Medan du justerar postgresql.conf , du kanske har märkt att det finns ett alternativ som heter full_page_writes . Kommentaren bredvid säger något om partiell sidaskrivning, och folk låter den i allmänhet vara on – vilket är bra, som jag kommer att förklara senare i det här inlägget. Det är dock användbart att förstå vad helsidesskrivningar gör, eftersom effekten på prestandan kan vara ganska stor.
Till skillnad från mitt tidigare inlägg om kontrollpunktsinställning är detta inte en guide för hur man ställer in servern. Det finns inte mycket du kan justera, egentligen, men jag ska visa dig hur vissa beslut på applikationsnivå (t.ex. val av datatyper) kan interagera med helsidesskrivningar.
Delvis skrivning / trasiga sidor
Så vad skriver helsida om? Som kommentaren i postgresql.conf säger att det är ett sätt att återhämta sig från partiella sidskrivningar – PostgreSQL använder 8kB-sidor (som standard), men andra delar av stacken använder olika chunkstorlekar. Linux-filsystem använder vanligtvis 4kB-sidor (det är möjligt att använda mindre sidor, men 4kB är max på x86), och på hårdvarunivån använde de gamla enheterna 512B-sektorer medan nya enheter ofta skriver data i större bitar (ofta 4kB eller till och med 8kB) .
Så när PostgreSQL skriver 8kB-sidan kan de andra lagren i lagringsstacken dela upp detta i mindre bitar, hanterade separat. Detta ger ett problem angående skrivatomicitet. 8kB PostgreSQL-sidan kan delas upp i två 4kB filsystemsidor och sedan i 512B sektorer. Nu, vad händer om servern kraschar (strömavbrott, kärnfel, ...)?
Även om servern använder ett lagringssystem som är designat för att hantera sådana fel (SSD-enheter med kondensatorer, RAID-kontroller med batterier, …), delar kärnan redan upp data i 4kB-sidor. Så det är möjligt att databasen skrev 8 kB datasida, men bara en del av den kom till disken innan kraschen.
Vid det här laget tänker du förmodligen att det är just därför vi har transaktionslogg (WAL), och du har rätt! Så efter att ha startat servern kommer databasen att läsa WAL (sedan den senaste genomförda kontrollpunkten) och tillämpa ändringarna igen för att se till att datafilerna är kompletta. Enkelt.
Men det finns en hake – återställningen tillämpar inte ändringarna blint, den behöver ofta läsa datasidorna etc. Vilket förutsätter att sidan inte redan är borrad på något sätt, till exempel på grund av en partiell skrivning. Vilket verkar lite självmotsägande, för för att åtgärda datakorruption antar vi att det inte finns någon datakorruption.
Helsidesskrivning är ett sätt att komma runt denna gåta – när man modifierar en sida för första gången efter en kontrollpunkt skrivs hela sidan in i WAL. Detta garanterar att under återställningen innehåller den första WAL-posten som rör en sida hela sidan, vilket eliminerar behovet av att läsa den – eventuellt trasiga – sidan från datafilen.
Skrivförstärkning
Naturligtvis är den negativa konsekvensen av detta ökad WAL-storlek – om du ändrar en enstaka byte på 8kB-sidan loggas det hela i WAL. Helsidesskrivningen sker bara vid första skrivningen efter en kontrollpunkt, så att göra checkpoints mindre frekventa är ett sätt att förbättra situationen – vanligtvis finns det en kort "skur" av helsidesskrivningar efter en checkpoint, och sedan relativt få helsidesskrivningar till slutet av en kontrollpunkt.
UUID vs. BIGSERIAL-nycklar
Men det finns några oväntade interaktioner med designbeslut som fattas på applikationsnivå. Låt oss anta att vi har en enkel tabell med primärnyckel, antingen en BIGSERIAL eller UUID , och vi infogar data i den. Kommer det att finnas en skillnad i mängden genererad WAL (förutsatt att vi infogar samma antal rader)?
Det verkar rimligt att förvänta sig att båda fallen producerar ungefär samma mängd WAL, men som följande diagram visar är det en enorm skillnad i praktiken.
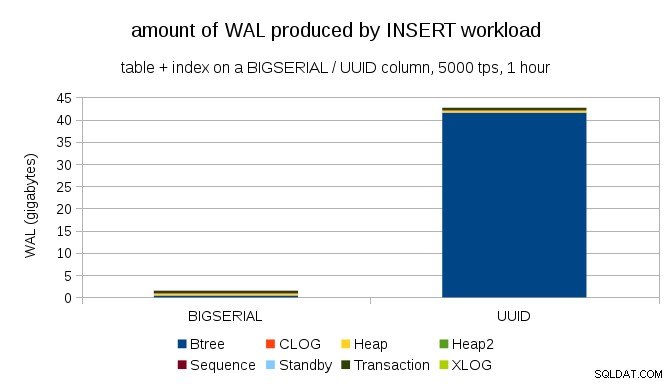
Detta visar mängden WAL som produceras under ett 1h-riktmärke, strypt till 5 000 skär per sekund. Med BIGSERIAL primärnyckel som producerar ~2GB WAL, medan med UUID det är mer än 40 GB. Det är en ganska betydande skillnad, och helt klart är det mesta av WAL associerat med indexstöd för primärnyckeln. Låt oss se som typer av WAL-poster.
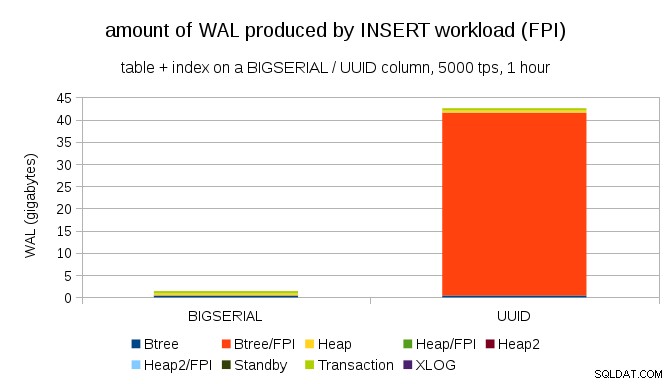
Det är uppenbart att den stora majoriteten av posterna är helsidesbilder (FPI), det vill säga resultatet av helsidesskrivningar. Men varför händer detta?
Naturligtvis beror detta på den inneboende UUID slumpmässighet. Med BIGSERIAL nya är sekventiella och infogas därför på samma bladsidor i btree-indexet. Eftersom endast den första ändringen av en sida utlöser helsidesskrivning, är bara en liten bråkdel av WAL-posterna FPI:er. Med UUID det är naturligtvis ett helt annat fall – värdena är inte sekventiella alls, i själva verket kommer varje inlägg sannolikt att vidröra en helt ny bladindexbladsida (förutsatt att indexet är tillräckligt stort).
Det finns inte mycket databasen kan göra – arbetsbelastningen är helt enkelt slumpmässig till sin natur, vilket utlöser många helsidesskrivningar.
Det är inte svårt att få liknande skrivförstärkning även med BIGSERIAL nycklar såklart. Det kräver bara en annan arbetsbelastning – till exempel med UPDATE arbetsbelastning, slumpmässig uppdatering av poster med enhetlig fördelning, ser diagrammet ut så här:
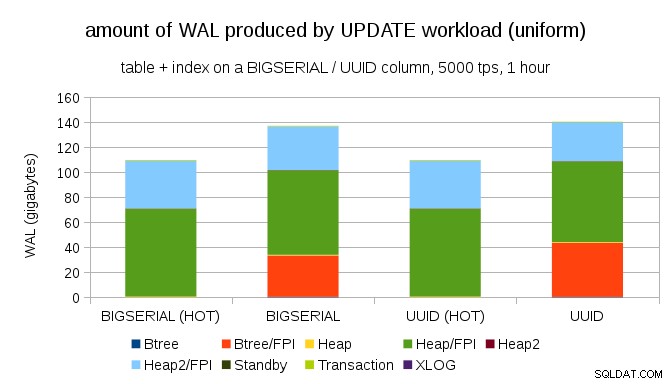
Plötsligt är skillnaderna mellan datatyper borta – åtkomsten är slumpmässig i båda fallen, vilket resulterar i nästan exakt samma mängd WAL som produceras. En annan skillnad är att det mesta av WAL är associerat med "heap", dvs tabeller, och inte index. "HOT"-fallen designades för att möjliggöra HOT UPDATE-optimering (dvs. uppdatera utan att behöva röra ett index), vilket i stort sett eliminerar all indexrelaterad WAL-trafik.
Men du kanske hävdar att de flesta applikationer inte uppdaterar hela datamängden. Vanligtvis är bara en liten delmängd av data "aktiva" – människor får bara tillgång till inlägg från de senaste dagarna på ett diskussionsforum, olösta beställningar i en e-butik, etc. Hur förändrar det resultaten?
Tack och lov stöder pgbench olikformiga distributioner, och till exempel med exponentiell distribution som rör 1 % delmängd av data ~25 % av tiden, ser diagrammet ut så här:
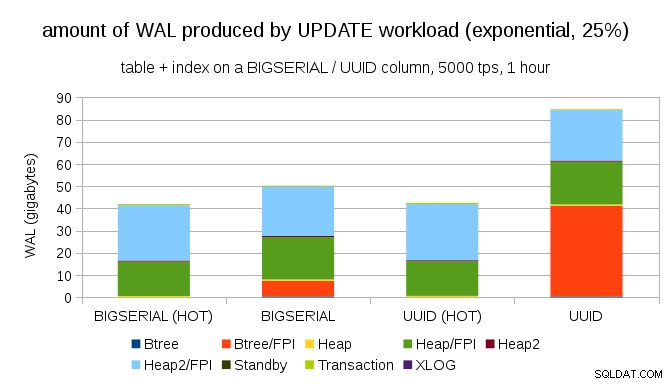
Och efter att ha gjort fördelningen ännu mer skev, rörde du vid 1%-delmängden ~75% av tiden:
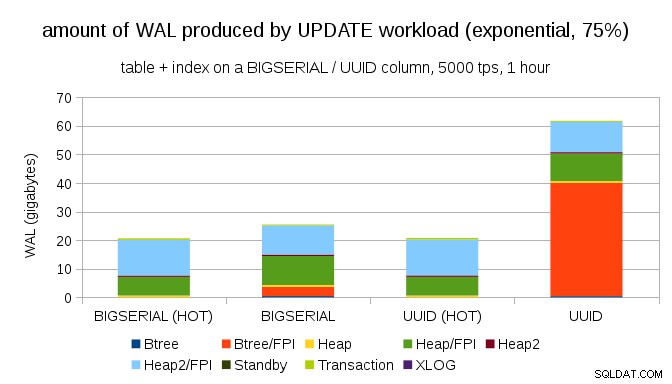
Detta visar återigen hur stor skillnad valet av datatyper kan göra, och även vikten av att ställa in för HETA uppdateringar.
8 kB och 4 kB sidor
En intressant fråga är hur mycket WAL-trafik vi kan spara genom att använda mindre sidor i PostgreSQL (vilket kräver att man kompilerar ett anpassat paket). I bästa fall kan det spara upp till 50 % WAL, tack vare att endast logga 4kB istället för 8kB sidor. För arbetsbelastningen med enhetligt fördelade UPPDATERINGAR ser det ut så här:
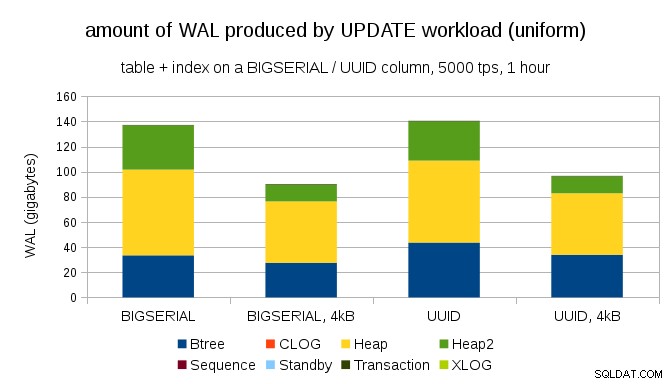
Så besparingen är inte exakt 50 %, men minskningen från ~140GB till ~90GB är fortfarande ganska betydande.
Behöver vi fortfarande helsidesskrivningar?
Det kan tyckas som ett löjligt efter att ha förklarat faran med partiella skrivningar, men kanske att inaktivera helsidesskrivningar kan vara ett genomförbart alternativ, åtminstone i vissa fall.
För det första undrar jag om moderna Linux-filsystem fortfarande är sårbara för partiella skrivningar? Parametern introducerades i PostgreSQL 8.1 som släpptes 2005, så kanske några av de många filsystemförbättringar som introducerats sedan dess gör att detta inte är ett problem. Förmodligen inte universellt för godtyckliga arbetsbelastningar, men det kanske skulle vara tillräckligt att anta något ytterligare villkor (t.ex. att använda 4 kB sidstorlek i PostgreSQL? PostgreSQL skriver aldrig över endast en delmängd av sidan på 8 kB – hela sidan skrivs alltid ut.
Jag har nyligen gjort många tester för att utlösa en partiell skrivning, och jag har inte lyckats orsaka ett enda fall. Naturligtvis är det inte ett riktigt bevis på att problemet inte existerar. Men även om det fortfarande är ett problem kan datakontrollsummor vara tillräckligt skydd (det kommer inte att lösa problemet, men det kommer åtminstone att meddela dig att det finns en trasig sida).
För det andra förlitar sig många system nuförtiden på strömmande repliker – istället för att vänta på att servern ska starta om efter ett hårdvaruproblem (som kan ta ganska lång tid) och sedan lägga mer tid på att utföra återställning, växlar systemen helt enkelt till ett varmt standbyläge. Om databasen på den misslyckade primära tas bort (och sedan klonas från den nya primära), är partiella skrivningar ett icke-problem.
Men jag antar att om vi började rekommendera det, då "Jag vet inte hur data skadades, jag har precis ställt in full_page_writes=off på systemen!" skulle bli en av de vanligaste meningarna precis före döden för DBA:er (tillsammans med "Jag har sett den här ormen på reddit, den är inte giftig.").
Sammanfattning
Det finns inte mycket du kan göra för att justera helsidesskrivningar direkt. För de flesta arbetsbelastningar sker de flesta helsidesskrivningar direkt efter en kontrollpunkt och försvinner sedan tills nästa kontrollpunkt. Så det är viktigt att ställa in kontrollpunkter så att de inte händer för ofta.
Vissa beslut på applikationsnivå kan öka slumpmässigheten för skrivningar till tabeller och index – till exempel är UUID-värden i sig slumpmässiga, vilket gör även enkla INSERT-arbetsbelastningar till slumpmässiga indexuppdateringar. Schemat som användes i exemplen var ganska trivialt – i praktiken kommer det att finnas sekundära index, främmande nycklar etc. Men att använda BIGSERIAL primärnycklar internt (och att behålla UUID som surrogatnycklar) skulle åtminstone minska skrivförstärkningen.
Jag är verkligen intresserad av diskussion om behovet av helsidesskrivningar på nuvarande kärnor/filsystem. Tyvärr har jag inte hittat många resurser, så om du har relevant information, låt mig veta.