Som du kanske har noterat från min tidigare blogg har de senaste månaderna varit upptagna med att få Postgres-XL uppdaterad med den senaste 9.5-versionen av PostgreSQL. När vi väl hade en någorlunda stabil version av Postgres-XL 9.5 flyttade vi vår uppmärksamhet till att mäta prestanda för denna helt nya version av Postgres-XL. Vårt val av riktmärke påverkas till stor del av det pågående arbetet med AXLE-projektet, finansierat av Europeiska unionen under bidragsavtal 318633. Eftersom vi använder TPC BENCHMARK™ H för att mäta prestanda för allt annat arbete som utförts under detta projekt, beslutade vi att använd samma riktmärke för att utvärdera Postgres-XL. Det passar även Postgres-XL eftersom TPC-H försöker mäta OLAP-arbetsbelastningar, något som Postgres-XL borde göra bra.
1. Postgres-XL Cluster Setup
När riktmärket väl bestämdes var en annan stor utmaning att hitta rätt resurser för testning. Vi hade inte tillgång till ett stort kluster av fysiska maskiner. Så vi gjorde vad de flesta skulle göra. Vi bestämde oss för att använda Amazon AWS för att ställa in Postgres-XL-klustret. AWS erbjuder ett brett utbud av instanser, där varje instanstyp erbjuder olika beräknings- eller IO-kraft.
Den här sidan på AWS visar olika tillgängliga instanstyper, tillgängliga resurser och deras prissättning för olika regioner. Det måste noteras att priser och tillgänglighet kan variera från region till region, så det är viktigt att du kollar in alla regioner. Eftersom Postgres-XL kräver låg latens och hög genomströmning mellan dess komponenter, är det också viktigt att instansiera alla instanser i samma region. För vår 3TB TPC-H bestämde vi oss för att välja ett kluster med 16 datanoder av i2.xlarge AWS-instanser. Dessa instanser har 4 vCPU, 30 GB RAM och 800 GB SSD vardera, tillräckligt med lagringsutrymme för att behålla alla distribuerade tabeller, replikerade tabeller (som tar mer utrymme med ökande storlek på klustret), indexen på dem och fortfarande lämnar tillräckligt med ledigt utrymme i temporärt tabellutrymme för CREATE INDEX och andra frågor.
2. Benchmark-inställningar
2.1 TPC Benchmark™ H
Benchmarken innehåller 22 frågor med syfte att undersöka stora datamängder, utföra frågor med hög grad av komplexitet och ge svar på affärskritiska frågor. Vi vill notera att den fullständiga TPC Benchmark™ H-specifikationen handlar om olika tester som belastning, effekt och genomströmning tester. För våra tester har vi bara kört individuella frågor och inte hela testsviten. TPC Benchmark™ H består av en uppsättning affärsfrågor utformade för att utöva systemfunktioner på ett sätt som är representativt för komplexa affärsanalysapplikationer. Dessa frågor har fått ett realistiskt sammanhang, som visar aktiviteten hos en grossistleverantör för att hjälpa läsaren att relatera intuitivt till komponenterna i riktmärket.
2.2 Databasenheter, relationer och egenskaper
Komponenterna i TPC-H-databasen är definierade att bestå av åtta separata och individuella tabeller (Bastabellerna). Relationerna mellan kolumner i dessa tabeller illustreras i följande diagram. 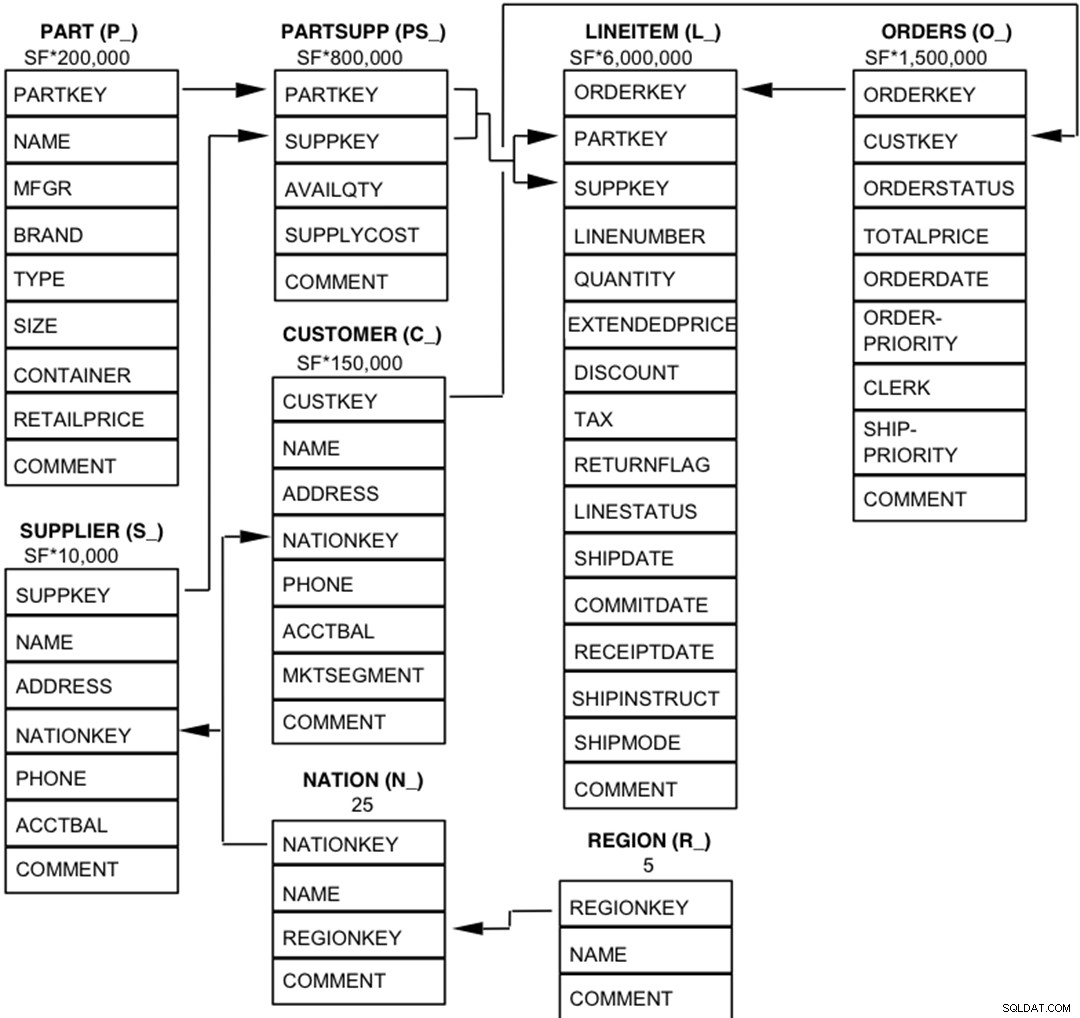 Legend :
Legend :
- Parentesen efter varje tabellnamn innehåller prefixet för kolumnnamnen för den tabellen;
- Pilarna pekar i riktning mot en-till-många-relationerna mellan tabeller
- Siffran/formeln under varje tabellnamn representerar tabellens kardinalitet (antal rader). Vissa är faktoriserade av SF, Skalfaktorn, för att få den valda databasstorleken. Kardinaliteten för tabellen LINEITEM är ungefärlig
2.3 Datadistribution för Postgres-XL
Vi analyserade alla 22 frågor i riktmärket och kom fram till följande datadistributionsstrategi för olika tabeller i riktmärket.
| Tabellnamn | Distributionsstrategi |
| LINEITEM | HASH (l_orderkey) |
| ORDNINGAR | HASH (o_orderkey) |
| DEL | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| KUND | REPLIKERAD |
| LEVERANTÖR | REPLIKERAD |
| NATION | REPLIKERAD |
| REGION | REPLIKERAD |
Observera att LINEITEM och ORDERS som är de största tabellerna i benchmark ofta sammanfogas på ORDERKEY. Så det är mycket meningsfullt att placera dessa tabeller på ORDERKEY. På samma sätt sammanfogas PART och PARTSUPP ofta på PARTKEY och de är därför samlokaliserade på PARTKEY-kolumnen. Resten av tabellerna replikeras för att säkerställa att de kan sammanfogas lokalt vid behov.
3. Benchmark-resultat
3.1 Lasttest
Vi jämförde resultat som erhållits genom att köra ett 3TB TPC-H-belastningstest på PostgreSQL 9.6 mot Postgres-XL-klustret med 16 noder. Följande diagram visar prestandaegenskaperna hos Postgres-XL.
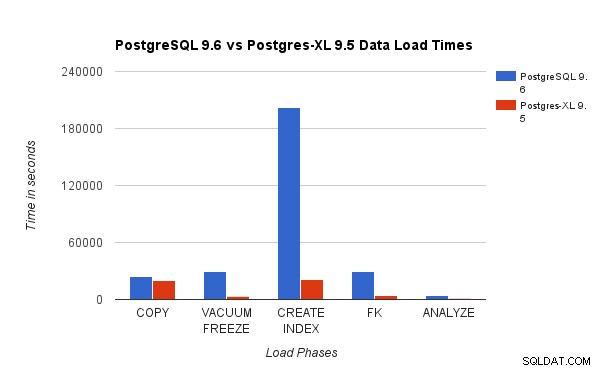 Tabellen ovan visar hur lång tid det tar att slutföra olika faser av ett belastningstest med PostgreSQL och Postgres-XL. Som sett presterar Postgres-XL något bättre för COPY och mycket bättre för alla andra fall. Obs :Vi observerade att koordinatorn kräver mycket beräkningskraft under COPY-fasen, speciellt när mer än en COPY-ström körs samtidigt. För att ta itu med det kördes koordinatorn på en beräkningsoptimerad AWS-instans med 16 vCPU. Alternativt kunde vi också ha kört flera koordinatorer och fördelat beräkningsbelastning mellan dem.
Tabellen ovan visar hur lång tid det tar att slutföra olika faser av ett belastningstest med PostgreSQL och Postgres-XL. Som sett presterar Postgres-XL något bättre för COPY och mycket bättre för alla andra fall. Obs :Vi observerade att koordinatorn kräver mycket beräkningskraft under COPY-fasen, speciellt när mer än en COPY-ström körs samtidigt. För att ta itu med det kördes koordinatorn på en beräkningsoptimerad AWS-instans med 16 vCPU. Alternativt kunde vi också ha kört flera koordinatorer och fördelat beräkningsbelastning mellan dem.
3.2 Effekttest
Vi jämförde också frågekörningstiderna för 3TB benchmark på PostgreSQL 9.6 och Postgres-XL 9.5. Följande diagram visar prestandaegenskaperna för frågekörningen på de två inställningarna.
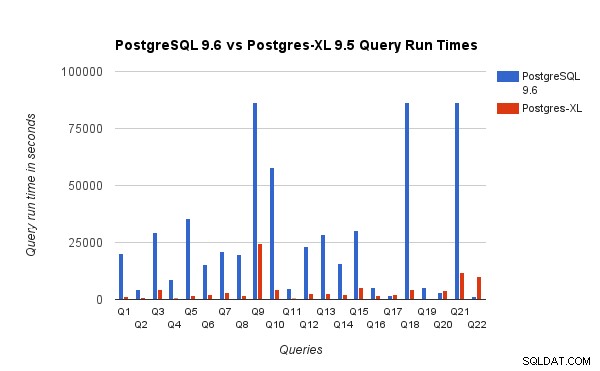 Vi observerade att i genomsnitt sprang frågorna cirka 6,4 gånger snabbare på Postgres-XL och minst 25 % av frågorna visade nästan linjär förbättring av prestanda, med andra ord presterade de nästan 16 gånger snabbare på detta 16-nods Postgres-XL-kluster. Dessutom visade minst 50 % av frågorna 10 gånger förbättring i prestanda. Vi analyserade ytterligare frågeprestanda och drog slutsatsen att frågor som är väl uppdelade över alla tillgängliga datanoder, så att det finns minimalt utbyte av data mellan noder och utan upprepade fjärrexekveringsanrop, skalas mycket bra i Postgres-XL. Sådana frågor har vanligtvis en Remote Subquery Scan-nod överst och underträdet under noden exekveras på en eller flera noder parallellt. Det är också vanligt att ha några andra noder som en Limit-nod eller en Aggregate-nod ovanpå Remote Subquery Scan-noden. Även sådana frågor fungerar mycket bra på Postgres-XL. Fråga Q1 är ett exempel på en fråga som bör skalas mycket bra med Postgres-XL. Å andra sidan kan frågor som kräver mycket utbyte av tuplar mellan datanod-datanode och/eller koordinator-datanod inte fungera bra i Postgres-XL. På samma sätt kan frågor som kräver många korsnodsanslutningar också visa dålig prestanda. Till exempel kommer du att märka att prestandan hos Q22 är dålig jämfört med en PostgreSQL-server för en enda nod. När vi analyserade frågeplanen för Q22, observerade vi att det finns tre nivåer av kapslade Remote Subquery Scan-noder i frågeplanen, där varje nod öppnar lika många anslutningar till datanoderna. Vidare har Nest Loop Anti Join en inre relation med en toppnivånod för Remote Subquery Scan och därför måste den för varje tuppel av den yttre relationen utföra en fjärrunderfråga. Detta resulterar i dålig prestanda för exekvering av sökfrågor.
Vi observerade att i genomsnitt sprang frågorna cirka 6,4 gånger snabbare på Postgres-XL och minst 25 % av frågorna visade nästan linjär förbättring av prestanda, med andra ord presterade de nästan 16 gånger snabbare på detta 16-nods Postgres-XL-kluster. Dessutom visade minst 50 % av frågorna 10 gånger förbättring i prestanda. Vi analyserade ytterligare frågeprestanda och drog slutsatsen att frågor som är väl uppdelade över alla tillgängliga datanoder, så att det finns minimalt utbyte av data mellan noder och utan upprepade fjärrexekveringsanrop, skalas mycket bra i Postgres-XL. Sådana frågor har vanligtvis en Remote Subquery Scan-nod överst och underträdet under noden exekveras på en eller flera noder parallellt. Det är också vanligt att ha några andra noder som en Limit-nod eller en Aggregate-nod ovanpå Remote Subquery Scan-noden. Även sådana frågor fungerar mycket bra på Postgres-XL. Fråga Q1 är ett exempel på en fråga som bör skalas mycket bra med Postgres-XL. Å andra sidan kan frågor som kräver mycket utbyte av tuplar mellan datanod-datanode och/eller koordinator-datanod inte fungera bra i Postgres-XL. På samma sätt kan frågor som kräver många korsnodsanslutningar också visa dålig prestanda. Till exempel kommer du att märka att prestandan hos Q22 är dålig jämfört med en PostgreSQL-server för en enda nod. När vi analyserade frågeplanen för Q22, observerade vi att det finns tre nivåer av kapslade Remote Subquery Scan-noder i frågeplanen, där varje nod öppnar lika många anslutningar till datanoderna. Vidare har Nest Loop Anti Join en inre relation med en toppnivånod för Remote Subquery Scan och därför måste den för varje tuppel av den yttre relationen utföra en fjärrunderfråga. Detta resulterar i dålig prestanda för exekvering av sökfrågor.
4. Några AWS-lektioner
Under benchmarking av Postgres-XL lärde vi oss några lektioner om att använda AWS. Vi trodde att de skulle vara användbara för alla som funderar på att använda/testa Postgres-XL på AWS.
- AWS erbjuder flera olika typer av instanser. Du måste noggrant utvärdera din arbetsbelastning och mängd lagring som krävs innan du väljer en specifik instanstyp.
- De flesta av de lagringsoptimerade instanserna har tillfälliga diskar anslutna till dem. Du behöver inte betala något extra för dessa diskar, de är anslutna till instansen och fungerar ofta bättre än EBS. Men du måste montera dem explicit för att kunna använda dem. Kom dock ihåg att data som lagras på dessa diskar inte är permanenta och kommer att raderas om instansen stoppas. Så se till att du är beredd att hantera den situationen. Eftersom vi använde AWS mest för benchmarking, bestämde vi oss för att använda dessa tillfälliga diskar.
- Om du använder EBS, se till att du väljer lämplig Provisioned IOPS. För lågt värde kommer att orsaka mycket långsam IO, men ett mycket högt värde kan öka din AWS-räkning avsevärt, särskilt när du har att göra med ett stort antal noder.
- Se till att du startar instanserna i samma zon för att minska latensen och förbättra genomströmningen för anslutningar mellan dem.
- Se till att du konfigurerar instanser så att de använder privata nätverk för att prata med varandra.
- Titta på spot-instanser. De är relativt billigare. Eftersom AWS kan avsluta spotförekomster efter behag, till exempel om spotpriset blir högre än ditt högsta budpris, var beredd på det. Postgres-XL kan bli delvis eller helt oanvändbar beroende på vilka noder som avslutas. AWS stöder konceptet launch_group. Om flera instanser är grupperade i samma launch_group om AWS beslutar sig för att avsluta en instans kommer alla instanser att avslutas.
5. Slutsats
Vi kan visa, genom olika riktmärken, att Postgres-XL kan skalas riktigt bra för en stor uppsättning av verkliga, komplexa frågor. Dessa riktmärken hjälper oss att visa Postgres-XLs förmåga som en effektiv lösning för OLAP-arbetsbelastningar. Våra experiment visar också att det finns vissa prestandaproblem med Postgres-XL, särskilt för mycket stora kluster och när planeraren gör ett dåligt val av en plan. Vi observerade också att när det finns ett mycket stort antal samtidiga anslutningar till en datanod, försämras prestandan. Vi kommer att fortsätta att arbeta med dessa prestationsproblem. Vi skulle också vilja testa Postgres-XLs förmåga som en OLTP-lösning genom att använda lämpliga arbetsbelastningar.