Så fort du börjar köra en databasserver och din användning ökar, utsätts du för många typer av tekniska problem, prestandaförsämring och databasfel. Var och en av dessa kan leda till mycket större problem, såsom katastrofala misslyckanden eller dataförlust. Det är som en kedjereaktion, där en sak kan leda till en annan och orsaka fler och fler problem. Proaktiva motåtgärder måste vidtas för att du ska ha en stabil miljö så länge som möjligt.
I det här blogginlägget kommer vi att titta på ett gäng coola funktioner som erbjuds av ClusterControl som i hög grad kan hjälpa oss att felsöka och fixa våra MySQL-databasproblem när de inträffar.
Databaslarm och aviseringar
För alla oönskade händelser kommer ClusterControl att logga allt under Larm, tillgängligt på aktiviteten (toppmenyn) på ClusterControl-sidan. Detta är vanligtvis det första steget för att börja felsöka när något går fel. Från den här sidan kan vi få en uppfattning om vad som faktiskt händer med vårt databaskluster:
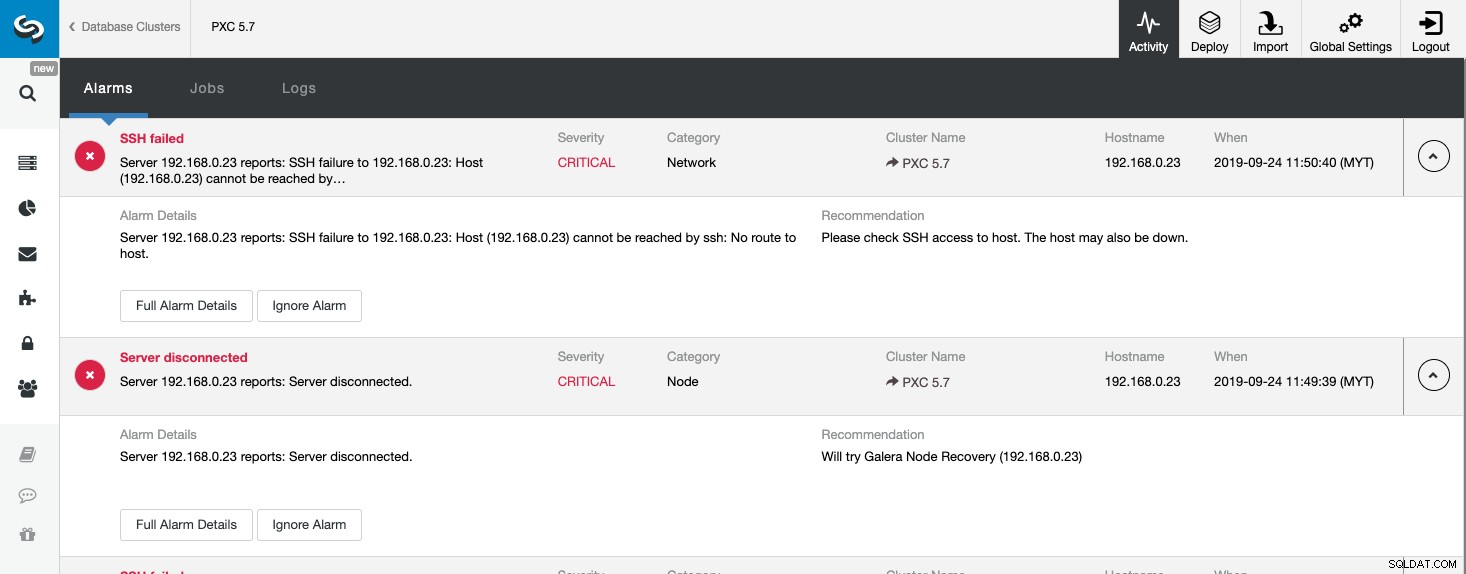
Ovanstående skärmdump visar ett exempel på en server som inte kan nås, med svårighetsgrad KRITISK , detekteras av två komponenter, nätverk och nod. Om du har konfigurerat inställningen för e-postmeddelanden bör du få en kopia av dessa larm i din brevlåda.
När du klickar på "Fullständiga larmdetaljer" kan du få viktiga detaljer om larmet som värdnamn, tidsstämpel, klusternamn och så vidare. Det ger också nästa rekommenderade steg att ta. Du kan också skicka ut detta larm som ett e-postmeddelande till andra mottagare som konfigurerats under inställningarna för e-postmeddelanden.
Du kan också välja att tysta ett larm genom att klicka på knappen "Ignorera larm" och det kommer inte att visas i listan igen. Att ignorera ett larm kan vara användbart om du har ett larm med låg svårighetsgrad och vet hur du ska hantera eller kringgå det. Till exempel om ClusterControl upptäcker ett duplicerat index i din databas, där det i vissa fall skulle behövas av dina äldre applikationer.
Genom att titta på den här sidan kan vi få en omedelbar förståelse för vad som händer med vårt databaskluster och vad nästa steg är att göra för att lösa problemet. Som i det här fallet gick en av databasnoderna ner och blev oåtkomlig via SSH från ClusterControl-värden. Även en nybörjare SysAdmin skulle nu veta vad han ska göra härnäst om detta larm visas.
Centraliserade databasloggfiler
Det är här vi kan gå igenom vad som var fel på vår databasserver. Under ClusterControl -> Loggar -> Systemloggar kan du se alla loggfiler relaterade till databasklustret. När det gäller MySQL-baserat databaskluster, hämtar ClusterControl ProxySQL-loggen, MySQL-felloggen och backuploggarna:
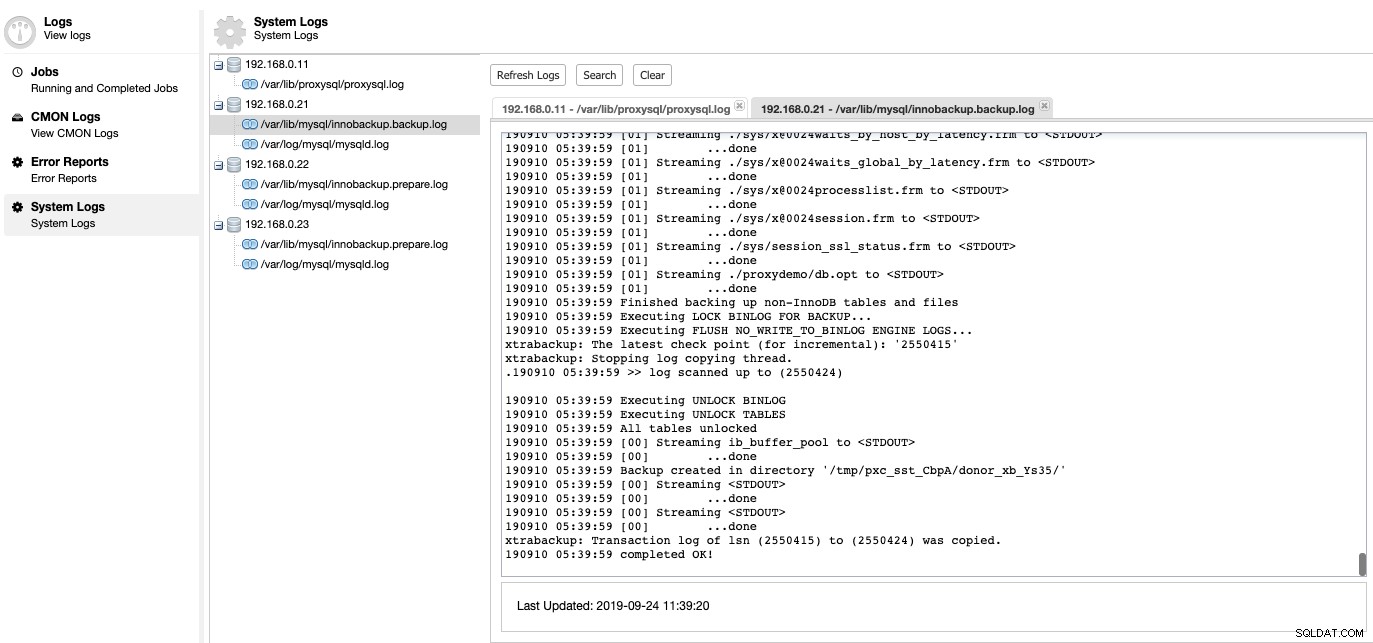
Klicka på "Uppdatera logg" för att hämta den senaste loggen från alla värdar som är tillgängliga vid just den tidpunkten. Om en nod inte går att nå, kommer ClusterControl fortfarande att se den föråldrade inloggningen eftersom denna information lagras i CMON-databasen. Som standard fortsätter ClusterControl att hämta systemloggarna var 10:e minut, konfigurerbart under Inställningar -> Loggintervall.
ClusterControl kommer att utlösa jobbet för att hämta den senaste loggen från varje server, som visas i följande "Samla in loggar"-jobb:
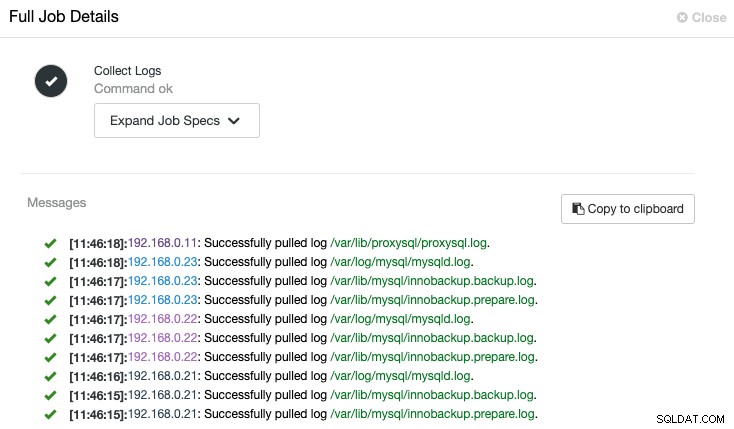
En centraliserad vy av loggfilen gör att vi kan få snabbare förståelse för vad som hände fel. För ett databaskluster som vanligtvis involverar flera noder och nivåer, kommer den här funktionen att avsevärt förbättra loggläsningen där en SysAdmin kan jämföra dessa loggar sida vid sida och lokalisera kritiska händelser, vilket minskar den totala felsökningstiden.
Web SSH-konsol
ClusterControl tillhandahåller en webbaserad SSH-konsol så att du kan komma åt DB-servern direkt via ClusterControl-gränssnittet (eftersom SSH-användaren är konfigurerad att ansluta till databasvärdarna). Härifrån kan vi samla in mycket mer information som gör att vi kan åtgärda problemet ännu snabbare. Alla vet när ett databasproblem drabbar produktionssystemet, varje sekund av driftstopp räknas.
För att komma åt SSH-konsolen via webben, välj helt enkelt noderna under Noder -> Nodåtgärder -> SSH-konsol, eller klicka helt enkelt på kugghjulsikonen för en genväg:
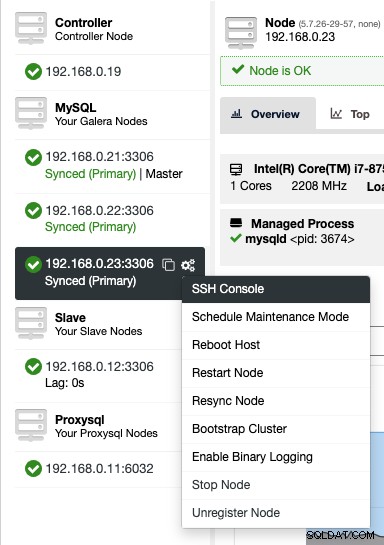
På grund av säkerhetsproblem som kan åläggas den här funktionen, särskilt för multi -användar- eller multi-tenant-miljö, man kan inaktivera den genom att gå till /var/www/html/clustercontrol/bootstrap.php på ClusterControl-servern och ställa in följande konstant till false:
define('SSH_ENABLED', false);Uppdatera ClusterControl UI-sidan för att läsa in de nya ändringarna.
Problem med databasprestanda
Förutom övervaknings- och trendfunktioner skickar ClusterControl dig proaktivt olika larm och rådgivare relaterade till databasprestanda, till exempel:
- Överdriven användning – Resurs som passerar vissa trösklar som CPU, minne, swap-användning och diskutrymme.
- Klusterförsämring – Kluster- och nätverkspartitionering.
- Systemets tidsdrift – Tidsskillnad mellan alla noder i klustret (inklusive ClusterControl-noden).
- Olika andra MySQL-relaterade rådgivare:
- Replikering – replikeringsfördröjning, binlogs utgång, plats och tillväxt
- Galera - SST-metod, skanna GRA-loggfil, klusteradresskontroll
- Schemakontroll - Icke-transaktionell tabell existerar på Galera Cluster.
- Anslutningar - Trådanslutna förhållande
- InnoDB - Dirty pages ratio, InnoDB-loggfiltillväxt
- Långsamma frågor - Som standard larmar ClusterControl om den hittar en fråga som körs i mer än 30 sekunder. Detta är naturligtvis konfigurerbart under Inställningar -> Runtime Configuration -> Long Query.
- Deadlocks - Deadlock för InnoDB-transaktioner och Galera-deadlock.
- Index - Dubbletter av nycklar, tabell utan primärnycklar.
Kolla in Advisors-sidan under Prestanda -> Advisors för att få information om saker som kan förbättras enligt ClusterControls förslag. För varje rådgivare ger den motiveringar och råd som visas i följande exempel för rådgivaren "Kontrollera diskutrymmesanvändning":
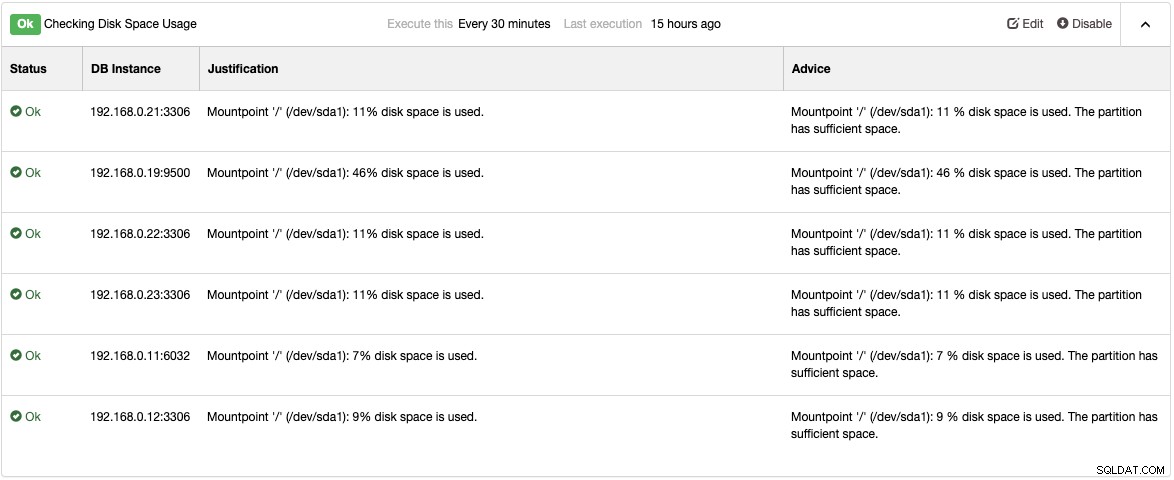
När ett prestandaproblem uppstår får du "Varning" (gul) eller "Kritisk" (röd) status på dessa rådgivare. Ytterligare justering krävs vanligtvis för att lösa problemet. Rådgivare larmar, vilket innebär att användare kommer att få en kopia av dessa larm i brevlådan om e-postmeddelanden konfigureras därefter. För varje larm som utlöses av ClusterControl eller dess rådgivare kommer användarna också att få ett e-postmeddelande om larmet har åtgärdats. Dessa är förkonfigurerade inom ClusterControl och kräver ingen initial konfiguration. Ytterligare anpassning är alltid möjlig under Manage -> Developer Studio. Du kan kolla in det här blogginlägget om hur du skriver din egen rådgivare.
ClusterControl tillhandahåller också en dedikerad sida med avseende på databasprestanda under ClusterControl -> Prestanda. Det ger alla typer av databasinsikter efter bästa praxis som centraliserad vy av DB Status, Variabler, InnoDB status, Schema Analyzer, Transaktionsloggar. Dessa är ganska självförklarande och enkla att förstå.
För frågeprestanda kan du inspektera Top Queries och Query Outliers, där ClusterControl framhäver frågor som presterade avsevärt skiljer sig från deras genomsnittliga fråga. Vi har behandlat detta ämne i detalj i det här blogginlägget, MySQL Query Performance Tuning.
Databasfelrapporter
ClusterControl levereras med ett verktyg för att generera felrapporter för att samla in felsökningsinformation om ditt databaskluster för att hjälpa dig förstå den aktuella situationen och statusen. För att skapa en felrapport, gå helt enkelt till ClusterControl -> Loggar -> Felrapporter -> Skapa felrapport:
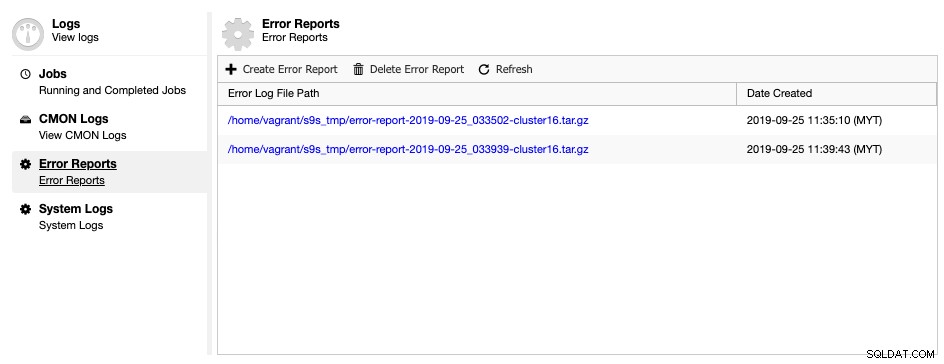
Den genererade felrapporten kan laddas ner från den här sidan när den är klar. Den här genererade rapporten kommer att vara i TAR-bollformat (tar.gz) och du kan bifoga den till en supportförfrågan. Eftersom supportbiljetten har gränsen på 10 MB filstorlek, om tarballstorleken är större än så, kan du ladda upp den till en molnenhet och bara dela nedladdningslänken med oss med rätt tillstånd. Du kan ta bort den senare när vi redan har fått filen. Du kan också generera felrapporten via kommandoraden enligt beskrivningen på sidan med dokumentation för felrapporter.
I händelse av ett avbrott rekommenderar vi starkt att du genererar flera felrapporter under och direkt efter avbrottet. Dessa rapporter kommer att vara mycket användbara för att försöka förstå vad som gick fel, konsekvenserna av avbrottet och för att verifiera att klustret faktiskt är tillbaka till operativ status efter en katastrofal händelse.
Slutsats
ClusterControl proaktiv övervakning, tillsammans med en uppsättning felsökningsfunktioner, ger en effektiv plattform för användare att felsöka alla typer av MySQL-databasproblem. Länge borta är det gamla sättet att felsöka där man måste öppna flera SSH-sessioner för att få åtkomst till flera värdar och utföra flera kommandon upprepade gånger för att lokalisera rotorsaken.
Om de ovan nämnda funktionerna inte hjälper dig att lösa problemet eller felsöka databasproblemet, kontaktar du alltid Severalnines supportteam för att säkerhetskopiera dig. Våra 24/7/365 dedikerade tekniska experter är tillgängliga för att när som helst närvara vid din förfrågan. Vår genomsnittliga första svarstid är vanligtvis mindre än 30 minuter.