Som systemadministratörer och utvecklare tillbringar vi mycket tid i en terminal. Så vi tog ClusterControl till terminalen med vårt kommandoradsgränssnittsverktyg som heter s9s. s9s ger ett enkelt gränssnitt till ClusterControl RPC v2 API. Du kommer att tycka att det är mycket användbart när du arbetar med storskaliga distributioner, eftersom CLI tillåter dig att designa mer komplexa funktioner och arbetsflöden.
Det här blogginlägget visar hur man använder s9s för att automatisera hanteringen av Galera Cluster för MySQL eller MariaDB, samt en enkel master-slave replikeringsinställning.
Inställningar
Du hittar installationsinstruktioner för just ditt operativsystem i dokumentationen. Vad som är viktigt att notera är att om du råkar använda de senaste s9s-verktygen, från GitHub, finns det en liten förändring i hur du skapar en användare. Följande kommando kommer att fungera bra:
s9s user --create --generate-key --controller="https://localhost:9501" dbaI allmänhet krävs två steg om du vill konfigurera CLI lokalt på ClusterControl-värden. Först måste du skapa en användare och sedan göra några ändringar i konfigurationsfilen - alla steg ingår i dokumentationen.
Implementering
När CLI har konfigurerats korrekt och har SSH-åtkomst till dina måldatabasvärdar kan du starta distributionsprocessen. I skrivande stund kan du använda CLI för att distribuera MySQL, MariaDB och PostgreSQL-kluster. Låt oss börja med ett exempel på hur man distribuerar Percona XtraDB Cluster 5.7. Ett enda kommando krävs för att göra det.
s9s cluster --create --cluster-type=galera --nodes="10.0.0.226;10.0.0.227;10.0.0.228" --vendor=percona --provider-version=5.7 --db-admin-passwd="pass" --os-user=root --cluster-name="PXC_Cluster_57" --waitDet sista alternativet "--vänta" betyder att kommandot väntar tills jobbet är klart och visar dess framsteg. Du kan hoppa över det om du vill - i så fall kommer s9s-kommandot att återgå direkt till skalet efter att det registrerat ett nytt jobb i cmon. Detta är helt okej eftersom cmon är processen som sköter själva jobbet. Du kan alltid kontrollera förloppet för ett jobb separat med:
example@sqldat.com:~# s9s job --list -l
--------------------------------------------------------------------------------------
Create Galera Cluster
Installing MySQL on 10.0.0.226 [██▊ ]
26.09%
Created : 2017-10-05 11:23:00 ID : 1 Status : RUNNING
Started : 2017-10-05 11:23:02 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 1Låt oss ta en titt på ett annat exempel. Den här gången skapar vi ett nytt kluster, MySQL-replikering:enkel master - slavpar. Återigen, ett enda kommando räcker:
example@sqldat.com:~# s9s cluster --create --nodes="10.0.0.229?master;10.0.0.230?slave" --vendor=percona --cluster-type=mysqlreplication --provider-version=5.7 --os-user=root --wait
Create MySQL Replication Cluster
/ Job 6 FINISHED [██████████] 100% Cluster createdVi kan nu verifiera att båda klustren är igång:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Naturligtvis är allt detta också synligt via GUI:
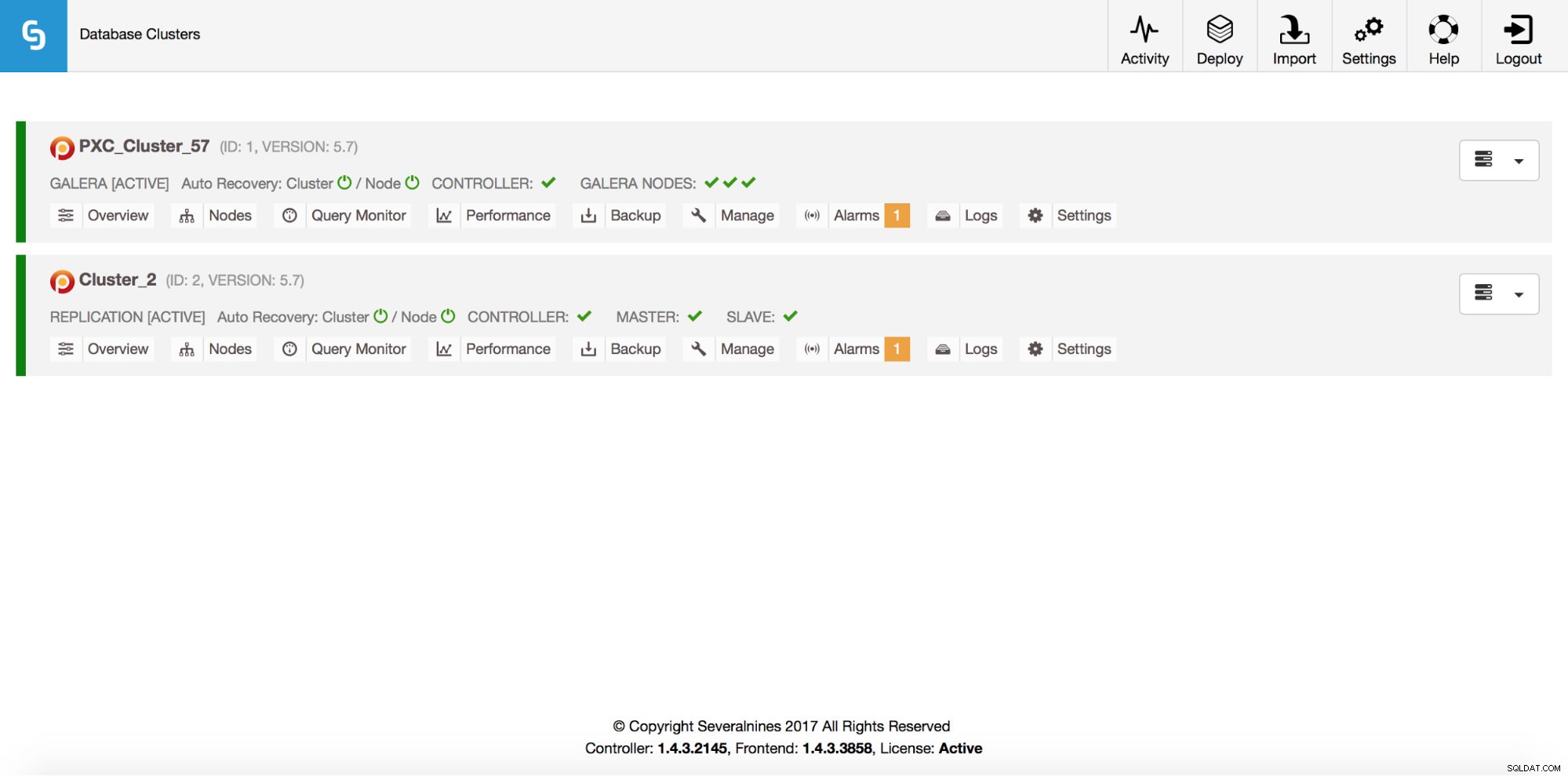
Låt oss nu lägga till en ProxySQL loadbalancer:
example@sqldat.com:~# s9s cluster --add-node --nodes="proxysql://10.0.0.226" --cluster-id=1
WARNING: admin/admin
WARNING: proxy-monitor/proxy-monitor
Job with ID 7 registered.Den här gången använde vi inte alternativet "--vänta", så om vi vill kontrollera framstegen måste vi göra det på egen hand. Observera att vi använder ett jobb-ID som returnerades av det tidigare kommandot, så vi får endast information om just detta jobb:
example@sqldat.com:~# s9s job --list --long --job-id=7
--------------------------------------------------------------------------------------
Add ProxySQL to Cluster
Waiting for ProxySQL [██████▋ ]
65.00%
Created : 2017-10-06 14:09:11 ID : 7 Status : RUNNING
Started : 2017-10-06 14:09:12 User : dba Host :
Ended : Group: users
--------------------------------------------------------------------------------------
Total: 7Skalar ut
Noder kan läggas till i vårt Galera-kluster via ett enda kommando:
s9s cluster --add-node --nodes 10.0.0.229 --cluster-id 1
Job with ID 8 registered.
example@sqldat.com:~# s9s job --list --job-id=8
ID CID STATE OWNER GROUP CREATED RDY TITLE
8 1 FAILED dba users 14:15:52 0% Add Node to Cluster
Total: 8Något gick fel. Vi kan kontrollera exakt vad som hände:
example@sqldat.com:~# s9s job --log --job-id=8
addNode: Verifying job parameters.
10.0.0.229:3306: Adding host to cluster.
10.0.0.229:3306: Testing SSH to host.
10.0.0.229:3306: Installing node.
10.0.0.229:3306: Setup new node (installSoftware = true).
10.0.0.229:3306: Detected a running mysqld server. It must be uninstalled first, or you can also add it to ClusterControl.Okej, den IP-adressen används redan för vår replikeringsserver. Vi borde ha använt en annan, gratis IP. Låt oss prova det:
example@sqldat.com:~# s9s cluster --add-node --nodes 10.0.0.231 --cluster-id 1
Job with ID 9 registered.
example@sqldat.com:~# s9s job --list --job-id=9
ID CID STATE OWNER GROUP CREATED RDY TITLE
9 1 FINISHED dba users 14:20:08 100% Add Node to Cluster
Total: 9Hantera
Låt oss säga att vi vill ta en säkerhetskopia av vår replikeringsmaster. Vi kan göra det från GUI men ibland kan vi behöva integrera det med externa skript. ClusterControl CLI skulle passa perfekt för ett sådant fall. Låt oss kolla vilka kluster vi har:
example@sqldat.com:~# s9s cluster --list --long
ID STATE TYPE OWNER GROUP NAME COMMENT
1 STARTED galera dba users PXC_Cluster_57 All nodes are operational.
2 STARTED replication dba users cluster_2 All nodes are operational.
Total: 2Låt oss sedan kontrollera värdarna i vårt replikeringskluster, med kluster-ID 2:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
coC- 1.4.3.2145 2 cluster_2 10.0.2.15 9500 Up and runningSom vi kan se finns det tre värdar som ClusterControl känner till - två av dem är MySQL-värdar (10.0.0.229 och 10.0.0.230), den tredje är själva ClusterControl-instansen. Låt oss bara skriva ut relevanta MySQL-värdar:
example@sqldat.com:~# s9s nodes --list --long --cluster-id=2 10.0.0.2*
STAT VERSION CID CLUSTER HOST PORT COMMENT
soM- 5.7.19-17-log 2 cluster_2 10.0.0.229 3306 Up and running
soS- 5.7.19-17-log 2 cluster_2 10.0.0.230 3306 Up and running
Total: 3I kolumnen "STAT" kan du se några tecken där. För mer information föreslår vi att du tittar på manualsidan för s9s-noder (man s9s-noder). Här ska vi bara sammanfatta de viktigaste bitarna. Det första tecknet berättar om typen av nod:"s" betyder att det är en vanlig MySQL-nod, "c" - ClusterControl-kontroller. Det andra tecknet beskriver nodens tillstånd:"o" talar om för oss att den är online. Tredje karaktären - nodens roll. Här beskriver "M" en master och "S" - en slav medan "C" står för controller. Det sista fjärde tecknet talar om för oss om noden är i underhållsläge. "-" betyder att inget underhåll är planerat. Annars skulle vi se "M" här. Så från dessa data kan vi se att vår master är en värd med IP:10.0.0.229. Låt oss ta en säkerhetskopia av den och lagra den på styrenheten.
example@sqldat.com:~# s9s backup --create --nodes=10.0.0.229 --cluster-id=2 --backup-method=xtrabackupfull --wait
Create Backup
| Job 12 FINISHED [██████████] 100% Command okVi kan sedan verifiera om det verkligen slutfördes ok. Observera alternativet "--backup-format" som låter dig definiera vilken information som ska skrivas ut:
example@sqldat.com:~# s9s backup --list --full --backup-format="Started: %B Completed: %E Method: %M Stored on: %S Size: %s %F\n" --cluster-id=2
Started: 15:29:11 Completed: 15:29:19 Method: xtrabackupfull Stored on: 10.0.0.229 Size: 543382 backup-full-2017-10-06_152911.xbstream.gz
Total 1Övervakning
Alla databaser måste övervakas. ClusterControl använder rådgivare för att titta på några av mätvärdena på både MySQL och operativsystemet. När ett villkor är uppfyllt skickas ett meddelande. ClusterControl tillhandahåller också en omfattande uppsättning grafer, både i realtid och historiska för obduktion eller kapacitetsplanering. Ibland skulle det vara bra att ha tillgång till några av dessa mätvärden utan att behöva gå igenom GUI. ClusterControl CLI gör det möjligt genom kommandot s9s-node. Information om hur man gör det finns på manualsidan för s9s-node. Vi visar några exempel på vad du kan göra med CLI.
Först och främst, låt oss ta en titt på alternativet "--node-format" till kommandot "s9s node". Som du kan se finns det många alternativ för att skriva ut intressant innehåll.
example@sqldat.com:~# s9s node --list --node-format "%N %T %R %c cores %u%% CPU utilization %fmG of free memory, %tMB/s of net TX+RX, %M\n" "10.0.0.2*"
10.0.0.226 galera none 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Up and running
10.0.0.227 galera none 1 cores 13.033900% CPU utilization 0.543209G of free memory, 0.053596MB/s of net TX+RX, Up and running
10.0.0.228 galera none 1 cores 12.929100% CPU utilization 0.541988G of free memory, 0.052066MB/s of net TX+RX, Up and running
10.0.0.226 proxysql 1 cores 13.823200% CPU utilization 0.503227G of free memory, 0.061036MB/s of net TX+RX, Process 'proxysql' is running.
10.0.0.231 galera none 1 cores 13.104700% CPU utilization 0.544048G of free memory, 0.045713MB/s of net TX+RX, Up and running
10.0.0.229 mysql master 1 cores 11.107300% CPU utilization 0.575871G of free memory, 0.035830MB/s of net TX+RX, Up and running
10.0.0.230 mysql slave 1 cores 9.861590% CPU utilization 0.580315G of free memory, 0.035451MB/s of net TX+RX, Up and runningMed det vi visade här kan du förmodligen föreställa dig några fall för automatisering. Till exempel kan du titta på CPU-användningen av noderna och om den når någon tröskel kan du utföra ett annat s9s-jobb för att snurra upp en ny nod i Galera-klustret. Du kan också till exempel övervaka minnesutnyttjandet och skicka varningar om det passerar någon tröskel.
CLI kan mer än så. Först och främst är det möjligt att kontrollera graferna från kommandoraden. Naturligtvis är de inte lika funktionsrika som grafer i GUI, men ibland räcker det bara att se en graf för att hitta ett oväntat mönster och avgöra om det är värt att undersöka ytterligare.
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=load 10.0.0.231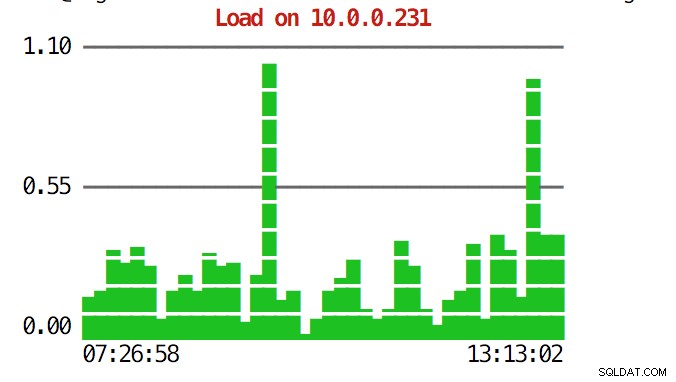
example@sqldat.com:~# s9s node --stat --cluster-id=1 --begin="00:00" --end="14:00" --graph=sqlqueries 10.0.0.231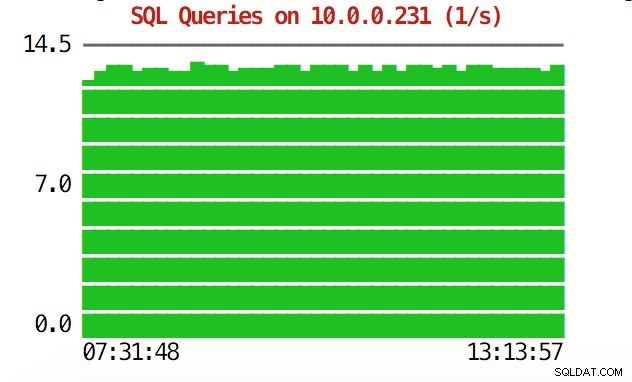
Under nödsituationer kanske du vill kontrollera resursutnyttjandet över hela klustret. Du kan skapa en toppliknande utdata som kombinerar data från alla klusternoder:
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqld
22994 root 10.0.2.15 20 30400 9312 S 0.93 1.23 s9s
9115 root 10.0.0.227 20 95368 7192 S 0.68 0.95 sshd
23768 root 10.0.0.228 20 95372 7160 S 0.67 0.94 sshd
15690 mysql 10.0.2.15 20 1102012 209056 S 0.67 27.58 mysqld
11471 root 10.0.0.226 20 95372 7392 S 0.17 0.98 sshd
22086 vagrant 10.0.2.15 20 95372 4960 S 0.17 0.65 sshd
7282 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:2
9003 root 10.0.0.226 20 0 0 S 0.09 0.00 kworker/u4:1
1195 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:0
27240 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/1:1
9933 root 10.0.0.227 20 0 0 S 0.09 0.00 kworker/u4:2
16181 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/u4:1
1744 root 10.0.0.228 20 0 0 S 0.08 0.00 kworker/1:1
28506 root 10.0.0.228 20 95372 7348 S 0.08 0.97 sshd
691 messagebus 10.0.0.228 20 42896 3872 S 0.08 0.51 dbus-daemon
11892 root 10.0.2.15 20 0 0 S 0.08 0.00 kworker/0:2
15609 root 10.0.2.15 20 403548 12908 S 0.08 1.70 apache2
256 root 10.0.2.15 20 0 0 S 0.08 0.00 jbd2/dm-0-8
840 root 10.0.2.15 20 316200 1308 S 0.08 0.17 VBoxService
14694 root 10.0.0.227 20 95368 7200 S 0.00 0.95 sshd
12724 n/a 10.0.0.227 20 4508 1780 S 0.00 0.23 mysqld_safe
10974 root 10.0.0.227 20 95368 7400 S 0.00 0.98 sshd
14712 root 10.0.0.227 20 95368 7384 S 0.00 0.97 sshd
16952 root 10.0.0.227 20 95368 7344 S 0.00 0.97 sshd
17025 root 10.0.0.227 20 95368 7100 S 0.00 0.94 sshd
27075 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/u4:1
27169 root 10.0.0.227 20 0 0 S 0.00 0.00 kworker/0:0
881 root 10.0.0.227 20 37976 760 S 0.00 0.10 rpc.mountd
100 root 10.0.0.227 0 0 0 S 0.00 0.00 deferwq
102 root 10.0.0.227 0 0 0 S 0.00 0.00 bioset
11876 root 10.0.0.227 20 9588 2572 S 0.00 0.34 bash
11852 root 10.0.0.227 20 95368 7352 S 0.00 0.97 sshd
104 root 10.0.0.227 0 0 0 S 0.00 0.00 kworker/1:1HNär du tar en titt på toppen ser du CPU- och minnesstatistik samlad över hela klustret.
example@sqldat.com:~# s9s process --top --cluster-id=1
PXC_Cluster_57 - 14:38:01 All nodes are operational.
4 hosts, 7 cores, 2.2 us, 3.1 sy, 94.7 id, 0.0 wa, 0.0 st,
GiB Mem : 2.9 total, 0.2 free, 0.9 used, 0.2 buffers, 1.6 cached
GiB Swap: 3 total, 0 used, 3 free,Nedan hittar du listan över processer från alla noder i klustret.
PID USER HOST PR VIRT RES S %CPU %MEM COMMAND
8331 root 10.0.2.15 20 743748 40948 S 10.28 5.40 cmon
26479 root 10.0.0.226 20 278532 6448 S 2.49 0.85 accounts-daemon
5466 root 10.0.0.226 20 95372 7132 R 1.72 0.94 sshd
651 root 10.0.0.227 20 278416 6184 S 1.37 0.82 accounts-daemon
716 root 10.0.0.228 20 278304 6052 S 1.35 0.80 accounts-daemon
22447 n/a 10.0.0.226 20 2744444 148820 S 1.20 19.63 mysqld
975 mysql 10.0.0.228 20 2733624 115212 S 1.18 15.20 mysqld
13691 n/a 10.0.0.227 20 2734104 130568 S 1.11 17.22 mysqldDetta kan vara extremt användbart om du behöver ta reda på vad som orsakar belastningen och vilken nod som är mest påverkad.
Förhoppningsvis gör CLI-verktyget det lättare för dig att integrera ClusterControl med externa skript och infrastrukturverktyg för orkestrering. Vi hoppas att du kommer att gilla att använda det här verktyget och om du har feedback om hur du kan förbättra det får du gärna meddela oss.