ProxySQL sitter vanligtvis mellan applikations- och databasnivåerna, i så kallad omvänd proxynivå. När dina applikationsbehållare är orkestrerade och hanterade av Kubernetes, kanske du vill använda ProxySQL framför dina databasservrar.
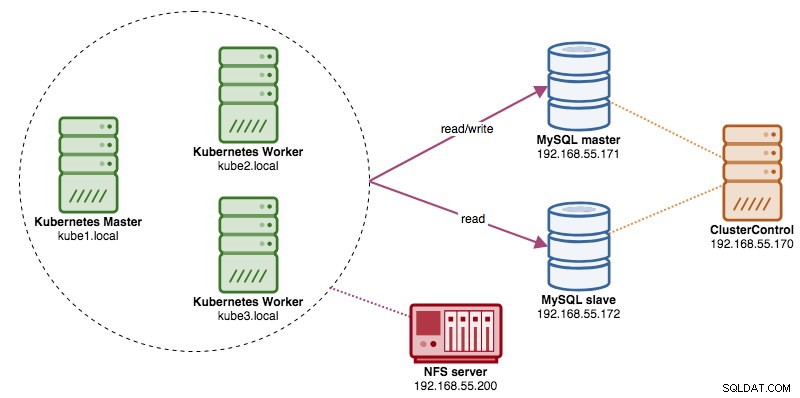
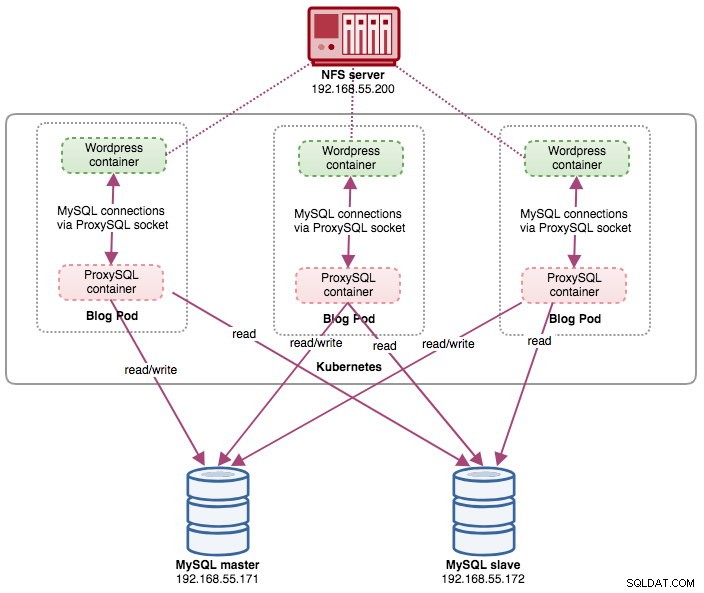
I det här inlägget kommer vi att visa dig hur du kör ProxySQL på Kubernetes som en hjälpbehållare i en pod. Vi kommer att använda Wordpress som exempelapplikation. Datatjänsten tillhandahålls av vår MySQL-replikering med två noder, som distribueras med ClusterControl och sitter utanför Kubernetes-nätverket på en barmetallinfrastruktur, som illustreras i följande diagram:
ProxySQL Docker Image
I det här exemplet kommer vi att använda ProxySQL Docker-avbildning som underhålls av Severalnines, en allmän allmän bild byggd för multi-purpose användning. Bilden kommer utan entrypoint-skript och stöder Galera Cluster (utöver inbyggt stöd för MySQL-replikering), där ett extra skript krävs för hälsokontrollsyften.
I grund och botten, för att köra en ProxySQL-behållare, kör du helt enkelt följande kommando:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlDen här bilden rekommenderar att du binder en ProxySQL-konfigurationsfil till monteringspunkten, /etc/proxysql.cnf, även om du kan hoppa över detta och konfigurera det senare med ProxySQL-administratörskonsolen. Exempel på konfigurationer finns på Docker Hub-sidan eller Github-sidan.
ProxySQL på Kubernetes
Att designa ProxySQL-arkitekturen är ett subjektivt ämne och i hög grad beroende av placeringen av applikationen och databasbehållarna samt rollen som ProxySQL själv. ProxySQL dirigerar inte bara frågor, den kan också användas för att skriva om och cache-förfrågningar. Effektiva cacheträffar kan kräva en anpassad konfiguration som är skräddarsydd specifikt för applikationsdatabasens arbetsbelastning.
Helst kan vi konfigurera ProxySQL för att hanteras av Kubernetes med två konfigurationer:
- ProxySQL som en Kubernetes-tjänst (centraliserad distribution).
- ProxySQL som en hjälpbehållare i en pod (distribuerad distribution).
Det första alternativet är ganska enkelt, där vi skapar en ProxySQL-pod och bifogar en Kubernetes-tjänst till den. Applikationer kommer sedan att ansluta till ProxySQL-tjänsten via nätverk på de konfigurerade portarna. Standard är 6033 för MySQL belastningsbalanserad port och 6032 för ProxySQL administrationsport. Den här implementeringen kommer att behandlas i det kommande blogginlägget.
Det andra alternativet är lite annorlunda. Kubernetes har ett koncept som kallas "pod". Du kan ha en eller flera behållare per pod, dessa är relativt tätt kopplade. En pods innehåll är alltid samlokaliserat och samschemalagt och körs i ett delat sammanhang. En pod är den minsta hanterbara containerenheten i Kubernetes.
Båda distributionerna kan enkelt särskiljas genom att titta på följande diagram:
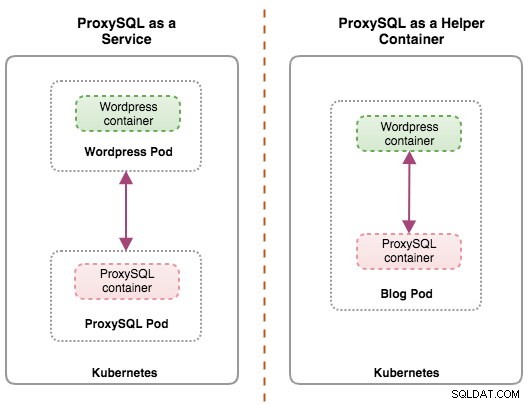
Det primära skälet till att poddar kan ha flera behållare är att stödja hjälpprogram som hjälper en primär applikation. Typiska exempel på hjälptillämpningar är datautdragare, datapådrivare och proxyservrar. Hjälpar- och primärapplikationer behöver ofta kommunicera med varandra. Vanligtvis görs detta genom ett delat filsystem, som visas i den här övningen, eller genom loopback-nätverksgränssnittet, localhost. Ett exempel på detta mönster är en webbserver tillsammans med ett hjälpprogram som söker efter nya uppdateringar i ett Git-förråd.
Det här blogginlägget kommer att täcka den andra konfigurationen - att köra ProxySQL som en hjälpbehållare i en pod.
ProxySQL som hjälpare i en Pod
I den här installationen kör vi ProxySQL som en hjälpbehållare till vår Wordpress-behållare. Följande diagram illustrerar vår högnivåarkitektur:
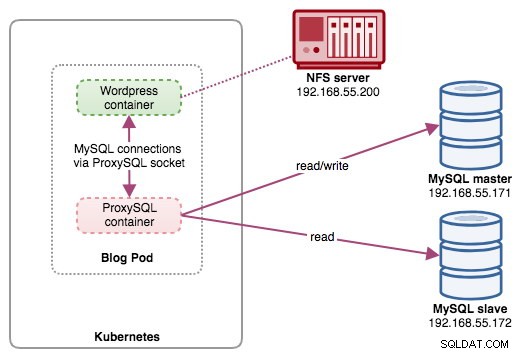
I den här installationen är ProxySQL-behållaren tätt kopplad till Wordpress-behållaren, och vi kallade den som "blogg"-pod. Om schemaläggning sker, t.ex. Kubernetes-arbetarnoden går ner, kommer dessa två behållare alltid att omschemaläggas tillsammans som en logisk enhet på nästa tillgängliga värd. För att hålla programbehållarnas innehåll beständigt över flera noder måste vi använda ett klustrade eller fjärranslutna filsystem, som i det här fallet är NFS.
ProxySQL-rollen är att tillhandahålla ett databasabstraktionslager till applikationsbehållaren. Eftersom vi kör en MySQL-replikering med två noder som backend-databastjänsten, är läs-skrivdelning avgörande för att maximera resursförbrukningen på båda MySQL-servrarna. ProxySQL utmärker sig på detta och kräver minimala eller inga ändringar av applikationen.
Det finns ett antal andra fördelar med ProxySQL i den här installationen:
- Ta med funktionen för cachning av frågor närmast applagret som körs i Kubernetes.
- Säker implementering genom att ansluta via ProxySQL UNIX-socketfil. Det är som ett rör som servern och klienterna kan använda för att ansluta och utbyta förfrågningar och data.
- Distribuerad omvänd proxynivå med delad ingenting-arkitektur.
- Mindre nätverkskostnader på grund av implementering av "hoppa över nätverk".
- Statslös distributionsmetod genom att använda Kubernetes ConfigMaps.
Förbereder databasen
Skapa wordpress-databasen och användaren på mastern och tilldela med rätt behörighet:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Skapa också ProxySQL-övervakningsanvändaren:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Ladda sedan om bidragstabellen:
mysql-master> FLUSH PRIVILEGES;Förbereder podden
Kopiera och klistra in följande rader i en fil som heter blog-deployment.yml på värden där kubectl är konfigurerad:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}YAML-filen har många rader och låt oss bara titta på den intressanta delen. Det första avsnittet:
apiVersion: apps/v1
kind: DeploymentDen första raden är apiVersion. Vårt Kubernetes-kluster körs på v1.12 så vi bör hänvisa till Kubernetes v1.12 API-dokumentation och följa resursdeklarationen enligt detta API. Nästa är den typ som talar om vilken typ av resurs vi vill distribuera. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume är några av exemplen.
Nästa viktiga avsnitt är avsnittet "behållare". Här definierar vi alla behållare som vi skulle vilja köra tillsammans i denna pod. Den första delen är Wordpress-behållaren:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpI det här avsnittet säger vi åt Kubernetes att distribuera Wordpress 4.9 med Apache webbserver och vi gav behållaren namnet "wordpress". Vi vill också att Kubernetes ska skicka ett antal miljövariabler:
- WORDPRESS_DB_HOST - Databasvärden. Eftersom vår ProxySQL-behållare finns i samma Pod som Wordpress-behållaren, är det säkrare att använda en ProxySQL-socket-fil istället. Formatet för att använda socketfilen i Wordpress är "localhost:{sökväg till socketfilen}". Som standard finns den under /tmp-katalogen i ProxySQL-behållaren. Den här /tmp-sökvägen delas mellan Wordpress- och ProxySQL-behållare genom att använda "shared-data" volymmounts som visas längre ner. Båda behållarna måste montera denna volym för att dela samma innehåll under /tmp-katalogen.
- WORDPRESS_DB_USER - Ange wordpress databasanvändare.
- WORDPRESS_DB_PASSWORD - Lösenordet för WORDPRESS_DB_USER . Eftersom vi inte vill avslöja lösenordet i den här filen kan vi dölja det med Kubernetes Secrets. Här instruerar vi Kubernetes att läsa den hemliga resursen "mysql-pass" istället. Hemligheter måste skapas i avancerat innan podden distribueras, som förklaras längre ner.
Vi vill också publicera port 80 i containern för slutanvändaren. Wordpress-innehållet som lagras inuti /var/www/html i behållaren kommer att monteras i vår beständiga lagring som körs på NFS.
Därefter definierar vi ProxySQL-behållaren:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlI avsnittet ovan säger vi åt Kubernetes att distribuera en ProxySQL med severalnines/proxysql bildversion 1.4.12. Vi vill också att Kubernetes ska montera vår anpassade, förkonfigurerade konfigurationsfil och mappa den till /etc/proxysql.cnf inuti behållaren. Det kommer att finnas en volym som heter "shared-data" som mappar till /tmp-katalogen för att dela med Wordpress-bilden - en tillfällig katalog som delar en pods livstid. Detta gör att ProxySQL-socket-filen (/tmp/proxysql.sock) kan användas av Wordpress-behållaren vid anslutning till databasen, utan att TCP/IP-nätverket förbigår.
Den sista delen är avsnittet "volymer":
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes måste skapa tre volymer för denna pod:
- wordpress-persistent-storage - Använd PersistentVolumeClaim resurs för att mappa NFS-export till behållaren för beständig datalagring för Wordpress-innehåll.
- proxysql-config - Använd ConfigMap resurs för att mappa ProxySQL-konfigurationsfilen.
- delad data - Använd emptyDir resurs för att montera en delad katalog för våra behållare inuti podden. emptyDir resurs är en tillfällig katalog som delar en pods livstid.
Därför måste vi, baserat på vår YAML-definition ovan, förbereda ett antal Kubernetes-resurser innan vi kan börja distribuera "blogg"-podden:
- PersistentVolume och PersistentVolumeClaim - För att lagra webbinnehållet i vår Wordpress-applikation, så när podden schemaläggs om till en annan arbetarnod, kommer vi inte att förlora de senaste ändringarna.
- Hemligheter - För att dölja Wordpress-databasens användarlösenord i YAML-filen.
- ConfigMap - För att mappa konfigurationsfilen till ProxySQL-behållaren, så när den schemaläggs till en annan nod, kan Kubernetes automatiskt montera om den igen.
PersistentVolume och PersistentVolumeClaim
En bra beständig lagring för Kubernetes bör vara tillgänglig för alla Kubernetes-noder i klustret. För det här blogginläggets skull använde vi NFS som leverantör av PersistentVolume (PV) eftersom det är enkelt och stöds direkt. NFS-servern finns någonstans utanför vårt Kubernetes-nätverk och vi har konfigurerat den för att tillåta alla Kubernetes-noder med följande rad inuti /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Observera att NFS-klientpaketet måste installeras på alla Kubernetes-noder. Annars skulle Kubernetes inte kunna montera NFS korrekt. På alla noder:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSSe också till att målkatalogen finns på NFS-servern:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressSkapa sedan en fil som heter wordpress-pv-pvc.yml och lägg till följande rader:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendI definitionen ovan vill vi att Kubernetes tilldelar 3 GB volymutrymme på NFS-servern för vår Wordpress-behållare. Notera för produktionsanvändning, NFS bör konfigureras med automatisk provisionerare och lagringsklass.
Skapa PV- och PVC-resurserna:
$ kubectl create -f wordpress-pv-pvc.ymlVerifiera om dessa resurser har skapats och statusen måste vara "Bound":
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hHemligheter
Den första är att skapa en hemlighet som ska användas av Wordpress-behållaren för WORDPRESS_DB_PASSWORD miljöfaktor. Anledningen är helt enkelt för att vi inte vill exponera lösenordet i klartext i YAML-filen.
Skapa en hemlig resurs som heter mysql-pass och skicka lösenordet därefter:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdVerifiera att vår hemlighet har skapats:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mConfigMap
Vi behöver också skapa en ConfigMap-resurs för vår ProxySQL-behållare. En Kubernetes ConfigMap-fil innehåller nyckel-värdepar av konfigurationsdata som kan konsumeras i pods eller användas för att lagra konfigurationsdata. Med ConfigMaps kan du koppla bort konfigurationsartefakter från bildinnehåll för att hålla applikationer i containers bärbara.
Eftersom vår databasserver redan körs på bare-metal-servrar med ett statiskt värdnamn och IP-adress plus statiskt användarnamn och lösenord för övervakning, kommer ConfigMap-filen i detta fall att lagra förkonfigurerad konfigurationsinformation om ProxySQL-tjänsten som vi vill använda.
Skapa först en textfil som heter proxysql.cnf och lägg till följande rader:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Var extra uppmärksam på avsnitten "mysql_servers" och "mysql_users", där du kan behöva ändra värdena så att de passar din databasklusterinställning. I det här fallet har vi två databasservrar som körs i MySQL-replikering som sammanfattas i följande Topology-skärmdump från ClusterControl:
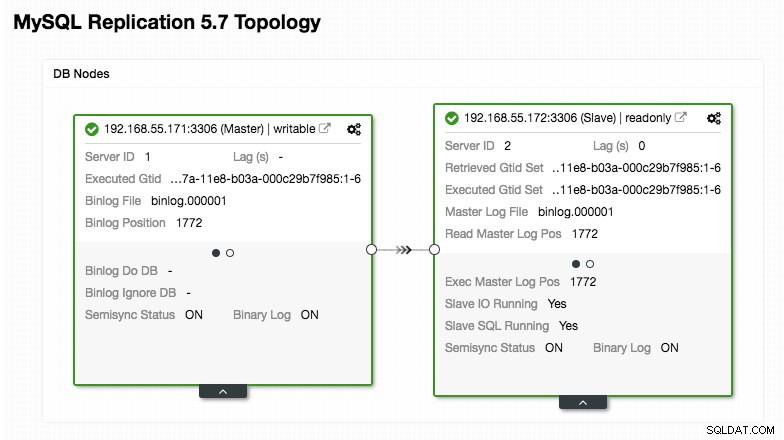
Alla skrivningar ska gå till masternoden medan läsningar vidarebefordras till värdgrupp 20, som definierats under avsnittet "mysql_query_rules". Det är grunden för läs/skrivdelning och vi vill använda dem helt och hållet.
Importera sedan konfigurationsfilen till ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdKontrollera om ConfigMap är inläst i Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sDistribuera Pod
Nu borde vi vara bra att distribuera bloggpodden. Skicka distributionsjobbet till Kubernetes:
$ kubectl create -f blog-deployment.ymlVerifiera poddens status:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sDen måste visa 2/2 under kolumnen READY, vilket indikerar att det finns två behållare som kör inuti poden. Använd flaggan -c för att kontrollera Wordpress- och ProxySQL-behållarna inuti bloggpodden:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlFrån ProxySQL-behållareloggen bör du se följande rader:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (skrivarvärdgrupp) måste bara ha en ONLINE-nod (indikerar en enda master) och den andra värden måste vara i åtminstone OFFLINE_HARD-status. För HID 20 förväntas den vara ONLINE för alla noder (vilket indikerar flera läsrepliker).
För att få en sammanfattning av distributionen, använd beskrivflaggan:
$ kubectl describe deployments blogVår blogg körs nu, men vi kan inte komma åt den utanför Kubernetes-nätverket utan att konfigurera tjänsten, som förklaras i nästa avsnitt.
Skapa bloggtjänsten
Det sista steget är att skapa bifoga en tjänst till vår pod. Detta för att säkerställa att vår Wordpress-bloggpod är tillgänglig från omvärlden. Skapa en fil som heter blog-svc.yml och klistra in följande rad:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendSkapa tjänsten:
$ kubectl create -f blog-svc.ymlKontrollera om tjänsten är korrekt skapad:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hPort 80 publicerad av bloggpodden är nu mappad till omvärlden via port 30080. Vi kan komma åt vårt blogginlägg på https://{any_kubernetes_host}:30080/ och bör omdirigeras till Wordpress installationssida. Om vi fortsätter med installationen skulle den hoppa över databasanslutningsdelen och direkt visa denna sida:
Det indikerar att vår MySQL- och ProxySQL-konfiguration är korrekt konfigurerad i filen wp-config.php. Annars skulle du omdirigeras till databaskonfigurationssidan.
Vår implementering är nu klar.
Hantera ProxySQL-behållare inuti en Pod
Failover och återställning förväntas hanteras automatiskt av Kubernetes. Till exempel, om Kubernetes-arbetaren går ner, kommer podden att återskapas i nästa tillgängliga nod efter --pod-eviction-timeout (standard är 5 minuter). Om behållaren kraschar eller dödas kommer Kubernetes att ersätta den nästan omedelbart.
Vissa vanliga hanteringsuppgifter förväntas vara annorlunda när de körs inom Kubernetes, som visas i nästa avsnitt.
Skala upp och ned
I ovanstående konfiguration distribuerade vi en replik i vår distribution. För att skala upp, ändra helt enkelt spec.replikorna värde i enlighet med detta genom att använda kommandot kubectl edit:
$ kubectl edit deployment blogDet kommer att öppna distributionsdefinitionen i en standardtextfil och helt enkelt ändra spec.replicas värde till något högre, till exempel "repliker:3". Spara sedan filen och kontrollera omedelbart utrullningsstatusen genom att använda följande kommando:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outVid det här laget har vi tre bloggpoddar (Wordpress + ProxySQL) som körs samtidigt i Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mVid det här laget ser vår arkitektur ut ungefär så här:
Observera att det kan kräva mer anpassning än vår nuvarande konfiguration för att köra Wordpress smidigt i en horisontell produktionsmiljö (tänk på statiskt innehåll, sessionshantering och annat). De ligger faktiskt utanför ramen för det här blogginlägget.
Procedurerna för nedskalning är liknande.
Konfigurationshantering
Konfigurationshantering är viktig i ProxySQL. Det är här magin händer där du kan definiera din egen uppsättning frågeregler för att göra frågecache, brandvägg och omskrivning. I motsats till vanlig praxis, där ProxySQL skulle konfigureras via administratörskonsolen och pressa in i persistens genom att använda "SAVE .. TO DISK", kommer vi att hålla oss till konfigurationsfiler endast för att göra saker mer portabla i Kubernetes. Det är anledningen till att vi använder ConfigMaps.
Eftersom vi förlitar oss på vår centraliserade konfiguration som lagras av Kubernetes ConfigMaps, finns det ett antal sätt att utföra konfigurationsändringar. För det första genom att använda kommandot kubectl edit:
$ kubectl edit configmap proxysql-configmapDet öppnar konfigurationen i en standardtextredigerare och du kan direkt göra ändringar i den och spara textfilen när den är klar. Annars, återskapa configmaps bör också göra:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfEfter att konfigurationen har tryckts in i ConfigMap, starta om kapseln eller behållaren som visas i avsnittet Servicekontroll. Att konfigurera behållaren via ProxySQL-administratörsgränssnittet (port 6032) kommer inte att göra den beständig efter omläggning av podden av Kubernetes.
Servicekontroll
Eftersom de två behållarna inuti en pod är tätt kopplade, är det bästa sättet att tillämpa ProxySQL-konfigurationsändringarna att tvinga Kubernetes att byta ut pod. Tänk på att vi har tre bloggpoddar nu efter att vi skalat upp:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mAnvänd följande kommando för att ersätta en pod i taget:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnVerifiera sedan med följande:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sDu kommer att märka att den senaste podden har startats om genom att titta på kolumnen AGE och RESTART, den kom med ett annat podnamn. Upprepa samma steg för de återstående baljorna. Annars kan du också använda kommandot "docker kill" för att döda ProxySQL-behållaren manuellt inuti Kubernetes-arbetarnoden. Till exempel:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes kommer då att ersätta den dödade ProxySQL-behållaren med en ny.
Övervakning
Använd kommandot kubectl exec för att köra SQL-satsen via mysql-klienten. Till exempel, för att övervaka frågesammanslutning:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Eller med en one-liner:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Genom att ändra SQL-satsen kan du övervaka andra ProxySQL-komponenter eller utföra administrativa uppgifter via denna administratörskonsol. Återigen, det kommer bara att kvarstå under ProxySQL-behållarens livstid och kommer inte att kvarstå om podden schemaläggs om.
Sluta tankar
ProxySQL har en nyckelroll om du vill skala dina applikationsbehållare och ha ett intelligent sätt att komma åt en distribuerad databasbackend. Det finns ett antal sätt att distribuera ProxySQL på Kubernetes för att stödja vår applikationstillväxt när den körs i stor skala. Det här blogginlägget täcker bara en av dem.
I ett kommande blogginlägg kommer vi att titta på hur man kör ProxySQL i ett centraliserat tillvägagångssätt genom att använda det som en Kubernetes-tjänst.