Galera Cluster kommer med många anmärkningsvärda funktioner som inte är tillgängliga i standard MySQL-replikering (eller gruppreplikering); automatisk nodprovisionering, äkta multimaster med konfliktlösningar och automatisk failover. Det finns också ett antal begränsningar som potentiellt kan påverka klustrets prestanda. Lyckligtvis, om du inte är medveten om dessa, finns det lösningar. Och om du gör det rätt kan du minimera effekten av dessa begränsningar och förbättra den övergripande prestandan.
Vi har tidigare täckt många tips och tricks relaterade till Galera Cluster, inklusive att köra Galera på AWS Cloud. Det här blogginlägget dyker tydligt ner i prestandaaspekterna, med exempel på hur du får ut det mesta av Galera.
Replikeringsnyttolast
Lite introduktion - Galera replikerar skrivuppsättningar under commit-stadiet, och överför skrivuppsättningar från ursprungsnoden till mottagarnoderna synkront genom wsrep-replikeringsplugin. Denna plugin kommer också att certifiera skrivuppsättningar på mottagarnoderna. Om certifieringsprocessen går igenom, återgår den OK till klienten på ursprungsnoden och kommer att tillämpas på mottagarnoderna vid ett senare tillfälle asynkront. Annars kommer transaktionen att rullas tillbaka på ursprungsnoden (returfel till klienten) och skrivuppsättningarna som har överförts till mottagarnoderna kommer att kasseras.
En skrivuppsättning består av skrivoperationer inuti en transaktion som ändrar databastillståndet. I Galera Cluster, autocommit är standard på 1 (aktiverad). Bokstavligen kommer alla SQL-satser som körs i Galera Cluster att inkluderas som en transaktion, såvida du inte uttryckligen börjar med BEGIN, START TRANSACTION eller SET autocommit=0. Följande diagram illustrerar inkapslingen av en enda DML-sats i en skrivuppsättning:
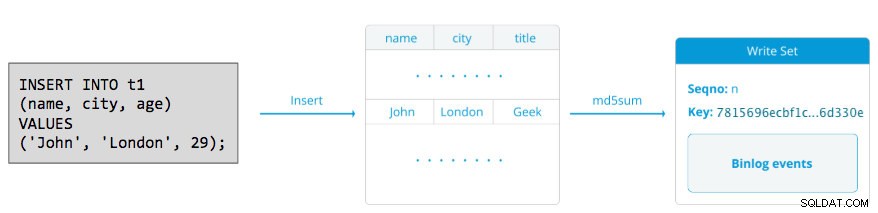
För DML (INSERT, UPDATE, DELETE..) består skrivuppsättningens nyttolast av de binära logghändelserna för en viss transaktion, medan för DDL:er (ALTER, GRANT, CREATE..) är skrivuppsättningens nyttolast själva DDL-satsen. För DML:er måste skrivuppsättningen certifieras mot konflikter på mottagarnoden medan för DDL:er (beroende på wsrep_osu_metod , standard till TOI), kör klusterklustret DDL-satsen på alla noder i samma totala ordersekvens, vilket blockerar andra transaktioner från att utföra medan DDL pågår (se även RSU). Med enkla ord hanterar Galera Cluster DDL- och DML-replikering på olika sätt.
Tid för tur och retur
I allmänhet avgör följande faktorer hur snabbt Galera kan replikera en skrivuppsättning från en ursprungsnod till alla mottagarnoder:
- Rundturstid (RTT) till den längsta noden i klustret från ursprungsnoden.
- Storleken på en skrivuppsättning som ska överföras och certifieras för konflikt på mottagarnoden.
Till exempel, om vi har ett Galera-kluster med tre noder och en av noderna är placerad 10 millisekunder bort (0,01 sekund), är det mycket osannolikt att du kan skriva mer än 100 gånger per sekund till samma rad utan att komma i konflikt. Det finns ett populärt citat från Mark Callaghan som beskriver detta beteende ganska bra:
"[I ett Galera-kluster] kan en given rad inte ändras mer än en gång per RTT"
För att mäta RTT-värdet, utför helt enkelt en ping på ursprungsnoden till den längst borta noden i klustret:
$ ping 192.168.55.173 # the farthest nodeVänta ett par sekunder (eller minuter) och avsluta kommandot. Den sista raden i pingstatistiksektionen är vad vi letar efter:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msmax värdet är 1,340 ms (0,00134s) och vi bör ta detta värde när vi uppskattar minimum transaktioner per sekund (tps) för detta kluster. genomsnittet värdet är 0,431ms (0,000431s) och vi kan använda för att uppskatta genomsnittet tps medan min värdet är 0,111ms (0,000111s) som vi kan använda för att uppskatta maximum tps. Mdev betyder hur RTT-proverna fördelades från genomsnittet. Lägre värde betyder mer stabil RTT.
Därför kan transaktioner per sekund uppskattas genom att dividera RTT (i andra) i 1 sekund:

Resultat,
- Minsta tps:1 / 0,00134 (max RTT) =746,26 ~ 746 tps
- Genomsnittlig tps:1 / 0,000431 (genomsnittlig RTT) =2320,19 ~ 2320 tps
- Maximala tps:1 / 0,000111 (min RTT) =9009,01 ~ 9009 tps
Observera att detta bara är en uppskattning för att förutse replikeringsprestanda. Det finns inte mycket vi kan göra för att förbättra detta på databassidan, när vi väl har installerat och kört allt. Förutom om du flyttar eller migrerar databasservrarna närmare varandra för att förbättra RTT mellan noder, eller uppgradera kringutrustning eller infrastruktur för nätverket. Detta skulle kräva underhållsfönster och ordentlig planering.
Skapa stora transaktioner
En annan faktor är transaktionsstorleken. Efter att skrivuppsättningen har överförts kommer det att finnas en certifieringsprocess. Certifiering är en process för att avgöra om noden kan tillämpa skrivuppsättningen eller inte. Galera genererar MD5-checksum-pseudo-nycklar från varje hel rad. Kostnaden för certifiering beror på storleken på skrivuppsättningen, vilket översätts till ett antal unika nyckeluppslagningar i certifieringsindexet (en hashtabell). Om du uppdaterar 500 000 rader i en enda transaktion, till exempel:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Ovanstående kommer att generera en enda skrivuppsättning med 500 000 binära logghändelser i den. Denna enorma skrivuppsättning överstiger inte wsrep_max_ws_size (standard till 2GB) så det kommer att överföras av Galera replikeringsplugin till alla noder i klustret, vilket certifierar dessa 500 000 rader på mottagarnoderna för eventuella motstridiga transaktioner som fortfarande finns i slavkön. Slutligen återförs certifieringsstatusen till insticksprogrammet för gruppreplikering. Ju större transaktionsstorleken är, desto högre risk kommer det att vara i konflikt med andra transaktioner som kommer från en annan master. Motstridiga transaktioner slösar serverresurser och orsakar en enorm rollback till ursprungsnoden. Observera att en återställningsoperation i MySQL är mycket långsammare och mindre optimerad än commit-operation.
Ovanstående SQL-sats kan skrivas om till en mer Galera-vänlig sats med hjälp av en enkel loop, som exemplet nedan:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneOvanstående skalkommando skulle uppdatera 1000 rader per transaktion 500 gånger och vänta i 2 sekunder mellan körningarna. Du kan också använda en lagrad procedur eller andra medel för att uppnå ett liknande resultat. Om att skriva om SQL-frågan inte är ett alternativ, instruera helt enkelt applikationen att utföra den stora transaktionen under ett underhållsfönster för att minska risken för konflikter.
För stora raderingar kan du överväga att använda pt-archiver från Percona Toolkit - ett jobb med låg effekt, endast framåt för att knapra ut gammal data från tabellen utan att påverka OLTP-frågor mycket.
Parallella slavtrådar
I Galera är applikatorn en flertrådad process. Applier är en tråd som körs inom Galera för att applicera inkommande skrivuppsättningar från en annan nod. Vilket innebär att det är möjligt för alla mottagare att utföra flera DML-operationer som kommer direkt från ursprungsnoden (master) samtidigt. Galera parallell replikering tillämpas endast på transaktioner när det är säkert att göra det. Det förbättrar sannolikheten för noden att synkronisera med ursprungsnoden. Replikeringshastigheten är dock fortfarande begränsad till RTT och skrivuppsättningsstorlek.
För att få ut det bästa av detta behöver vi veta två saker:
- Antalet kärnor som servern har.
- Värdet på wsrep_cert_deps_distance status.
Statusen wsrep_cert_deps_distance talar om för oss den potentiella graden av parallellisering. Det är värdet på medelavståndet mellan högsta och lägsta sekvensvärde som eventuellt kan appliceras parallellt. Du kan använda wsrep_cert_deps_distance statusvariabel för att bestämma det maximala antalet möjliga slavtrådar. Observera att detta är ett genomsnittligt värde över tiden. Därför, för att få ett bra värde, måste du träffa klustret med skrivoperationer genom testarbetsbelastning eller benchmark tills du ser ett stabilt värde komma ut.
För att få antalet kärnor kan du helt enkelt använda följande kommando:
$ grep -c processor /proc/cpuinfo
4Helst är 2, 3 eller 4 trådar slavapplikator per CPU-kärna en bra början. Således bör minimivärdet för slavtrådarna vara 4 x antalet CPU-kärnor och får inte överstiga wsrep_cert_deps_distance värde:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Du kan kontrollera antalet slavapplikatortrådar med wsrep_slave_thread variabel. Även om detta är en dynamisk variabel, skulle bara en ökning av antalet ha en omedelbar effekt. Om du minskar värdet dynamiskt, skulle det ta lite tid innan applikatortråden avslutas efter att den är klar. Ett rekommenderat värde är någonstans mellan 16 och 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Observera att för att parallella slavtrådar ska fungera måste följande ställas in (vilket vanligtvis är förkonfigurerat för Galera Cluster):
innodb_autoinc_lock_mode=2Galera-cache (gcache)
Galera använder en förallokerad fil med en specifik storlek som kallas gcache, där en Galera-nod håller en kopia av skrivuppsättningar i cirkulär buffertstil. Som standard är dess storlek 128MB, vilket är ganska litet. Incremental State Transfer (IST) är en metod för att förbereda en medlem genom att bara skicka de saknade skrivuppsättningarna som finns tillgängliga i givarens gcache. IST är snabbare än SST (State Snapshot Transfer), den är icke-blockerande och har ingen betydande prestationspåverkan på givaren. Det bör vara det föredragna alternativet när det är möjligt.
IST kan bara uppnås om alla ändringar som missat av joinern fortfarande finns i donatorns gcache-fil. Den rekommenderade inställningen för detta är att vara lika stor som hela MySQL-datauppsättningen. Om diskutrymmet är begränsat eller dyrt är det avgörande att bestämma rätt storlek på gcache-storleken, eftersom det kan påverka datasynkroniseringsprestanda mellan Galera-noder.
Nedanstående uttalande ger oss en uppfattning om mängden data som replikeras av Galera. Kör följande uttalande på en av Galera-noderna under rusningstid (testade på MariaDB>10.0 och PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Vi kan uppskatta att Galera-noden kan ha cirka 16 minuters driftstopp, utan att SST behöver gå med (såvida inte Galera inte kan fastställa sammanfogningstillståndet). Om det är för kort tid och du har tillräckligt med diskutrymme på dina noder kan du ändra wsrep_provider_options="gcache.size=
Det rekommenderas också att använda gcache.recover=yes i wsrep_provider_options (Galera>3.19), där Galera kommer att försöka återställa gcache-filen till ett användbart tillstånd vid start i stället för att ta bort den, vilket bevarar möjligheten att ha IST och undviker SST så mycket som möjligt. Codership och Percona har behandlat detta i detalj i sina bloggar. IST är alltid den bästa metoden att synkronisera efter att en nod återansluter sig till klustret. Det är 50 % snabbare än xtrabackup eller mariabackup och 5 gånger snabbare än mysqldump.
Asynkron slav
Galera-noder är tätt kopplade, där replikeringsprestandan är lika snabb som den långsammaste noden. Galera använder en flödeskontrollmekanism för att kontrollera replikeringsflödet mellan medlemmar och eliminera eventuell slavfördröjning. Replikeringen kan vara snabb eller långsam på varje nod och justeras automatiskt av Galera. Om du vill veta mer om flödeskontroll, läs detta blogginlägg av Jay Janssen från Percona.
I de flesta fall är tunga operationer som långa analyser (läsintensiva) och säkerhetskopior (läsintensiva, låsning) ofta oundvikliga, vilket potentiellt kan försämra klustrets prestanda. Det bästa sättet att utföra den här typen av frågor är att skicka dem till en löst kopplad replikserver, till exempel en asynkron slav.
En asynkron slav replikerar från en Galera-nod med hjälp av standard MySQL asynkron replikeringsprotokoll. Det finns ingen begränsning på antalet slavar som kan anslutas till en Galera-nod, och det är också möjligt att kedja ut den med en mellanliggande master. MySQL-operationer som körs på den här servern kommer inte att påverka klustrets prestanda, förutom den initiala synkroniseringsfasen där en fullständig säkerhetskopia måste tas på Galera-noden för att iscensätta slaven innan replikeringslänken etableras (även om ClusterControl låter dig bygga asynkroniseringen slav från en befintlig säkerhetskopia först innan du ansluter den till klustret).
GTID (Global Transaction Identifier) ger en bättre transaktionskartläggning över noder och stöds i MySQL 5.6 och MariaDB 10.0. Med GTID förenklas failover-operationen på en slav till en annan master (en annan Galera-nod), utan att behöva ta reda på den exakta loggfilen och positionen. Galera kommer också med sin egen GTID-implementering men dessa två är oberoende av varandra.
Att skala ut en asynkron slav är ett klick bort om du använder ClusterControl -> Lägg till replikeringsslav-funktionen:
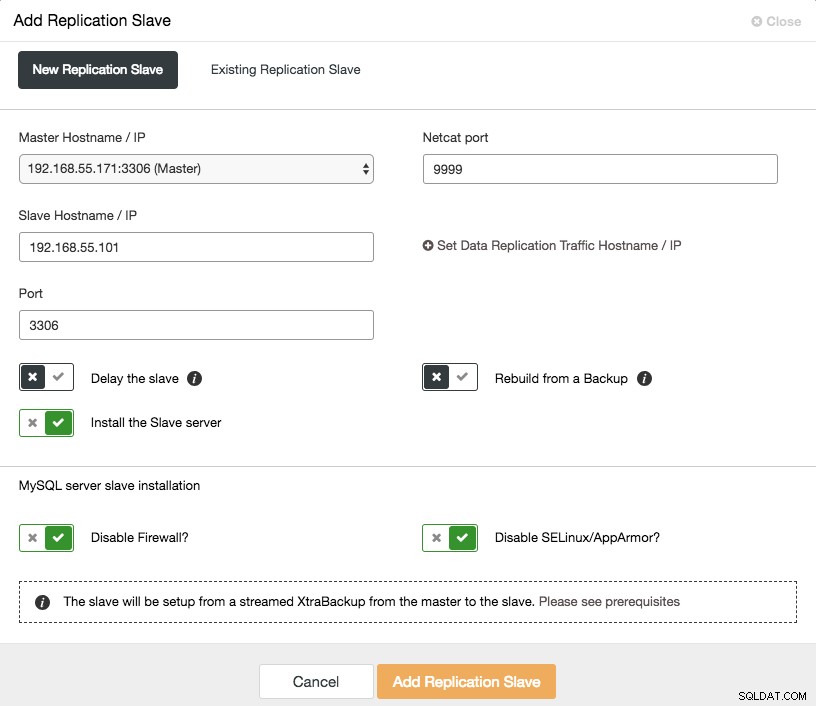
Observera att binära loggar måste vara aktiverade på mastern (den valda Galera-noden) innan vi kan fortsätta med denna inställning. Vi har också täckt det manuella sättet i detta tidigare inlägg.
Följande skärmdump från ClusterControl visar klustertopologin, den illustrerar vår Galera Cluster-arkitektur med en asynkron slav:
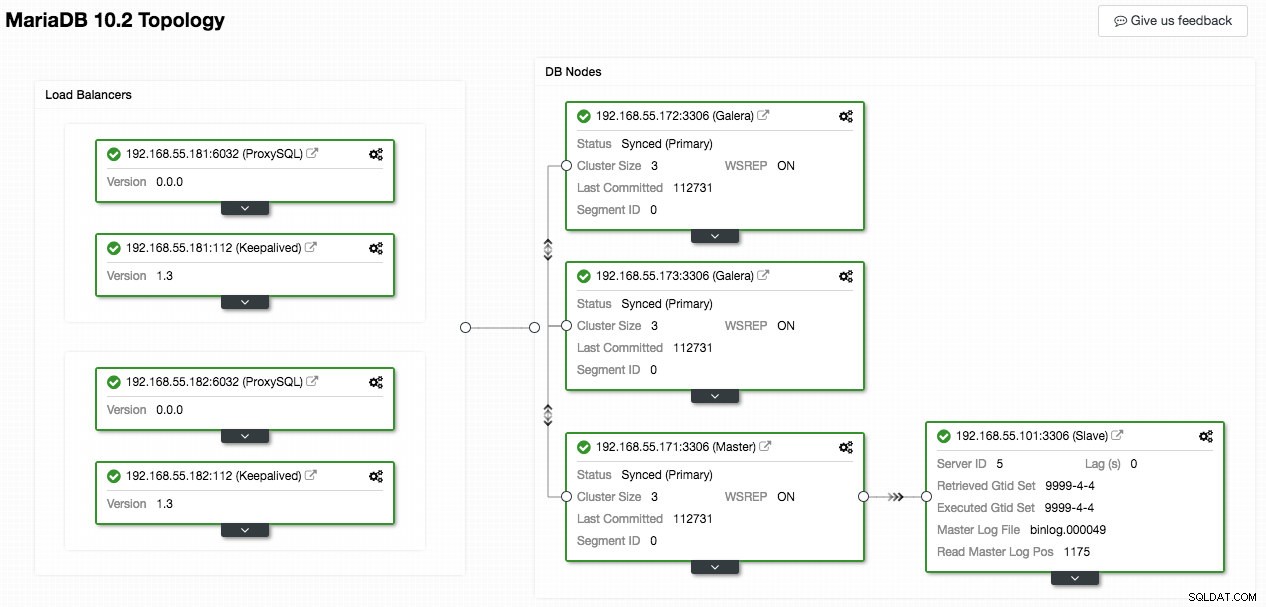
ClusterControl upptäcker automatiskt topologin och genererar det supercoola diagrammet som ovan. Du kan också utföra administrationsuppgifter direkt från den här sidan genom att klicka på kugghjulsikonen uppe till höger i varje ruta.
SQL-medveten omvänd proxy
ProxySQL och MariaDB MaxScale är intelligenta omvända proxyservrar som förstår MySQL-protokollet och kan fungera som en gateway, router, lastbalanserare och brandvägg framför dina Galera-noder. Med hjälp av en virtuell IP-adressleverantör som LVS eller Keepalived, och genom att kombinera detta med Galera multi-master replikeringsteknik, kan vi ha en högtillgänglig databastjänst, vilket eliminerar alla möjliga single-point-of-failures (SPOF) från applikationspunkten -av synen. Detta kommer säkerligen att förbättra tillgängligheten och tillförlitligheten för arkitekturen som helhet.
En annan fördel med detta tillvägagångssätt är att du kommer att ha förmågan att övervaka, skriva om eller omdirigera de inkommande SQL-frågorna baserat på en uppsättning regler innan de träffar den faktiska databasservern, vilket minimerar ändringarna på applikations- eller klientsidan och dirigerar frågor till en mer lämplig nod för optimal prestanda. Riskfyllda frågor för Galera som LOCK TABLES och FLUSH TABLES MED LÄSSLÅS kan förhindras långt fram innan de skulle orsaka förödelse för systemet, medan påverkande frågor som "hotspot"-frågor (en rad som olika frågor vill komma åt samtidigt) kan skrivas om eller omdirigeras till en enda Galera-nod för att minska risken för transaktionskonflikter. För tunga skrivskyddade frågor som OLAP eller säkerhetskopiering kan du dirigera dem till en asynkron slav om du har några.
Omvänd proxy övervakar också databastillståndet, frågor och variabler för att förstå topologiförändringarna och producera ett korrekt routingbeslut till backend-servrarna. Indirekt centraliserar den nodövervakningen och klusteröversikten utan att behöva kontrollera varje enskild Galera-nod regelbundet. Följande skärmdump visar ProxySQL-övervakningsinstrumentpanelen i ClusterControl:
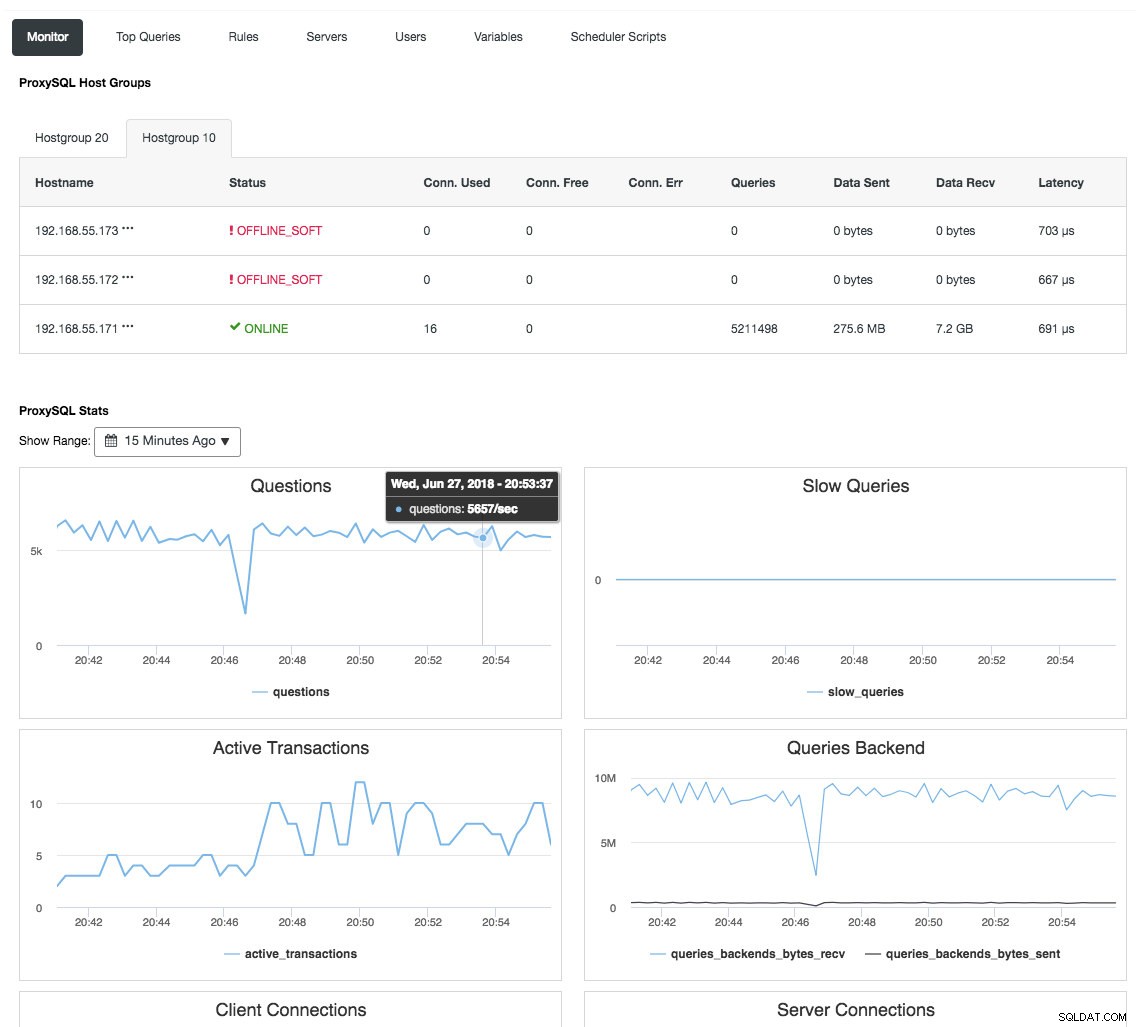
Det finns också många andra fördelar som en lastbalanserare kan ge för att förbättra Galera Cluster avsevärt, som beskrivs i detaljer i det här blogginlägget, Bli en ClusterControl DBA:Gör dina DB-komponenter HA via Load Balancers.
Sluta tankar
Med god förståelse för hur Galera Cluster fungerar internt kan vi kringgå några av begränsningarna och förbättra databastjänsten. Lycka till med klustringen!