Bakgrund
En av de första sakerna jag tittar på när jag felsöker ett prestandaproblem är väntestatistik via sys.dm_os_wait_stats DMV. För att se vad SQL Server väntar på använder jag frågan från Glenn Berrys nuvarande uppsättning SQL Server Diagnostic Queries. Beroende på resultatet börjar jag gräva i specifika områden inom SQL Server.
Som ett exempel, om jag ser höga CXPACKET-väntningar kontrollerar jag antalet kärnor på servern, antalet NUMA-noder och värdena för maxgraden av parallellitet och kostnadströskeln för parallellism. Detta är bakgrundsinformation som jag använder för att förstå konfigurationen. Innan jag ens överväger att göra några ändringar samlar jag på mig mer kvantitativ data, eftersom ett system med CXPACKET väntar inte nödvändigtvis har en felaktig inställning för maximal grad av parallellitet.
På liknande sätt har ett system som har höga väntetider för I/O-relaterade väntetyper som PAGEIOLATCH_XX, WRITELOG och IO_COMPLETION inte nödvändigtvis ett sämre lagringsundersystem. När jag ser I/O-relaterade väntetyper när toppen väntar, vill jag genast förstå mer om den underliggande lagringen. Är det direktansluten lagring eller ett SAN? Vad är RAID-nivån, hur många diskar finns det i arrayen och vilken hastighet har diskarna? Jag vill också veta om andra filer eller databaser delar lagringen. Och även om det är viktigt att förstå konfigurationen, är ett logiskt nästa steg att titta på virtuell filstatistik via sys.dm_io_virtual_file_stats DMV.
Denna DMV, som introducerades i SQL Server 2005, är en ersättning för funktionen fn_virtualfilestats som de av er som körde på SQL Server 2000 och tidigare förmodligen känner till och älskar. DMV innehåller kumulativ I/O-information för varje databasfil, men data återställs vid omstart av instansen, när en databas stängs, tas offline, kopplas bort och återansluts, etc. Det är viktigt att förstå att statistikdata för virtuella filer inte är representativa för nuvarande prestanda – det är en ögonblicksbild som är en aggregering av I/O-data sedan den senaste rensningen av en av de tidigare nämnda händelserna. Även om informationen inte är punkt-i-tid, kan den fortfarande vara användbar. Om de högsta väntetiderna på en instans är I/O-relaterade, men den genomsnittliga väntetiden är mindre än 10 ms, är lagring förmodligen inte ett problem – men att korrelera utdata med det du ser i sys.dm_io_virtual_stats är fortfarande värt att bekräfta lågt latenser. Dessutom, även om du ser höga latenser i sys.dm_io_virtual_stats, har du fortfarande inte bevisat att lagring är ett problem.
Inställningen
För att titta på virtuell filstatistik satte jag upp två kopior av databasen AdventureWorks2012, som du kan ladda ner från Codeplex. För det första exemplaret, hädanefter känt som EX_AdventureWorks2012, körde jag Jonathan Kehayias skript för att utöka tabellerna Sales.SalesOrderHeader och Sales.SalesOrderDetail till 1,2 miljoner respektive 4,9 miljoner rader. För den andra databasen, BIG_AdventureWorks2012, använde jag skriptet från mitt tidigare partitioneringsinlägg för att skapa en kopia av tabellen Sales.SalesOrderHeader med 123 miljoner rader. Båda databaserna lagrades på en extern USB-enhet (Seagate Slim 500GB), med tempdb på min lokala disk (SSD).
Innan jag testade skapade jag fyra anpassade lagrade procedurer i varje databas (Create_Custom_SPs.zip), som skulle fungera som min "normala" arbetsbelastning. Min testprocess var följande för varje databas:
- Starta om instansen.
- Fånga statistik för virtuella filer.
- Kör den "normala" arbetsbelastningen i två minuter (procedurer anropas upprepade gånger via ett PowerShell-skript).
- Fånga statistik för virtuella filer.
- Bygg om alla index för lämplig(a) försäljningsordertabell(er).
- Fånga statistik för virtuella filer.
Datan
För att fånga virtuell filstatistik skapade jag en tabell för historisk information och använde sedan en variant av Jimmy Mays fråga från hans DMV All-Stars-skript för ögonblicksbilden:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Jag startade om instansen och fångade sedan omedelbart filstatistik. När jag filtrerade utdata för att bara visa EX_AdventureWorks2012- och tempdb-databasfilerna fångades endast tempdb-data eftersom ingen data hade begärts från EX_AdventureWorks2012-databasen:

Utdata från initial insamling av sys.dm_os_virtual_file_stats
Jag körde sedan den "normala" arbetsbelastningen i två minuter (antalet körningar av varje lagrad procedur varierade något), och efter att den slutförts infångade jag filstatistik igen:

Utdata från sys.dm_os_virtual_file_stats efter normal arbetsbelastning
Vi ser en latens på 57ms för datafilen EX_AdventureWorks2012. Inte idealiskt, men med tiden med min normala arbetsbelastning skulle detta förmodligen jämna ut sig. Det finns minimal latens för tempdb, vilket förväntas eftersom arbetsbelastningen jag körde inte genererar mycket tempdb-aktivitet. Därefter byggde jag om alla index för tabellerna Sales.SalesOrderHeaderEnlarged och Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Ombyggnationerna tog mindre än en minut och märkte ökningen i läslatens för EX_AdventureWorks2012-datafilen och topparna i skrivfördröjning för EX_AdventureWorks2012-data och loggfiler:

Utdata från sys.dm_os_virtual_file_stats efter ombyggnad av index
Enligt den ögonblicksbilden av filstatistik är latensen hemsk; över 600ms för att skriva! Om jag såg detta värde för ett produktionssystem skulle det vara lätt att omedelbart misstänka problem med lagring. Det är dock också värt att notera att AvgBPerWrite ökade också, och större blockskrivningar tar längre tid att slutföra. AvgBPerWrite-ökningen förväntas för indexåteruppbyggnadsuppgiften.
Förstå att när du tittar på denna information får du inte en fullständig bild. Ett bättre sätt att titta på latenser med hjälp av virtuell filstatistik är att ta ögonblicksbilder och sedan beräkna latens för den förflutna tidsperioden. Skriptet nedan använder till exempel två ögonblicksbilder (nuvarande och tidigare) och beräknar sedan antalet läsningar och skrivningar under den tidsperioden, skillnaden i io_stall_read_ms och io_stall_write_ms värden, och dividerar sedan io_stall_read_ms delta med antal läsningar och io_stall_write_ms med delta antal skrivningar. Med den här metoden beräknar vi hur lång tid SQL Server väntade på I/O för läsning eller skrivning, och dividerar den sedan med antalet läsningar eller skrivningar för att bestämma latens.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
När vi kör detta för att beräkna latens under indexombyggnaden får vi följande:

Latens beräknad från sys.dm_io_virtual_file_stats under ombyggnad av index2_0Adventure för index2_0Adventure för index2_0Adventure. em>
Nu kan vi se att den faktiska latensen under den tiden var hög – vilket vi skulle förvänta oss. Och om vi sedan gick tillbaka till vår normala arbetsbelastning och körde den i några timmar, skulle medelvärdena beräknade från virtuell filstatistik minska med tiden. Faktum är att om vi tittar på PerfMon-data som fångades under testet (och sedan bearbetades genom PAL), ser vi betydande toppar i Avg. Disk sek/Läs och Avg. Disk sec/Write som korrelerar med den tid då indexombyggnaden kördes. Men vid andra tillfällen är latensvärdena långt under acceptabla värden:
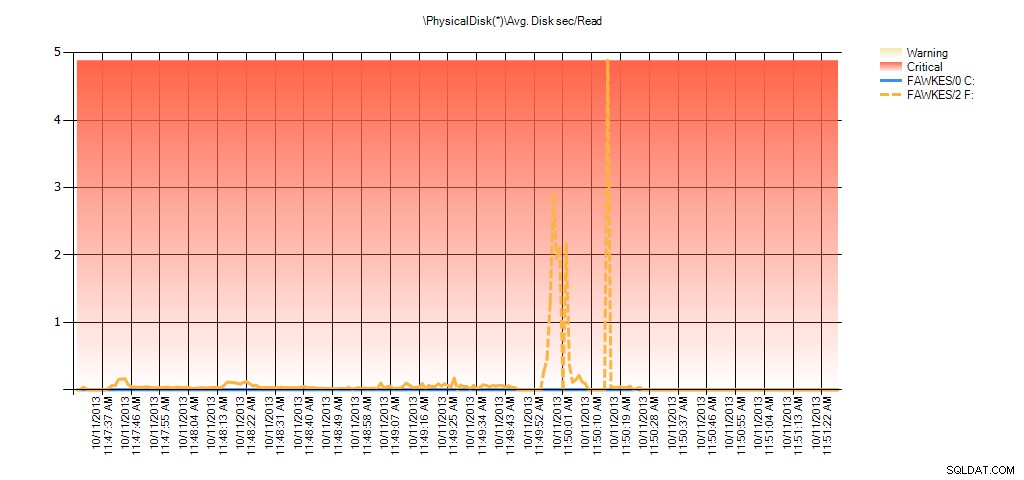
Sammanfattning av genomsnittlig disksek./läsning från PAL för EX_AdventureWorks2012 under testning
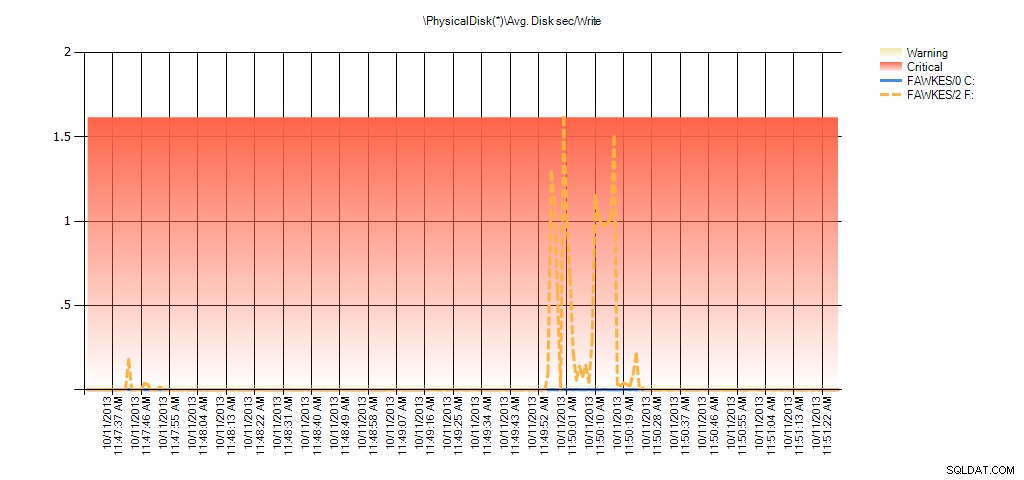
Sammanfattning av Avg Disk Sec/Write från PAL för EX_AdventureWorks2012 under testning
Du kan se samma beteende för databasen BIG_AdventureWorks 2012. Här är latensinformationen baserad på den virtuella filstatistikens ögonblicksbild före indexombyggnaden och efter:

Latens beräknad från sys.dm_io_virtual_file_stats under index rebuild eller BIG2_0Adventure em>
Och Performance Monitor-data visar samma toppar under ombyggnaden:
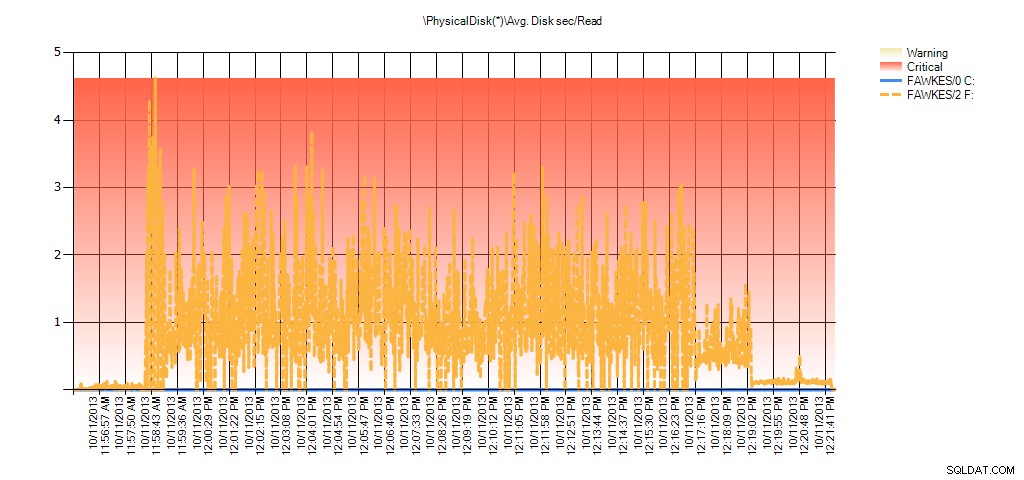
Sammanfattning av Avg Disk Sec/Läs från PAL för BIG_AdventureWorks2012 under testning
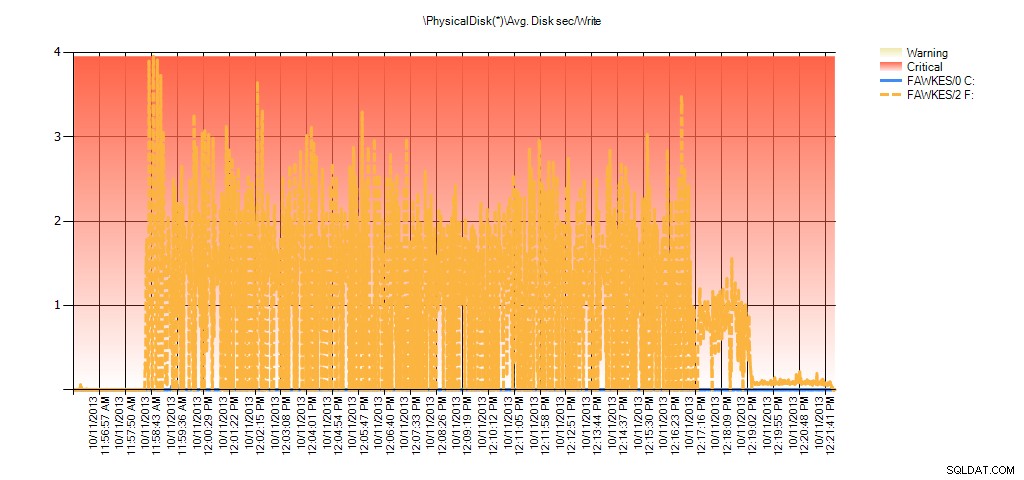
Sammanfattning av Avg Disk Sec/Write från PAL för BIG_AdventureWorks2012 under testning
Slutsats
Virtuell filstatistik är en bra utgångspunkt när du vill förstå I/O-prestanda för en SQL Server-instans. Om du ser I/O-relaterade väntetider när du tittar på väntestatistik är det ett logiskt nästa steg att titta på sys.dm_io_virtual_file_stats. Förstå dock att den information du visar är en sammansättning sedan statistiken senast rensades av en av de associerade händelserna (omstart av instans, databas offline, etc). Om du ser låga latenser hänger I/O-undersystemet med i prestandabelastningen. Men om du ser höga latenser är det inte en självklarhet att lagring är ett problem. För att verkligen veta vad som händer kan du börja ta stillbilder av filstatistik, som visas här, eller så kan du helt enkelt använda Performance Monitor för att titta på latens i realtid. Det är väldigt enkelt att skapa en datainsamlaruppsättning i PerfMon som fångar de fysiska diskräknarna Avg. Disk Sec/Read och Avg. Disk Sec/Read för alla diskar som är värd för databasfiler. Schemalägg datainsamlaren att starta och stoppa regelbundet och prova varje n sekunder (t.ex. 15), och när du har fångat PerfMon-data under en lämplig tid, kör den genom PAL för att undersöka latens över tid.
Om du upptäcker att I/O-latens inträffar under din normala arbetsbelastning, och inte bara under underhållsuppgifter som driver I/O, fortfarande kan inte peka på lagring som det underliggande problemet. Lagringsfördröjning kan finnas av en mängd olika anledningar, till exempel:
- SQL Server måste läsa för mycket data som ett resultat av ineffektiva frågeplaner eller saknade index
- För lite minne allokeras till instansen och samma data läses från disken om och om igen eftersom den inte kan stanna i minnet
- Implicita omvandlingar orsakar index- eller tabellsökningar
- Frågor utför SELECT * när inte alla kolumner krävs
- Problem med vidarebefordrade inspelningar i högar orsakar ytterligare I/O
- Låga siddensiteter från indexfragmentering, siddelningar eller felaktiga fyllfaktorinställningar orsakar ytterligare I/O
Oavsett grundorsaken, det som är viktigt att förstå om prestanda – särskilt när det gäller I/O – är att det sällan finns en datapunkt som du kan använda för att lokalisera problemet. Att hitta det sanna problemet kräver flera fakta som, när de sätts ihop, hjälper dig att avslöja problemet.
Slutligen, notera att i vissa fall kan lagringslatensen vara helt acceptabel. Innan du kräver snabbare lagring eller ändringar av kod, granska arbetsbelastningsmönstren och Service Level Agreement (SLA) för databasen. I fallet med ett Data Warehouse som tjänster rapporterar till användare, är SLA för frågor förmodligen inte samma värden på undersekund som du kan förvänta dig för ett OLTP-system med hög volym. I DW-lösningen kan I/O-latenser större än en sekund vara helt acceptabla och förväntade. Förstå företagets och dess användares förväntningar och bestäm sedan vilken åtgärd, om någon, du ska vidta. Och om ändringar krävs, samla in den kvantitativa data du behöver för att stödja ditt argument, nämligen väntestatistik, virtuell filstatistik och latenser från Performance Monitor.