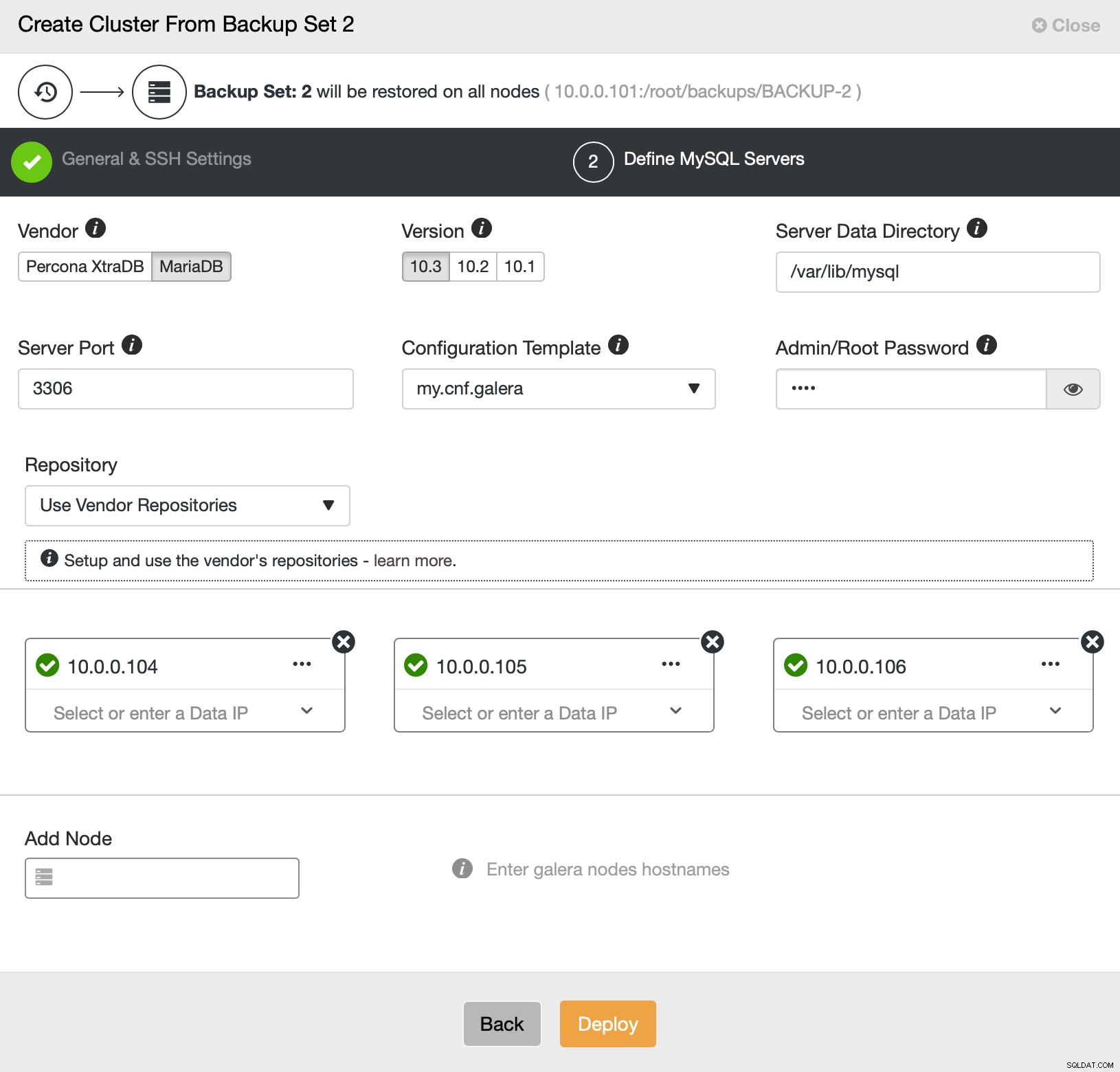
Det är allt när det gäller distribution och provisionering. ClusterControl kommer att konfigurera det nya klustret och det kommer att tillhandahålla det med hjälp av data från det gamla.
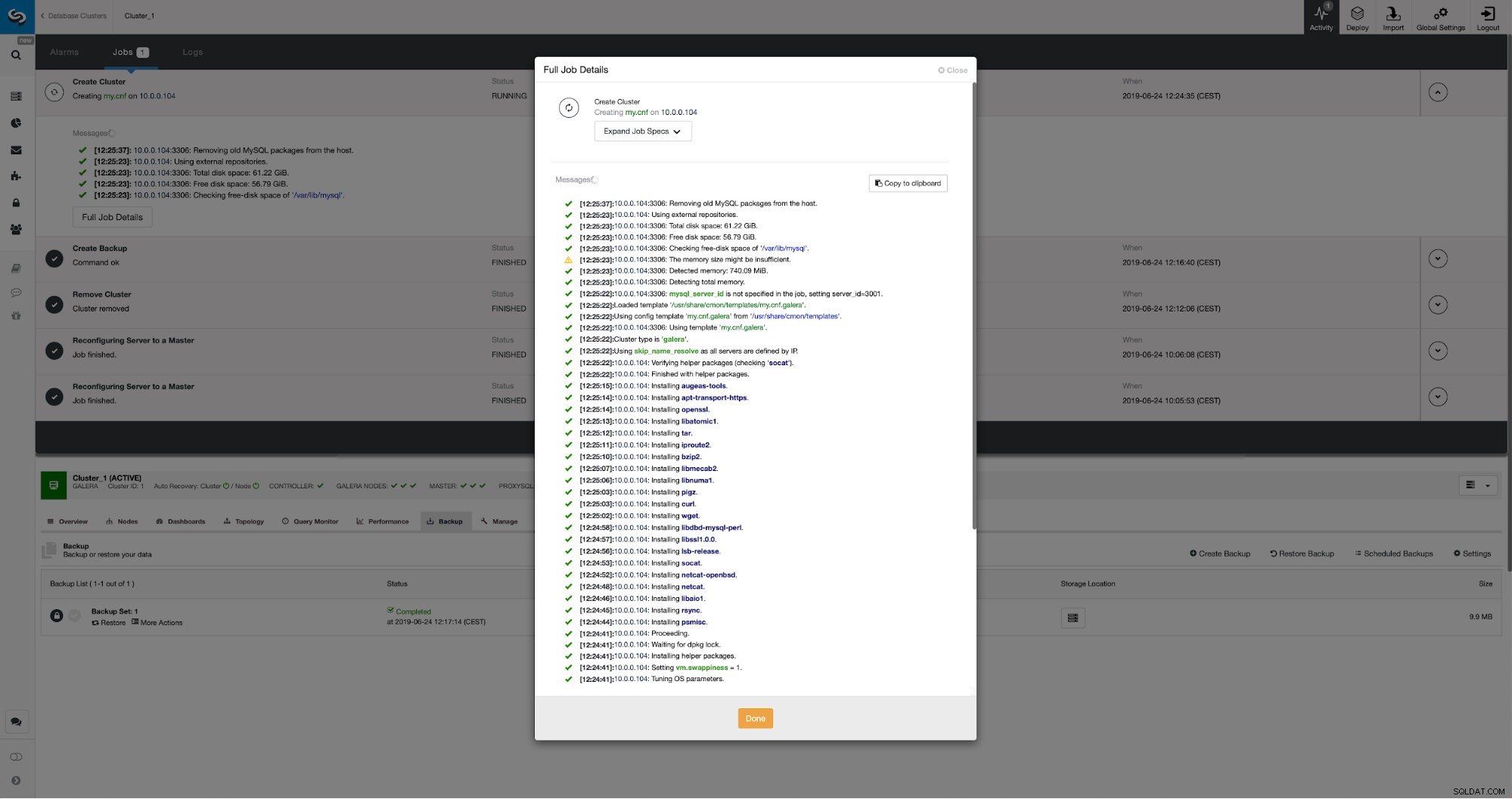
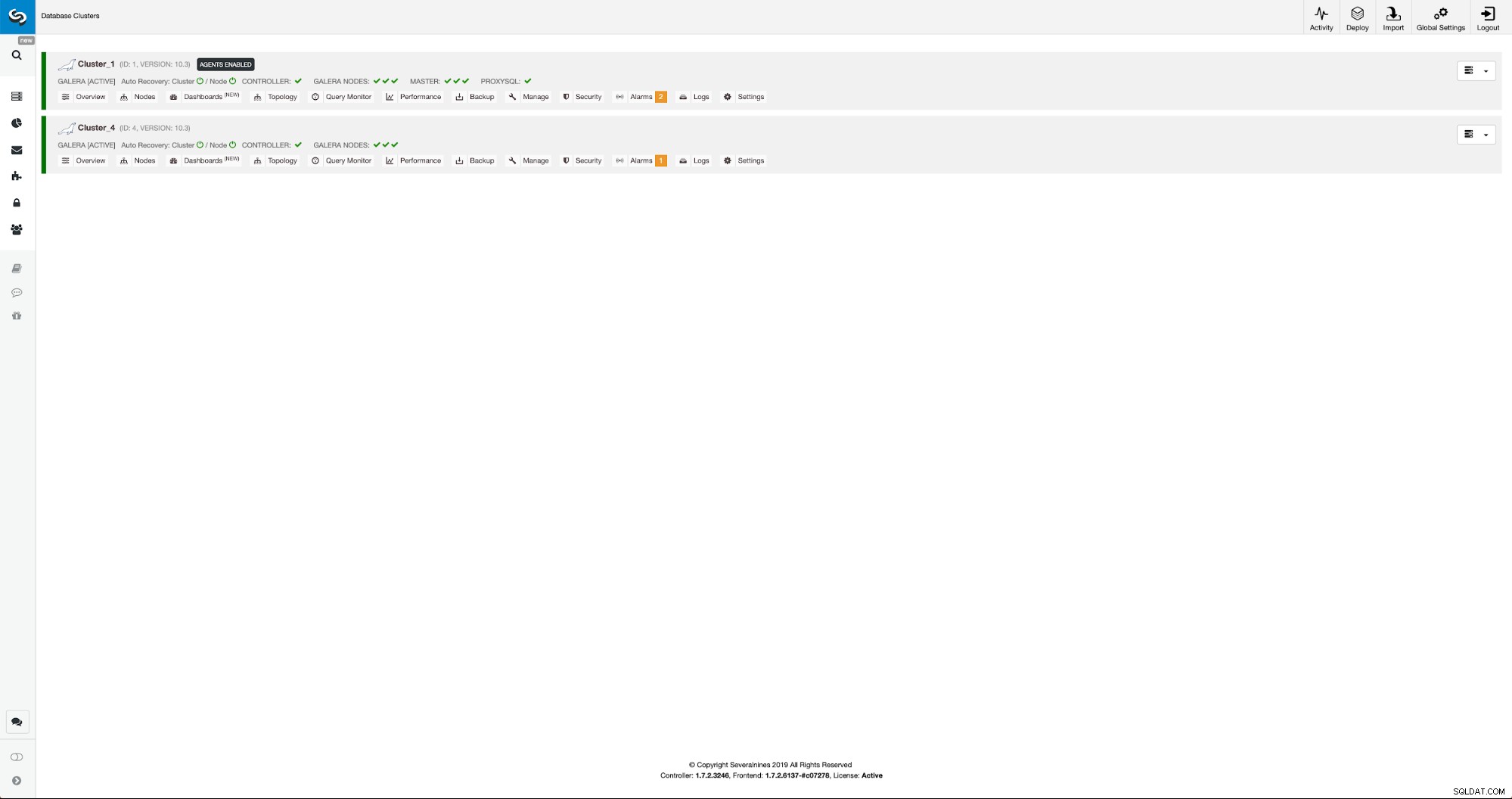
Vi kan följa utvecklingen på aktivitetsfliken. När det är klart kommer det andra klustret att dyka upp på klusterlistan i ClusterControl.
Omkonfigurering av det nya klustret med ClusterControl
Nu måste vi konfigurera om klustret - vi kommer att aktivera binära loggar. I den manuella processen var vi tvungna att göra ändringar i konfigurationen wsrep_sst_auth och även konfigurationsposter i sektionerna [mysqldump] och [xtrabackup] av konfigurationen. Dessa inställningar finns i filen secrets-backup.cnf. Den här gången behövs det inte eftersom ClusterControl genererade nya lösenord för klustret och konfigurerade filerna korrekt. Vad som är viktigt att komma ihåg är dock att om du skulle ändra lösenordet för 'backupuser'@'127.0.0.1'-användaren i det ursprungliga klustret, måste du göra konfigurationsändringar i det andra klustret också för att återspegla det som ändringar i det första klustret kommer att replikera till det andra klustret.
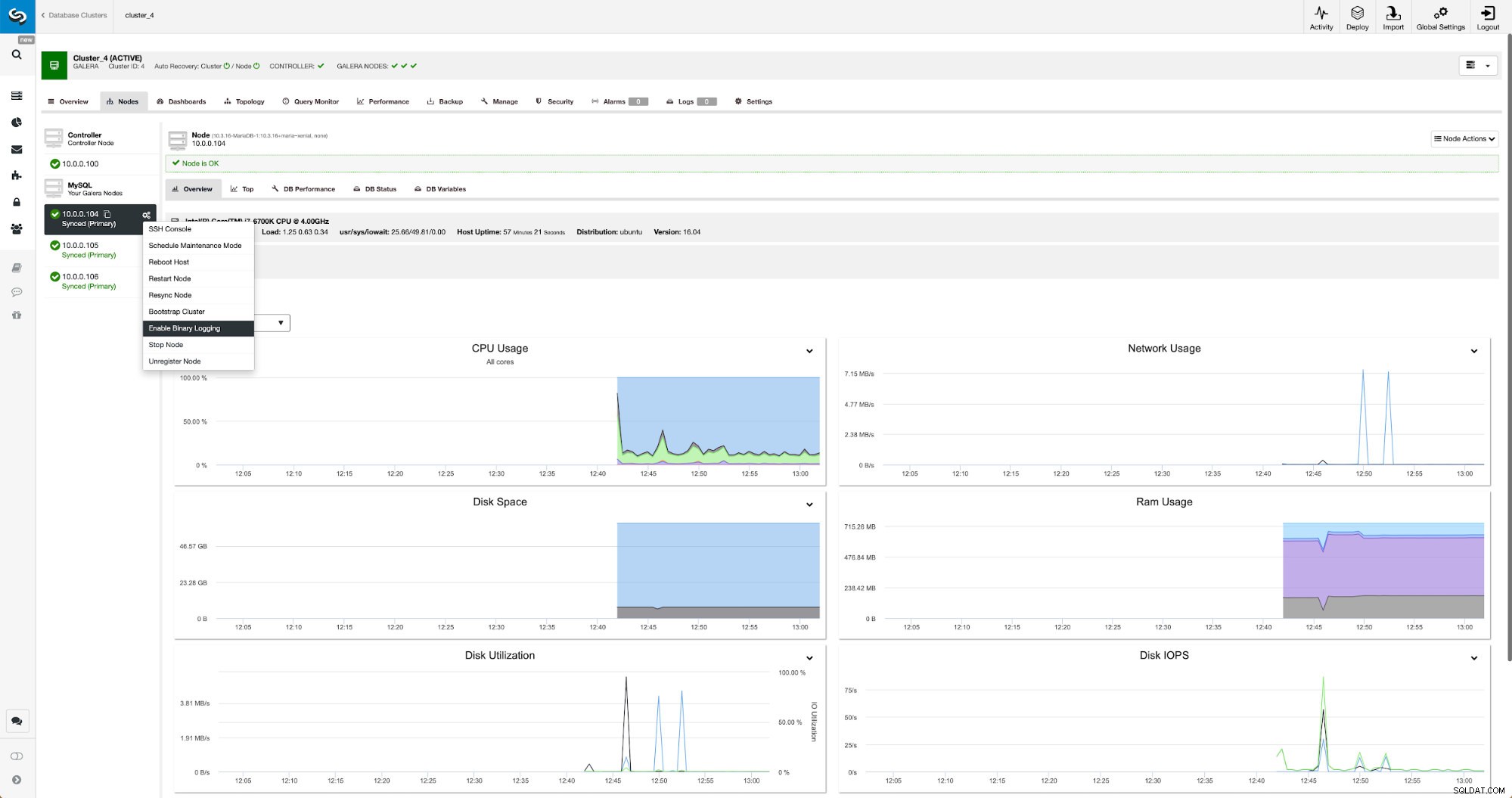
Binära loggar kan aktiveras från avsnittet Noder. Du måste välja nod för nod och köra "Aktivera binär loggning". Du kommer att presenteras med en dialogruta:
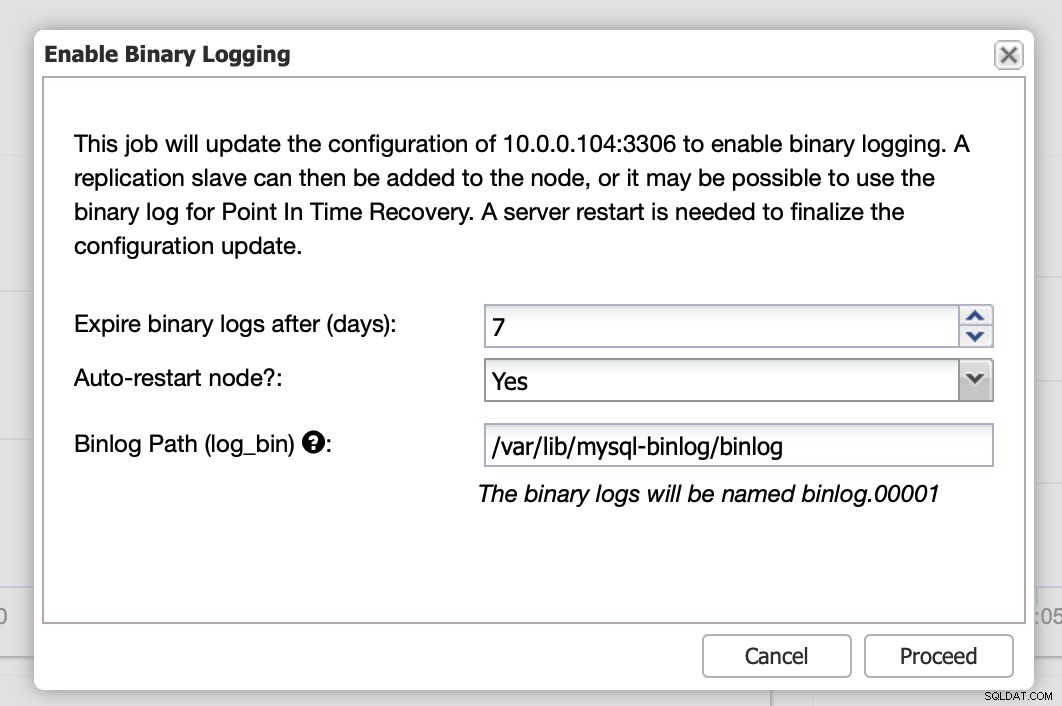
Här kan du definiera hur länge du vill behålla loggarna, var de ska lagras och om ClusterControl ska starta om noden för att du ska kunna tillämpa ändringar - binär loggkonfiguration är inte dynamisk och MariaDB måste startas om för att tillämpa dessa ändringar.
När ändringarna är klara kommer du att se alla noder markerade som "master", vilket betyder att dessa noder har binär logg aktiverad och kan fungera som master.
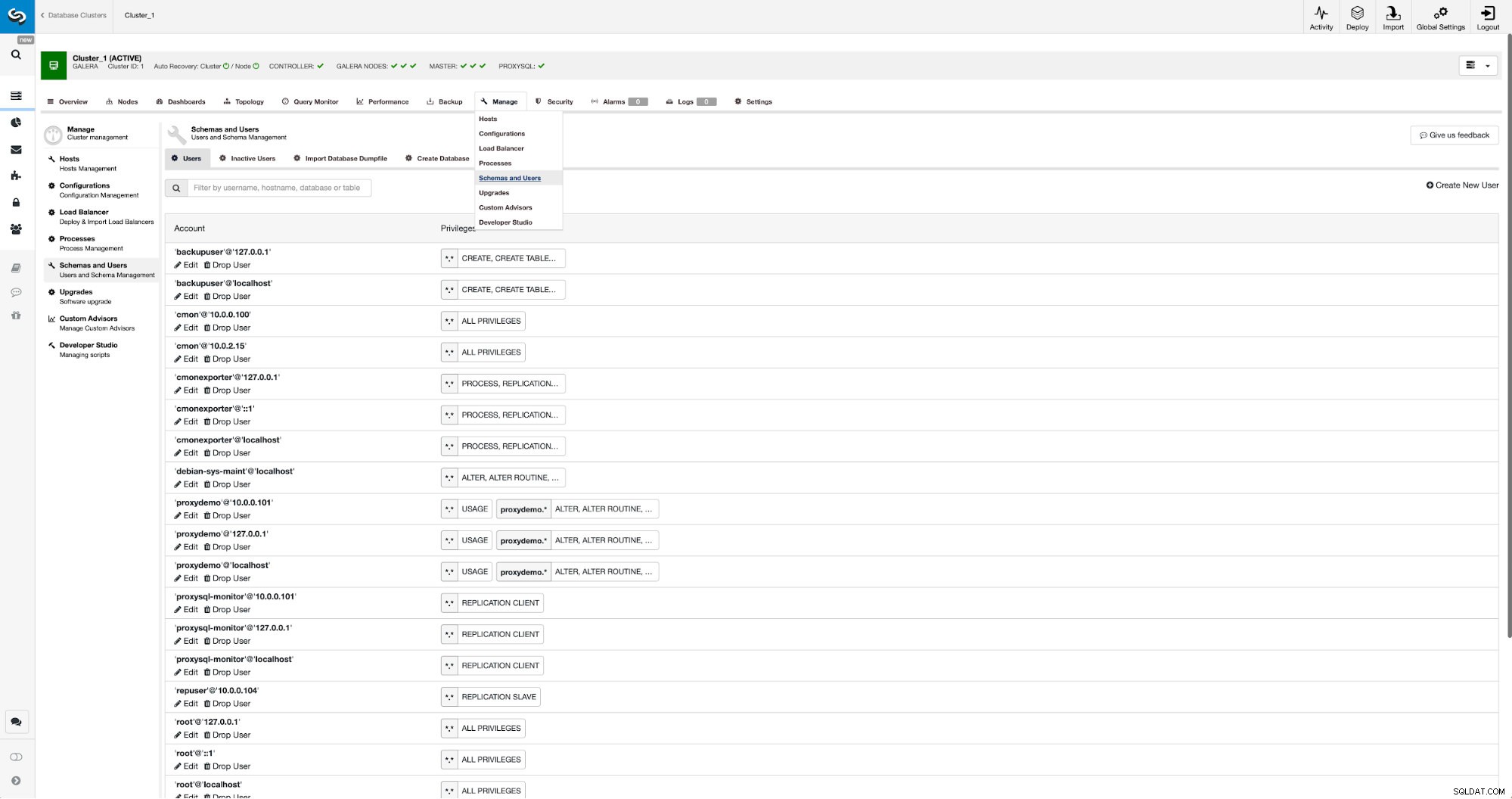
Om vi inte redan har skapat en replikeringsanvändare måste vi göra det. I det första klustret måste vi gå till Hantera -> Schema och användare:
På höger sida har vi ett alternativ att skapa en ny användare:
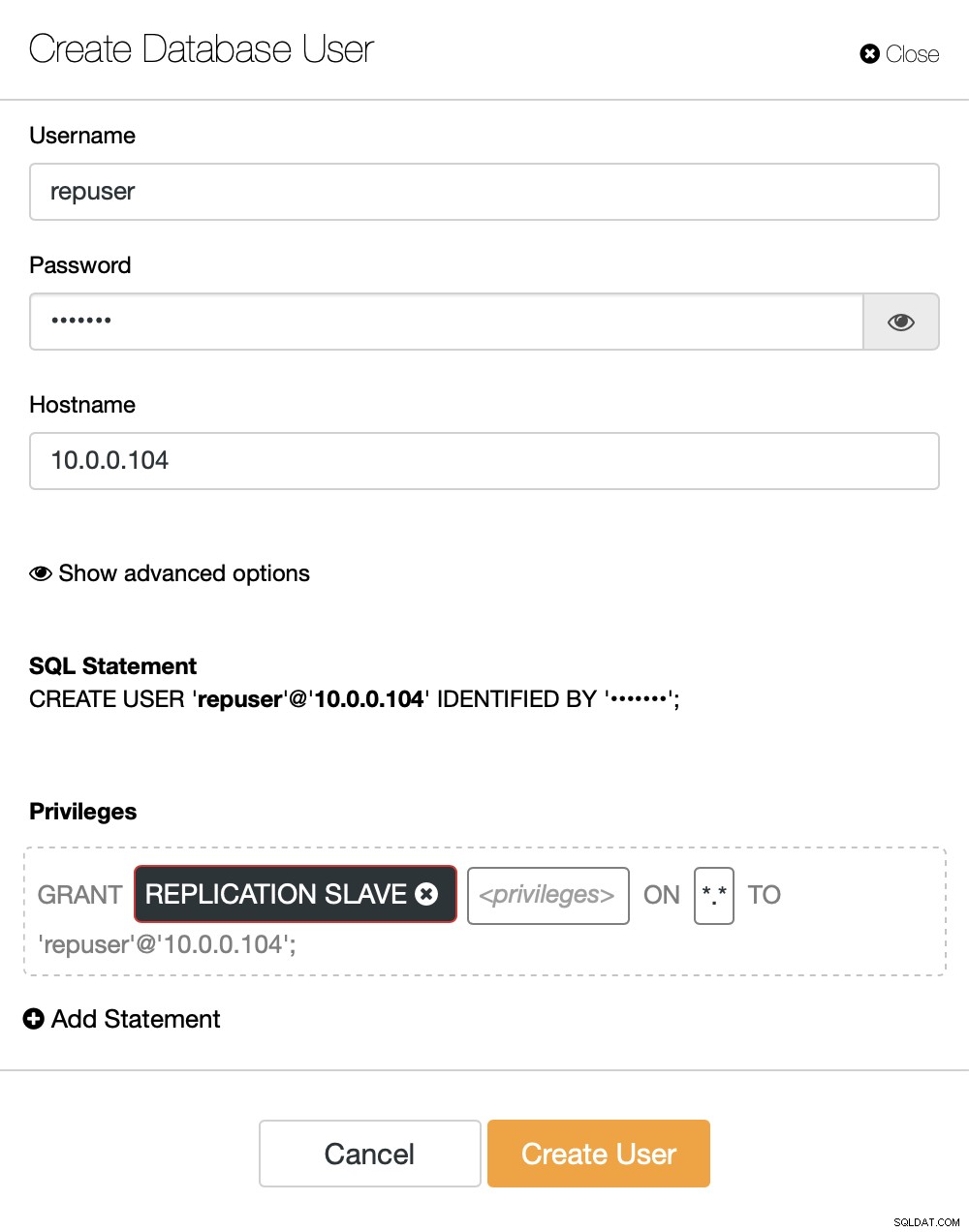
Detta avslutar den konfiguration som krävs för att ställa in replikeringen.
Ställa in replikering mellan kluster med ClusterControl
Som vi sa arbetar vi på att automatisera denna del. För närvarande måste det göras manuellt. Som du kanske kommer ihåg behöver vi GITD-positionen för vår säkerhetskopia och kör sedan ett par kommandon med MySQL CLI. GTID-data finns tillgänglig i säkerhetskopian. ClusterControl skapar backup med hjälp av xbstream/mbstream och den komprimerar den efteråt. Vår säkerhetskopia lagras på ClusterControl-värden där vi inte har tillgång till mbstream binär. Du kan försöka installera den eller så kan du kopiera säkerhetskopian till platsen där sådan binär finns tillgänglig:
scp /root/backups/BACKUP-2/ backup-full-2019-06-24_144329.xbstream.gz 10.0.0.104:/root/mariabackup/När det är gjort vill vi den 10.0.0.104 kontrollera innehållet i filen xtrabackup_info:
cd /root/mariabackup
zcat backup-full-2019-06-24_144329.xbstream.gz | mbstream -x
example@sqldat.com:~/mariabackup# cat /root/mariabackup/xtrabackup_info | grep binlog_pos
binlog_pos = filename 'binlog.000007', position '379', GTID of the last change '9999-1002-846116'Slutligen konfigurerar vi replikeringen och startar den:
MariaDB [(none)]> SET GLOBAL gtid_slave_pos ='9999-1002-846116';
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST='10.0.0.101', MASTER_PORT=3306, MASTER_USER='repuser', MASTER_PASSWORD='reppass', MASTER_USE_GTID=slave_pos;
Query OK, 0 rows affected (0.024 sec)MariaDB [(none)]> START SLAVE;
Query OK, 0 rows affected (0.010 sec)Det här är det - vi har precis konfigurerat asynkron replikering mellan två MariaDB Galera-kluster med ClusterControl. Som du kunde ha sett kunde ClusterControl automatisera majoriteten av de steg vi var tvungna att ta för att ställa in den här miljön.