I ett tidigare inlägg diskuterade vi hur du kan ta kontroll över failover-processen i ClusterControl genom att använda vitlistor och svartlistor. I det här inlägget ska vi diskutera ett liknande koncept. Men den här gången kommer vi att fokusera på integrationer med externa skript och applikationer genom många krokar som görs tillgängliga av ClusterControl.
Infrastrukturmiljöer kan byggas på olika sätt, eftersom det ofta finns många alternativ att välja mellan för en given pusselbit. Hur definierar vi vilken databasnod vi ska skriva till? Använder du virtuell IP? Använder du någon form av tjänsteupptäckt? Kanske går du med DNS-poster och ändrar A-posterna när det behövs? Hur är det med proxy-lagret? Förlitar du dig på "read_only"-värdet för dina proxyservrar för att bestämma skribenten, eller kanske du gör de nödvändiga ändringarna direkt i konfigurationen av proxyn? Hur hanterar din miljö byten? Kan du bara gå vidare och utföra det, eller kanske du måste vidta några preliminära åtgärder i förväg? Till exempel, stoppa några andra processer innan du faktiskt kan göra bytet?
Det är inte möjligt för en failover-mjukvara att förkonfigureras för att täcka alla olika inställningar som människor kan skapa. Detta är huvudskälet till att tillhandahålla olika sätt att koppla in i failover-processen. På så sätt kan du anpassa den och göra det möjligt att hantera alla finesser i din installation. I det här blogginlägget kommer vi att undersöka hur ClusterControls failover-process kan anpassas med olika pre- och post-failover-skript. Vi kommer också att diskutera några exempel på vad som kan åstadkommas med sådan anpassning.
Integrera ClusterControl
ClusterControl tillhandahåller flera krokar som kan användas för att koppla in externa skript. Nedan hittar du en lista över dem med viss förklaring.
- Replication_onfail_failover_script - detta skript körs så snart det har upptäckts att en failover behövs. Om skriptet inte är noll kommer det att tvinga övergången att avbryta. Om skriptet är definierat men inte hittat, kommer failover att avbrytas. Fyra argument levereras till skriptet:arg1='alla servrar' arg2='oldmaster' arg3='kandidat', arg4='slavar från oldmaster' och skickas så här:'skriptnamn arg1 arg2 arg3 arg4'. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_pre_failover_script - det här skriptet körs innan failover sker, men efter att en kandidat har blivit vald och det är möjligt att fortsätta failover-processen. Om skriptet inte är noll kommer det att tvinga övergången att avbryta. Om skriptet är definierat men inte hittat, kommer failover att avbrytas. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_post_failover_script - det här skriptet körs efter att failover hände. Om skriptet inte är noll, kommer en varning att skrivas i jobbloggen. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_post_unsuccessful_failover_script - Detta skript körs efter att failover-försöket misslyckades. Om skriptet inte är noll, kommer en varning att skrivas i jobbloggen. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_failed_reslave_failover_script - detta skript exekveras efter att en ny master har befordrats och om omslavningen av slavarna till den nya mastern misslyckas. Om skriptet inte är noll, kommer en varning att skrivas i jobbloggen. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_pre_switchover_script - detta skript körs innan övergången sker. Om skriptet inte är noll kommer det att tvinga övergången att misslyckas. Om skriptet är definierat men inte hittat, kommer övergången att avbrytas. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
- Replication_post_switchover_script - det här skriptet körs efter övergången. Om skriptet inte är noll, kommer en varning att skrivas i jobbloggen. Skriptet måste vara tillgängligt på styrenheten och vara körbart.
Som du kan se täcker krokarna de flesta fall där du kanske vill vidta några åtgärder - före och efter en omställning, före och efter en failover, när reslaven har misslyckats eller när failoveren har misslyckats. Alla skript anropas med fyra argument (som kan eller kanske inte hanteras i skriptet, det krävs inte för att skriptet ska använda dem alla):alla servrar, värdnamn (eller IP - som det definieras i ClusterControl) av den gamla master-, värdnamnet (eller IP - som det definieras i ClusterControl) för masterkandidaten och den fjärde, alla repliker av den gamla mastern. Dessa alternativ bör göra det möjligt att hantera majoriteten av ärendena.
Alla dessa krokar bör definieras i en konfigurationsfil för ett givet kluster (/etc/cmon.d/cmon_X.cnf där X är klustrets id). Ett exempel kan se ut så här:
replication_pre_failover_script=/usr/bin/stonith.py
replication_post_failover_script=/usr/bin/vipmove.shNaturligtvis måste anropade skript vara körbara, annars kommer inte cmon att kunna köra dem. Låt oss nu ta en stund och gå igenom failover-processen i ClusterControl och se när de externa skripten exekveras.
Failover-process i ClusterControl
Vi definierade alla krokar som finns tillgängliga:
replication_onfail_failover_script=/tmp/1.sh
replication_pre_failover_script=/tmp/2.sh
replication_post_failover_script=/tmp/3.sh
replication_post_unsuccessful_failover_script=/tmp/4.sh
replication_failed_reslave_failover_script=/tmp/5.sh
replication_pre_switchover_script=/tmp/6.sh
replication_post_switchover_script=/tmp/7.shEfter detta måste du starta om cmon-processen. När det är klart är vi redo att testa failover. Den ursprungliga topologin ser ut så här:
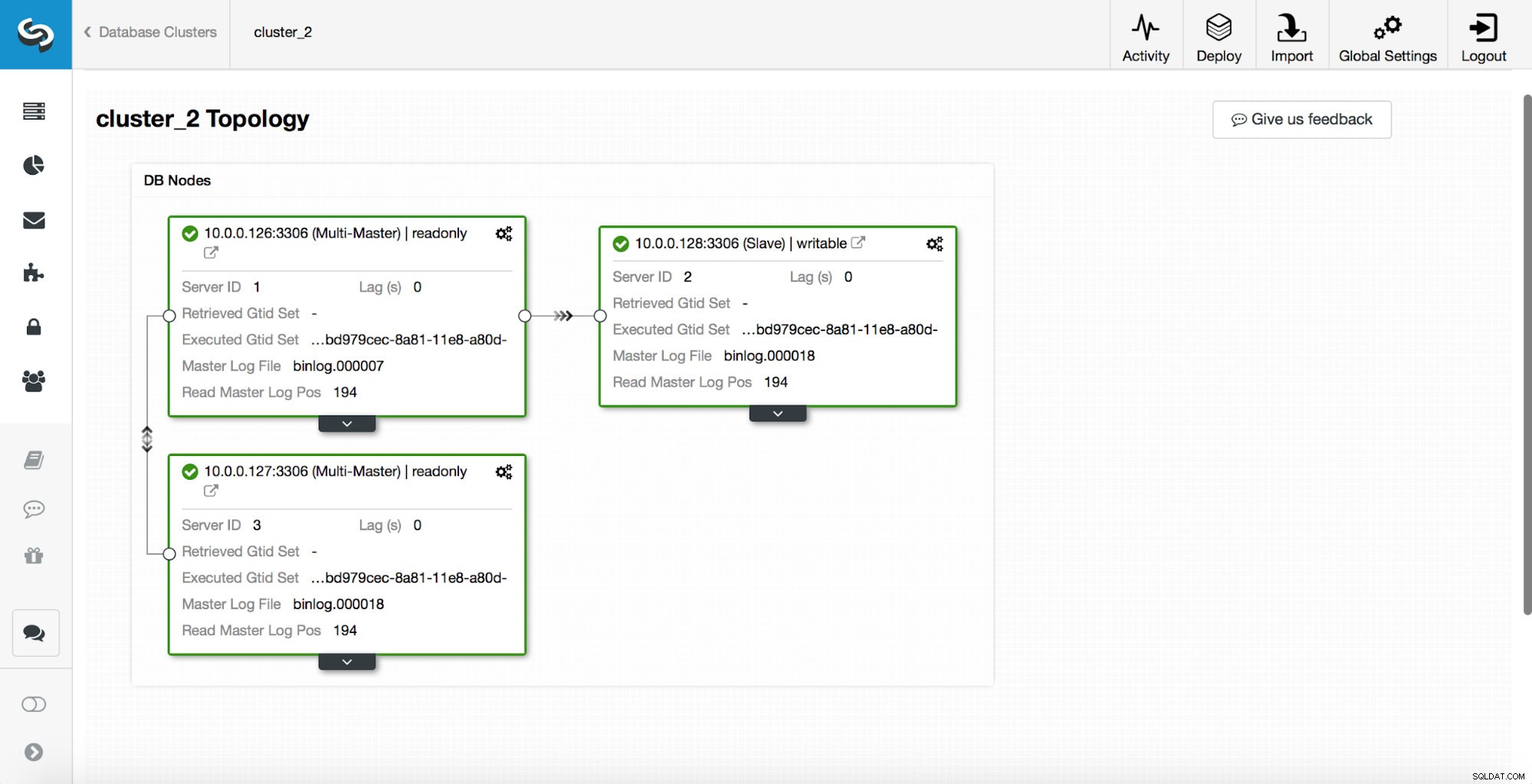
En master har dödats och failover-processen startade. Observera att de senaste loggposterna finns överst så att du vill följa failover från botten till toppen.
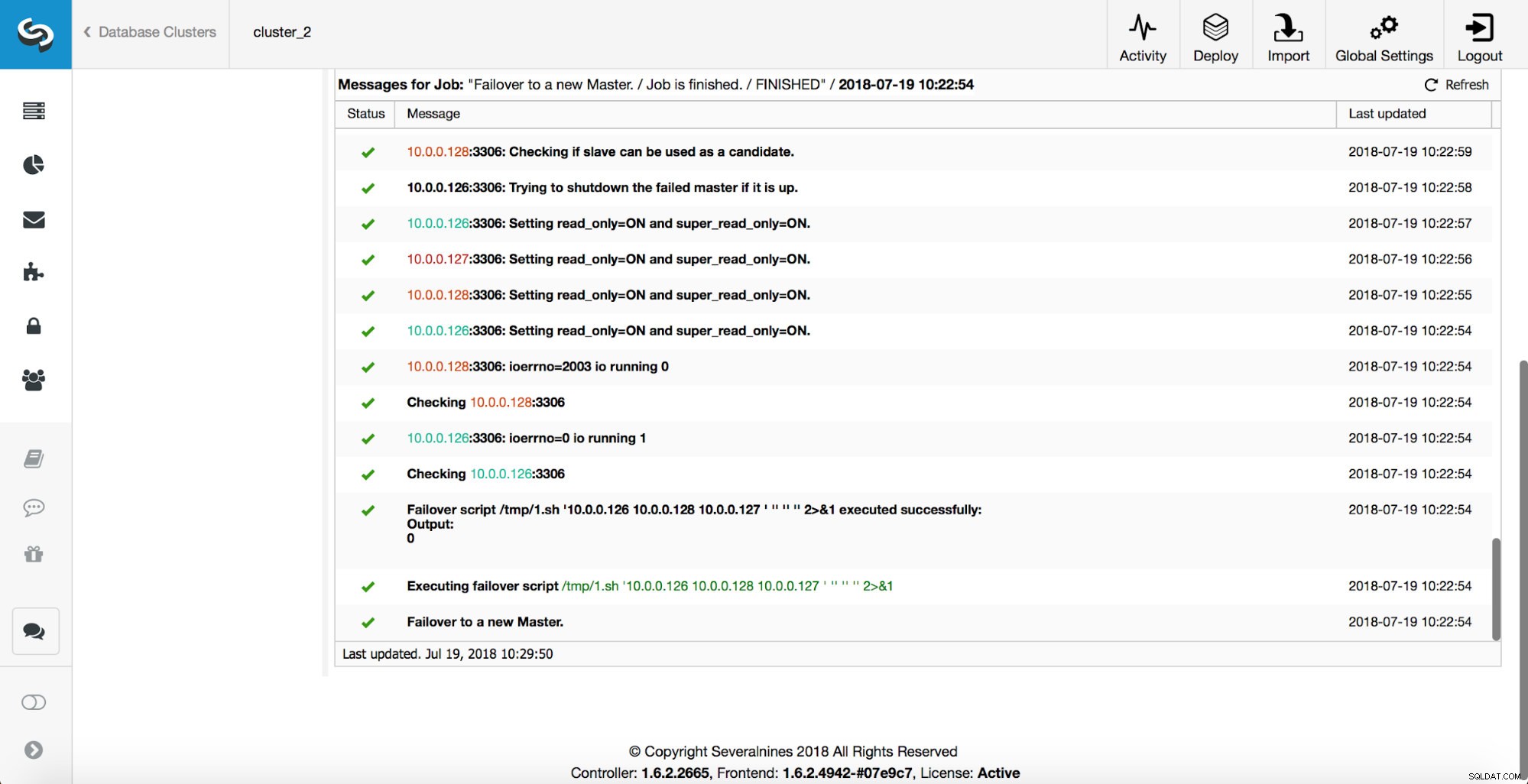
Som du kan se, omedelbart efter att failover-jobbet startade, triggar det "replikering_på_fel_fel_fel_skript"-kroken. Sedan markeras alla tillgängliga värdar som read_only och ClusterControl försöker förhindra att den gamla mastern körs.
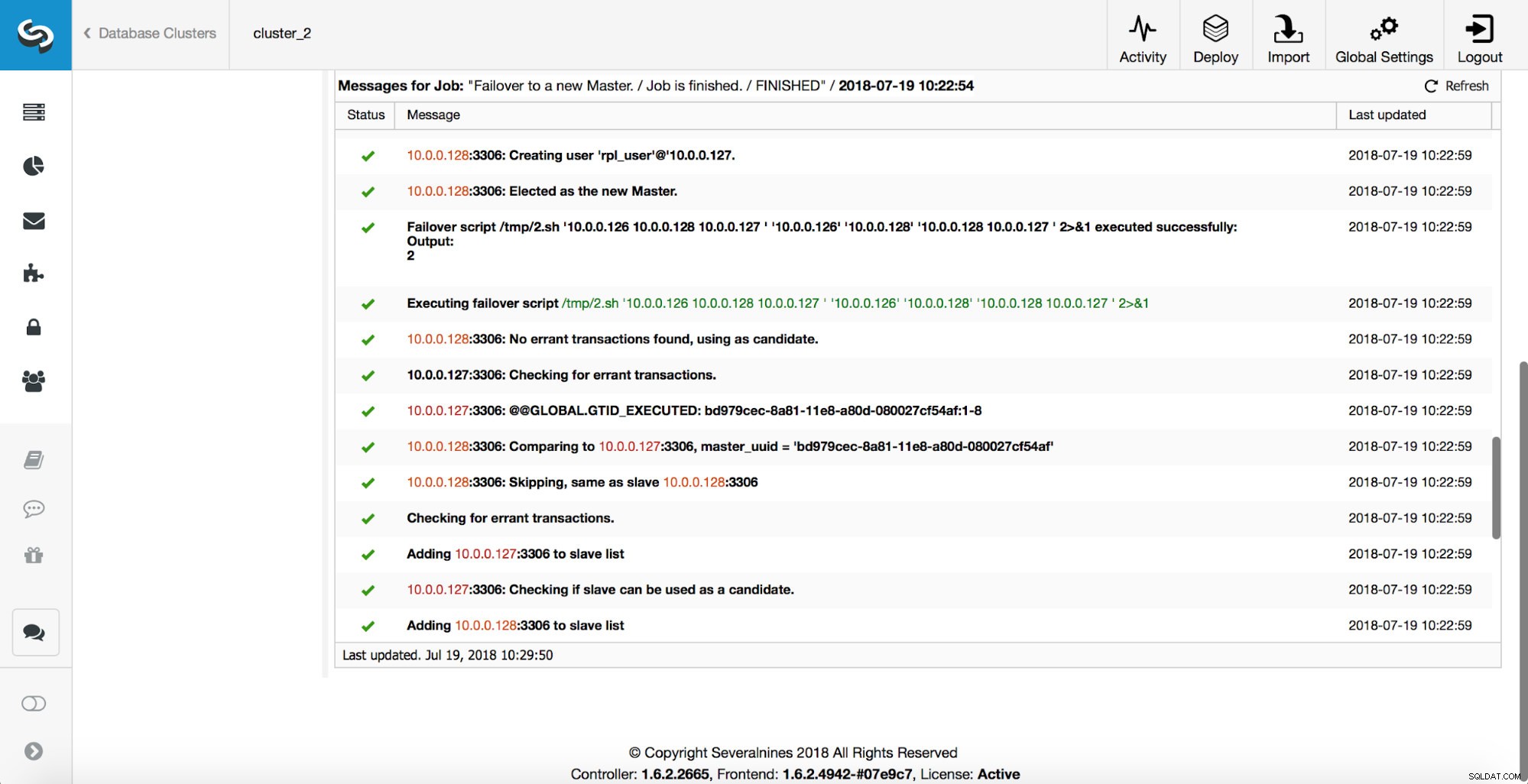
Därefter väljs masterkandidaten ut, hälsokontroller utförs. När det har bekräftats att masterkandidaten kan användas som en ny master, exekveras "replication_pre_failover_script".
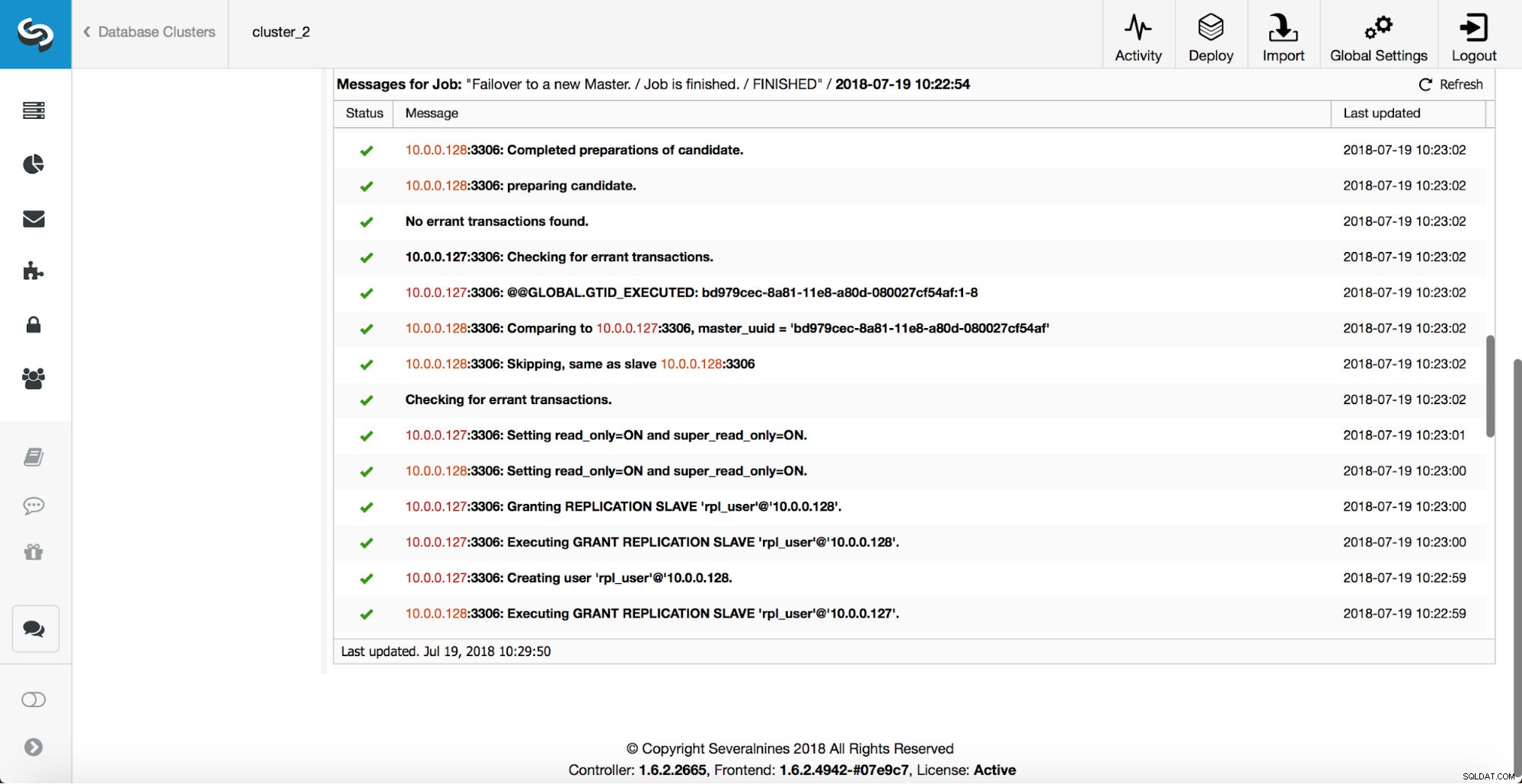
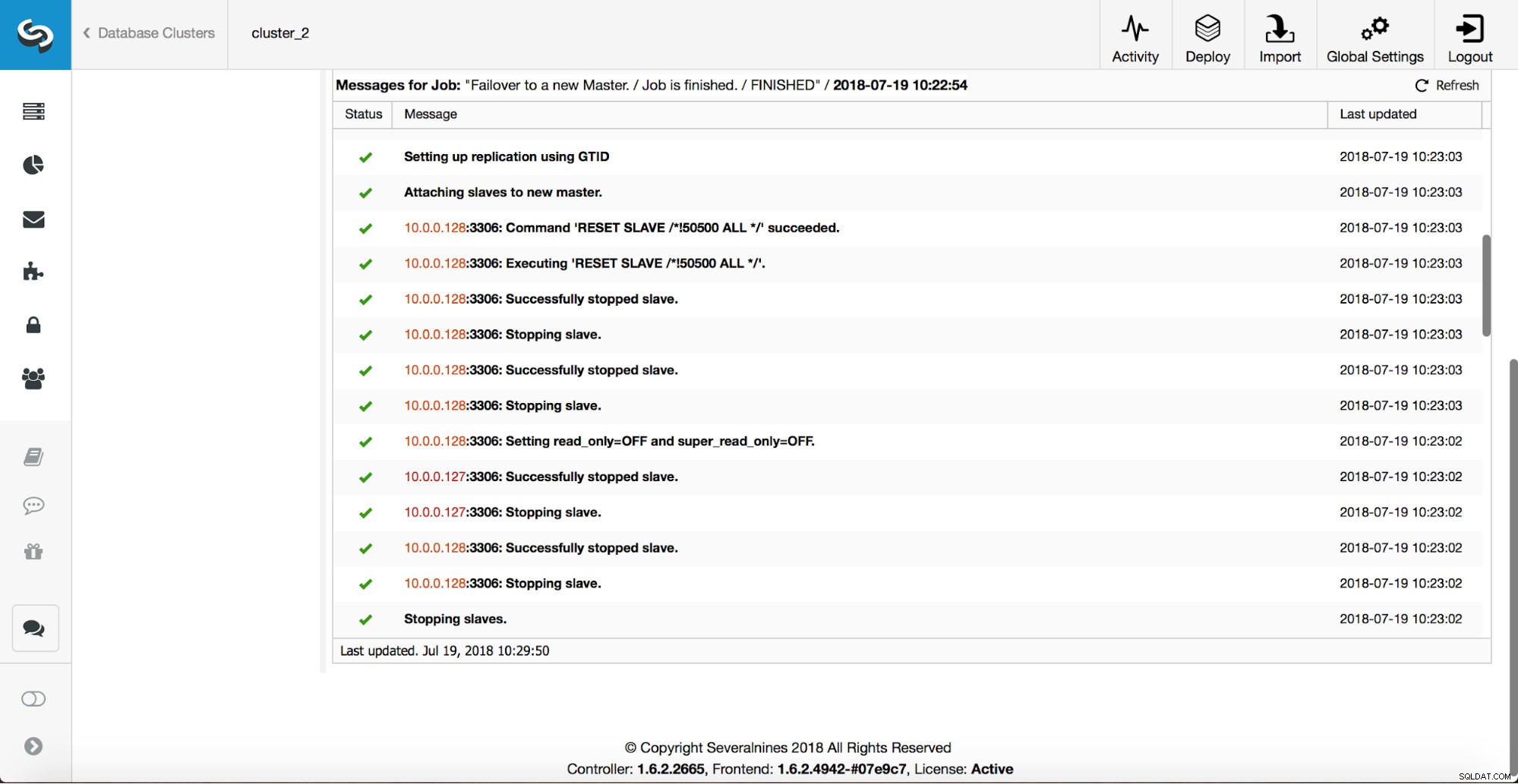
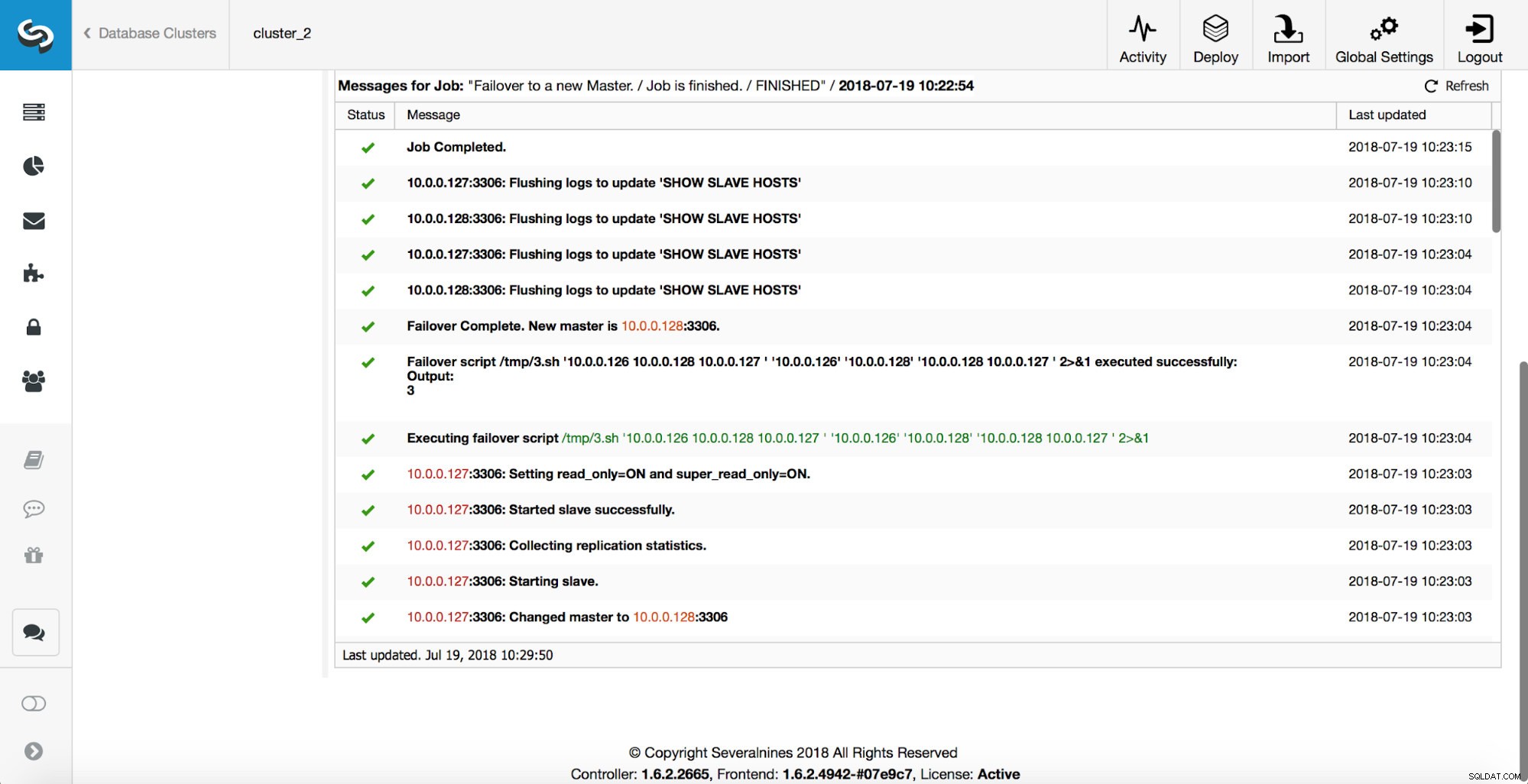
Fler kontroller utförs, repliker stoppas och slavas av den nya mastern. Slutligen, efter att failover slutförts, utlöses en sista hook, 'replikering_post_felöver_skript'.
När krokar kan vara användbara?
I det här avsnittet går vi igenom ett par exempel på fall där det kan vara en bra idé att implementera externa skript. Vi kommer inte att gå in på några detaljer eftersom de är för nära relaterade till en viss miljö. Det blir mer en lista med förslag som kan vara användbara att implementera.
STONITH-skript
Shoot The Other Node In The Head (STONITH) är en process för att se till att den gamla mästaren, som är död, förblir död (och ja... vi gillar inte zombies som strövar omkring i vår infrastruktur). Det sista du antagligen vill ha är att ha en gammal mästare som inte svarar som sedan kommer online igen och som ett resultat får du två skrivbara mästare. Det finns försiktighetsåtgärder du kan vidta för att se till att den gamla mastern inte kommer att användas även om den dyker upp igen, och det är säkrare för den att förbli offline. Sätt att säkerställa att det kommer att skilja sig från miljö till miljö. Därför kommer det troligen inte att finnas något inbyggt stöd för STONITH i failover-verktyget. Beroende på miljön kanske du vill köra CLI-kommandot som kommer att stoppa (och till och med ta bort) en virtuell dator som den gamla mastern körs på. Om du har en lokal installation kan du ha mer kontroll över hårdvaran. Det kan vara möjligt att använda någon form av fjärrhantering (integrerad Lights-out eller någon annan fjärråtkomst till servern). Du kan också ha tillgång till hanterbara eluttag och stänga av strömmen i ett av dem för att säkerställa att servern aldrig startar igen utan mänsklig inblandning.
Service Discovery
Vi har redan nämnt lite om tjänsteupptäckt. Det finns många sätt man kan lagra information om en replikeringstopologi och detektera vilken värd som är en master. Definitivt, ett av de mer populära alternativen är att använda etc.d eller Consul för att lagra data om aktuell topologi. Med den kan en applikation eller proxy förlita sig på denna data för att skicka trafiken till rätt nod. ClusterControl har (precis som de flesta verktyg som stöder failover-hantering) ingen direkt integration med varken etc.d eller Consul. Uppgiften att uppdatera topologidata ligger på användaren. Hon kan använda krokar som replication_post_failover_script eller replication_post_switchover_script för att anropa några av skripten och göra de nödvändiga ändringarna. En annan ganska vanlig lösning är att använda DNS för att dirigera trafik till korrekta instanser. Om du kommer att hålla Time-To-Live för en DNS-post låg bör du kunna definiera en domän som pekar på din master (dvs. writes.cluster1.example.com). Detta kräver en ändring av DNS-posterna och återigen kan krokar som replication_post_failover_script eller replication_post_switchover_script vara till stor hjälp för att göra nödvändiga ändringar efter att en failover inträffat.
Proxyomkonfiguration
Varje proxyserver som används måste skicka trafik till korrekta instanser. Beroende på själva proxyn kan hur en masterdetektering utförs antingen (delvis) hårdkodas eller vara upp till användaren att definiera vad hon vill. ClusterControl failover-mekanismen är utformad på ett sätt som den integrerar väl med proxyservrar som den har distribuerat och konfigurerat. Det kan fortfarande hända att det finns proxyservrar på plats, som inte installerades av ClusterControl och de kräver att vissa manuella åtgärder utförs medan failover exekveras. Sådana proxyservrar kan också integreras med ClusterControl failover-processen genom externa skript och krokar som replication_post_failover_script eller replication_post_switchover_script.
Ytterligare loggning
Det kan hända att du vill samla in data från failover-processen för felsökningsändamål. ClusterControl har omfattande utskrifter för att säkerställa att det är möjligt att följa processen och ta reda på vad som hände och varför. Det kan fortfarande hända att du vill samla in ytterligare, anpassad information. I princip alla krokar kan användas här - du kan samla in det initiala tillståndet, före failover kan du spåra miljöns tillstånd i alla stadier av failover.