PostgreSQL är ett fantastiskt projekt och det utvecklas i en otrolig hastighet. Vi kommer att fokusera på utvecklingen av feltoleransfunktioner i PostgreSQL genom hela dess versioner med en serie blogginlägg. Detta är det fjärde inlägget i serien och vi kommer att prata om synkron commit och dess effekter på feltolerans och pålitlighet hos PostgreSQL.
Om du vill se utvecklingens framsteg från början, vänligen kolla de tre första blogginläggen i serien nedan. Varje inlägg är oberoende, så du behöver faktiskt inte läsa ett för att förstå ett annat.
- Utveckling av feltolerans i PostgreSQL
- Evolution av feltolerans i PostgreSQL:replikeringsfas
- Evolution av feltolerans i PostgreSQL:Tidsresor
Synchronous Commit
Som standard implementerar PostgreSQL asynkron replikering, där data strömmas ut när det passar servern. Detta kan innebära dataförlust i händelse av failover. Det är möjligt att be Postgres att kräva en (eller flera) väntelägen för att bekräfta replikering av data före commit, detta kallas synkron replikering (synkron commit ) .
Med synkron replikering fördröjer replikeringen direkt påverkar den förflutna tiden för transaktioner på mastern. Med asynkron replikering kan mastern fortsätta med full hastighet.
Synkron replikering garanterar att data skrivs till minst två noder innan användaren eller applikationen får veta att en transaktion har genomförts.
Användaren kan välja commit-läge för varje transaktion , så att det är möjligt att ha både synkrona och asynkrona commit-transaktioner som körs samtidigt.
Detta möjliggör flexibla avvägningar mellan prestanda och säkerhet för transaktionens hållbarhet.
Konfigurera Synchronous Commit
För att ställa in synkron replikering i Postgres måste vi konfigurera synchronous_commit parameter i postgresql.conf.
Parametern anger om transaktionsbekräftelse kommer att vänta på att WAL-poster skrivs till disken innan kommandot returnerar en framgång indikation till klienten. Giltiga värden är på , remote_apply , remote_write , lokal , och av . Vi kommer att diskutera hur saker och ting fungerar när det gäller synkron replikering när vi ställer in synchronous_commit parameter med vart och ett av de definierade värdena.
Låt oss börja med Postgres-dokumentation (9.6):
Här förstår vi konceptet med synkron commit, som vi beskrev i introduktionsdelen av inlägget, du är fri att ställa in synkron replikering men om du inte gör det finns det alltid en risk att förlora data. Men utan risk för att skapa databasinkonsekvens, till skillnad från att stänga av fsync off – men det är ett ämne för ett annat inlägg -. Slutligen drar vi slutsatsen att om vi behöver inte vill förlora någon data mellan replikeringsfördröjningar och vill vara säkra på att data skrivs till minst två noder innan användaren/applikationen informeras om att transaktionen har genomförts , vi måste acceptera att förlora lite prestanda.
Låt oss se hur olika inställningar fungerar för olika nivåer av synkronisering. Innan vi börjar, låt oss prata hur commit bearbetas av PostgreSQL-replikering. Klientkörningsfrågor på huvudnoden, ändringarna skrivs till en transaktionslogg (WAL) och kopieras över nätverket till WAL på standbynoden. Återställningsprocessen på standbynoden läser sedan ändringarna från WAL och applicerar dem på datafilerna precis som under kraschåterställning. Om vänteläget är i hot standby läget kan klienter utfärda skrivskyddade frågor på noden medan detta händer. För mer information om hur replikering fungerar kan du kolla in replikeringsblogginlägget i den här serien.
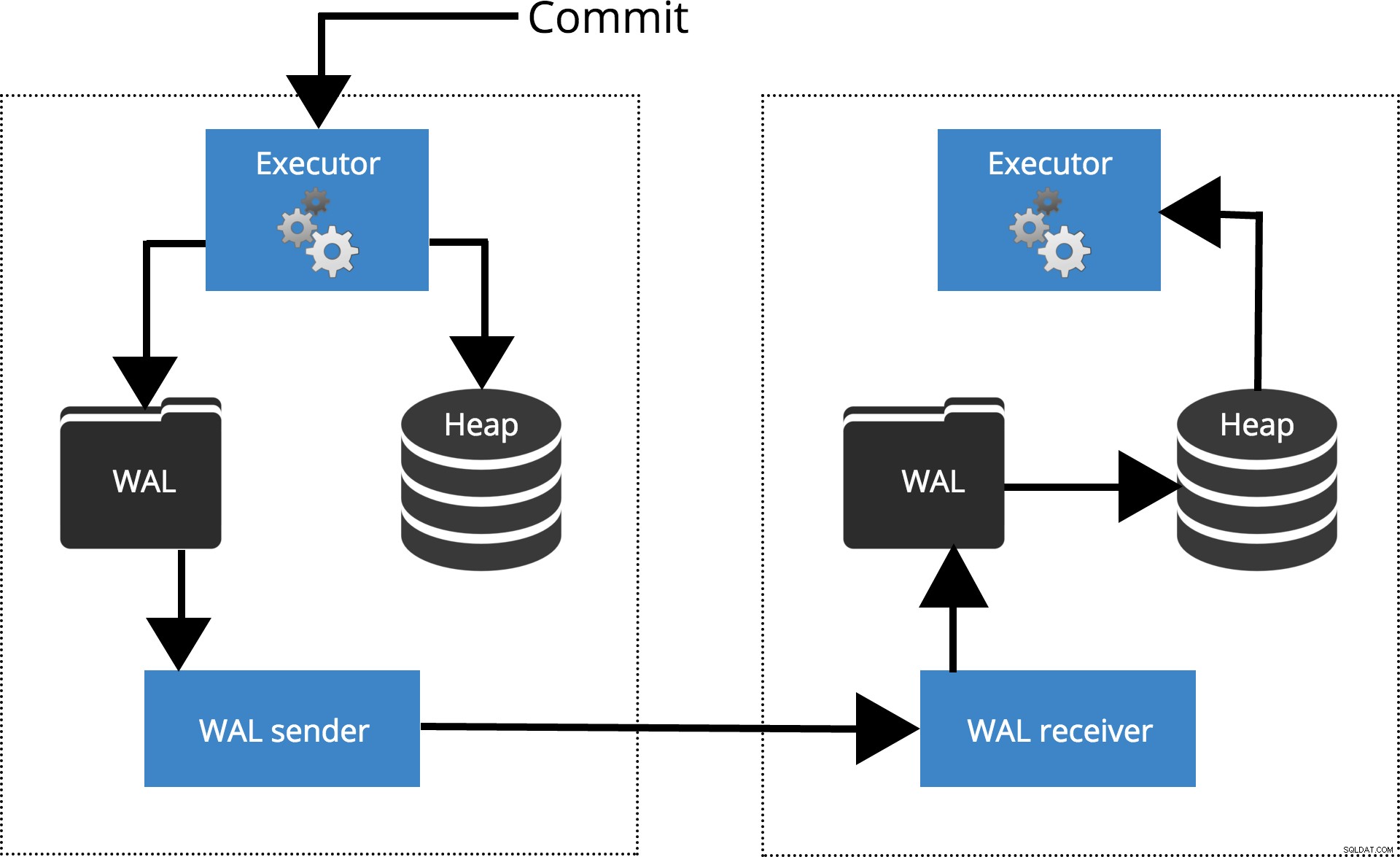
Fig.1 Hur replikering fungerar
synchronous_commit =av
När vi ställer in sychronous_commit = off, COMMIT väntar inte på att transaktionsposten ska spolas till disken. Detta är markerat i Fig.2 nedan.
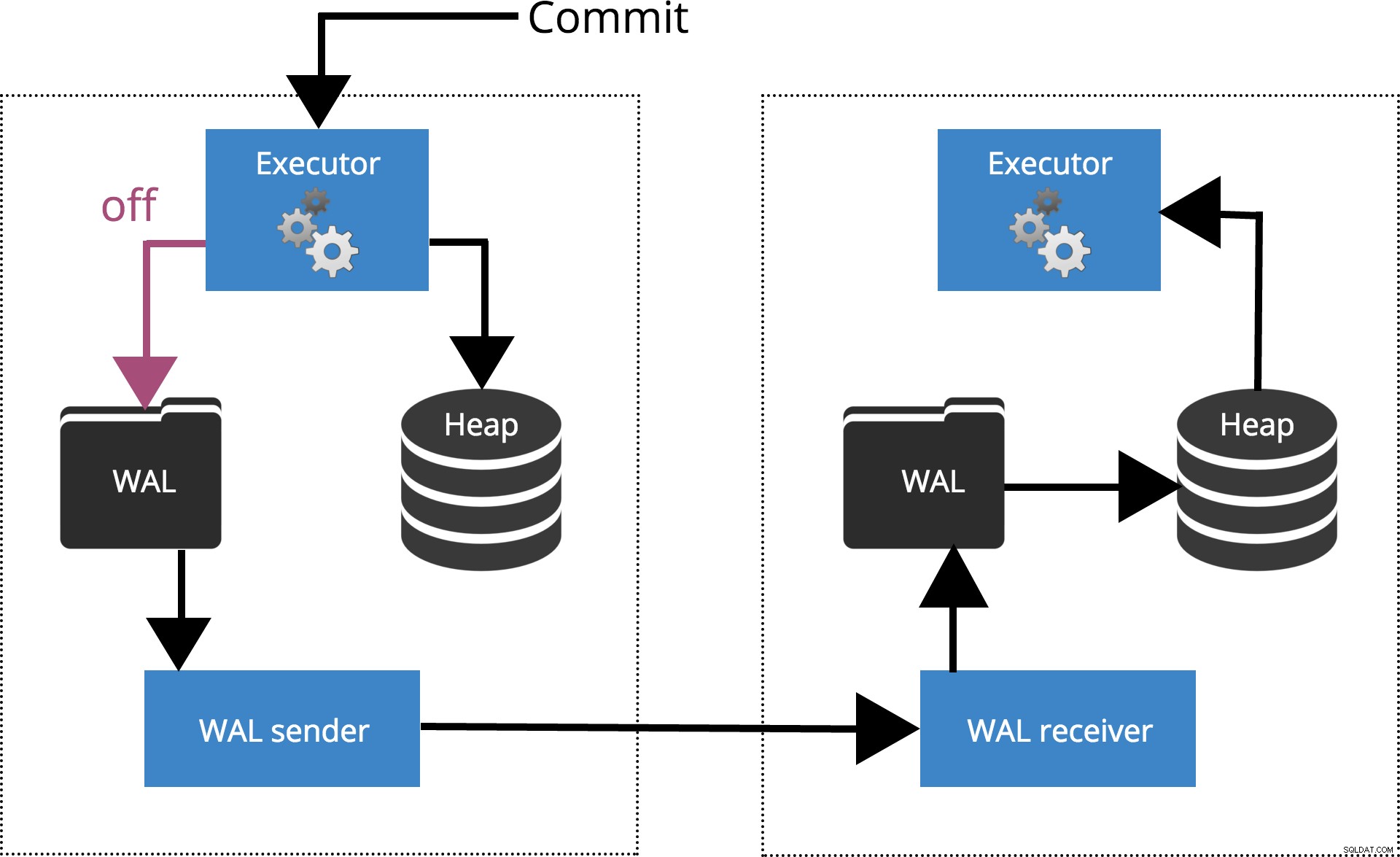
Fig.2 synchronous_commit =av
synchronous_commit =lokal
När vi ställer in synchronous_commit = local, COMMIT väntar tills transaktionsposten har tömts till den lokala disken. Detta är markerat i Fig.3 nedan.
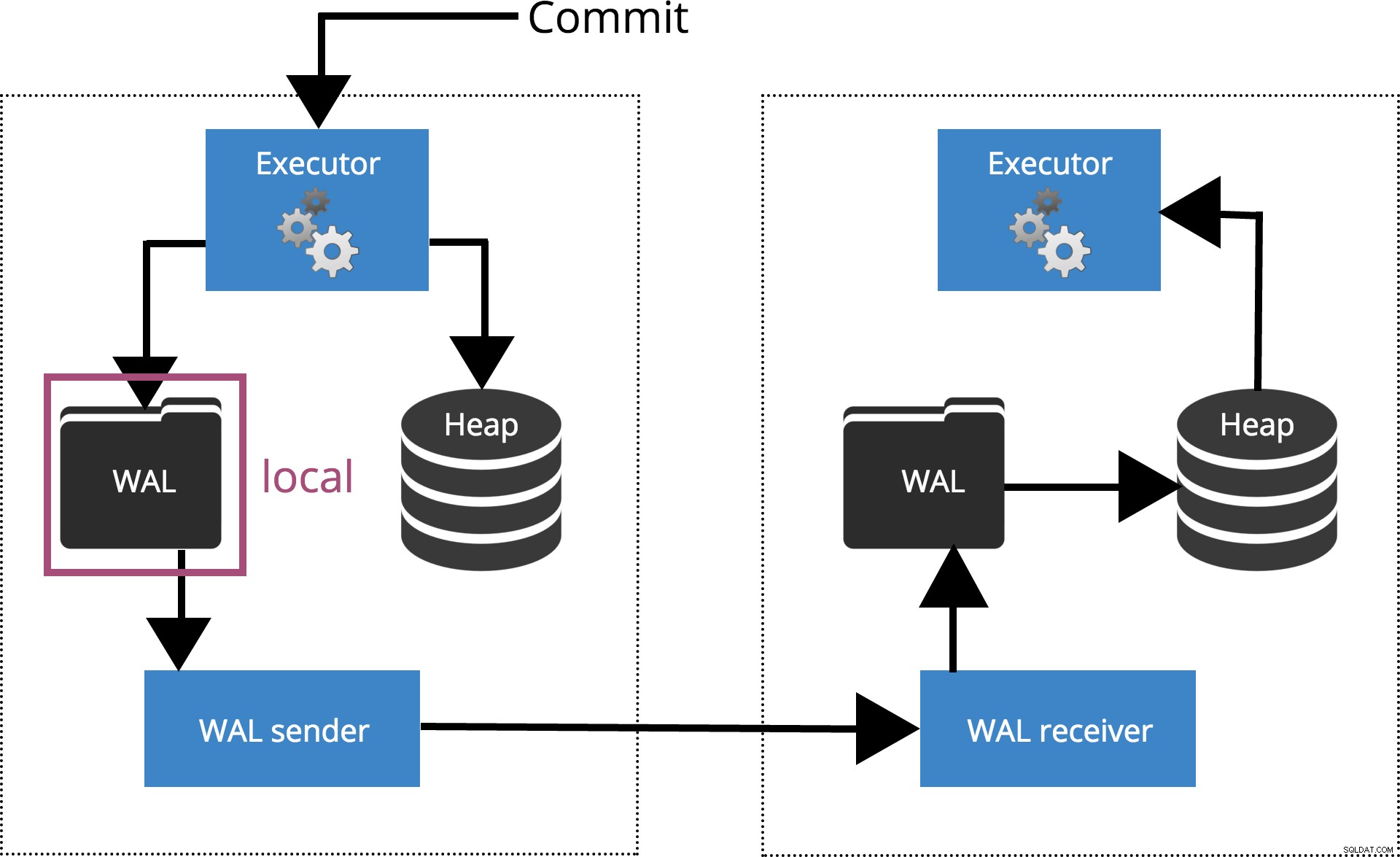
Fig.3 synchronous_commit =lokal
synchronous_commit =på (standard)
När vi ställer in synchronous_commit = on, COMMIT kommer att vänta tills servern(arna) specificeras av synchronous_standby_names bekräfta att transaktionsposten skrevs säkert till disken. Detta är markerat i Fig.4 nedan.
Obs! När synchronous_standby_names är tom, fungerar den här inställningen på samma sätt som synchronous_commit = local .
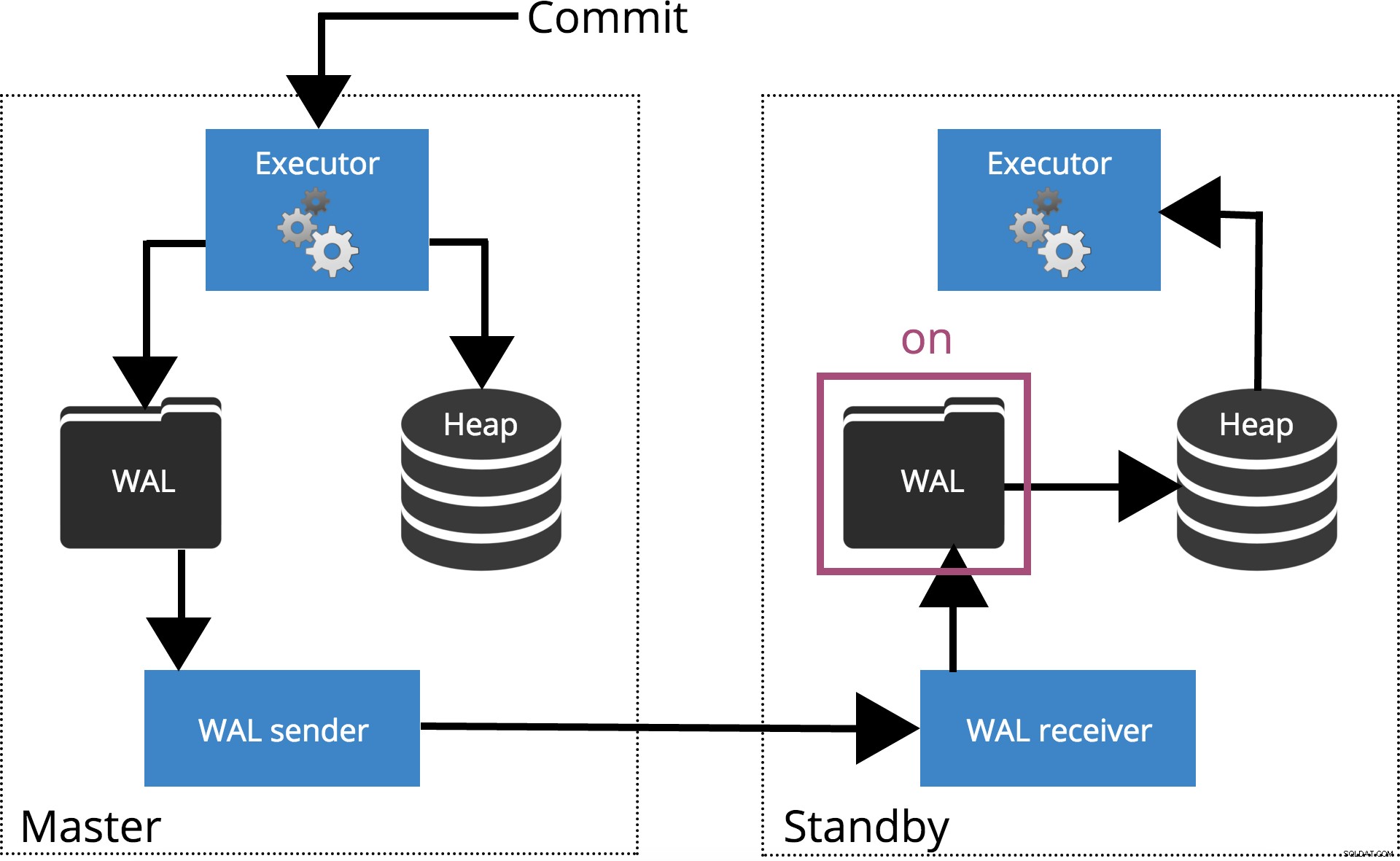
Fig.4 synchronous_commit =på
synchronous_commit =remote_write
När vi ställer in synchronous_commit = remote_write, COMMIT kommer att vänta tills servern(arna) specificeras av synchronous_standby_names bekräfta skrivning av transaktionsposten till operativsystemet men har inte nödvändigtvis nått disken. Detta är markerat i Fig. 5 nedan.
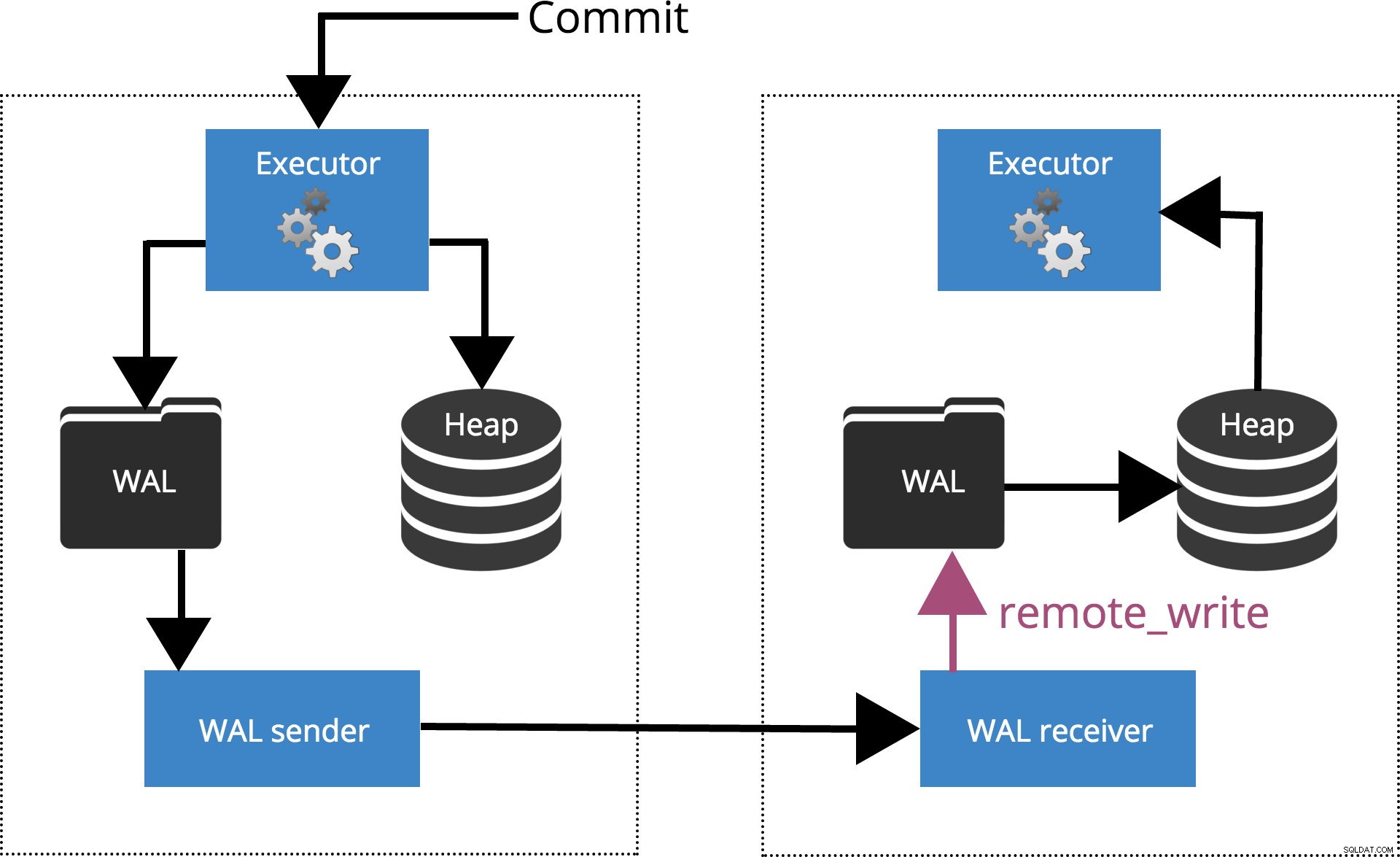
Fig.5 synchronous_commit =remote_write
synchronous_commit =remote_apply
När vi ställer in synchronous_commit = remote_apply, COMMIT kommer att vänta tills servern(arna) specificeras av synchronous_standby_names bekräfta att transaktionsposten tillämpades på databasen. Detta är markerat i Fig. 6 nedan.
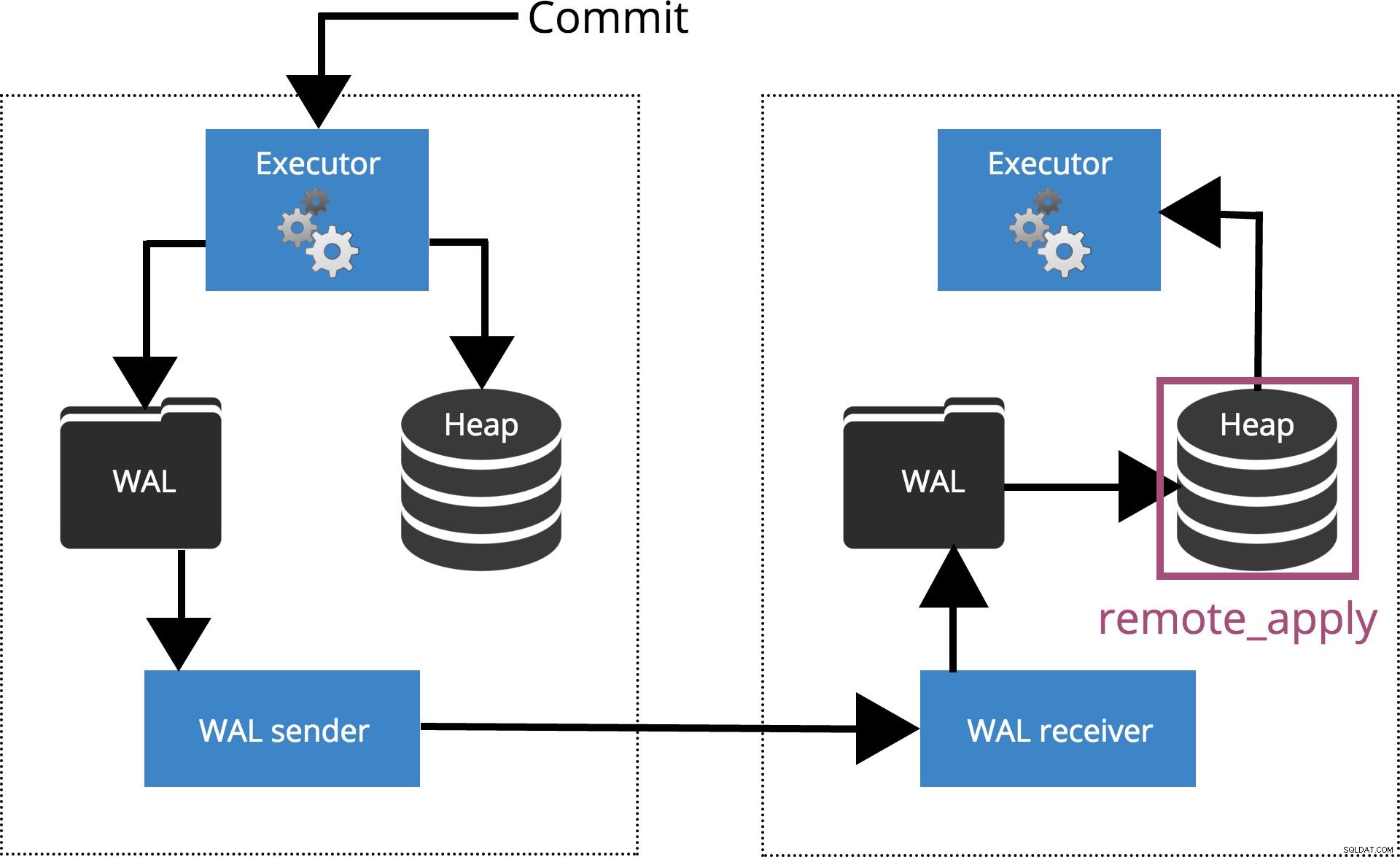
Fig. 6 synchronous_commit =remote_apply
Låt oss nu titta på sychronous_standby_names parameter i detaljer, som hänvisas till ovan vid inställning av synchronous_commit som on , remote_apply eller remote_write .
synchronous_standby_names ='standby_name [, …]'
Den synkrona bekräftelsen väntar på svar från ett av standby-lägena som är listade i prioritetsordning. Detta betyder att om det första vänteläget är anslutet och streamar, kommer den synkrona commit alltid att vänta på svar från den även om den andra vänteläget redan har svarat. Specialvärdet för * kan användas som stanby_name som matchar alla anslutna väntelägen.
synchronous_standby_names ='num (standby_name [, …])'
Den synkrona commit väntar på svar från minst num antal beredskapslägen i prioritetsordning. Samma regler som ovan gäller. Så, till exempel inställning av synchronous_standby_names = '2 (*)' kommer att få synkron commit att vänta på svar från två valfria standby-servrar.
synchronous_standby_names är tom
Om denna parameter är tom som visas ändras beteendet för inställningen synchronous_commit till on , remote_write eller remote_apply att bete sig på samma sätt som local (dvs. COMMIT väntar bara på spolning till lokal disk).
Slutsats
I det här blogginlägget diskuterade vi synkron replikering och beskrev olika skyddsnivåer som är tillgängliga i Postgres. Vi fortsätter med logisk replikering i nästa blogginlägg.
Referenser
Ett särskilt tack till min kollega Petr Jelinek för att han gav mig idén till illustrationer.
PostgreSQL-dokumentation
PostgreSQL 9 Administration Cookbook – Andra upplagan