I kommentarsektionen på en av våra bloggar frågade en läsare om effekten av wsrep_slave_threads på Galera Clusters I/O-prestanda och skalbarhet. Vid den tiden kunde vi inte enkelt svara på den frågan och säkerhetskopiera den med mer data, men till slut lyckades vi ställa in miljön och köra några tester.
Vår läsare pekade på riktmärken som visade att ökning av wsrep_slave_threads inte hade någon inverkan på Galera-klustrets prestanda.
För att förklara vilken effekt den inställningen har, satte vi upp ett litet kluster med tre noder (m5d.xlarge). Detta gjorde det möjligt för oss att använda direkt ansluten nvme SSD för MySQL-datakatalogen. Genom att göra detta minimerar vi chansen att lagring blir flaskhalsen i vår installation.
Vi ställer in InnoDB buffertpool till 8GB och gör om loggar till två filer, 1GB vardera. Vi ökade också innodb_io_capacity till 2000 och innodb_io_capacity_max till 10000. Detta var också avsett att säkerställa att ingen av dessa inställningar skulle påverka vår prestanda.
Hela problemet med sådana riktmärken är att det finns så många flaskhalsar att man måste eliminera dem en efter en. Först efter att ha gjort lite konfigurationsjustering och efter att ha sett till att hårdvaran inte kommer att vara ett problem, kan man hoppas att några mer subtila gränser kommer att dyka upp.
Vi genererade ~90 GB data med hjälp av sysbench:
sysbench /usr/share/sysbench/oltp_write_only.lua --threads=16 --events=0 --time=600 --mysql-host=172.30.4.245 --mysql-user=sbtest --mysql-password=sbtest --mysql-port=3306 --tables=28 --report-interval=1 --skip-trx=off --table-size=10000000 --db-ps-mode=disable --mysql-db=sbtest_large prepareSedan utfördes riktmärket. Vi testade två inställningar:wsrep_slave_threads=1 och wsrep_slave_threads=16. Hårdvaran var inte tillräckligt kraftfull för att dra nytta av att öka denna variabel ytterligare. Kom också ihåg att vi inte gjorde en detaljerad benchmarking för att avgöra om wsrep_slave_threads ska ställas in på 16, 8 eller kanske 4 för bästa prestanda. Vi var intresserade av att se om vi kan visa en inverkan på klustret. Och ja, effekten var tydligt synlig. Till att börja med, några flödeskontrolldiagram.
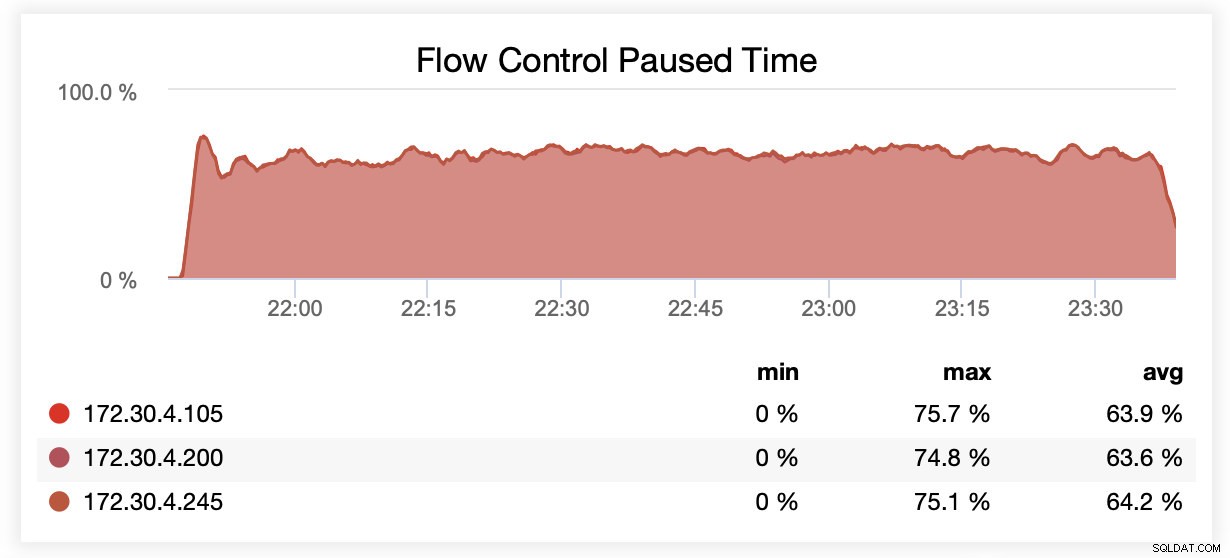
När du körde med wsrep_slave_threads=1 pausades i genomsnitt noder på grund av flödeskontroll ~64 % av tiden.
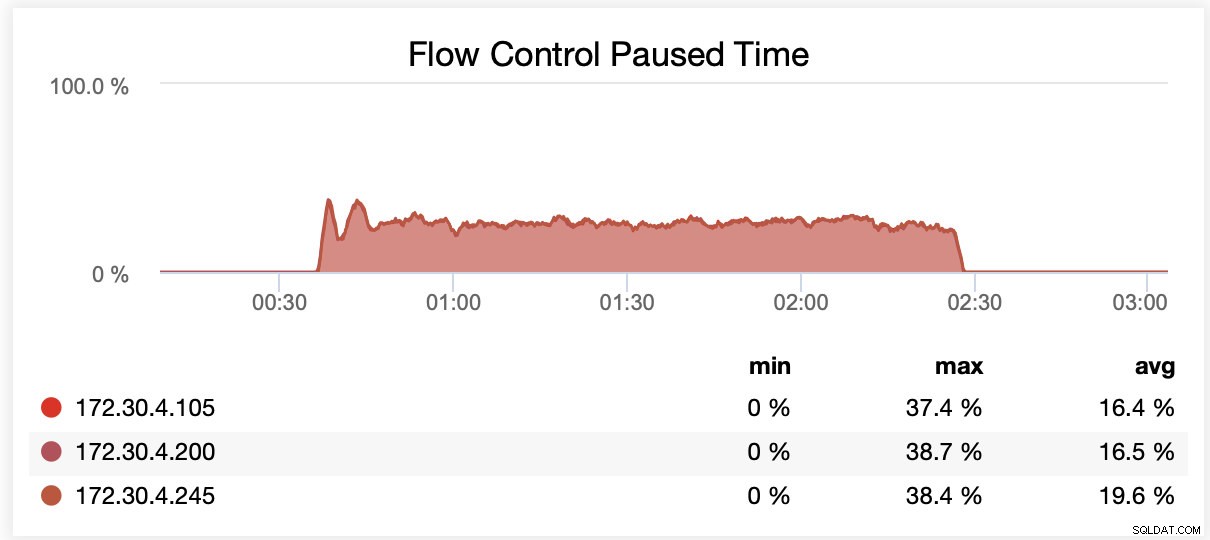
När du körde med wsrep_slave_threads=16 pausades i genomsnitt noder på grund av flödeskontroll ~20 % av tiden.
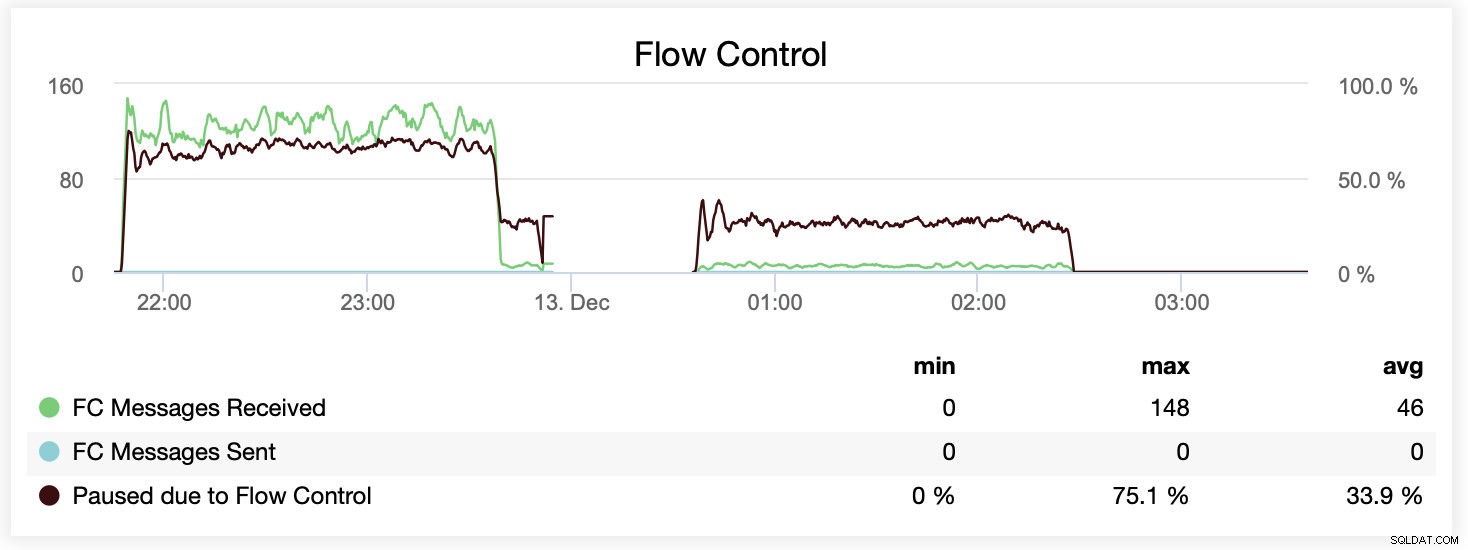
Du kan också jämföra skillnaden på en enda graf. Droppet i slutet av den första delen är det första försöket att köra med wsrep_slave_threads=16. Servrarna fick slut på diskutrymme för binära loggar och vi var tvungna att köra det riktmärket igen vid ett senare tillfälle.
Hur översattes detta i prestandatermer? Skillnaden är synlig även om den definitivt inte är så spektakulär.
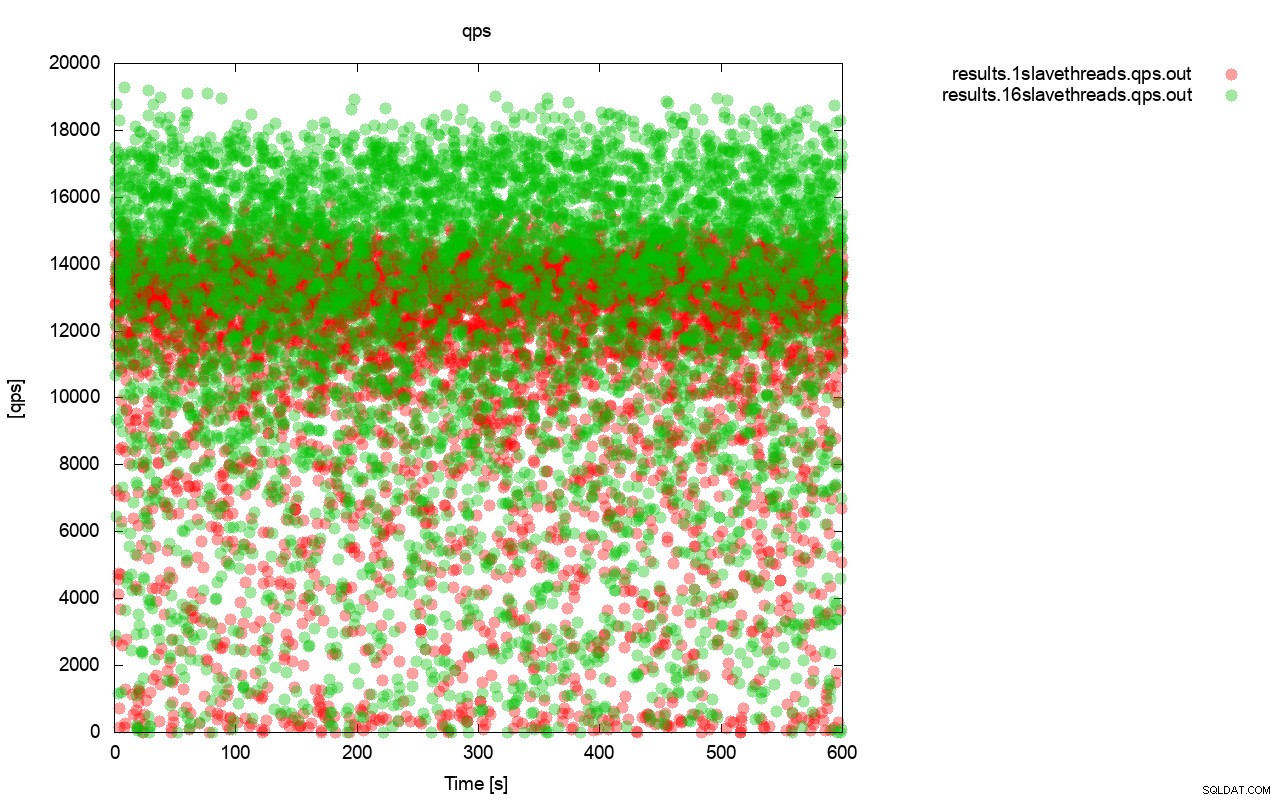
Först, frågan per sekund-grafen. Först och främst kan du märka att resultaten är överallt i båda fallen. Detta är mest relaterat till den instabila prestandan hos I/O-lagringen och flödeskontrollen som slumpmässigt slår in. Du kan fortfarande se att prestandan för det "röda" resultatet (wsrep_slave_threads=1) är ganska lägre än det "gröna" ( wsrep_slave_threads=16).
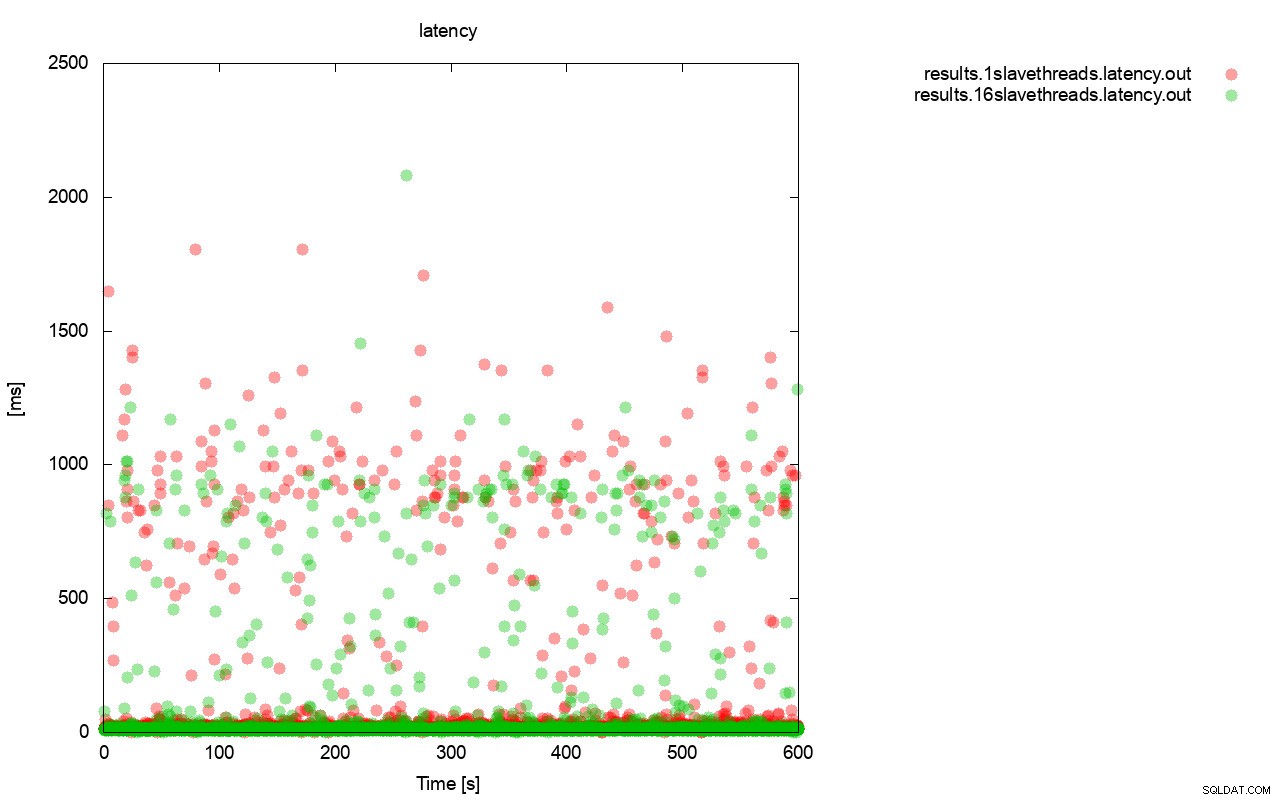
Ganska liknande bild är när vi tittar på latensen. Du kan se fler (och vanligtvis djupare) bås för löpningen med wsrep_slave_thread=1.
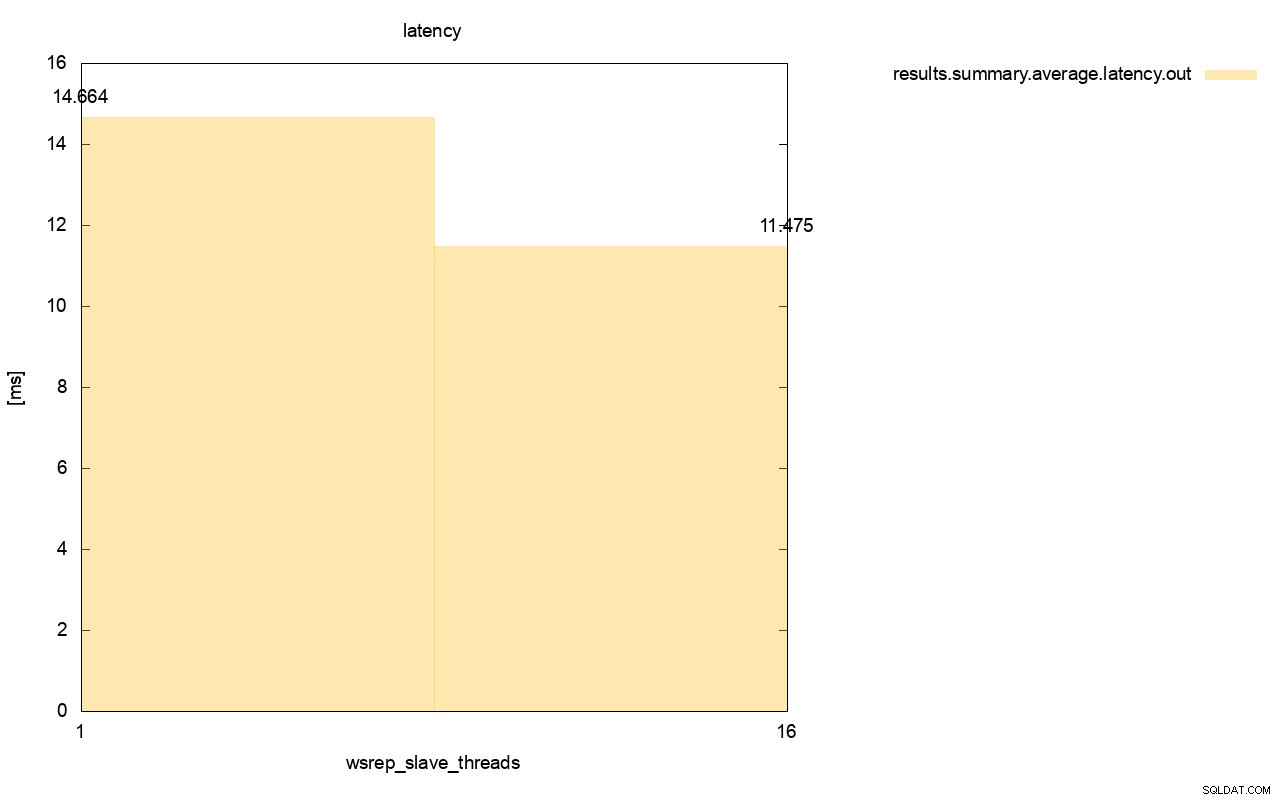
Skillnaden är ännu mer synlig när vi beräknade genomsnittlig latens över alla körningar och du kan se att latensen för wsrep_slave_thread=1 är 27 % högre av latensen med 16 slavtrådar, vilket uppenbarligen inte är bra eftersom vi vill att latensen ska vara lägre , inte högre.
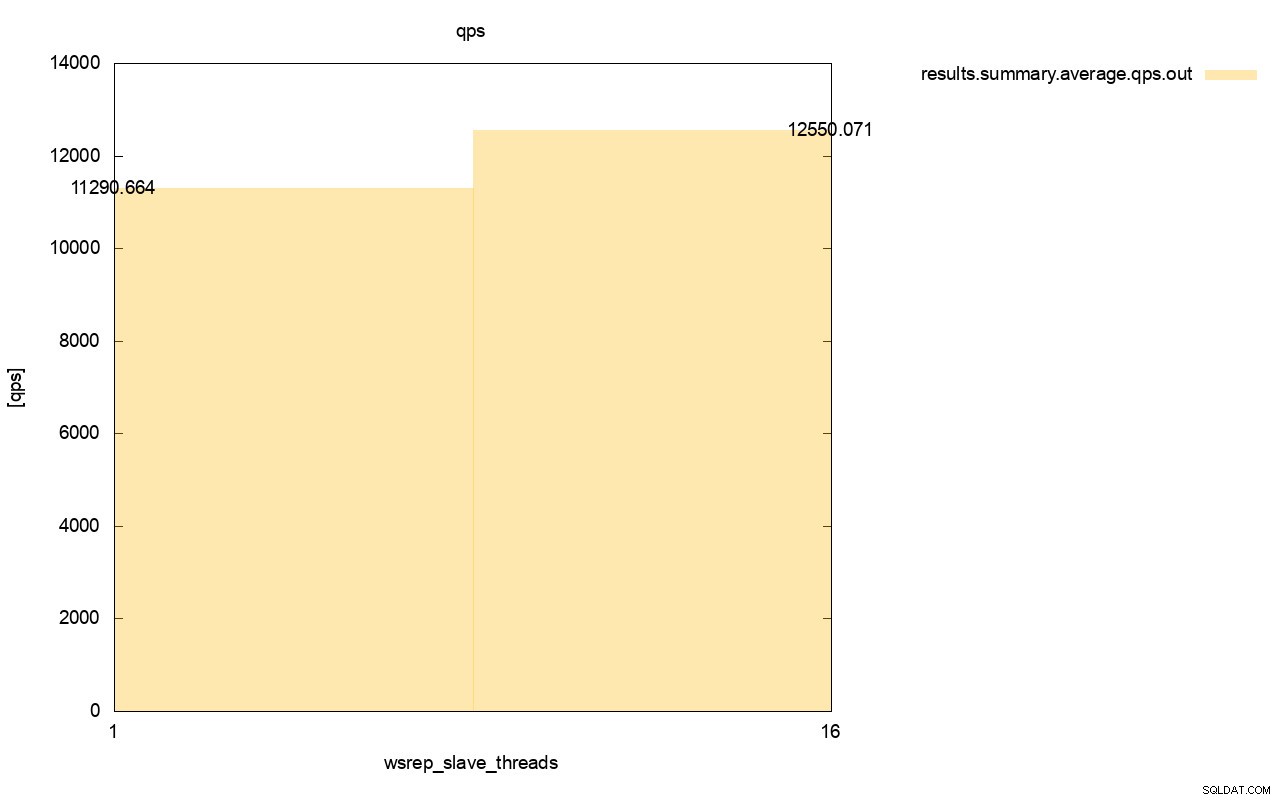
Skillnaden i genomströmning är också synlig, cirka 11 % av förbättringen när vi lade till fler wsrep_slave_threads.
Som du kan se är effekten där. Det är inte på något sätt 16x (även om det var så vi ökade antalet slavtrådar i Galera) men det är definitivt tillräckligt framträdande så att vi inte kan klassificera det som bara en statistisk anomali.
Kom ihåg att i vårt fall använde vi ganska små noder. Skillnaden borde vara ännu mer betydande om vi talar om stora instanser som körs på EBS-volymer med tusentals provisionerade IOPS.
Då skulle vi kunna köra sysbench ännu mer aggressivt, med högre antal samtidiga operationer. Detta bör förbättra parallelliseringen av skrivuppsättningarna och förbättra vinsten från multitrådningen ytterligare. Snabbare hårdvara innebär också att Galera kommer att kunna använda dessa 16 trådar på ett mer effektivt sätt.
När du kör sådana här tester måste du komma ihåg att du måste pressa din installation nästan till dess gränser. Enkeltrådsreplikering kan hantera ganska mycket belastning och du måste köra tung trafik för att den faktiskt inte ska prestera tillräckligt för att hantera uppgiften.
Vi hoppas att det här blogginlägget ger dig mer insikt i Galera Clusters förmåga att tillämpa skrivuppsättningar parallellt och de begränsande faktorerna runt det.