Databasschema är inget som är skrivet i sten. Det är designat för en given applikation, men då kan kraven förändras och kommer vanligtvis att förändras. Nya moduler och funktioner läggs till i applikationen, mer data samlas in, kod- och datamodellrefaktorering utförs. Därmed behovet av att modifiera databasschemat för att anpassa sig till dessa förändringar; lägga till eller ändra kolumner, skapa nya tabeller eller partitionera stora. Frågor förändras också när utvecklare lägger till nya sätt för användare att interagera med data - nya frågor kan använda nya, mer effektiva index så vi skyndar oss att skapa dem för att ge applikationen bästa databasprestanda.
Så, hur närmar vi oss bäst en schemaändring? Vilka verktyg är användbara? Hur minimerar man påverkan på en produktionsdatabas? Vilka är de vanligaste problemen med schemadesign? Vilka verktyg kan hjälpa dig att hålla koll på ditt schema? I det här blogginlägget kommer vi att ge dig en kort översikt över hur du gör schemaändringar i MySQL och MariaDB. Observera att vi inte kommer att diskutera schemaändringar i samband med Galera Cluster. Vi har redan diskuterat Total Order Isolation, Rolling Schema Upgrades och tips för att minimera påverkan från RSU i tidigare blogginlägg. Vi kommer också att diskutera tips och tricks relaterade till schemadesign och hur ClusterControl kan hjälpa dig att hålla koll på alla schemaändringar.
Typer av schemaändringar
Först till kvarn. Innan vi gräver in i ämnet måste vi förstå hur MySQL och MariaDB utför schemaändringar. Du förstår, en schemaändring är inte lika med en annan schemaändring.
Du kanske har hört talas om online-ändringar, omedelbara ändringar eller ändringar på plats. Allt detta är ett resultat av ett pågående arbete för att minimera effekten av schemaändringarna på produktionsdatabasen. Historiskt sett blockerade nästan alla schemaändringar. Om du utförde en schemaändring kommer alla frågor att börja hopa sig i väntan på att ALTER ska slutföras. Uppenbarligen innebar detta allvarliga problem för produktionsinstallationer. Visst, folk börjar genast leta efter lösningar, och vi kommer att diskutera dem senare i den här bloggen, eftersom de fortfarande är relevanta idag. Men också började arbetet med att förbättra MySQL:s förmåga att köra DDL:s (Data Definition Language) utan större inverkan på andra frågor.
Omedelbara ändringar
Ibland behövs det inte röra någon data i tabellutrymmet, eftersom allt som behöver ändras är metadata. Ett exempel här är att ta bort ett index eller byta namn på en kolumn. Sådana operationer är snabba och effektiva. Vanligtvis är deras inverkan begränsad. Det är dock inte utan inverkan. Ibland tar det några sekunder att utföra ändringen i metadata och en sådan ändring kräver ett metadatalås för att skaffas. Detta lås är per tabell, och det kan blockera andra operationer som ska utföras på denna tabell. Du kommer att se detta som "Väntar på tabellmetadatalås"-poster i processlistan.
Ett exempel på en sådan förändring kan vara omedelbar ADD COLUMN, introducerad i MariaDB 10.3 och MySQL 8.0. Det ger möjlighet att utföra denna ganska populära schemaändring utan dröjsmål. Både MariaDB och Oracle bestämde sig för att inkludera kod från Tencent Game som gör det möjligt att omedelbart lägga till en ny kolumn i tabellen. Detta är under vissa specifika förhållanden; kolumn måste läggas till som den sista, fulltextindex kan inte existera i tabellen, radformat kan inte komprimeras - du kan hitta mer information om hur omedelbar add-kolumn fungerar i MariaDB-dokumentationen. För MySQL kan den enda officiella referensen hittas på mysqlserverteam.com-bloggen, även om det finns en bugg för att uppdatera den officiella dokumentationen.
På platsändringar
Vissa av ändringarna kräver modifiering av data i tabellutrymmet. Sådana ändringar kan utföras på själva data, och det finns inget behov av att skapa en tillfällig tabell med en ny datastruktur. Sådana ändringar tillåter vanligtvis (men inte alltid) andra frågor som rör tabellen att utföras medan schemaändringen körs. Ett exempel på en sådan operation är att lägga till ett nytt sekundärt index i tabellen. Denna operation kommer att ta lite tid att utföra men kommer att tillåta att DML:er körs.
Ombyggnad av tabell
Om det inte går att göra en ändring på plats kommer InnoDB att skapa en tillfällig tabell med den nya, önskade strukturen. Den kopierar sedan befintliga data till den nya tabellen. Denna operation är den dyraste och det är troligt (även om det inte alltid händer) att låsa DML:erna. Som ett resultat av detta är en sådan schemaändring mycket svår att utföra på ett stort bord på en fristående server, utan hjälp av externa verktyg - vanligtvis har du inte råd att ha din databas låst under långa minuter eller till och med timmar. Ett exempel på en sådan operation skulle vara att ändra kolumndatatypen, till exempel från INT till VARCHAR.
Schemaändringar och replikering
Ok, så vi vet att InnoDB tillåter online-schemaändringar och om vi konsulterar MySQL-dokumentationen kommer vi att se att majoriteten av schemaändringarna (åtminstone bland de vanligaste) kan utföras online. Vad är anledningen till att ägna timmar av utveckling för att skapa onlineverktyg för schemaändring som gh-ost? Vi kan acceptera att pt-online-schema-change är en kvarleva från gamla, dåliga tider men gh-ost är en ny programvara.
Svaret är komplext. Det finns två huvudfrågor.
Till att börja med, när du väl startar en schemaändring har du inte kontroll över den. Du kan avbryta det men du kan inte pausa det. Du kan inte strypa den. Som du kan föreställa dig är att bygga om tabellen en dyr operation och även om InnoDB tillåter att DML:er exekveras, påverkar ytterligare I/O-arbetsbelastning från DDL alla andra frågor och det finns inget sätt att begränsa denna påverkan till en nivå som är acceptabel för ansökan.
För det andra, ännu allvarligare problem, är replikering. Om du utför en icke-blockerande operation, som kräver en tabellombyggnad, kommer den verkligen inte att låsa DML:er men detta gäller endast på mastern. Låt oss anta att en sådan DDL tog 30 minuter att slutföra - ALTER-hastigheten beror på hårdvaran men det är ganska vanligt att se sådana exekveringstider på tabeller med 20 GB storleksintervall. Den replikeras sedan till alla slavar och från det ögonblick som DDL startar på dessa slavar kommer replikeringen att vänta på att den ska slutföras. Det spelar ingen roll om du använder MySQL eller MariaDB, eller om du har flertrådig replikering. Slavar kommer att släpa - de kommer att vänta dessa 30 minuter för att DDL ska slutföras innan de börjar tillämpa de återstående binlog-händelserna. Som du kan föreställa dig är 30 minuters fördröjning (ibland är till och med 30 sekunder inte acceptabelt - allt beror på applikationen) något som gör det omöjligt att använda dessa slavar för utskalning. Naturligtvis finns det lösningar - du kan utföra schemaändringar från botten till toppen av replikeringskedjan, men detta begränsar dina alternativ allvarligt. Speciellt om du använder radbaserad replikering kan du bara utföra kompatibla schemaändringar på detta sätt. Ett par exempel på begränsningar av radbaserad replikering; du kan inte släppa någon kolumn som inte är den sista, du kan inte lägga till en kolumn på en annan position än den sista. Du kan inte också ändra kolumntyp (till exempel INT -> VARCHAR).
Som du kan se lägger replikering till komplexitet i hur du kan utföra schemaändringar. Operationer som är icke-blockerande på den fristående värden blir blockerande när de körs på slavar. Låt oss ta en titt på några metoder du kan använda för att minimera effekten av schemaändringar.
Verktyg för onlineschemaändring
Som vi nämnde tidigare finns det verktyg som är avsedda att utföra schemaändringar. De mest populära är pt-online-schema-change skapad av Percona och gh-ost, skapad av GitHub. I en serie blogginlägg jämförde vi dem och diskuterade hur gh-ost kan användas för att utföra schemaändringar och hur du kan strypa och omkonfigurera en pågående migrering. Här kommer vi inte att gå in på detaljer, men vi skulle ändå vilja nämna några av de viktigaste aspekterna av att använda dessa verktyg. Till att börja med kommer en schemaändring som exekveras genom pt-osc eller gh-ost att ske på alla databasnoder samtidigt. Det finns ingen som helst fördröjning när det gäller när ändringen kommer att tillämpas. Detta gör det möjligt att använda dessa verktyg även för schemaändringar som är inkompatibla med radbaserad replikering. De exakta mekanismerna för hur dessa verktyg spårar förändringar på tabellen är olika (triggers i pt-osc vs. binlog parsing i gh-ost) men huvudidén är densamma - en ny tabell skapas med det önskade schemat och befintliga data är kopierade från det gamla bordet. Under tiden spåras DML:er (på ett eller annat sätt) och tillämpas på den nya tabellen. När all data har migrerats döps tabellerna om och den nya tabellen ersätter den gamla. Detta är atomär drift så det är inte synligt för applikationen. Båda verktygen har en möjlighet att strypa belastningen och pausa operationerna. Gh-ost kan stoppa all aktivitet, endast pt-osc kan stoppa processen att kopiera data mellan gamla och nya tabeller - triggers förblir aktiva och de kommer att fortsätta duplicera data, vilket lägger till en del overhead. På grund av omdöpningstabellen har båda verktygen vissa begränsningar vad gäller främmande nycklar - stöds inte av gh-ost, stöds delvis av pt-osc antingen genom vanlig ALTER, vilket kan orsaka replikeringsfördröjning (inte genomförbart om den underordnade tabellen är stor) eller av släppa den gamla tabellen innan du byter namn på den nya - det är farligt eftersom det inte finns något sätt att återställa om data av någon anledning inte kopierades till den nya tabellen korrekt. Utlösare är också svåra att stödja.
De stöds inte i gh-ost, pt-osc i MySQL 5.7 och nyare har begränsat stöd för tabeller med befintliga triggers. Andra viktiga begränsningar för online-schemaändringsverktyg är att unik eller primär nyckel måste finnas i tabellen. Den används för att identifiera rader att kopiera mellan gamla och nya tabeller. Dessa verktyg är också mycket långsammare än direkt ALTER - en förändring som tar timmar när du kör ALTER kan ta dagar när den utförs med pt-osc eller ghost.
Å andra sidan, som vi nämnde, så länge som kraven är uppfyllda och begränsningar inte kommer in i bilden, kan du köra alla schemaändringar med hjälp av ett av verktygen. Allt kommer att hända samtidigt på alla värdar så du behöver inte oroa dig för kompatibilitet. Du har också en viss nivå av kontroll över hur processen exekveras (mindre i pt-osc, mycket mer i gh-ost).
Du kan minska effekten av schemaändringen, du kan pausa dem och låta dem köras endast under övervakning, du kan testa ändringen innan du faktiskt utför den. Du kan låta dem spåra replikeringsfördröjning och pausa om en påverkan upptäcks. Detta gör dessa verktyg till ett riktigt bra komplement till DBA:s arsenal när du arbetar med MySQL-replikering.
Rullande schemaändringar
Vanligtvis kommer en DBA att använda ett av onlineverktygen för schemaändring. Men som vi diskuterade tidigare, under vissa omständigheter kan de inte användas och en direkt förändring är det enda genomförbara alternativet. Om vi pratar om fristående MySQL har du inget val - om ändringen är icke-blockerande är det bra. Om det inte är det, ja, det finns inget du kan göra åt det. Men då är det inte så många som kör MySQL som enstaka instanser, eller hur? Vad sägs om replikering? Som vi diskuterade tidigare är direkt förändring på mastern inte möjlig - i de flesta fall kommer det att orsaka fördröjning på slaven och detta kanske inte är acceptabelt. Vad som dock kan göras är att genomföra förändringen på ett rullande sätt. Du kan börja med slavar och, när ändringen har tillämpats på dem alla, främja en av slavarna som en ny master, degradera den gamla mastern till en slav och verkställa förändringen på den. Visst, förändringen måste vara kompatibel, men ärligt talat är de vanligaste fallen där du inte kan använda schemaändringar online på grund av brist på primär eller unik nyckel. För alla andra fall finns det någon form av lösning, särskilt i pt-online-schema-change eftersom gh-ost har hårdare begränsningar. Det är en lösning som du skulle kalla "så så" eller "långt ifrån idealisk", men det kommer att göra jobbet om du inte har något annat alternativ att välja mellan. Vad som också är viktigt, de flesta av begränsningarna kan undvikas om du övervakar ditt schema och fångar problemen innan tabellen växer. Även om någon skapar en tabell utan en primärnyckel är det inga problem att köra en direkt ändring som tar en halv sekund eller mindre, eftersom tabellen nästan är tom.
Om det kommer att växa kommer detta att bli ett allvarligt problem, men det är upp till DBA att fånga upp den här typen av problem innan de faktiskt börjar skapa problem. Vi kommer att täcka några tips och tricks om hur du ser till att du kommer att fånga sådana problem i tid. Vi kommer också att dela med oss av allmänna tips om hur du utformar dina scheman.
Tips och tricks
Schemadesign
Som vi visade i det här inlägget är verktyg för online-schemaändring ganska viktiga när du arbetar med en replikeringsinställning, därför är det ganska viktigt att se till att ditt schema är utformat på ett sådant sätt att det inte begränsar dina alternativ för att utföra schemaändringar. Det finns tre viktiga aspekter. Först måste primär eller unik nyckel existera - du måste se till att det inte finns några tabeller utan en primärnyckel i din databas. Du bör övervaka detta regelbundet, annars kan det bli ett allvarligt problem i framtiden. För det andra bör du seriöst överväga om det är en bra idé att använda främmande nycklar. Visst, de har sina användningsområden men de lägger också till overhead till din databas och de kan göra det problematiskt att använda verktyg för schemaändring online. Relationer kan verkställas av ansökan. Även om det innebär mer arbete kan det ändå vara en bättre idé än att börja använda främmande nycklar och vara starkt begränsad till vilka typer av schemaändringar som kan utföras. För det tredje, triggers. Samma historia som med främmande nycklar. De är en trevlig egenskap att ha, men de kan bli en börda. Du måste seriöst överväga om vinsterna av att använda dem överväger de begränsningar de innebär.
Spåra schemaändringar
Schemaändringshantering handlar inte bara om att köra schemaändringar. Du måste också hålla koll på din schemastruktur, särskilt om du inte är den enda som gör ändringarna.
ClusterControl ger användare verktyg för att spåra några av de vanligaste schemadesignproblemen. Det kan hjälpa dig att spåra tabeller som inte har primärnycklar:
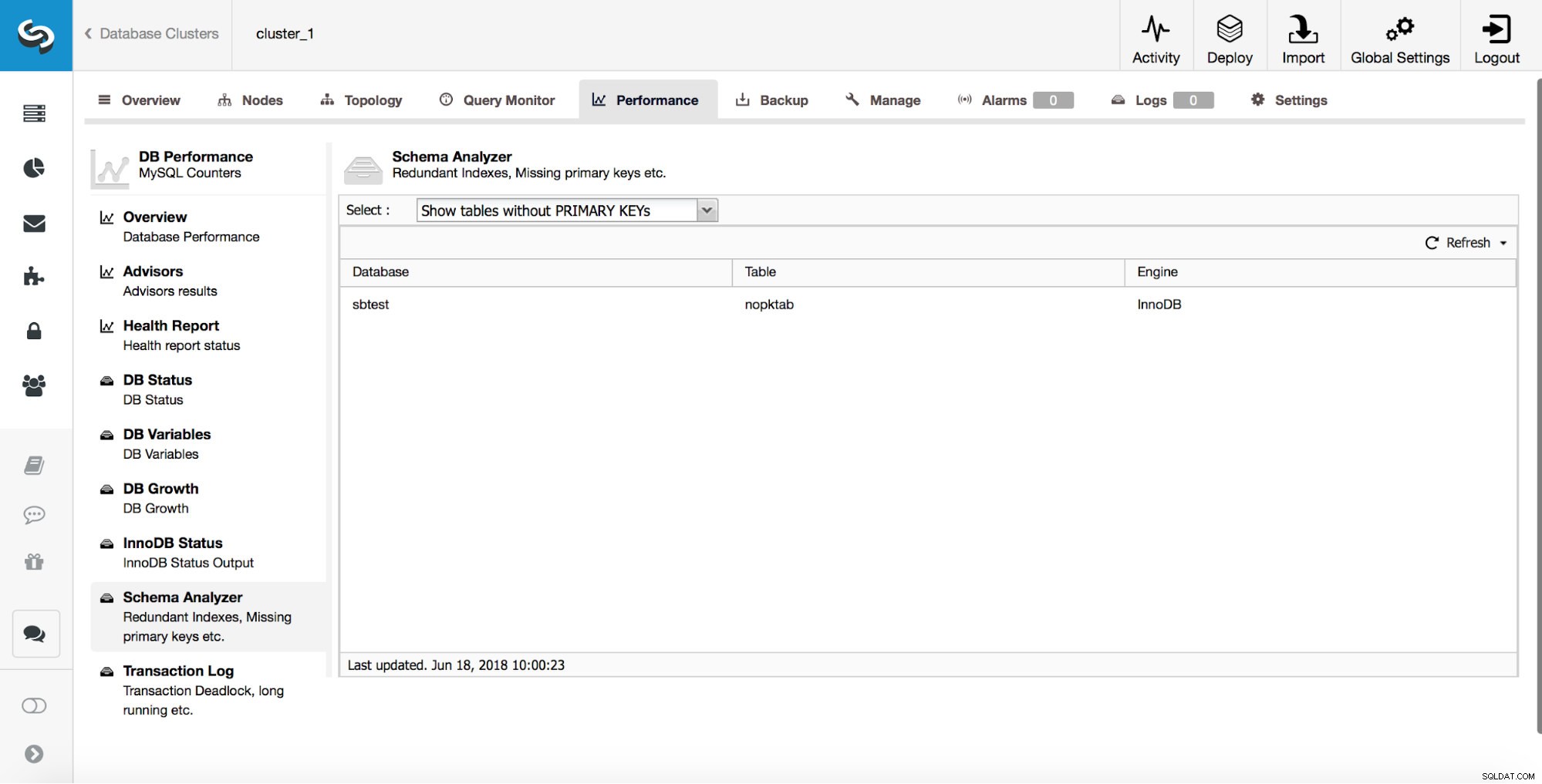
Som vi diskuterade tidigare är det mycket viktigt att fånga sådana tabeller tidigt eftersom primärnycklar måste läggas till med hjälp av direkt ändring.
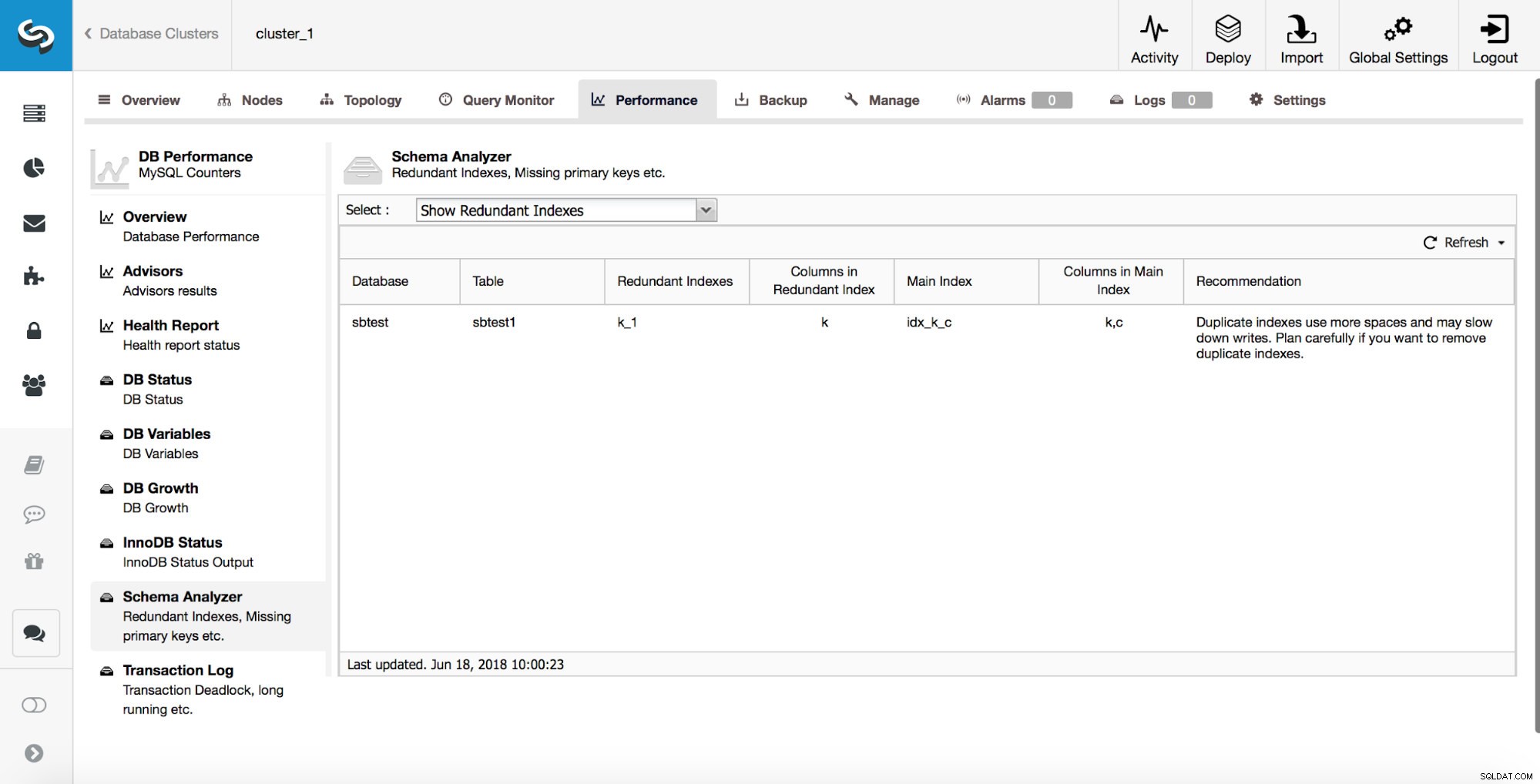
ClusterControl kan också hjälpa dig att spåra dubbletter av index. Vanligtvis vill du inte ha flera index som är överflödiga. I exemplet ovan kan du se att det finns ett index på (k, c) och det finns också ett index på (k). Alla frågor som kan använda index skapat på kolumn 'k' kan också använda ett sammansatt index skapat på kolumner (k, c). Det finns fall där det är fördelaktigt att hålla redundanta index men du måste närma dig det från fall till fall. Med utgångspunkt från MySQL 8.0 är det möjligt att snabbt testa om ett index verkligen behövs eller inte. Du kan göra ett redundant index "osynligt" genom att köra:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 INVISIBLE;Detta kommer att få MySQL att ignorera det indexet och genom övervakning kan du kontrollera om det fanns någon negativ inverkan på databasens prestanda. Om allt fungerar som planerat under en tid (ett par dagar eller till och med veckor), kan du planera att ta bort det överflödiga indexet. Om du upptäckte att något inte stämmer kan du alltid återaktivera detta index genom att köra:
ALTER TABLE sbtest.sbtest1 ALTER INDEX k_1 VISIBLE;Dessa operationer är omedelbara och indexet finns där hela tiden och bibehålls fortfarande - det är bara det att det inte kommer att beaktas av optimeraren. Tack vare det här alternativet blir det mycket säkrare att ta bort index i MySQL 8.0. I de tidigare versionerna kunde det ta timmar om inte dagar på stora bord att lägga till ett felaktigt borttaget index igen.
ClusterControl kan också informera dig om MyISAM-tabeller.
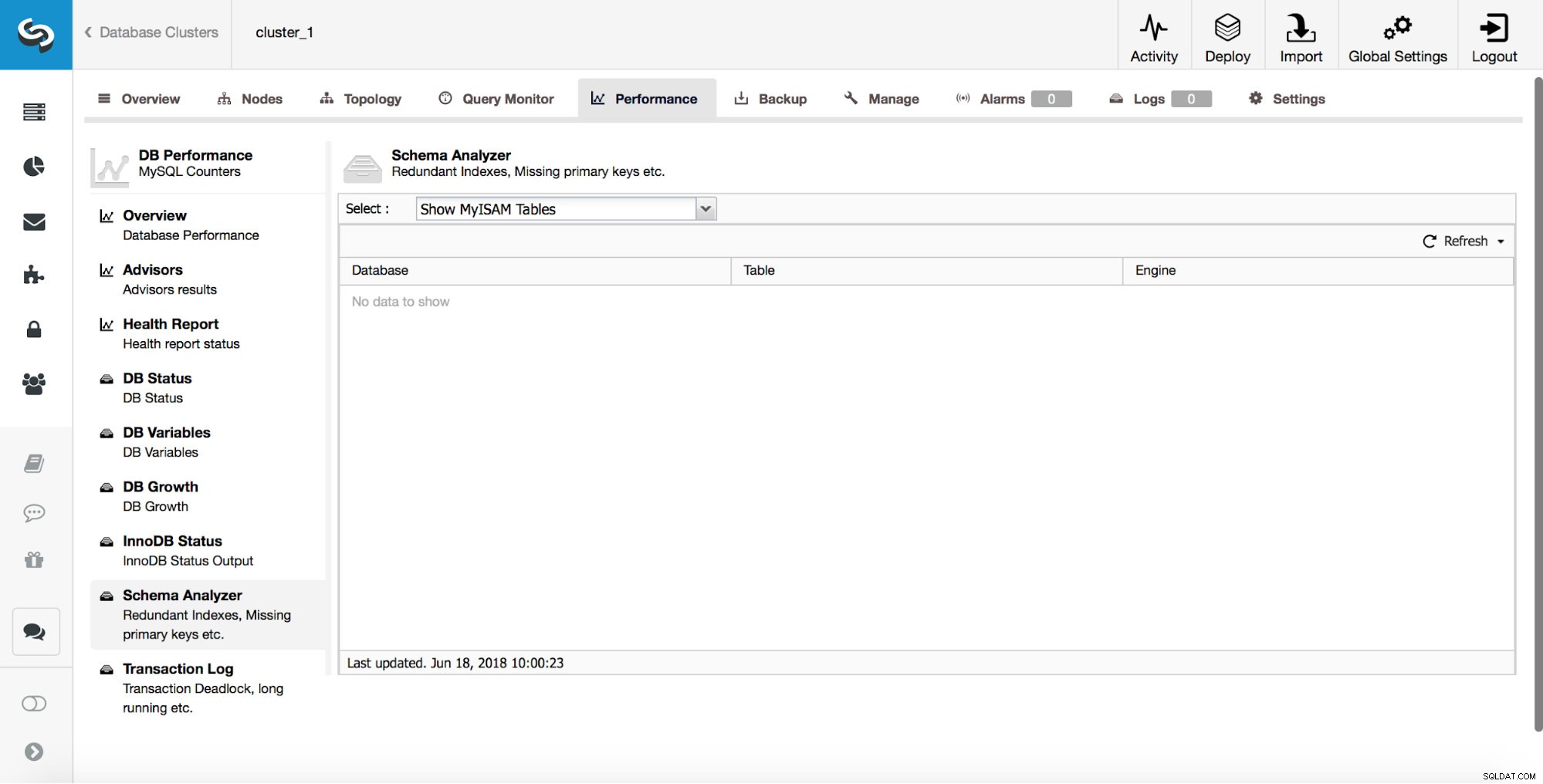
Även om MyISAM fortfarande kan ha sina användningsområden, måste du komma ihåg att det inte är en transaktionslagringsmotor. Som sådan kan det enkelt introducera datainkonsekvens mellan noder i en replikeringsinställning.
En annan mycket användbar funktion i ClusterControl är en av driftsrapporterna - en Schema Change Report.
I en idealisk värld granskar, godkänner och implementerar en DBA alla schemaändringar. Tyvärr är det inte alltid så. En sådan granskningsprocess går helt enkelt inte bra med agil utveckling. Utöver det är förhållandet mellan utvecklare och DBA vanligtvis ganska högt, vilket också kan bli ett problem eftersom DBA:er skulle kämpa för att inte bli en flaskhals. Det är därför det inte är ovanligt att se schemaändringar utföras utanför DBA:s kunskap. Ändå är DBA vanligtvis den som är ansvarig för databasens prestanda och stabilitet. Tack vare Schema Change Report kan de nu hålla reda på schemaändringarna.
Först krävs viss konfiguration. I en konfigurationsfil för ett givet kluster (/etc/cmon.d/cmon_X.cnf) måste du definiera på vilken värd ClusterControl ska spåra ändringarna och vilka scheman som ska kontrolleras.
schema_change_detection_address=10.0.0.126
schema_change_detection_databases=sbtestNär det är gjort kan du schemalägga en rapport som ska köras regelbundet. Ett exempel på utdata kan vara som nedan:
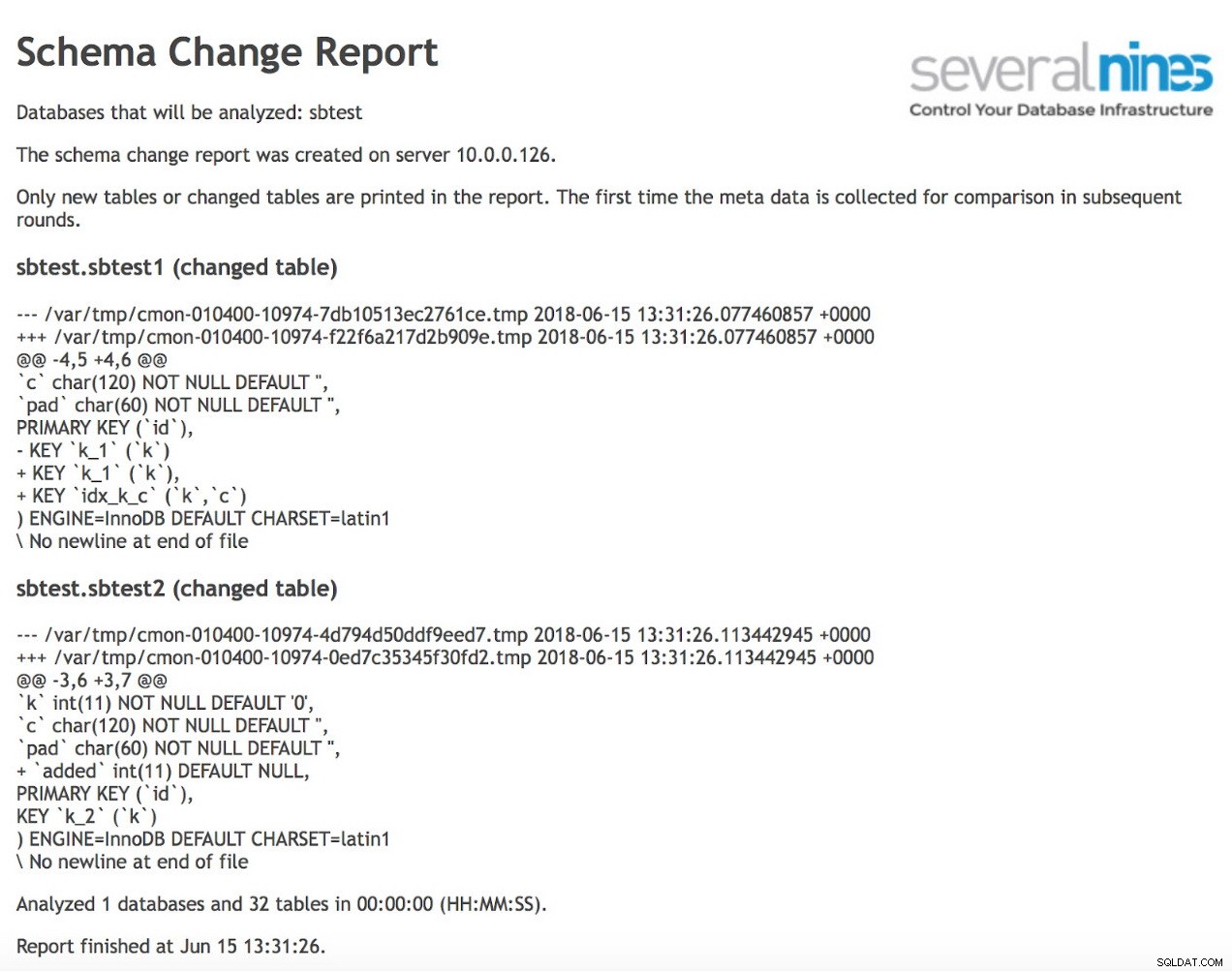
Som du kan se har två tabeller ändrats sedan föregående körning av rapporten. I den första har ett nytt sammansatt index skapats på kolumner (k, c). I den andra tabellen lades en kolumn till.
I den efterföljande körningen fick vi information om ny tabell, som skapades utan något index eller primärnyckel. Med hjälp av den här typen av information kan vi enkelt agera när det behövs och lösa problemen innan de faktiskt börjar bli blockerare.