Vikten av failover
Failover är en av de viktigaste databasmetoderna för databasstyrning. Det är användbart inte bara när du hanterar stora databaser i produktionen, utan också om du vill vara säker på att ditt system alltid är tillgängligt när du kommer åt det - särskilt på applikationsnivå.
Innan en failover kan ske måste dina databasinstanser uppfylla vissa krav. Dessa krav är i själva verket mycket viktiga för hög tillgänglighet. Ett av kraven som dina databasinstanser måste uppfylla är redundans. Redundans gör det möjligt för failover att fortsätta, där redundansen är inställd för att ha en failover-kandidat som kan vara en replik (sekundär) nod eller från en pool av repliker som fungerar som standby- eller hot-standby-noder. Kandidaten väljs antingen manuellt eller automatiskt baserat på den mest avancerade eller uppdaterade noden. Vanligtvis skulle du vilja ha en replika i hot standby eftersom den kan rädda din databas från att hämta index från disken eftersom ett hot standby ofta fyller index i databasens buffertpool.
Failover är termen som används för att beskriva att en återställningsprocess har inträffat. Före återställningsprocessen inträffar detta när en primär (eller huvud) databasnod misslyckas efter en krasch, efter naturkatastrofer, efter ett maskinvarufel, eller den kan ha drabbats av en nätverkspartitionering; dessa är de vanligaste fallen varför en failover kan äga rum. Återställningsprocessen fortsätter vanligtvis automatiskt och söker sedan efter den mest önskade och uppdaterade sekundära (replika) som nämnts tidigare.
Avancerad failover
Även om återställningsprocessen under en failover är automatisk, finns det vissa tillfällen då det inte är nödvändigt att automatisera processen, och en manuell process måste ta över. Komplexitet är ofta den viktigaste faktorn som är förknippad med tekniken som omfattar hela stacken av din databas - automatisk failover kan också blandas med manuell failover.
I de flesta dagliga överväganden med att hantera databaser är majoriteten av farhågorna kring automatisk failover verkligen inte triviala. Det är ofta praktiskt att implementera och ställa in en automatisk failover om problem uppstår. Även om det låter lovande eftersom det täcker komplexitet, kommer de avancerade failover-mekanismerna och som involverar "före"-händelser och "post"-händelserna som är knutna som krokar i en failover-programvara eller -teknik.
Dessa före- och efterhändelser kommer med antingen kontroller eller vissa åtgärder som ska utföras innan det äntligen kan fortsätta med failover, och efter att en failover är gjord, kommer vissa rensningar för att se till att failover äntligen lyckas ett. Lyckligtvis finns det tillgängliga verktyg som tillåter, inte bara automatiska failover, utan även funktioner för att applicera pre- och post script hooks.
I den här bloggen kommer vi att använda ClusterControl (CC) automatisk failover och kommer att förklara hur man använder pre- och post script-hooks och vilket kluster de gäller.
ClusterControl-replikeringsfel
ClusterControl-felöver-mekanismen är effektivt tillämpbar över asynkron replikering som är tillämplig på MySQL-varianter (MySQL/Percona Server/MariaDB). Det är tillämpligt på PostgreSQL/TimescaleDB-kluster också - ClusterControl stöder strömmande replikering. MongoDB- och Galera-kluster har sin egen mekanism för automatisk failover inbyggd i sin egen databasteknologi. Läs mer om hur ClusterControl utför automatisk databasåterställning och failover.
ClusterControl-failover fungerar inte om inte nod- och klusteråterställningen (Autoåterställning är aktiverad). Det betyder att dessa knappar ska vara gröna.

Dokumentationen anger att dessa konfigurationsalternativ också kan användas för att aktivera / inaktivera följande:
| enable_cluster_autorecovery= |
|
| enable_node_autorecovery= |
|
$ systemctl restart cmon
För den här bloggen fokuserar vi huvudsakligen på hur man använder pre/post-skriptkroken, vilket i grunden är en stor fördel för avancerad replikeringsfailover.
Stöd för kluster-failover-replikering före/efter skript
Som nämnts tidigare stöder MySQL-varianter som använder asynkron (inklusive semisynkron) replikering och strömmande replikering för PostgreSQL/TimescaleDB denna mekanism. ClusterControl har följande konfigurationsalternativ som kan användas för pre och post script hooks. I grund och botten kan dessa konfigurationsalternativ ställas in via deras konfigurationsfiler eller kan ställas in via webbgränssnittet (vi kommer att ta itu med detta senare).
Vår dokumentation anger att dessa är följande konfigurationsalternativ som kan ändra failover-mekanismen genom att använda pre/post script-hooks:
| replication_pre_failover_script= |
|
| replication_post_failover_script= |
|
| replication_post_unsuccessful_failover_script= |
|
Tekniskt sett, när du väl har ställt in följande konfigurationsalternativ i din /etc/cmon.d/cmon_
$ systemctl restart cmonAlternativt kan du också ställa in konfigurationsalternativen genom att gå till
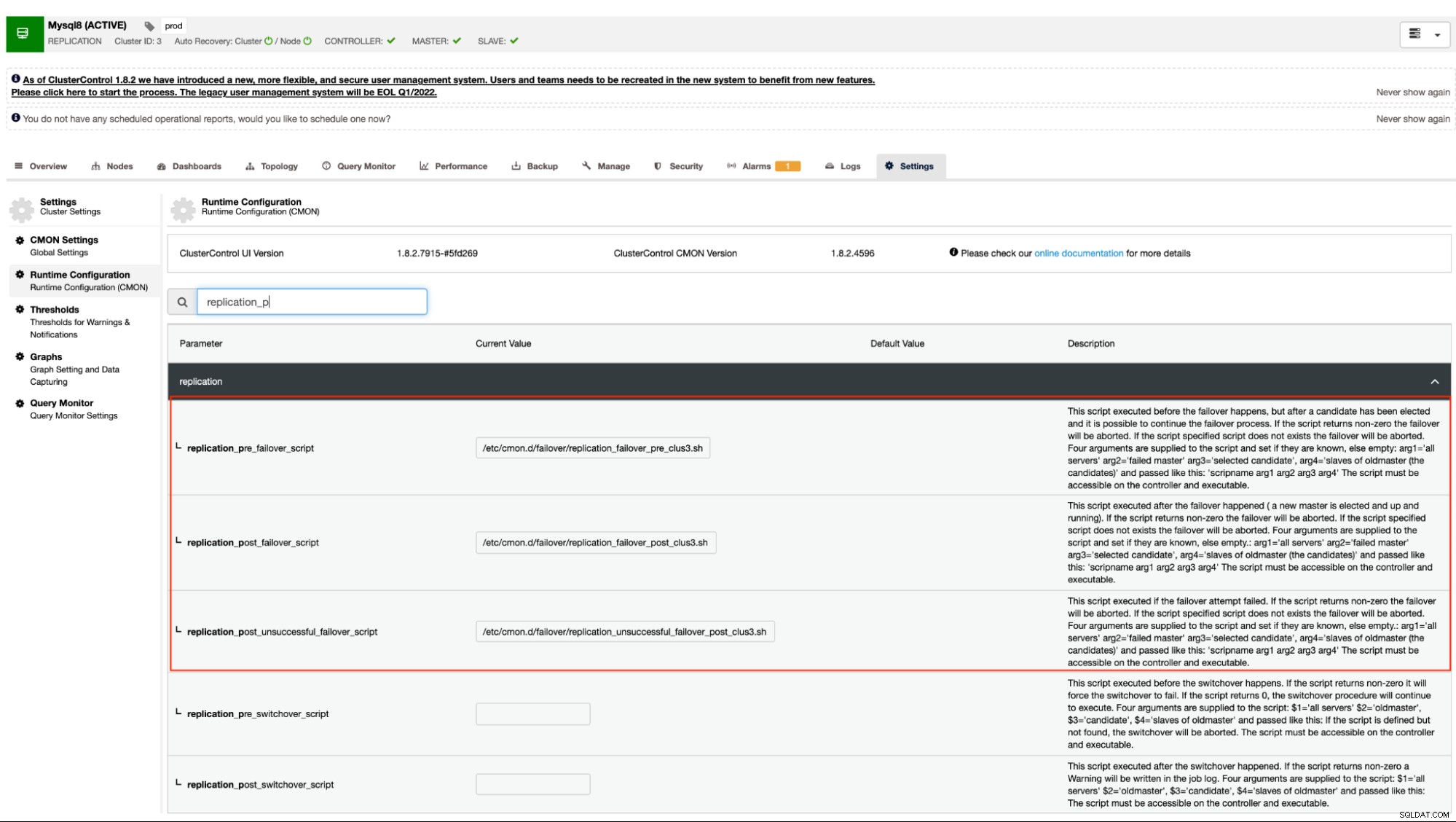
Det här tillvägagångssättet skulle fortfarande kräva en omstart till cmon-tjänsten innan det kan återspegla ändringar gjorda för dessa konfigurationsalternativ för pre/post script hooks.
Exempel på pre/post script hooks
I idealfallet är pre/post-skriptkroken dedikerade när du behöver en avancerad failover för vilken ClusterControl inte kunde hantera komplexiteten i din databasinstallation. Till exempel, om du driver olika datacenter med skärpt säkerhet och du vill avgöra om varningen om att nätverket inte kan nås inte är ett falskt positivt larm. Den måste kontrollera om primär och slav kan nå varandra och vice versa och den kan också nå från databasnoderna som går till ClusterControl-värden.
Låt oss göra det i vårt exempel och visa hur du kan dra nytta av det.
Serverinformation och skripten
I det här exemplet använder jag ett MariaDB-replikeringskluster med bara en primär och en replik. Hanteras av ClusterControl för att hantera failover.
ClusterControl =192.168.40.110
primär (debnode5) =192.168.30.50
replika (debnode9) =192.168.30.90
I den primära noden, skapa skriptet enligt nedan,
example@sqldat.com:~# cat /opt/pre_failover.sh
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat >> /tmp/debnode5.tmp"Se till att /opt/pre_failover.sh är körbar, dvs.
$ chmod +x /opt/pre_failover.shAnvänd sedan detta skript för att vara involverad via cron. I det här exemplet skapade jag filen /etc/cron.d/ccfailover och har följande innehåll:
example@sqldat.com:~# cat /etc/cron.d/ccfailover
#!/bin/bash
* * * * * vagrant /opt/pre_failover.shI din replik, använd bara följande steg vi gjorde för den primära förutom att ändra värdnamnet. Se följande av vad jag har nedan i min replik:
example@sqldat.com:~# tail -n+1 /etc/cron.d/ccfailover /opt/pre_failover.sh
==> /etc/cron.d/ccfailover <==
#!/bin/bash
* * * * * vagrant /opt/pre_failover.sh
==> /opt/pre_failover.sh <==
#!/bin/bash
date -u +%s | ssh -i /home/vagrant/.ssh/id_rsa example@sqldat.com -T "cat > /tmp/debnode9.tmp"och se till att skriptet som anropas i vår cron är körbart,
example@sqldat.com:~# ls -alth /opt/pre_failover.sh
-rwxr-xr-x 1 root root 104 Jun 14 05:09 /opt/pre_failover.shClusterControl före/efter skript
I den här demonstrationen är mitt cluster_id 3. Som nämnts tidigare i vår dokumentation kräver det att dessa skript måste finnas i vår CC-styrenhetsvärd. Så i min /etc/cmon.d/cmon_3.cnf har jag följande:
[example@sqldat.com cmon.d]# tail -n3 /etc/cmon.d/cmon_3.cnf
replication_pre_failover_script = /etc/cmon.d/failover/replication_failover_pre_clus3.sh
replication_post_failover_script = /etc/cmon.d/failover/replication_failover_post_clus3.sh
replication_post_unsuccessful_failover_script = /etc/cmon.d/failover/replication_unsuccessful_failover_post_clus3.shMedan följande "pre" failover-skript avgör om båda noderna kunde nå CC-styrenhetens värd. Se följande:
[example@sqldat.com cmon.d]# tail -n+1 /etc/cmon.d/failover/replication_failover_pre_clus3.sh
#!/bin/bash
arg1=$1
debnode5_tstamp=$(tail /tmp/debnode5.tmp)
debnode9_tstamp=$(tail /tmp/debnode9.tmp)
cc_tstamp=$(date -u +%s)
diff_debnode5=$(expr $cc_tstamp - $debnode5_tstamp)
diff_debnode9=$(expr $cc_tstamp - $debnode5_tstamp)
if [[ "$diff_debnode5" -le 60 && "$diff_debnode9" -le 60 ]]; then
echo "failover cannot proceed. It's just a false alarm. Checkout the firewall in your CC host";
exit 1;
elif [[ "$diff_debnode5" -gt 60 || "$diff_debnode9" -gt 60 ]]; then
echo "Either both nodes ($arg1) or one of them were not able to connect the CC host. One can be unreachable. Failover proceed!";
exit 0;
else
echo "false alarm. Failover discarded!"
exit 1;
fi
Whereas my post scripts just simply echoes and redirects the output to a file, just for the test.
[example@sqldat.com failover]# tail -n+1 replication_*_post*3.sh
==> replication_failover_post_clus3.sh <==
#!/bin/bash
echo "post failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_failover_script_cid3.txt
==> replication_unsuccessful_failover_post_clus3.sh <==
#!/bin/bash
echo "post unsuccessful failover script on cluster 3 with args: example@sqldat.com" > /tmp/post_unsuccessful_failover_script_cid3.txt
Demo av failover
Nu ska vi försöka simulera nätverksavbrott på den primära noden och se hur den kommer att reagera. I min primära nod tar jag ner nätverksgränssnittet som används för att kommunicera med repliken och CC-styrenheten.
example@sqldat.com:~# ip link set enp0s8 downUnder det första försöket med failover kunde CC köra mitt prescript som finns på /etc/cmon.d/failover/replication_failover_pre_clus3.sh. Se nedan hur det fungerar:
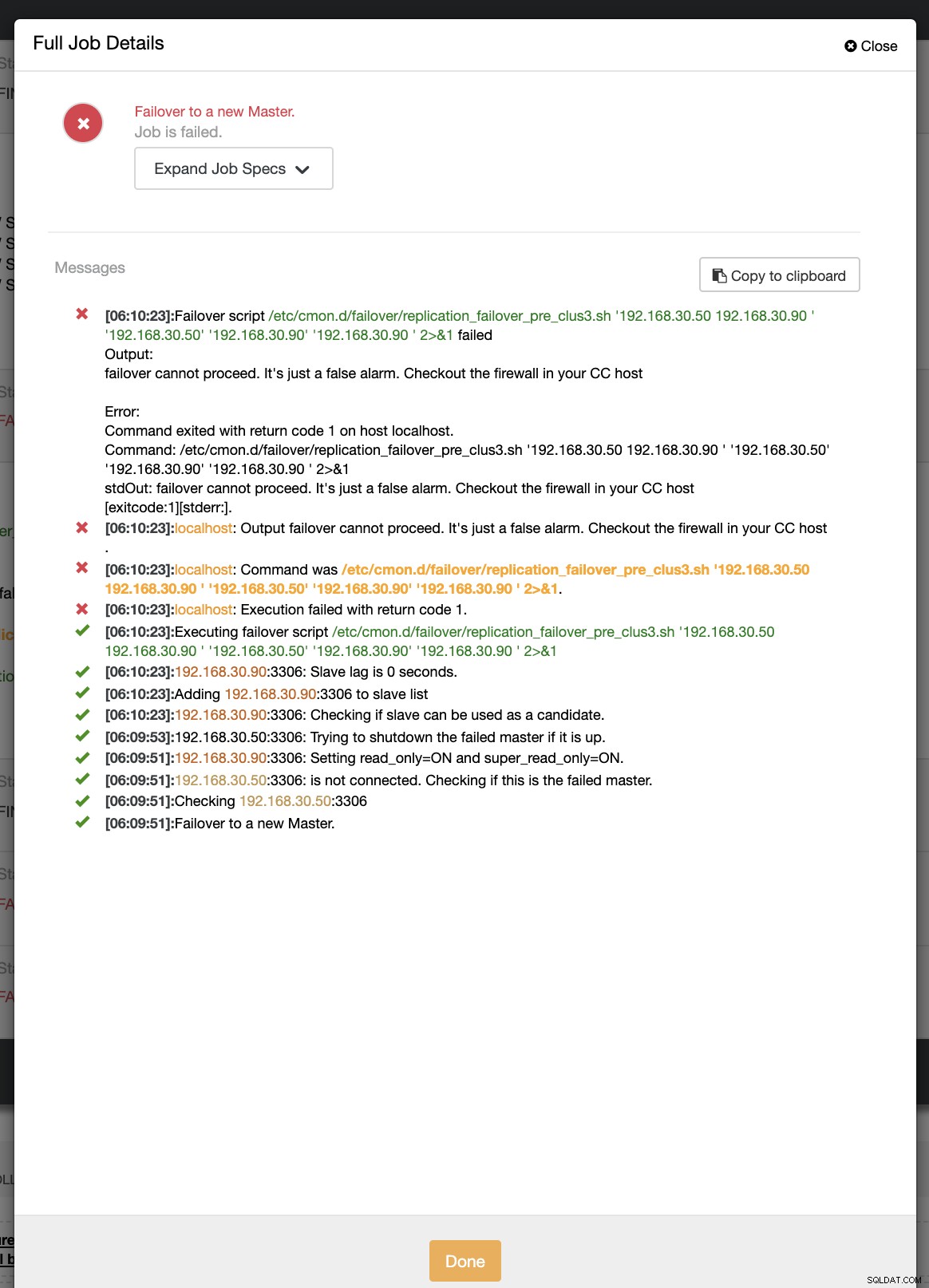
Självklart misslyckas det eftersom tidsstämpeln som har loggats ännu inte är mer än en minut eller så var det bara några sekunder sedan som den primära fortfarande kunde ansluta till CC-styrenheten. Uppenbarligen är det inte det perfekta tillvägagångssättet när du har att göra med ett verkligt scenario. ClusterControl kunde dock anropa och köra skriptet perfekt som förväntat. Vad sägs om om det verkligen når mer än en minut (dvs> 60 sekunder)?
I vårt andra försök med failover, eftersom tidsstämpeln når mer än 60 sekunder, anses det vara ett sant positivt, och det betyder att vi måste göra failover som avsett. CC har kunnat exekvera det perfekt och till och med exekvera postskriptet som avsett. Detta kan ses i jobbloggen. Se skärmdumpen nedan:
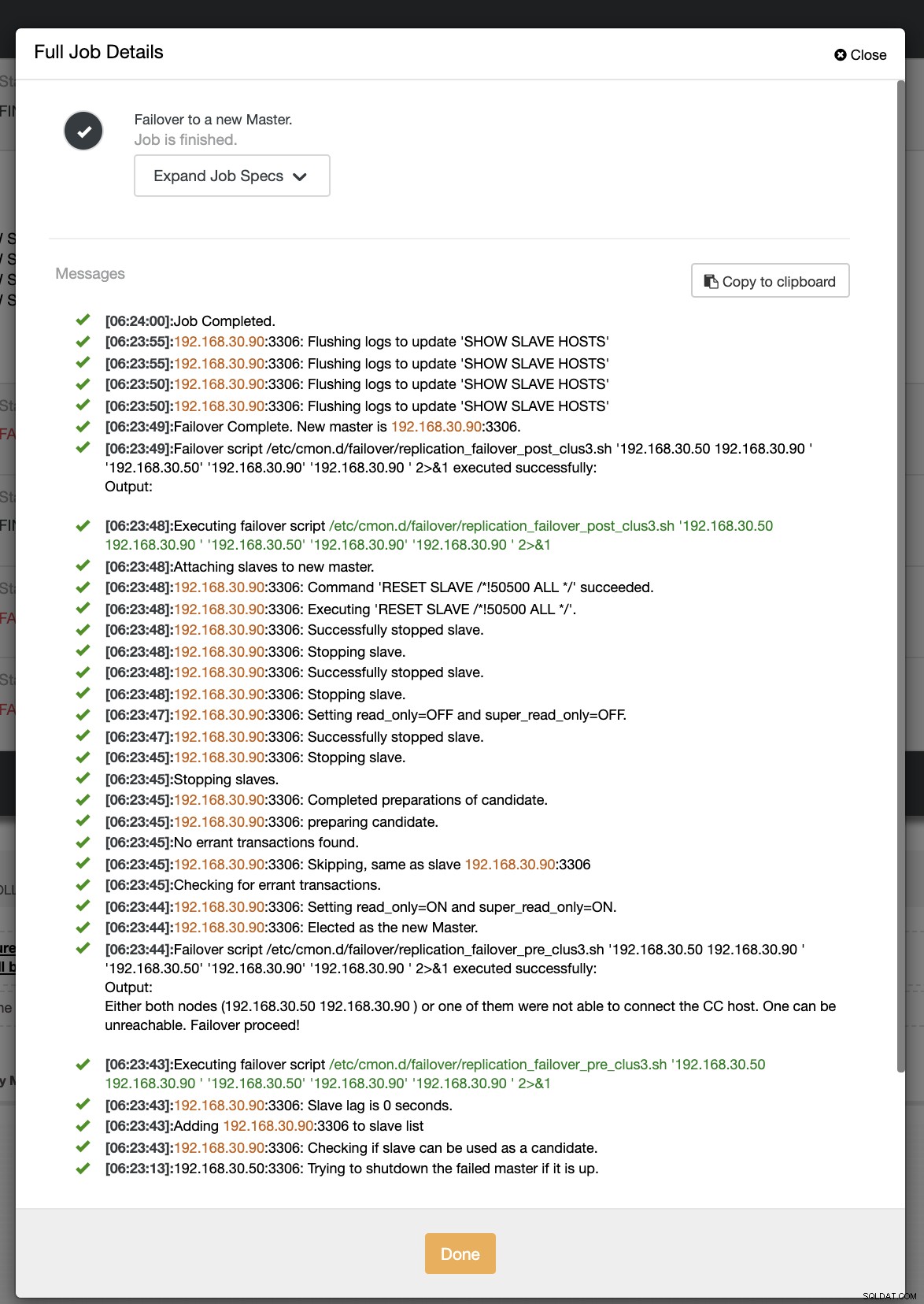
För att verifiera om mitt inläggsskript kördes kunde det skapa loggen fil i katalogen CC /tmp som förväntat,
[example@sqldat.com tmp]# cat /tmp/post_failover_script_cid3.txtlägg upp ett failover-skript på kluster 3 med args:192.168.30.50 192.168.30.90 192.168.30.50 192.168.30.90 192.168.30.90
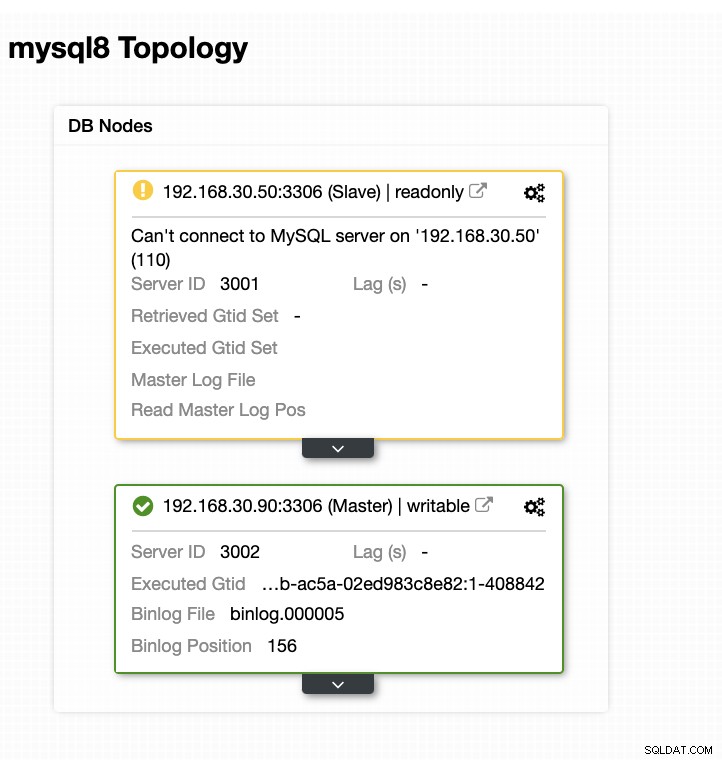
Nu har min topologi ändrats och failover lyckades!
Slutsats
För alla komplicerade databasinställningar du kan ha, när en avancerad failover krävs, kan pre/post-skript vara till stor hjälp för att göra saker genomförbara. Eftersom ClusterControl stöder dessa funktioner har vi visat hur kraftfullt och användbart det är. Även med dess begränsningar finns det alltid sätt att göra saker genomförbara och användbara, särskilt i produktionsmiljöer.