Presto är en öppen källkod, parallelldistribuerad, SQL-motor för stordatabehandling. Det har utvecklats från grunden av Facebook. Den första interna releasen ägde rum 2013 och var en ganska revolutionerande lösning för deras stora dataproblem.
Med hundratals geografiskt placerade servrar och petabyte data började Facebook leta efter en alternativ plattform för deras Hadoop-kluster. Deras infrastrukturteam ville minska tiden som behövs för att köra batch-jobb för analys och förenkla utvecklingen av pipeline genom att använda programmeringsspråk som är allmänt känt i organisationen - SQL.
Enligt Presto Foundation, "Facebook använder Presto för interaktiva frågor mot flera interna datalager, inklusive deras 300PB datalager. Över 1 000 Facebook-anställda använder Presto dagligen för att köra mer än 30 000 frågor som totalt skannas över en petabyte varje dag."
Även om Facebook har en exceptionell datalagermiljö, finns samma utmaningar i många organisationer som arbetar med big data.
I den här bloggen kommer vi att ta en titt på hur man ställer in en grundläggande presto-miljö med hjälp av en Docker-server från tar-filen. Som datakälla kommer vi att fokusera på MySQL-datakällan, men det kan vara vilken annan populär RDBMS som helst.
Kör Presto i Big Data-miljö
Innan vi börjar, låt oss ta en snabb titt på dess huvudsakliga arkitekturprinciper. Presto är ett alternativ till verktyg som söker efter HDFS med hjälp av pipelines av MapReduce-jobb - som Hive. Till skillnad från Hive använder Presto inte MapReduce. Presto körs med en sökmotor för speciella ändamål med operatörer på hög nivå och bearbetning i minnet.
I motsats till Hive kan Presto strömma data genom alla steg samtidigt som databitar körs samtidigt. Den är utformad för att köra ad-hoc analytiska frågor mot enstaka eller distribuerade heterogena datakällor. Den kan nå ut från en Hadoop-plattform för att söka efter relationsdatabaser eller andra datalager som platta filer.
Presto använder standard ANSI SQL inklusive aggregering, kopplingar eller analytiska fönsterfunktioner. SQL är välkänt och mycket lättare att använda jämfört med MapReduce skrivet i Java.
Distribuera Presto till Docker
Den grundläggande Presto-konfigurationen kan distribueras med en förkonfigurerad Docker-avbildning eller presto-server-tarball.
Docker-servern och Presto CLI-behållare kan enkelt distribueras med:
docker run -d -p 127.0.0.1:8080:8080 --name presto starburstdata/presto
docker exec -it presto presto-cliDu kan välja mellan två Presto-serverversioner. Community-version och Enterprise-version från Starburst. Eftersom vi kommer att köra det i en icke-produktionssandlådemiljö kommer vi att använda Apache-versionen i den här artikeln.
Förutsättningskrav
Presto implementeras helt i Java och kräver att JVM är installerat på ditt system. Det körs på både OpenJDK och Oracle Java. Minsta version är Java 8u151 eller Java 11.
För att ladda ner JAVA JDK besök https://openjdk.java.net/ eller https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
Du kan kontrollera din Java-version med
$ java -version
openjdk version "1.8.0_222"
OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_222-b10)
OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.222-b10, mixed mode)Presto-installation
För att installera Presto kommer vi att ladda ner server tar och Presto CLI jar körbar.
Tarballen kommer att innehålla en enda toppnivåkatalog, presto-server-0.223, som vi kallar installationskatalogen.
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-server/0.223/presto-server-0.223.tar.gz
$ tar -xzvf presto-server-0.223.tar.gz
$ cd presto-server-0.223/
$ wget https://repo1.maven.org/maven2/com/facebook/presto/presto-cli/0.223/presto-cli-0.223-executable.jar
$ mv presto-cli-0.223-executable.jar presto
$ chmod +x prestoDessutom behöver Presto en datakatalog för att lagra loggar, etc.
Det rekommenderas att skapa en datakatalog utanför installationskatalogen.
$ mkdir -p ~/data/presto/Den här platsen är platsen när vi börjar vår felsökning.
Konfigurera Presto
Innan vi börjar vår första instans måste vi skapa ett gäng konfigurationsfiler. Börja med att skapa en etc/-katalog i installationskatalogen. Den här platsen kommer att innehålla följande konfigurationsfiler:
etc/
- Nodegenskaper - nodmiljökonfiguration
- JVM Config (jvm.config) - Java Virtual Machine config
- Config Properties(config.properties) -konfiguration för Presto-servern
- Katalogegenskaper - konfiguration för anslutningar (datakällor)
- Loggegenskaper - Loggers konfiguration
Nedan hittar du några grundläggande konfigurationer för att köra Presto sandbox. För mer information besök dokumentationen.
vi etc/config.properties
Config.properties
coordinator = true
node-scheduler.include-coordinator = true
http-server.http.port = 8080
query.max-memory = 5GB
query.max-memory-per-node = 1GB
discovery-server.enabled = true
discovery.uri = https://localhost:8080
vi etc/jvm.config
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
vi etc/log.properties
com.facebook.presto = INFOvi etc/node.properties
node.environment = production
node.id = ffffffff-ffff-ffff-ffff-ffffffffffff
node.data-dir = /Users/bartez/data/prestoDen grundläggande etc/-strukturen kan se ut som följer:

Nästa steg är att ställa in MySQL-anslutningen.
Vi kommer att ansluta till en av de tre noderna MariaDB Cluster.
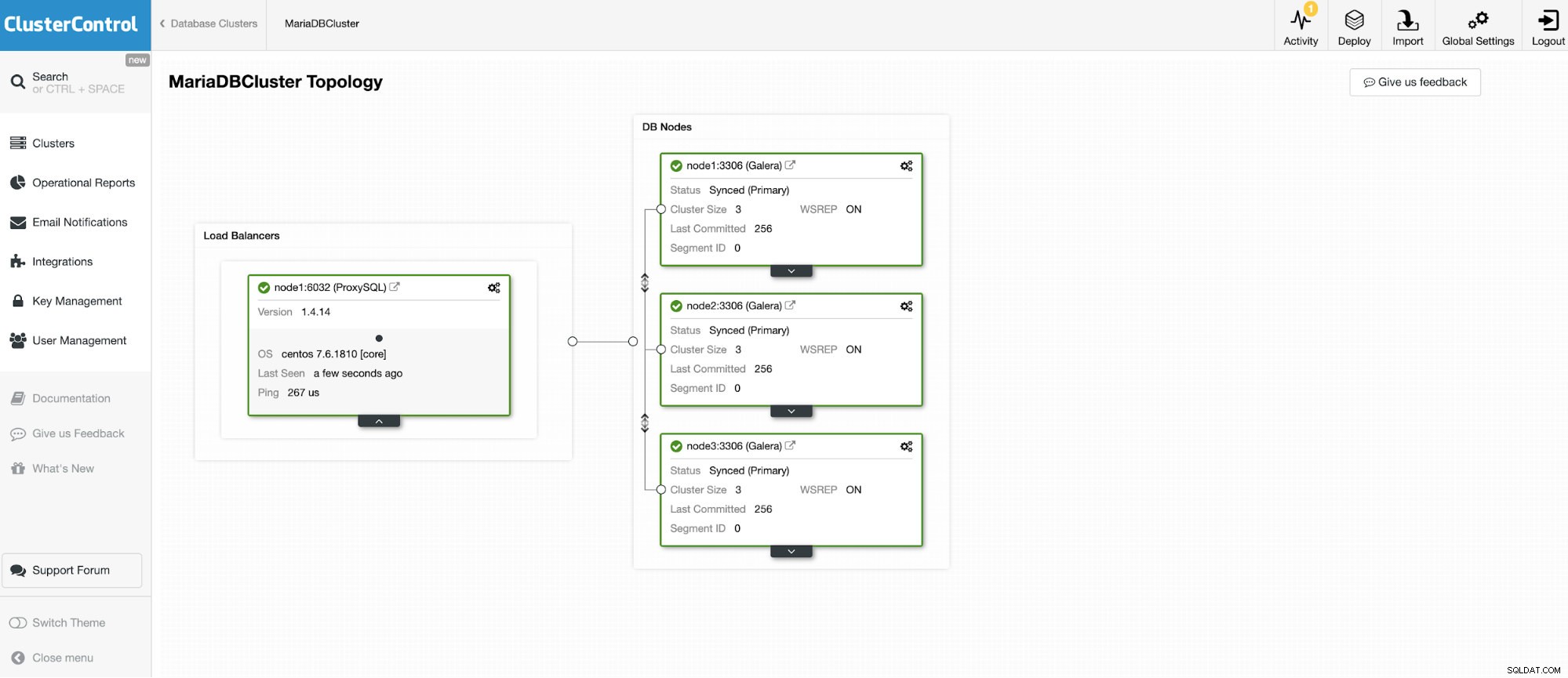
Och en annan fristående instans som kör Oracle MySQL 5.7.
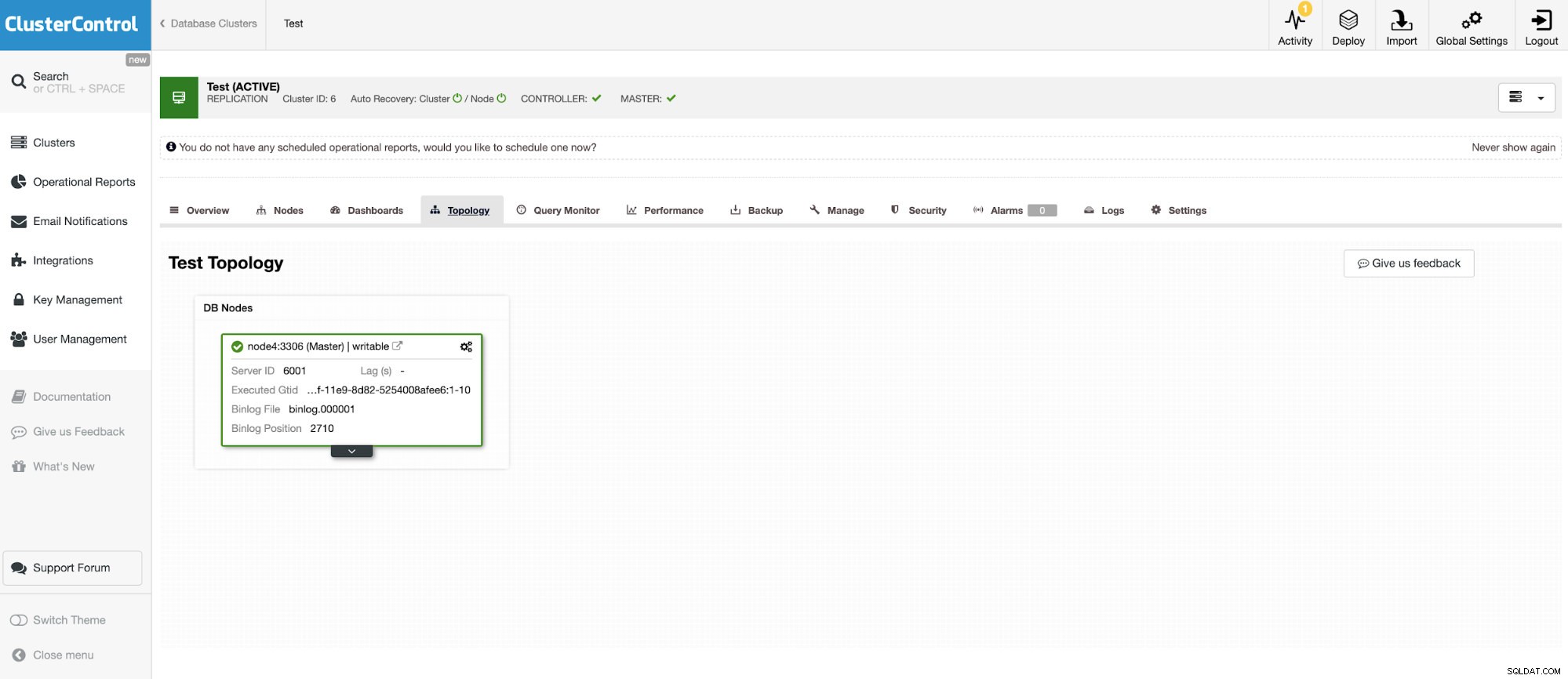
MySQL-anslutningen gör det möjligt att fråga och skapa tabeller i en extern MySQL-databas. Detta kan användas för att sammanfoga data mellan olika system som MariaDB och MySQL från Oracle.
Presto använder pluggbara kontakter och konfigurationen är mycket enkel. För att konfigurera MySQL-anslutningen, skapa en katalogegenskapersfil i etc/catalog som heter, till exempel, mysql.properties, för att montera MySQL-anslutaren som mysql-katalogen. Var och en av filerna representerar en anslutning till en annan server. I det här fallet har vi två filer:
vi etc/catalog/mysq.properties:
connector.name=mysql
connection-url=jdbc:mysql://node1.net:3306
connection-user=bart
connection-password=secretvi etc/catalog/mysq2.properties
connector.name=mysql
connection-url=jdbc:mysql://node4.net:3306
connection-user=bart2
connection-password=secretKör Presto
När allt är klart är det dags att starta Presto-instansen. För att starta presto gå till bin-katalogen under preso-installation och kör följande:
$ bin/launcher start
Started as 18363För att stoppa Presto-körningen
$ bin/launcher stopNu när servern är igång kan vi ansluta till Presto med CLI och söka efter MySQL-databas.
Så här startar du Presto-konsolkörningen:
./presto --server localhost:8080 --catalog mysql --schema employeesNu kan vi söka i våra databaser via CLI.
presto:mysql> select * from mysql.employees.departments;
dept_no | dept_name
---------+--------------------
d009 | Customer Service
d005 | Development
d002 | Finance
d003 | Human Resources
d001 | Marketing
d004 | Production
d006 | Quality Management
d008 | Research
d007 | Sales
(9 rows)
Query 20190730_232304_00019_uq3iu, FINISHED, 1 node
Splits: 17 total, 17 done (100,00%)
0:00 [9 rows, 0B] [81 rows/s, 0B/s]
Båda databaserna MariaDB-kluster och MySQL har matats med personaldatabas.
wget https://github.com/datacharmer/test_db/archive/master.zip
mysql -uroot -psecret < employees.sqlStatusen för frågan är också synlig i Presto webbkonsol:https://localhost:8080/ui/#
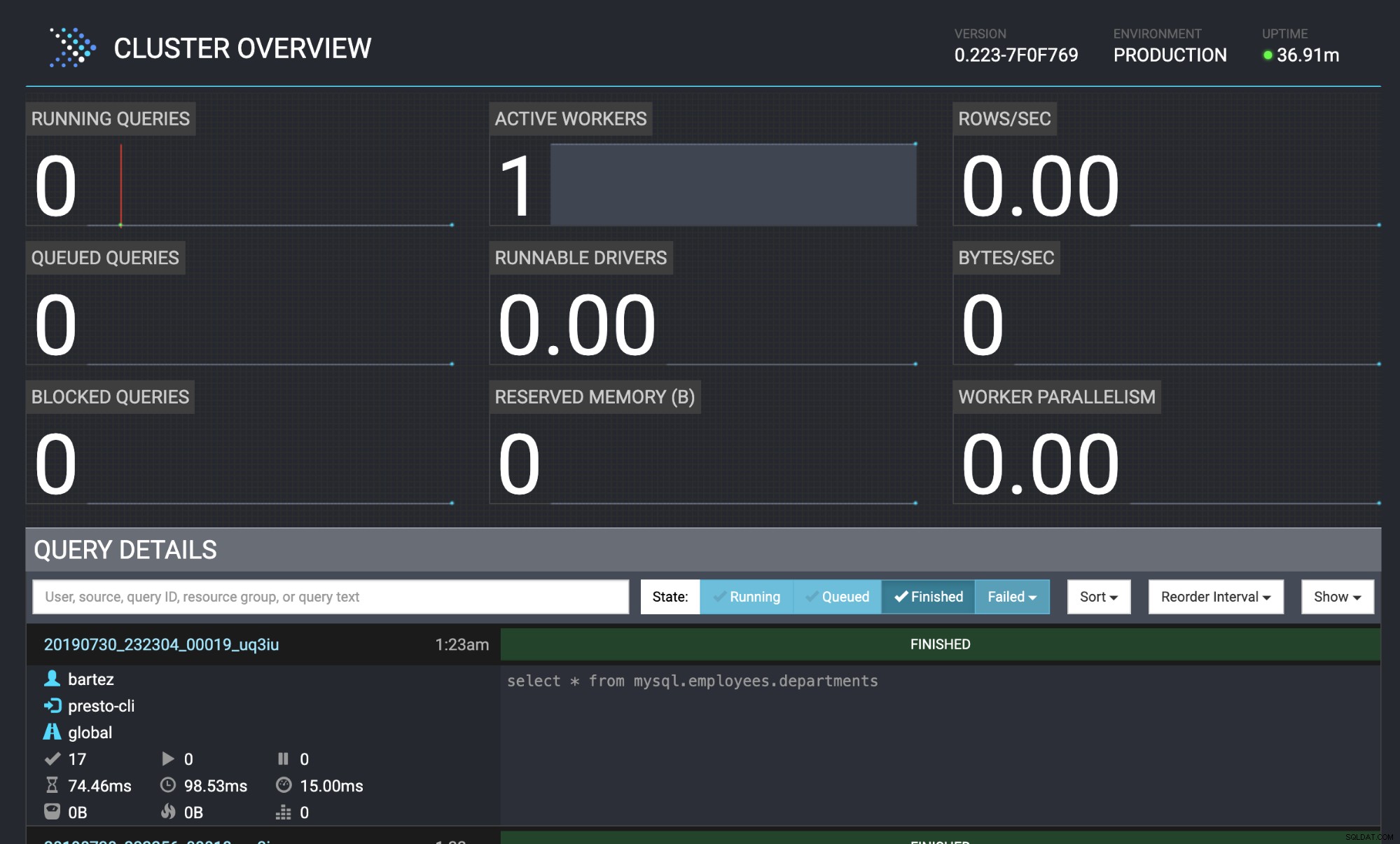 Presto-klusteröversikt
Presto-klusteröversikt Slutsats
Många välkända företag (som Airbnb, Netflix, Twitter) använder Presto för prestanda med låg latens. Det är utan tvekan mycket intressant programvara som kan eliminera behovet av att köra tunga ETL-datalagerprocesser. I den här bloggen tog vi en kort titt på MySQL-anslutningen men du kan använda den för att analysera data från HDFS, objektlager, RDBMS (SQL Server, Oracle, PostgreSQL), Kafka, Cassandra, MongoDB och många andra.