Kort sammanfattning
- Undersökningsmetodens prestanda beror på datadistributionen.
- Prestandan för villkorlig aggregering beror inte på datadistributionen.
Subqueries-metoden kan vara snabbare eller långsammare än villkorlig aggregering, det beror på datadistributionen.
Naturligtvis, om tabellen har ett lämpligt index, så kommer subqueries sannolikt att dra nytta av det, eftersom index skulle tillåta att endast skanna den relevanta delen av tabellen istället för hela skanningen. Att ha ett lämpligt index kommer sannolikt inte att gynna den villkorliga aggregeringsmetoden avsevärt, eftersom den kommer att skanna hela indexet ändå. Den enda fördelen skulle vara om indexet är smalare än tabellen och motorn skulle behöva läsa färre sidor i minnet.
Genom att veta detta kan du bestämma vilken metod du ska välja.
Första testet
Jag gjorde ett större testbord, med 5M rader. Det fanns inga index på tabellen. Jag mätte IO- och CPU-statistiken med SQL Sentry Plan Explorer. Jag använde SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64-bitars för dessa tester.
Faktum är att dina ursprungliga frågor betedde sig som du beskrev, d.v.s. undersökningar var snabbare även om läsningarna var 3 gånger högre.
Efter några försök på en tabell utan index skrev jag om din villkorliga aggregat och lade till variabler för att hålla värdet för DATEADD uttryck.
Totalt sett blev tiden betydligt snabbare.
Sedan ersatte jag SUM med COUNT och det blev lite snabbare igen.
När allt kommer omkring blev villkorlig aggregering ganska mycket lika snabb som underfrågor.
Värm cacheminnet (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Undersökningar (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);
Original villkorlig aggregering (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Villkorlig aggregering med variabler (CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Villkorlig aggregering med variabler och COUNT istället för SUM (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

Baserat på dessa resultat är min gissning att CASE anropade DATEADD för varje rad, medan WHERE var smart nog att räkna ut det en gång. Plus COUNT är lite mer effektivt än SUM .
I slutändan är villkorlig aggregering bara något långsammare än underfrågor (1062 vs 1031), kanske för att WHERE är lite effektivare än CASE i sig och dessutom WHERE filtrerar bort ganska många rader, så COUNT måste bearbeta färre rader.
I praktiken skulle jag använda villkorlig aggregering, eftersom jag tror att antalet läsningar är viktigare. Om ditt bord är litet för att passa och stanna i buffertpoolen, kommer alla frågor att vara snabba för slutanvändaren. Men om tabellen är större än tillgängligt minne, förväntar jag mig att läsning från disk skulle sakta ner undersökningar avsevärt.
Andra testet
Å andra sidan är det också viktigt att filtrera bort raderna så tidigt som möjligt.
Här är en liten variation av testet, som visar det. Här ställer jag in tröskeln till GETDATE() + 100 år, för att säkerställa att inga rader uppfyller filterkriterierna.
Värm cacheminnet (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);
Undersökningar (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);
Original villkorlig aggregering (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Villkorlig aggregering med variabler (CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
Villkorlig aggregering med variabler och COUNT istället för SUM (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
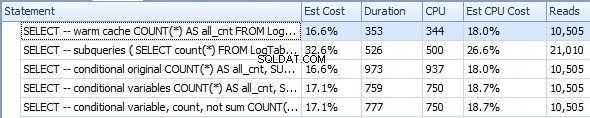
Nedan finns en plan med delfrågor. Du kan se att 0 rader gick in i Stream Aggregate i den andra underfrågan, alla filtrerades bort i tabellskanningssteget.
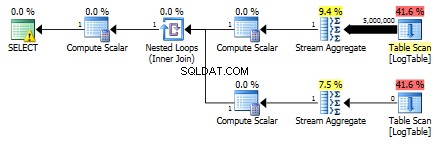
Som ett resultat är undersökningar återigen snabbare.
Tredje testet
Här ändrade jag filtreringskriterierna för det tidigare testet:all > ersattes med < . Som ett resultat, den villkorliga COUNT räknade alla rader istället för ingen. Överraskning, överraskning! Villkorlig aggregeringsfråga tog samma 750 ms, medan underfrågor blev 813 istället för 500.

Här är planen för underfrågor:
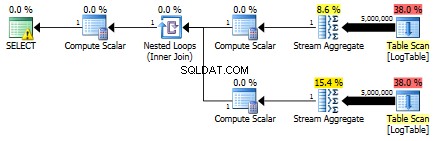
Kan du ge mig ett exempel där villkorlig aggregering framför allt överträffar subquery-lösningen?
Här är det. Prestandan för subqueries-metoden beror på datadistributionen. Utförande av villkorlig aggregering beror inte på datadistributionen.
Subqueries-metoden kan vara snabbare eller långsammare än villkorlig aggregering, det beror på datadistributionen.
Genom att veta detta kan du bestämma vilken metod du ska välja.
Bonusdetaljer
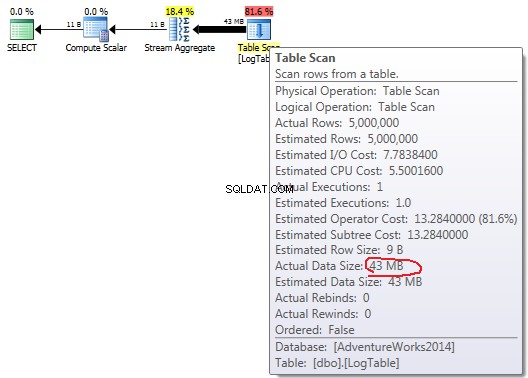
Om du håller musen över Table Scan operatör kan du se Actual Data Size i olika varianter.
- Enkel
COUNT(*):
- Villkorlig aggregering:
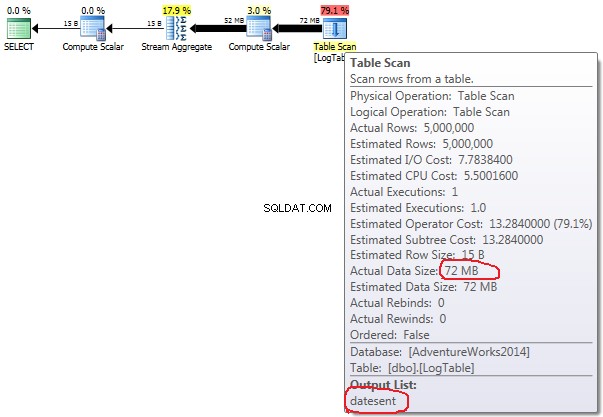
- Underfråga i test 2:
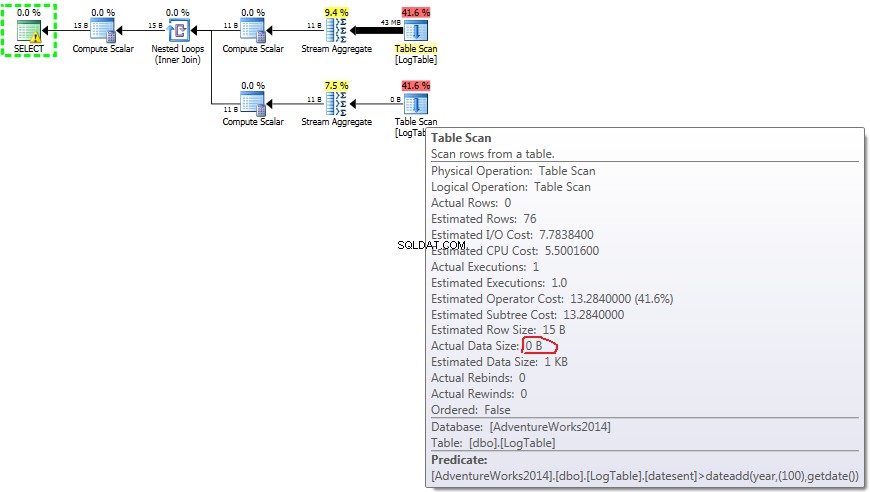
- Underfråga i test 3:
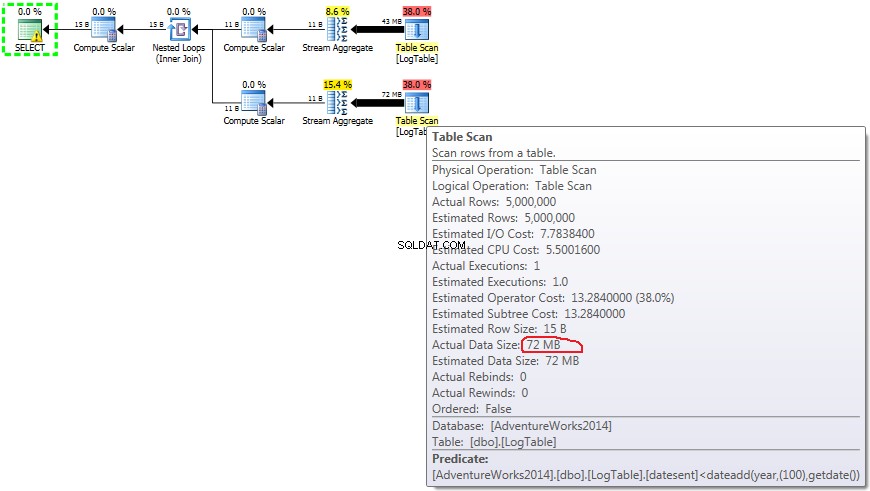
Nu står det klart att skillnaden i prestanda sannolikt beror på skillnaden i mängden data som flödar genom planen.
Vid enkel COUNT(*) det finns ingen Output list (inga kolumnvärden behövs) och datastorleken är minst (43MB).
Vid villkorad aggregering ändras inte detta belopp mellan test 2 och 3, det är alltid 72 MB. Output list har en kolumn datesent .
I händelse av underfrågor, gör detta belopp ändras beroende på datadistributionen.