För att driva en databas effektivt måste du ha insikt i databasprestanda. Detta kanske inte är självklart när allt går bra, men så fort något går fel kan tillgång till information vara avgörande för att snabbt och korrekt diagnostisera problemet.
Alla databaser gör en del av sin interna statusdata tillgänglig för användarna. I MySQL kan du få denna data mestadels genom att köra 'VISA STATUS' och 'VISA GLOBAL STATUS', genom att köra 'VISA ENGINE INNODB STATUS', kontrollera informationsschematabeller och, i nyare versioner, genom att fråga prestandaschematabeller.

Dessa metoder är långt ifrån bekväma i den dagliga verksamheten, därav populariteten för olika övervaknings- och trendlösningar. Verktyg som Nagios/Icinga är designade för att titta på värdar/tjänster och varna när en tjänst hamnar utanför ett acceptabelt intervall. Andra verktyg som Cacti och Munin ger en grafisk titt på värd-/tjänstinformation och ger historisk kontext till prestanda och användning. ClusterControl kombinerar dessa två typer av övervakning, så vi ska ta en titt på informationen den presenterar och hur vi ska tolka den.
Om du använder Galera Cluster (MySQL Galera Cluster av Codership eller MariaDB Cluster eller Percona XtraDB Cluster), kanske du har märkt följande avsnitt på ClusterControls "Översikt"-flik:
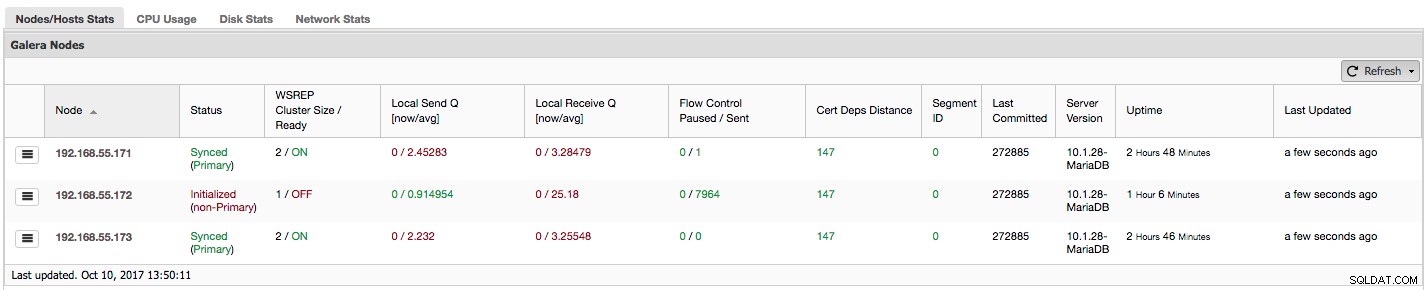
Låt oss se, steg för steg, vilken typ av data vi har här.
Den första kolumnen innehåller listan över noder med deras IP-adresser – det finns inte mycket mer att säga om det.
Andra kolumnen är mer intressant – den beskriver nodstatus (wsrep_local_state_comment status). En nod kan vara i olika tillstånd:
- Initialiserad – Noden är igång, men den är inte en del av ett kluster. Det kan till exempel orsakas av nätverksproblem;
- Gå med – Noden håller på att gå med i klustret och den tar antingen emot eller begär en tillståndsöverföring från en av andra noder;
- Donator/Desynkroniserad - Noden fungerar som en donator till någon annan nod som ansluter sig till klustret;
- Ansluten - Noden är ansluten till klustret men den är upptagen med att komma ikapp skrivuppsättningar;
- Synkroniserad - Noden fungerar normalt.
I samma kolumn inom parentes finns klusterstatusen (wsrep_cluster_status status). Den kan ha tre distinkta tillstånd:
- Primär – kommunikationen mellan noder fungerar och kvorum är närvarande (majoriteten av noderna är tillgängliga)
- Icke-primär – Noden var en del av klustret men av någon anledning förlorade den kontakten med resten av klustret. Som ett resultat av detta anses denna nod vara inaktiv och den accepterar inte frågor
- Kopplad från - Noden kunde inte upprätta gruppkommunikation.
"WSREP Cluster Size / Ready" berättar om en klusterstorlek som noden ser den och om noden är redo att acceptera frågor. Icke-primära komponenter skapar ett kluster med storleken 1 och wsrep-beredskapen är AV.
Låt oss ta en titt på skärmdumpen ovan och se vad den säger oss om Galera. Vi kan se tre noder. Två av dem (192.168.55.171 och 192.168.55.173) är helt ok, de är båda "Synced" och klustret är i "Primärt" tillstånd. Klustret består för närvarande av två noder. Nod 192.168.55.172 är "initierad" och den utgör en "icke-primär" komponent. Det betyder att den här noden tappade anslutningen till klustret - troligen något slags nätverksproblem (i själva verket använde vi iptables för att blockera en trafik till denna nod från både 192.168.55.171 och 192.168.55.173).
I detta ögonblick måste vi stanna upp lite och beskriva hur Galera Cluster fungerar internt. Vi går inte in på för mycket detaljer eftersom det inte ligger inom ramen för detta blogginlägg, men viss kunskap krävs för att förstå vikten av data som presenteras i nästa kolumner.
Galera är ett "nästan" synkront multi-masterkluster. Det betyder att du bör förvänta dig att data överförs över noder "virtuellt" samtidigt (inga mer irriterande problem med eftersläpande slavar) och att du kan skriva till vilken nod som helst i ett kluster (inga mer irriterande problem med att främja en slav till master ). För att åstadkomma det använder Galera skrivuppsättningar - atomära ändringar som replikeras över klustret. En skrivuppsättning kan innehålla flera radändringar och ytterligare nödvändig information som data angående låsning.
När en klient utfärdar COMMIT, men innan MySQL faktiskt begår någonting, skapas en skrivuppsättning som skickas till alla noder i klustret för certifiering. Alla noder kontrollerar om det är möjligt att genomföra ändringarna eller inte (eftersom ändringar kan störa andra skrivningar som utförs, under tiden, direkt på en annan nod). Om ja, data begås faktiskt av MySQL, om inte exekveras återställning.
Det som är viktigt att komma ihåg är det faktum att noder, liknande slavar i vanlig replikering, kan fungera annorlunda - vissa kan ha bättre hårdvara än andra, vissa kan vara mer laddade än andra. Ändå kräver Galera att de behandlar skrivuppsättningarna på ett kort och snabbt sätt, för att upprätthålla "virtuell" synkronisering. Det måste finnas en mekanism som kan strypa replikeringen och tillåta långsammare noder att hålla jämna steg med resten av klustret.
Låt oss ta en titt på kolumnerna "Local Send Q [nu/avg]" och "Local Receive Q [now/avg]". Varje nod har en lokal kö för att skicka och ta emot skrivuppsättningar. Det gör det möjligt att parallellisera en del av skriv- och ködata som inte kunde bearbetas på en gång om noden inte kan hänga med i trafiken. I VISA GLOBAL STATUS kan vi hitta åtta räknare som beskriver båda köerna, fyra räknare per kö:
- wsrep_local_send_queue - aktuellt tillstånd för sändningskön
- wsrep_local_send_queue_min - minimum sedan FLUSH STATUS
- wsrep_local_send_queue_max - maximalt sedan FLUSH STATUS
- wsrep_local_send_queue_avg - genomsnitt sedan SPOLNINGSSTATUS
- wsrep_local_recv_queue - aktuellt tillstånd för mottagningskön
- wsrep_local_recv_queue_min - minimum sedan FLUSH STATUS
- wsrep_local_recv_queue_max - maximalt sedan FLUSH STATUS
- wsrep_local_recv_queue_avg - genomsnitt sedan SPOLNINGSSTATUS
Ovanstående mätvärden är förenade över noder under ClusterControl -> Prestanda -> DB Status:
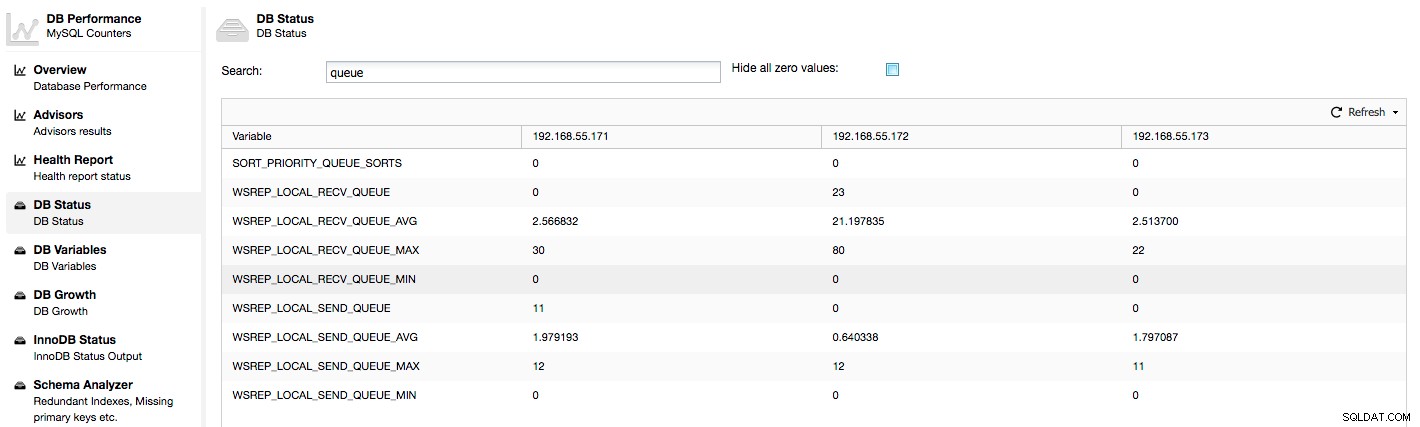
ClusterControl visar "nu" och "medelvärde"-räknare, eftersom de är de mest meningsfulla som ett enda nummer (du kan också skapa anpassade grafer baserade på variabler som beskriver köernas nuvarande tillstånd) . När vi ser att en av köerna stiger betyder det att noden inte kan hänga med i replikeringen och andra noder måste sakta ner för att den ska hinna ikapp. Vi rekommenderar att du undersöker en arbetsbelastning för den givna noden - kontrollera processlistan för några långa pågående frågor, kontrollera OS-statistik som CPU-användning och I/O-arbetsbelastning. Kanske är det också möjligt att omfördela en del av trafiken från den noden till resten av klustret.
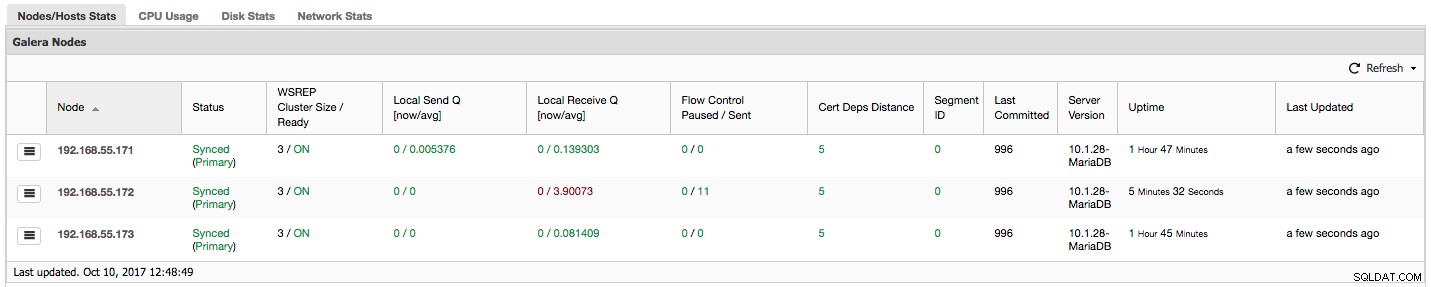
"Flödeskontroll pausad" visar information om hur många procent av tiden en given nod fick pausa sin replikering på grund av för hög belastning. När en nod inte kan hålla jämna steg med arbetsbelastningen skickar den Flow Control-paket till andra noder, och informerar dem om att de borde dra ner på att skicka skrivuppsättningar. I vår skärmdump har vi värdet "0.30" för nod 192.168.55.172. Detta betyder att nästan 30 % av tiden var den här noden tvungen att pausa replikeringen eftersom den inte kunde hålla jämna steg med skrivuppsättningscertifieringsfrekvensen som krävs av andra noder (eller enklare, för många skrivningar träffade den!). Som vi kan se är det "Local Receive Q [avg]" som pekar oss också på detta faktum.
Nästa kolumn, "Flow Control Send" ger oss information om hur många Flow Control-paket en given nod skickade till klustret. Återigen ser vi att det är nod 192.168.55.172 som saktar ner klustret.
Vad kan vi göra med denna information? För det mesta bör vi undersöka vad som händer i den långsamma noden. Kontrollera CPU-användning, kontrollera I/O-prestanda och nätverksstatistik. Detta första steg hjälper till att bedöma vilken typ av problem vi står inför.
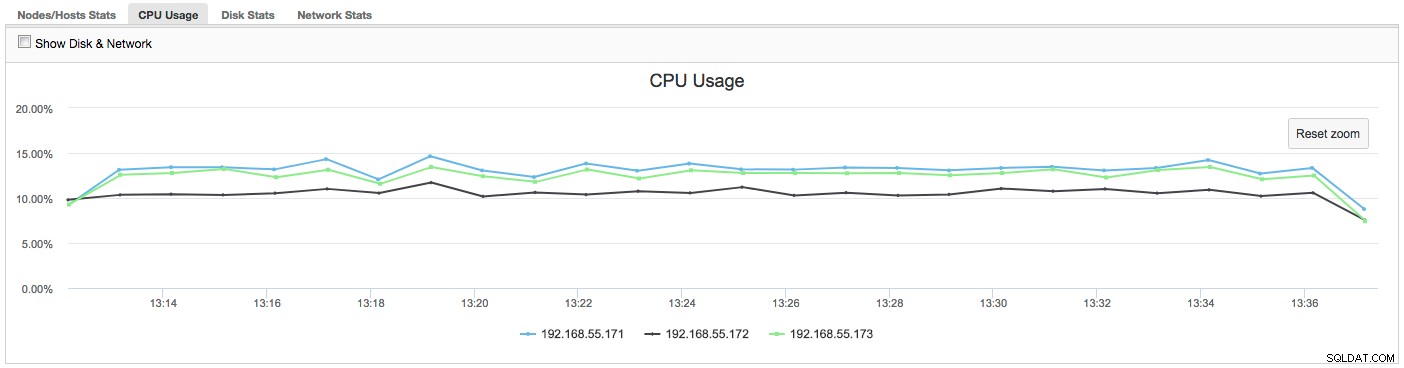
I det här fallet, när vi byter till fliken CPU-användning, blir det tydligt att omfattande CPU-användning orsakar våra problem. Nästa steg skulle vara att identifiera den skyldige genom att titta in i PROCESSLISTA (Frågeövervakare -> Kör frågor -> filtrera efter 192.168.55.172) för att leta efter stötande frågor:
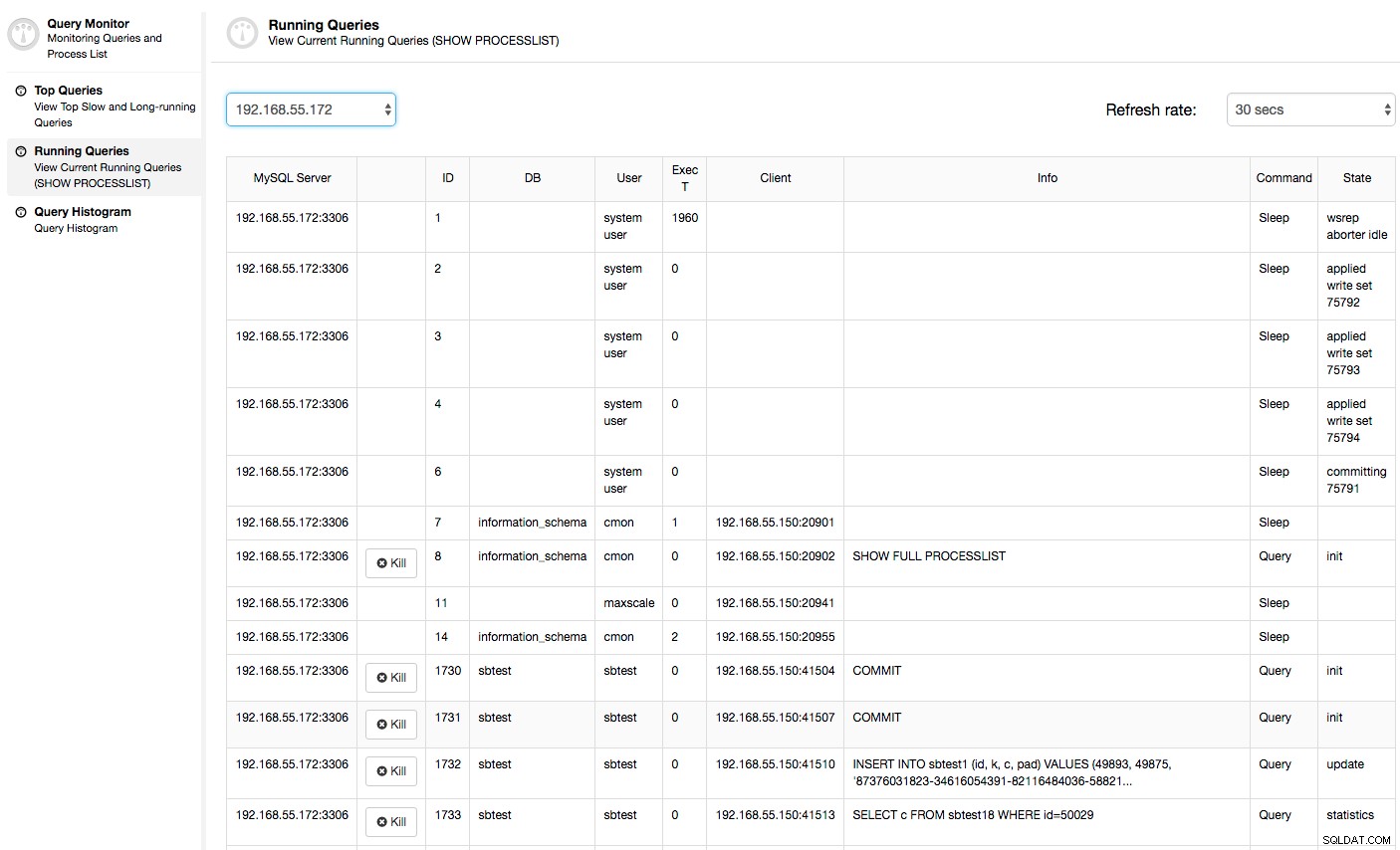
Eller kontrollera processer på noden från operativsystemets sida (Noder -> 192.168.55.172 -> Topp) för att se om belastningen inte orsakas av något utanför Galera/MySQL.
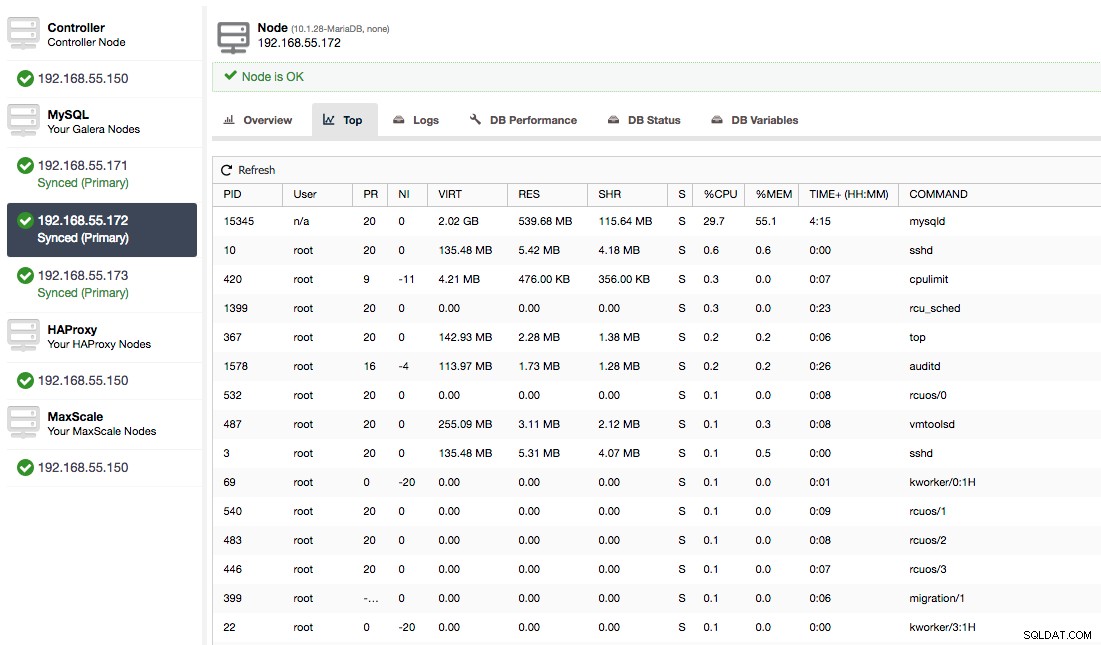
I det här fallet har vi kört mysqld-kommandot genom cpulimit, för att simulera långsam CPU-användning specifikt för mysqld-processen genom att begränsa den till 30 % av 400 % tillgänglig CPU (servern har 4 kärnor).
Kolumnen "Cert Deps Distance" ger oss information om hur många skrivuppsättningar som i genomsnitt kan appliceras parallellt. Skrivuppsättningar kan ibland köras samtidigt - Galera drar fördel av detta genom att använda flera wsrep_slave_threads att tillämpa skrivuppsättningar. Den här kolumnen ger dig en uppfattning om hur många slavtrådar du kan använda för din arbetsbelastning. Det är värt att notera att det inte är någon idé att konfigurera wsrep_slave_threads variabel till värden högre än du ser i den här kolumnen eller i wsrep_cert_deps_distance statusvariabel, på vilken kolumnen "Cert Deps Distance" är baserad. En annan viktig anmärkning - det är ingen idé att ställa in wsrep_slave_threads variabel till fler än antalet kärnor som din CPU har.
"Segment ID" - den här kolumnen kommer att kräva lite mer förklaring. Segment är en ny funktion som lagts till i Galera 3.0. Före denna version utbyttes skrivuppsättningar mellan alla noder. Låt oss säga att vi har två datacenter:
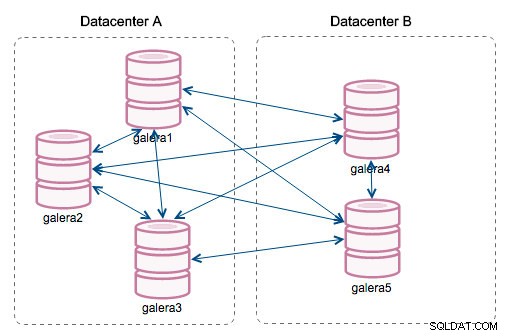
Den här typen av chatter fungerar ok på lokala nätverk men WAN är en annan historia - certifieringen saktar ner på grund av ökad latens, extra kostnader genereras på grund av nätverksbandbredd som används för att överföra skrivuppsättningar mellan varje medlem i klustret.
Med introduktionen av "Segment" förändrades saker. Du kan tilldela en nod till ett segment genom att ändra wsrep_provider_options variabel och lägga till "gmcast.segment=x" (0, 1, 2) till den. Noder med samma segmentnummer behandlas som de är i samma datacenter, anslutna via lokalt nätverk. Vår graf blir då annorlunda:
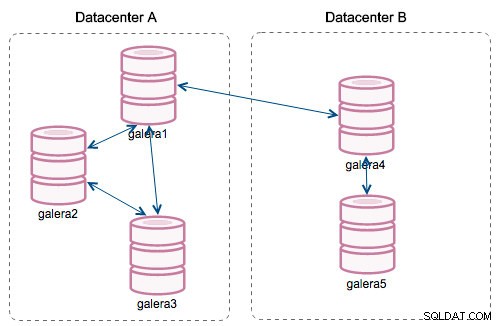
Den största skillnaden är att det inte längre är alla till allas kommunikation. Inom varje segment, ja - det är fortfarande samma mekanism men båda segmenten kommunicerar endast genom en enda anslutning mellan två valda noder. I händelse av driftstopp, kommer denna anslutning att failover automatiskt. Som ett resultat får vi mindre nätverksprat och mindre bandbreddsanvändning mellan fjärrdatacenter. Så i princip talar kolumnen "Segment ID" till vilket segment en nod är tilldelad.
Kolumnen "Last Committed" ger oss information om sekvensnumret för skrivuppsättningen som senast kördes på en given nod. Det kan vara användbart för att avgöra vilken nod som är den mest aktuella om det finns ett behov av att bootstrapa klustret.
Resten av kolumnerna är självförklarande:Serverversion, drifttid för en nod och när statusen uppdaterades.
Som du kan se ger avsnittet "Galera Nodes" i "Nodes/Hosts Stats" på fliken "Översikt" dig en ganska bra förståelse för klustrets hälsa - om det utgör en "Primär" komponent, hur många noder som är friska , finns det några prestandaproblem med vissa noder och om ja, vilken nod saktar ner klustret.
Denna uppsättning data är väldigt praktisk när du använder ditt Galera-kluster, så förhoppningsvis slipper du flyga i blindo längre :-)