SQL Server förser oss med ett antal lösningar för hög tillgänglighet och katastrofåterställning som hjälper till att göra data som betjänar de kritiska systemen tillgänglig under längsta möjliga tid med minsta möjliga driftstopp. Dessa lösningar för hög tillgänglighet och katastrofåterställning som tillhandahålls av Microsoft SQL Server diskuteras i artikeln SQL Server Transaction Log and High Availability Solutions.
I den här artikeln kommer vi att visa hur du ställer in och konfigurerar en tillgänglighetsgruppsajt och konfigurerar den för att uppfylla företagets krav. Men låt oss börja med en kort översikt över funktionen Always-on Availability Group för att bli bekanta med den.
Översikt
SQL Server Always-on Availability Group, introducerad i SQL Server 2012-versionen, är en hög tillgänglighets- och katastrofåterställningslösning på företagsnivå som är byggd över Windows Server Failover Clustering-funktionen, där en eller flera databaser kan fungera som en tillgänglighetsgrupp och misslyckades som en enda enhet.
Tillgänglighetsgruppen är en behållare för en uppsättning databaser som finns i en primär replik, innehåller läs-skrivkopian av databaserna och synkroniserad med upp till åtta sekundära repliker, innehåller en skrivskyddad kopia av dessa databaser.
Som ett alternativ till databasspeglingsfunktionen kan Always on Availability Group användas för att minska belastningen på den primära instansen genom att konfigurera de sekundära replikerna för att hantera skrivskyddad arbetsbelastning och säkerhetskopiering. På detta sätt kan Always-on Availability Group användas för att förbättra tillgängligheten för databaserna och förbättra SQL Server-resursutnyttjandet för alla repliker.
Synkroniseringsprocessen mellan Tillgänglighetsgruppens repliker kan utföras i ett av två tillgängliga lägen som stöds:
- Synchronous-commit-läge :I det här tillgänglighetsläget väntar den primära repliken på att de sekundära replikerna, upp till två synkrona sekundära repliker, bekräftar att loggen skrivits i sin databastransaktionsloggfil, innan den utförs vid den primära repliken. Detta tillgänglighetsläge ökar datatillgänglighetsnivån över transaktionslatenspriset.
- Asynkront commit-läge :Detta tillgänglighetsläge används huvudsakligen för att synkronisera med katastrofåterställningsreplikerna, som är distribuerade över distanserade datacenter, där den primära repliken inte väntar på de sekundära replikerna, för att bekräfta att loggen hårdnar för att utföra transaktionen på primärsidan, vilket ger mindre data tillgänglighetsnivå och färre transaktionsfördröjningar.
Always-on Availability Groups failover-processen, där den primära rollen kommer att ändras mellan replikerna, kan utföras manuellt av databasadministratören eller automatiskt av SQL Servern själv i händelse av något fel på servernivå, med hänsyn till att detta failover kommer inte att ske i händelse av problem på databasnivå som databaskorruption.
För varje tillgänglighetsgrupp kan ett servernamn skapas för att ge klienterna möjlighet att ansluta direkt till den primära repliken eller de skrivskyddade replikerna utan att återkalla de underliggande SQL Server-instansernas namn och roller inom tillgänglighetsgruppen. Detta servernamn kallas Availability Group Listener .
Demo-scenario
Efter att ha gett en kort introduktion av funktionen Alltid-på-tillgänglighetsgrupp är vi redo att konfigurera en tillgänglighetsgrupp och konfigurera den korrekt. I den här demon kommer vi att skapa en tillgänglighetsgrupp för att replikera AdventureWorks2017-databasen mellan två SQL Server-instanser; SQL1 och SQL2, med SQL Server 2017 redan installerad på dessa servrar.
För test- och demoändamål körs SQL Server Services i både SQL1- och SQL2-instanser under tjänstekontot ay\sqladmin, som har rätt behörighet för dessa SQL Server-instanser.
Komma igång
Som nämnts i översikten av den här artikeln är funktionen Always-on Availability Group byggd över Windows Server Failover Cluster-funktionen. Så vi måste skapa en failover-klustringsplats över vilken vi kommer att definiera tillgänglighetsgruppens webbplats.
Skapa ett failover-kluster
Först och främst måste vi se till att funktionen Failover Clustering är installerad på alla repliker som kommer att delta på Availability Group-webbplatsen. Detta kan utföras genom att öppna serverhanterarens instrumentpanel på varje replik och välja alternativet Lägg till roller och funktioner på menyn Hantera, kontrollera och installera sedan Failover Clustering funktion från den guiden, som visas nedan:

När du har installerat funktionen Failover Cluster öppnar du Failover Cluster Manager fönster i en av replikerna, med hjälp av ett auktoriserat lokalt administratörskonto med domänadministratörsbehörighet som gör att det kan skapa det klusternamnet i den aktiva katalogen och klicka på Skapa kluster alternativ, enligt nedan:
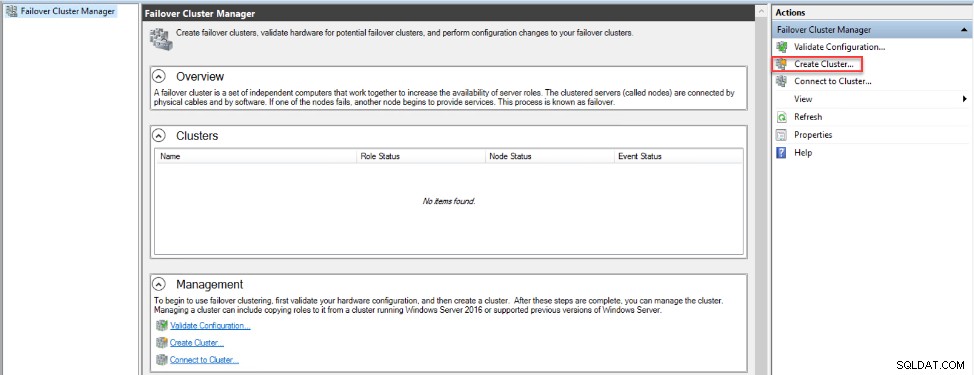
Från den öppnade Create Cluster Wizard , kontrollera instruktionerna i Innan du börjar fönstret och klicka på Nästa för att fortsätta:

På nästa sida anger du namnet eller IP-adressen för replikerna som kommer att delta i tillgänglighetsgruppen och klicka sedan på nästa för att fortsätta:

Efter det måste du ange om du vill köra klustervalideringstestet, för att verifiera att de tillgängliga resurserna på dessa servrar är kompatibla med funktionen Failover Cluster, innan du skapar Failover Cluster eller inte. Det rekommenderas alltid att utföra valideringstestet i det steget innan du försöker skapa Failover Cluster-webbplatsen.

Detta leder dig till Validera en konfigurationsguide . På den första sidan av valideringsguiden kontrollerar du guidens instruktioner och klickar på Nästa för att fortsätta:

Efter det måste du ange om du vill köra alla valideringar av Failover Cluster, vilket är det rekommenderade alternativet, eller välja specifika snabbare tester. I den här demon kommer vi att använda det av Microsoft rekommenderade alternativet och utföra alla valideringstester, klicka sedan på Nästa för att fortsätta:

Och du kan granska valideringstesterna som kommer att utföras i den här valideringsguiden och bekräfta att du fortsätter genom att klicka på Nästa , enligt följande:

När valideringsprocessen är klar kan du klicka på knappen Visa rapport för att granska valideringstestresultatet eller exportera det till en annan ingenjör för att åtgärda eventuella problem, eller klicka på Slutför direkt för att starta processen för att skapa kluster enligt nedan:

För närvarande kontrollerade vi att våra servrar är kompatibla med funktionskraven för Failover Clustering och vi kan fortsätta att skapa Failover Clustering-webbplatsen. I Åtkomstpunkten för att administrera klustret fönster, ange ett unikt namn och IP-adress för failover-klustret och klicka sedan på Nästa för att fortsätta:

Efter det, granska inställningarna för att skapa kluster som du anger och se till att ta bort bocken bredvid Lägg till all kvalificerad lagring i klustret , eftersom funktionen Always on Availability Group fungerar med dedikerad lagring för varje server och INTE delad lagring. Om du är bra med inställningarna klickar du på Nästa för att fortsätta:

När sajten för Failover Clustering har skapats framgångsrikt kommer guiden att meddela dig med ett meddelande om att Failover Clustering-webbplatsen har skapats helt, enligt nedan:

Du kan verifiera att Failover Cluster-webbplatsen har skapats framgångsrikt genom att öppna Failover Cluster Manager, som visar dig den skapade klusterplatsen och alla komponenter i det klustret enligt nedan:

För att hålla Failover Cluster-webbplatsen i bästa tillgänglighetsläge, måste du konfigurera klustret Quorum som styr när det ska hållas Failover Cluster online eller aktivera det offline baserat på noderna och resursrösterna. För att konfigurera klustrets kvorum högerklickar du på klusternamnet under Failover Cluster Manager och väljer Konfigurera klusterkvoruminställningar alternativet från Fler åtgärder menyn, enligt nedan. För detaljerad information om kvoruminställningarna som passar funktionen Always on Availability Group, kolla Windows Failover Cluster Quorum Modes i SQL Server Always On Availability Groups:

Aktivera funktionen Alltid på tillgänglighetsgrupp
Efter att ha skapat Failover-klustret, över vilket Availability Group kommer att skapas, måste vi aktivera funktionen Always-on Availability Group och ansluta den till Failover Cluster-webbplatsen som kommer att användas.
För att aktivera funktionen Always-on Availability Group, öppna SQL Server Configuration Manager -> SQL Server Services och högerklicka sedan på SQL Server-tjänsten och välj alternativet Egenskaper. Från egenskapsfönstret för SQL Server Service, flytta till Always-on Availability sida och kontrollera "Aktivera alltid på tillgänglighetsgrupper ” under det automatiskt upptäckta failover-klusternamnet, som visas nedan:

Tänk på att denna ändring bör utföras på alla repliker som kommer att delta i tillgänglighetsgruppen och kommer att träda i kraft efter att SQL Server-tjänsten startas om, enligt nedan:

Skapa ny Alltid-på-tillgänglighetsgrupp
Efter att ha aktiverat funktionen Alltid-på-tillgänglighetsgrupp kommer vi att börja skapa den nya tillgänglighetsgruppen genom att utöka noden Alltid-på-hög tillgänglighet, under SSMS-objektutforskaren, högerklicka sedan på noden Tillgänglighetsgrupper och välj Ny Tillgänglighetsgruppsguide , som visas nedan:

Den första sidan i Guiden Ny tillgänglighetsgrupp är introduktionssidan, där du kan hitta en kort beskrivning av de steg som kommer att utföras under denna guide för att skapa en ny tillgänglighetsgrupp. Granska den medföljande sammanfattningen och klicka sedan på Nästa för att fortsätta:

I Ange alternativ för tillgänglighetsgrupp fönstret måste du ange namnet på tillgänglighetsgruppen, typen av kluster, baserat på SQL Server-versionen och operativsystemet som används på replikerna, där du kan välja från Windows Server Failover Clustering , icke-Windows EXTERN kluster eller INGEN om inget kluster används.
På den här sidan kan du också aktivera hälsodetektering på databasnivå alternativet, som kontrollerar när en databas inte längre är i onlinestatus, och utför den automatiska failover av tillgänglighetsgruppen och aktiverar de distribuerade transaktionerna i tillgänglighetsgrupper för varje databas, som visas nedan:

Efter det måste du välja databasen/databaserna som ska delta i den tillgänglighetsgruppen. Guiden kommer att kontrollera förhandsbegäranden för databasen för att läggas till i gruppen Tillgänglighet, inklusive modellen för fullständig återställning av databasen och att en fullständig säkerhetskopia tas från databasen innan den läggs till. När du har uppfyllt kraven för att databasen/databaserna ska inkluderas, uppdatera databasen, kontrollera databasen och klicka sedan på Nästa för att fortsätta:

På nästa sida, under Repliker fliken måste du lägga till alla SQL Server-repliker som kommer att delta i denna tillgänglighetsgrupp och vara värd för en kopia från de inkluderade databaserna. Efter att du har lagt till replikerna kan du välja att upp till tre instanser ska konfigureras med tillgänglighetsläget Synchronous commit och tillåta automatisk failover mellan dessa repliker och resten av replikerna som kommer att konfigureras med asynkront commit-läge. Du kan också bestämma om du vill konfigurera varje replik som läsbar sekundär för skrivskyddade anslutningar eller läsbar replika för att hantera skrivskyddad arbetsbelastning som styrs automatiskt av lyssnaren, som visas nedan:

På fliken Endpoints kontrollerar du inställningarna för anslutningsändpunkterna som kommer att användas för kommunikationen mellan replikerna, där du måste se till att den använda TCP-porten är aktiverad i brandväggsreglerna för alla repliker och att det tillhandahållna tjänstkontot har Anslut behörighet för replikernas slutpunkt, enligt nedan:

På fliken Säkerhetskopieringsinställningar måste du ange platsen där säkerhetskopieringsjobben ska utföras i tillgänglighetsgruppen. Det låter dig utföra en automatisk säkerhetskopiering från den sekundära repliken som ett föredraget alternativ, den sekundära som ett måste, den primära som ett måste eller vilken replik som helst. Baserat på detta alternativ kan du skapa underhållsplanen för att ta en säkerhetskopia från databaserna som deltar i tillgänglighetsgruppen, enligt nedan:

Från samma fönster kan du också definiera inställningarna för tillgänglighetsgruppslyssnare, under Lyssnarsidan eller fortsätta utan att skapa lyssnaren för nu och utföra skapandet senare. I den här demon kommer vi att konfigurera lyssnaren efter att ha skapat tillgänglighetsgruppen, som visas nedan:

Du kan också använda sidan Skrivskyddad routing för att definiera den skrivskyddade routinglistan, som används för att kontrollera skrivskyddad arbetsbelastning inom sekundärerna. För mer information, se Hur man konfigurerar skrivskyddad routing för en tillgänglighetsgrupp i SQL Server 2016:

På nästa sida måste du ange mekanismen som kommer att användas för den initiala datasynkroniseringsprocessen mellan de primära och sekundära replikerna, med möjligheten att utföra synkroniseringen automatiskt eller manuellt genom att gå med den sekundära till tillgänglighetsgruppen och synkronisera databaserna senare manuellt.
Det finns två automatiska synkroniseringsmetoder tillgängliga i den guiden, den första är att specificera en delad mapp för att kopiera hela säkerhetskopiorna och transaktionsloggen tillfälligt och utföra återställningen automatiskt, som vi kommer att använda här i den här demon, eller använda en Direct Seeding-metod utan ta backup, enligt beskrivningen i SQL Server 2016 Always On Availability Group med Direct Seeding:

För att använda fullständig databas och loggsäkerhetskopiering metod måste vi skapa en delad mapp och tillhandahålla SQL Server-tjänsterna för replikerna läs- och skrivbehörigheter för den mappen, som visas nedan:

Därefter kommer guiden New Availability Group att utföra en valideringskontroll för all konfiguration innan du fortsätter med processen för att skapa tillgänglighetsgrupp. Om det finns något fel kan du fixa det direkt och sedan uppdatera sidan och klicka på Nästa för att fortsätta:

I det sista skedet kommer guiden att ge dig en sammanfattning för alla guidekonfigurationer för att granska den och klicka sedan på Slutför för att börja skapa tillgänglighetsgruppen, enligt nedan:

När guiden är klar kommer den att visa dig resultatet av varje steg och om det finns något fel. Annars kommer det att visa ett meddelande om att tillgänglighetsgruppen har skapats utan problem, som visas nedan:

Du kan också validera att gruppen Alltid på tillgänglighet har skapats och konfigurerats framgångsrikt med hjälp av SSMS-objektutforskaren, genom att kontrollera att de deltagande databaserna är i synkroniserat tillstånd i alla repliker och att replikerna och databaserna är online under Alltid-på High Availability nod, som visas nedan:

Du kan också ansluta till den primära repliken, med det primära ordet bredvid namnet på tillgänglighetsgruppen, och kontrollera egenskapssidan för tillgänglighetsgrupp, med möjligheten att utföra samma uppgifter som vi utförde under guiden New Availability Group, som att lägga till nya repliker , lägga till ny databas, ändra varje replikkonfiguration, ändra inställningarna för säkerhetskopiering och definiera en skrivskyddad ruttlista, som visas nedan:

Skapa Always-on Availability Group Listener
Det sista steget i att konfigurera tillgänglighetsgruppen är att skapa tillgänglighetsgruppavlyssnaren som kommer att användas vid anslutning till de primära och sekundära replikerna utan att ange replikens namn.
För att skapa tillgänglighetsgruppslyssnaren högerklickar du på Availability Group Listener-noden under den skapade tillgänglighetsgruppsnoden och väljer Lägg till lyssnare alternativ. Från den öppnade New Availability Group Listener fönster, ange namnet på den lyssnaren, TCP-porten som kommer att användas för att ansluta till den lyssnaren och den statiska IP-adressen som kommer att tilldelas lyssnaren och klicka sedan på OK att skapa den. När lyssnaren har skapats framgångsrikt stängs fönstret automatiskt och lyssnarens namn kommer att visas under Lyssnarnoden, som visas nedan:

För att ansluta till Availability Group med lyssnarnamnet, ange lyssnarens namn eller IP med TCP-portnumret i Connect to Server och den kommer att ansluta direkt till den primära noden, som visas nedan:

Testa failover-processen
Efter att ha testat anslutningen till Availability Group-avlyssnaren och replikerna måste vi utföra ett viktigt test för failover, för att säkerställa att den primära rollen kommer att flyttas mellan replikerna utan problem, och att databaserna kommer att vara tillgängliga och i det synkroniserade tillståndet efter failover.
För att utföra en manuell failover, högerklicka på tillgänglighetsgruppens namn och välj Failover alternativ, enligt nedan:

Den första sidan i Failover Availability Group guiden är introduktionssidan som ger en sammanfattning av de åtgärder som kan utföras i den guiden. Granska introduktionen och klicka på Nästa för att fortsätta:

På nästa sida, välj vilken nod som ska fungera som den nya primära repliken, se till att ingen dataförlust inträffar när failover-operationen utförs, klicka sedan på Nästa för att fortsätta:

Därefter bör du ansluta till den nya primära repliken som du väljer för att se till att denna replik är online och nåbar, som visas nedan:

Granska sedan dina val i Failover-guiden på sammanfattningssidan och klicka på Slutför för att starta Failover-processen:

När failoveren är klar, granska resultatsidan för att se till att det inte finns några problem under failover-processen, enligt nedan:

Från SSMS-objektutforskaren kommer rollen för SQL1-repliken att ändras direkt till Sekundär, som visas nedan:

I den här artikeln beskrev vi i detalj stegen som bör utföras för att förbereda för skapandet av webbplatsen för tillgänglighetsgruppen och hur du skapar och konfigurerar webbplatsen för alltid tillgänglig tillgänglighetsgrupp. I nästa artikel kommer vi att se hur du felsöker de problem som du kan möta med en befintlig tillgänglighetsgruppsajt. Håll utkik.