En Oracle-utvecklare som ofta använder reguljära uttryck i kod förr eller senare kan möta ett fenomen som verkligen är mystiskt. Långvariga sökande efter roten till problemet kan leda till viktminskning, aptit och provocera fram olika typer av psykosomatiska störningar – allt detta kan förebyggas med hjälp av regexp_replace-funktionen. Den kan ha upp till 6 argument:
REGEXP_REPLACE (
- källsträng,
- mall,
- ersätter_sträng,
- startpositionen för matchningssökningen med en mall (standard 1),
- en position där mallen förekommer i en källsträng (som standard är 0 lika med alla förekomster),
- modifierare (än så länge är det en mörk häst)
)
Returnerar den modifierade källsträngen där alla förekomster av mallen ersätts med värdet som skickas i parametern substituting_string. Ofta används en kort version av funktionen, där de första 3 argumenten anges, vilket räcker för att lösa många problem. Jag gör detsamma. Anta att vi måste maskera alla strängtecken med asterisker i strängen 'MASK:gemener'. För att ange omfånget av gemener bör mönstret '[a-z]' passa.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Förväntning
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Verklighet
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Om denna händelse inte har återgivits i din databas så har du tur hittills. Men oftare börjar du gräva i kod, konverterar strängar från en uppsättning tecken till en annan och så småningom kommer en förtvivlan.
Definiera ett problem
Frågan uppstår – vad är det som är så speciellt med bokstaven 'A' att den inte har ersatts eftersom resten av versalerna inte heller skulle bytas ut. Kanske finns det andra korrekta bokstäver förutom den här. Det är nödvändigt att titta på hela alfabetet med versaler.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Men
Om det sjätte argumentet för funktionen inte är explicit specificerat, till exempel är 'i' skiftlägeskänslighet eller 'c' är skiftlägeskänslighet när man jämför en källsträng med en mall, reguljärt uttryck använder parametern NLS_SORT för sessionen/databasen som standard. Till exempel:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Denna parameter specificerar sorteringsmetoden i ORDER BY. Om vi pratar om att sortera enkla individuella tecken, så motsvarar ett visst binärt tal (NLSSORT-kod) var och en av dem och sorteringen sker faktiskt efter värdet på dessa siffror.
För att illustrera detta, låt oss ta de första och sista tecknen i alfabetet, både gemener och versaler, och placera dem i en villkorligt oordnad tabelluppsättning och kalla det ABC. Låt oss sedan sortera denna uppsättning efter SYMBOL-fältet och visa dess NLSSORT-kod i HEX-format bredvid varje symbol.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
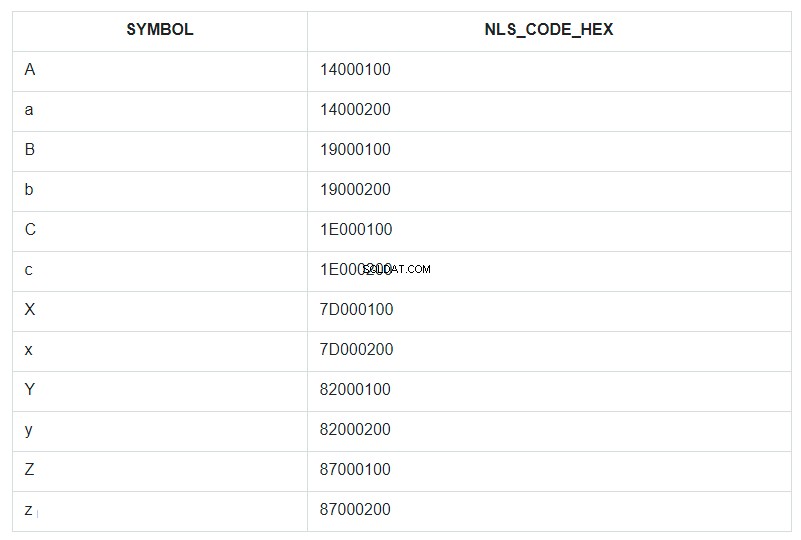
I frågan specificeras ORDER BY för SYMBOL-fältet, men i själva verket gick sorteringen i databasen efter värdena från fältet NLS_CODE_HEX.
Gå nu tillbaka till intervallet från mallen och titta på tabellen – vad är vertikalt mellan symbolen 'a' (kod 14000200) och 'z' (kod 87000200)? Allt utom den stora bokstaven 'A'. Det är allt som har ersatts med en asterisk. Och koden 14000100 i bokstaven "A" ingår inte i ersättningsintervallet från 14000200 till 87000200.
Kur
Ange explicit modifieraren av skiftlägeskänslighet
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Vissa källor säger att modifieraren 'c' är inställd som standard, men vi har precis sett att detta inte är riktigt sant. Och om någon inte såg det, är parametern NLS_SORT för dess session/databas troligen inställd på BINÄR och sorteringen utförs i överensstämmelse med riktiga teckenkoder. Faktum är att om du ändrar sessionsparametern kommer problemet att lösas.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Tester utfördes i Oracle 12c.
Lämna gärna dina kommentarer och ta hand om dig.