Den här artikeln beskriver SQL-markörer och hur man använder dem för vissa speciella ändamål. Det belyser vikten av SQL-markörer tillsammans med deras nackdelar.
Det är inte alltid så att du använder SQL-markör i databasprogrammering, men deras konceptuella förståelse och att lära sig hur man använder dem hjälper mycket för att förstå hur man utför exceptionella uppgifter i T-SQL-programmering.
Översikt över SQL-markörer
Låt oss gå igenom några grunder för SQL-markörer om du inte är bekant med dem.
Enkel definition
En SQL-markör ger åtkomst till data en rad i taget och ger dig därmed mer (rad-för-rad) kontroll över resultatuppsättningen.
Microsoft Definition
Enligt Microsofts dokumentation ger Microsoft SQL Server-satser en komplett resultatuppsättning, men det finns tillfällen då resultaten bäst bearbetas en rad i taget. Genom att öppna en markör på en resultatuppsättning kan resultatuppsättningen bearbetas en rad i taget.
T-SQL och resultatuppsättning
Eftersom både en enkel och Microsoft-definition av SQL-markören nämner en resultatuppsättning, låt oss försöka förstå exakt vad resultatuppsättningen är i samband med databasprogrammering. Låt oss snabbt skapa och fylla i Studenttabellen i en exempeldatabas UniversityV3 enligt följande:
SKAPA TABELL [dbo].[Student] ( [StudentId] INT IDENTITY (1, 1) NOT NULL, [Namn] VARCHAR (30) NULL, [Kurs] VARCHAR (30) NULL, [Marks] INT NULL, [ExamDate] DATETIME2 (7) NULL, BEGRÄNSNING [PK_Student] PRIMÄRNYCKEL KLUSTERAD ([StudentId] ASC));-- (5) Fyll i StudenttabellSET IDENTITY_INSERT [dbo].[Student] ONINSERT INTO [dbo].[Student] ( [StudentId], [Namn], [Kurs], [Betyg], [ExamDate]) VÄRDEN (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00 ')INSERT INTO [dbo].[Student] ([StudentId], [Namn], [Kurs], [Betyg], [ExamDate]) VÄRDEN (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')INSERT INTO [dbo].[Student] ([StudentId], [Namn], [Kurs], [Betyg], [ExamDate]) VÄRDEN (3, N' Sam', N'Database Management System', 85, N'2016-01-01 00:00:00')INSERT INTO [dbo].[Student] ([StudentId], [Namn], [Kurs], [Betyg ], [ExamDate]) VÄRDEN (4, N'Adil', N'Database Management System', 85, N'2016-01-01 00:00:00 ')INSERT INTO [dbo].[Student] ([StudentId], [Namn], [Kurs], [Betyg], [ExamDate]) VÄRDEN (5, N'Naveed', N'Database Management System', 90, N'2016-01-01 00:00:00')SET IDENTITY_INSERT [dbo].[Student] AV
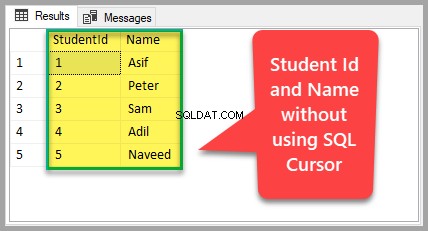
Välj nu alla rader från Elev tabell:
-- Visa studenttabelldata VÄLJ [StudentId], [Namn], [Kurs], [Betyg], [ExamDate] FRÅN dbo.Student
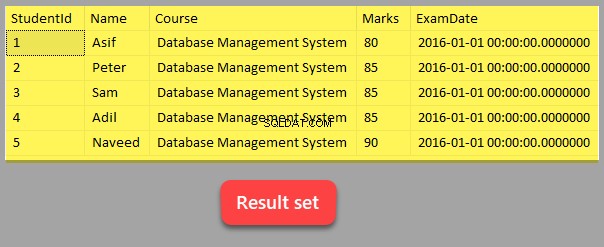
Detta är resultatuppsättningen som returneras som ett resultat av att alla poster har valts från Student bord.
T-SQL och mängdteori
T-SQL är enbart baserad på följande två matematiska begrepp:
- Mängdteori
- Predikatlogik
Mängdläran är, som namnet antyder, en gren av matematiken om mängder som också kan kallas samlingar av bestämda distinkta objekt.
Kort sagt, i mängdteorin tänker vi på saker eller föremål som en helhet på samma sätt som vi tänker på ett enskilt föremål.
Eleven är till exempel en uppsättning av alla bestämda distinkta elever, så vi tar en elev som en helhet vilket är tillräckligt för att få detaljer om alla elever i den uppsättningen (tabell).
Se min artikel Konsten att aggregera data i SQL från enkla till glidande aggregationer för ytterligare information.
Markörer och radbaserade operationer
T-SQL är i första hand utformad för att utföra uppsättningsbaserade operationer som att välja alla poster från en tabell eller ta bort alla rader från en tabell.
Kort sagt, T-SQL är speciellt utformad för att arbeta med tabeller på ett uppsättningsbaserat sätt, vilket innebär att vi tänker på en tabell som en helhet, och alla operationer som att välja, uppdatera eller ta bort tillämpas som en helhet på tabellen eller vissa rader som uppfyller kriterierna.
Det finns dock fall då tabeller måste nås rad för rad snarare än som en enda resultatuppsättning, och det är då markörerna träder i kraft.
Enligt Vaidehi Pandere behöver applikationslogik ibland fungera med en rad i taget snarare än alla rader på en gång, vilket är samma sak som looping (användning av loopar för att iterera) genom hela resultatuppsättningen.
Grunderna i SQL-markörer med exempel
Låt oss nu diskutera mer om SQL-markörer.
Först av allt, låt oss lära oss eller granska (de som redan är bekanta med att använda markörer i T-SQL) hur man använder markören i T-SQL.
Att använda SQL-markören är en process i fem steg som uttrycks enligt följande:
- Deklarera markör
- Öppna markören
- Hämta rader
- Stäng markör
- Avallokera markör
Steg 1:Ange markör
Det första steget är att deklarera SQL-markören så att den kan användas efteråt.
SQL-markören kan deklareras enligt följande:
DECLARE Cursorför
Steg 2:Öppna markören
Nästa steg efter deklarationen är att öppna markören vilket innebär att markören fylls i med resultatuppsättningen som uttrycks enligt följande:
Öppna
Steg 3:Hämta rader
När markören har deklarerats och öppnats är nästa steg att börja hämta rader från SQL-markören en efter en så hämta rader får nästa tillgängliga rad från SQL-markören:
Hämta nästa från
Steg 4:Stäng markören
När raderna har hämtats en efter en och manipulerats enligt kraven, är nästa steg att stänga SQL-markören.
Att stänga SQL-markören utför tre uppgifter:
- Släpper resultatuppsättningen som för närvarande hålls av markören
- Frigör alla markörlås på raderna vid markören
- Stänger den öppna markören
Den enkla syntaxen för att stänga markören är som följer:
Stäng
Steg 5:Avallokera markör
Det sista steget i detta avseende är att avallokera markören som tar bort markörreferensen.
Syntaxen är följande:
DEALLOCATE
SQL-markörkompatibilitet
Enligt Microsofts dokumentation är SQL-markörer kompatibla med följande versioner:
- SQL Server 2008 och senare versioner
- Azure SQL Database
SQL-markörexempel 1:
Nu när vi är bekanta med stegen för att implementera SQL-markören, låt oss titta på ett enkelt exempel på hur du använder SQL-markören:
-- Deklarera studentmarkörexempel 1ANVÄND UniversityV3GODECLARE Student_Cursor CURSOR FOR SELECT StudentId ,[Name]FROM dbo.Student;OPEN Student_CursorFETCH NEXT FROM Student_CursorWHILE @@FETCH_STATUS =0BEGINFETCH NEXT_CursorFETCH_Cursor FETCHUtgången är som följer:
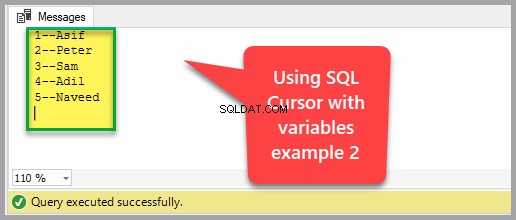
SQL-markörexempel 2:
I det här exemplet kommer vi att använda två variabler för att lagra data som hålls av markören när den flyttas från rad till rad så att vi kan visa resultatuppsättningen en rad i taget genom att visa variabelvärdena.
-- Deklarera studentmarkör med variabler exempel 2ANVÄND UniversityV3GODECLARE @StudentId INT ,@StudentName VARCHAR(40) -- Deklarera att variabler innehåller raddata som innehas av cursorDECLARE Student_Cursor CURSOR FOR SELECT StudentId ,[Name]FROM dboOPFENCursor Student_Cursor NÄSTA FRÅN Student_Cursor INTO @StudentId, @StudentName -- Hämta första raden och lagra den i variabler WHILE @@FETCH_STATUS =0BEGIN PRINT CONCAT(@StudentId,'--', @StudentName) -- Visa variabler dataFETCH NEXT FROM Student_Crowursor data i markören och lagra den i variabler INTO @StudentId, @StudentNameENDCLOSE Student_Cursor -- Stäng markörlås på radernaDEALLOCATE Student_Cursor -- Släpp markörreferensResultatet av ovanstående SQL-kod är följande:
Man skulle hävda att vi kan uppnå samma utdata genom att använda enkla SQL-skript enligt följande:
-- Visa student-id och namn utan SQL cursorSELECT StudentId,Name FROM dbo.Studentorder by StudentId
Det finns faktiskt en hel del uppgifter som kräver att SQL-markörer används trots att det avråds från att använda SQL-markörer på grund av deras direkta inverkan på minnet.
Viktig anmärkning
Vänligen kom ihåg att enligt Vaidehi Pandere är markörer en minnesbaserad uppsättning pekare så att de upptar ditt systemminne som annars skulle användas av andra viktiga processer; det är därför att det aldrig är en bra idé att gå igenom ett stort resultat med hjälp av markörer om det inte finns en legitim anledning till det.
Använda SQL-markörer för speciella ändamål
Vi kommer att gå igenom några speciella syften för vilka SQL-markörer kan användas.
Minnestestning av databasserver
Eftersom SQL-markörer har en stor inverkan på systemminnet är de goda kandidater för att replikera scenarier där överdriven minnesanvändning av olika lagrade procedurer eller ad-hoc SQL-skript behöver undersökas.
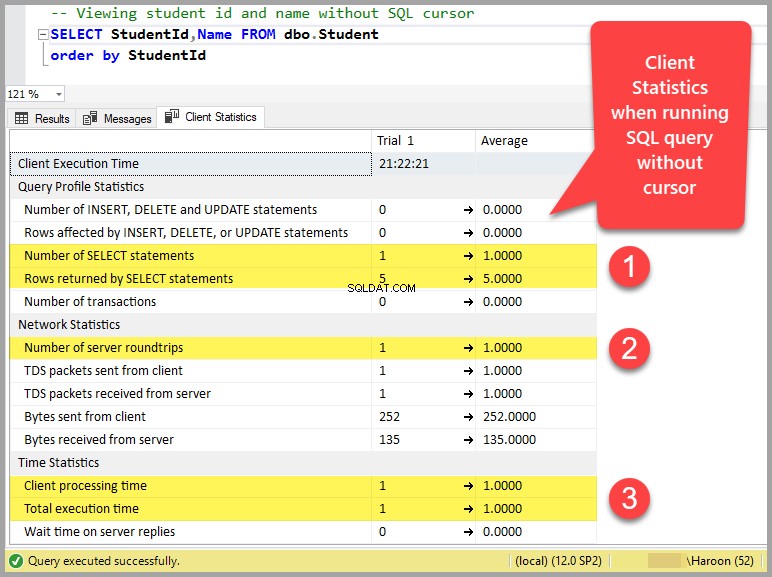
Ett enkelt sätt att förstå detta är att klicka på klientstatistikknappen i verktygsfältet (eller trycka Skift+Alt+S) i SSMS (SQL Server Management Studio) och köra en enkel fråga utan markör:
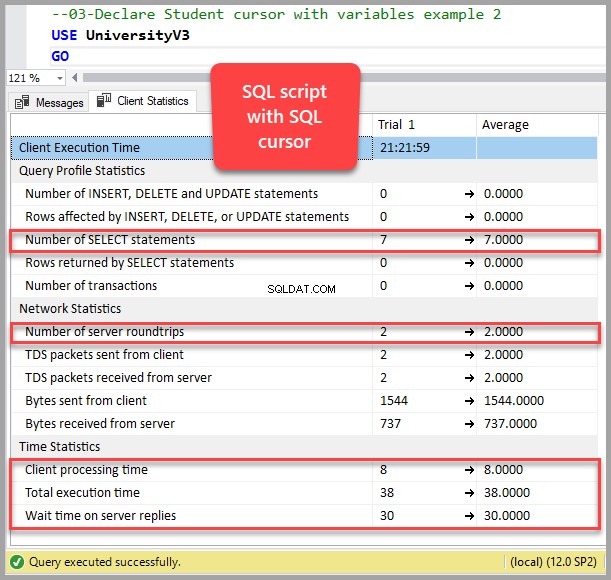
Kör nu frågan med markören med hjälp av variabler (SQL-markörexempel 2):
Notera nu skillnaderna:
Antal SELECT-satser utan markör:1
Antal SELECT-satser med markören:7
Antal server rundor utan markör:1
Antal serverturer med markören:2
Klientbehandlingstid utan markör:1
Klientbehandlingstid med markör:8
Total körningstid utan markör:1
Total körningstid med markör:38
Väntetid på serversvar utan markör:0
Väntetid på serversvar med markör:30
Kort sagt, att köra frågan utan markören, som bara returnerar 5 rader, kör samma fråga 6-7 gånger med markören.
Nu kan du föreställa dig hur lätt det är att replikera minnespåverkan med hjälp av markörer, men detta är inte alltid det bästa du kan göra.
Manipulationsuppgifter för massdatabasobjekt
Det finns ett annat område där SQL-markörer kan vara praktiska och det är när vi måste utföra en bulkoperation på databaser eller databasobjekt.
För att förstå detta måste vi först skapa kurstabellen och fylla i den i UniversityV3 databas enligt följande:
-- Skapa kurstabell SKAPA TABELL [dbo].[Kurs] ( [CourseId] INT IDENTITY (1, 1) NOT NULL, [Namn] VARCHAR (30) NOT NULL, [Detalj] VARCHAR (200) NULL, CONSTRAINT [PK_Course] PRIMARY KEY CLUSTERED ([CourseId] ASC));-- Fyll kurstabellSET IDENTITY_INSERT [dbo].[Course] ONINSERT I [dbo].[Course] ([CourseId], [Namn], [Detalj]) VÄRDEN (1, N'DevOps for Databases', N'This is about DevOps for Databases')INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detalj]) VÄRDEN (2, N'Power BI Fundamentals', N'Detta handlar om Power BI Fundamentals')INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detalj]) VÄRDEN (3, N'T-SQL-programmering', N'About T-SQL-programmering')INSERT INTO [dbo].[Course] ([CourseId], [Name], [Detalj]) VÄRDEN (4, N'Tabulär Datamodellering', N'Detta handlar om tabelldatamodellering')INSERT INTO [dbo].[Kurs] ([CourseId], [Namn], [Detalj]) VÄRDEN (5, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals')SET IDENTITY_INSERT [dbo].[Kurs] AVAnta nu att vi vill byta namn på alla befintliga tabeller i UniversityV3 databas som GAMLA tabeller.
Detta kräver att markören upprepas över alla tabeller en efter en så att de kan byta namn.
Följande kod gör jobbet:
-- Deklarera Studentmarkör för att byta namn på alla tabeller som oldUSE UniversityV3GODECLARE @TableName VARCHAR(50) -- Befintligt tabellnamn ,@NewTableName VARCHAR(50) -- Nytt tabellnamnDECLARE Student_Cursor CURSOR FÖR VÄLJ T.TABLE_NAME FRÅN INFORMATIONSSCHEMA. T;OPEN Student_CursorFETCH NEXT FROM Student_Cursor INTO @TableNameWHILE @@FETCH_STATUS =0BEGINSET @example@sqldat.com+'_OLD' -- Lägg till _OLD till befintligt namn på tabellEXEC sp_rename @TableName,@NewTableName -- FXTROMETCH tabell OLD -- Hämta nästa raddata till markören och lagra den i variabler INTO @TabellnamnENDCLOSE Student_Cursor -- Stäng markörlås på radernaDEALLOCATE Student_Cursor -- Släpp markörreferens
Grattis, du har framgångsrikt bytt namn på alla befintliga tabeller med hjälp av SQL-markören.
Saker att göra
Nu när du är bekant med användningen av SQL-markören, försök med följande saker:
- Försök att skapa och byta namn på index för alla tabeller i en exempeldatabas med markören.
- Försök att återställa de omdöpta tabellerna i den här artikeln till ursprungliga namn med hjälp av markören.
- Försök att fylla i tabeller med många rader och mät statistiken och tiden för frågorna med och utan markören.