Det finns olika sätt att återställa din PostgreSQL-databas, men en av de mest bekväma metoderna för att återställa dina data från en logisk säkerhetskopia. Logiska säkerhetskopior spelar en viktig roll för Disaster and Recovery Planning (DRP). Logiska säkerhetskopior är säkerhetskopior som tas, till exempel med pg_dump eller pg_dumpall, som genererar SQL-satser för att få all tabelldata som skrivs till en binär fil.
Det rekommenderas också att köra periodiska logiska säkerhetskopior om dina fysiska säkerhetskopior misslyckas eller är otillgängliga. För PostgreSQL kan återställning vara problematiskt om du är osäker på vilka verktyg du ska använda. Säkerhetskopieringsverktyget pg_dump är vanligtvis ihopparat med återställningsverktyget pg_restore.
pg_dump och pg_restore agerar parallellt om en katastrof inträffar och du behöver återställa dina data. Även om de tjänar det primära syftet med dumpning och återställning, kräver det att du utför några extra uppgifter när du behöver återställa ditt kluster och göra en failover (om din aktiva primära eller master dör på grund av maskinvarufel eller korruption av VM-systemet). Du kommer att hitta och använda tredjepartsverktyg som kan hantera failover eller automatisk klusteråterställning.
I den här bloggen ska vi ta en titt på hur pg_restore fungerar och jämföra det med hur ClusterControl hanterar säkerhetskopiering och återställning av dina data om en katastrof skulle inträffa.
Mekanismer för pg_restore
pg_restore är användbart när du skaffar följande uppgifter:
- parad med pg_dump för att generera SQL-genererade filer som innehåller data, åtkomstroller, databas- och tabelldefinitioner
- återställ en PostgreSQL-databas från ett arkiv skapat av pg_dump i ett av de icke-oformaterade formaten.
- Den kommer att utfärda de kommandon som krävs för att rekonstruera databasen till det tillstånd den var i när den sparades.
- har förmågan att vara selektiv eller till och med ordna om objekten innan de återställs baserat på arkivfilen
- Arkivfilerna är designade för att vara portabla över olika arkitekturer.
- pg_restore kan fungera i två lägen.
- Om ett databasnamn anges ansluter pg_restore till den databasen och återställer arkivinnehåll direkt till databasen.
- eller, ett skript som innehåller de SQL-kommandon som krävs för att återuppbygga databasen skapas och skrivs till en fil eller standardutdata. Dess skriptutdata motsvarar formatet som genereras av pg_dump
- Några av alternativen som styr utdata är därför analoga med pg_dump-alternativ.
När du har återställt data är det bäst och tillrådligt att köra ANALYSE på varje återställd tabell så att optimeraren har användbar statistik. Även om den får LÄS-LÅS, kan du behöva köra detta under låg trafik eller under din underhållsperiod.
Fördelar med pg_restore
pg_dump och pg_restore i tandem har funktioner som är bekväma för en DBA att använda.
- pg_dump och pg_restore har förmågan att köras parallellt genom att ange alternativet -j. Genom att använda -j/--jobben
kan du specificera hur många jobb som körs parallellt som kan köras speciellt för att ladda data, skapa index eller skapa begränsningar med flera samtidiga jobb. - Den är tyst behändig att använda, du kan selektivt dumpa eller ladda specifika databas eller tabeller
- Det tillåter och ger användaren flexibilitet för vilken speciell databas, schema eller omordning av procedurerna som ska köras baserat på listan. Du kan till och med generera och ladda SQL-sekvensen löst som att förhindra acls eller privilegier i enlighet med dina behov. Det finns många alternativ för att passa dina behov.
- Det ger dig möjlighet att generera SQL-filer precis som pg_dump från ett arkiv. Detta är mycket praktiskt om du vill ladda till en annan databas eller värd för att tillhandahålla en separat miljö.
- Det är lätt att förstå baserat på den genererade sekvensen av SQL-procedurer.
- Det är ett bekvämt sätt att ladda data i en replikeringsmiljö. Du behöver inte replika din replik eftersom satserna är SQL som replikerades ner till standby- och återställningsnoderna.
Begränsningar för pg_restore
För logiska säkerhetskopior är de uppenbara begränsningarna för pg_restore tillsammans med pg_dump prestanda och hastighet när man använder verktygen. Det kan vara praktiskt när du vill tillhandahålla en test- eller utvecklingsdatabasmiljö och ladda dina data, men det är inte tillämpligt när din datamängd är enorm. PostgreSQL måste dumpa dina data en efter en eller köra och tillämpa dina data sekventiellt av databasmotorn. Även om du kan göra detta löst flexibelt för att snabba upp som att specificera -j eller använda --single-transaction för att undvika påverkan på din databas, måste laddning med SQL fortfarande analyseras av motorn.
Dessutom anger PostgreSQL-dokumentationen följande begränsningar, med våra tillägg när vi observerade dessa verktyg (pg_dump och pg_restore):
- När data återställs till en redan existerande tabell och alternativet --disable-triggers används, avger pg_restore kommandon för att inaktivera utlösare på användartabeller innan data infogas och sedan kommandon för att återaktivera dem efter att data har infogats. Om återställningen stoppas i mitten kan systemkatalogerna lämnas i fel tillstånd.
- pg_restore kan inte återställa stora objekt selektivt; till exempel endast de för en specifik tabell. Om ett arkiv innehåller stora objekt kommer alla stora objekt att återställas, eller inget av dem om de exkluderas via -L, -t eller andra alternativ.
- Båda verktygen förväntas generera en enorm mängd storlek (filer, katalog eller tar-arkiv) speciellt för en enorm databas.
- För pg_dump, när du dumpar en enstaka tabell eller som vanlig text, hanterar inte pg_dump stora objekt. Stora objekt måste dumpas med hela databasen med ett av de icke-textbaserade arkivformaten.
- Om du har tar-arkiv genererade av dessa verktyg, notera att tar-arkiv är begränsade till en storlek mindre än 8 GB. Detta är en inneboende begränsning av tar-filformatet. Därför kan detta format inte användas om den textmässiga representationen av en tabell överskrider den storleken. Den totala storleken på ett tar-arkiv och något av de andra utdataformaten är inte begränsad, förutom möjligen av operativsystemet.
Använda pg_restore
Att använda pg_restore är ganska praktiskt och lätt att använda. Eftersom det paras ihop med pg_dump, fungerar båda dessa verktyg tillräckligt bra så länge som målutgången passar den andra. Till exempel kommer följande pg_dump inte att vara användbar för pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Detta resultat kommer att vara en psql-kompatibel som ser ut så här:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Men detta kommer att misslyckas för pg_restore eftersom det inte finns något vanligt format att följa:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerLåt oss nu gå till mer användbara termer för pg_restore.
pg_restore:Släpp och återställ
Tänk på en enkel användning av pg_restore som du har släppt en databas, t.ex.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Det är väldigt enkelt att återställa det med pg_restore,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Tillstånden -C/--create here som skapar databasen när den påträffas i rubriken. -d postgres pekar på postgres databasen men det betyder inte att den kommer att skapa tabellerna till postgres databasen. Det kräver att databasen måste finnas. Om -C inte anges, kommer tabell(er) och poster att lagras i den databasen som refereras till med -d-argumentet.
Återställer selektivt efter tabell
Att återställa en tabell med pg_restore är enkelt och enkelt. Till exempel har du två tabeller nämligen "b" och "d" tabeller. Låt oss säga att du kör följande pg_dump-kommando nedan,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Där innehållet i denna katalog kommer att se ut enligt följande,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Om du vill återställa en tabell (nämligen "d" i det här exemplet),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Skall ha,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Kopiera databastabeller till en annan databas
Du kan till och med kopiera innehållet i din befintliga databas och ha det på din måldatabas. Till exempel har jag följande databaser,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Paultest-databasen är en tom databas medan vi ska kopiera det som finns i maxtest-databasen,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)För att kopiera den måste vi dumpa data från maxtest-databasen enligt följande,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Ladda in eller återställ den enligt följande,
Nu har vi data på paultest-databasen och tabellerna har lagrats därefter.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Generera en SQL-fil med omordning
Jag har sett mycket användning av pg_restore men det verkar som om den här funktionen vanligtvis inte visas upp. Jag tyckte att det här tillvägagångssättet var mycket intressant eftersom det låter dig beställa baserat på vad du inte vill inkludera och sedan generera en SQL-fil från den ordning du vill fortsätta.
Vi kommer till exempel att använda exemplet pgdump_data.tar som vi har genererat tidigare och skapa en lista. För att göra detta, kör följande kommando:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listDetta genererar en fil som visas nedan:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresNu, låt oss ordna om det eller ska vi säga att jag har tagit bort skapandet av SEQUENCE och även skapandet av begränsningen. Detta skulle se ut så här,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresFör att generera filen i SQL-format, gör bara följande:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Nu kommer filen /tmp/selective_data.out att vara en SQL-genererad fil och denna är läsbar om du använder psql, men inte pg_restore. Det som är bra med detta är att du kan generera en SQL-fil i enlighet med din mall där data endast kan återställas från ett befintligt arkiv eller säkerhetskopieras med hjälp av pg_dump med hjälp av pg_restore.
PostgreSQL-återställning med ClusterControl
ClusterControl använder inte pg_restore eller pg_dump som en del av dess funktioner. Vi använder pg_dumpall för att skapa logiska säkerhetskopior och tyvärr är utdata inte kompatibel med pg_restore.
Det finns flera andra sätt att skapa en säkerhetskopia i PostgreSQL enligt nedan.
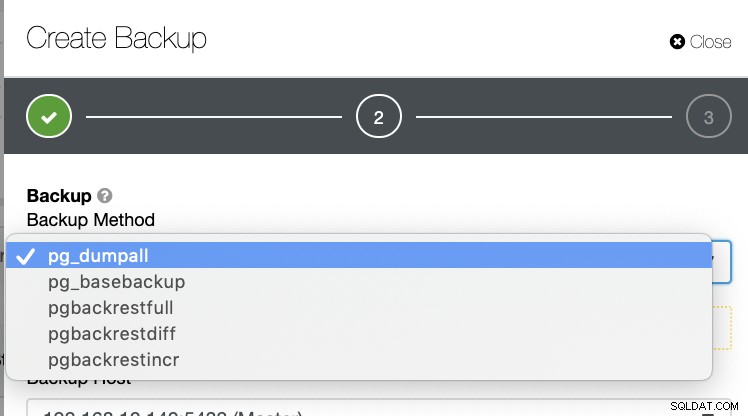
Det finns ingen sådan mekanism där du selektivt kan lagra en tabell, en databas, eller kopiera från en databas till en annan databas.
ClusterControl stöder Point-in-Time Recovery (PITR), men detta tillåter dig inte att hantera dataåterställning lika flexibelt som med pg_restore. För alla listan över säkerhetskopieringsmetoder är endast pg_basebackup och pgbackrest PITR-kompatibla.
Hur ClusterControl hanterar återställning är att den har förmågan att återställa ett misslyckat kluster så länge som Auto Recovery är aktiverat som visas nedan.

När mastern misslyckas kan slaven automatiskt återställa klustret när ClusterControl utförs failover (som görs automatiskt). För dataåterställningsdelen är ditt enda alternativ att ha en klusteromfattande återställning, vilket innebär att den kommer från en fullständig säkerhetskopia. Det finns ingen möjlighet att selektivt återställa på måldatabasen eller tabellen som du bara ville återställa. Om du vill göra det, återställ hela säkerhetskopian, det är enkelt att göra detta med ClusterControl. Du kan gå till flikarna Säkerhetskopiering precis som visas nedan,
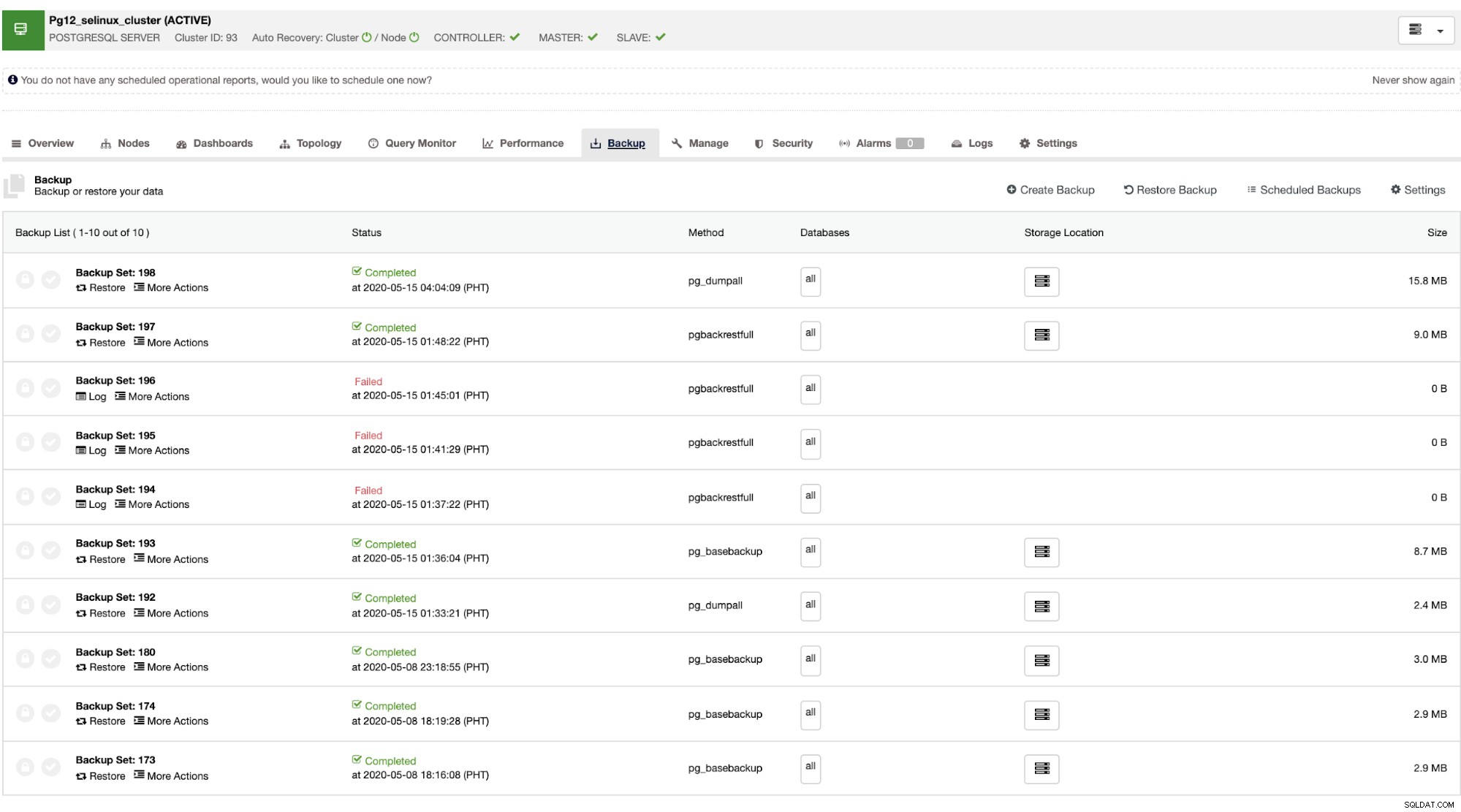
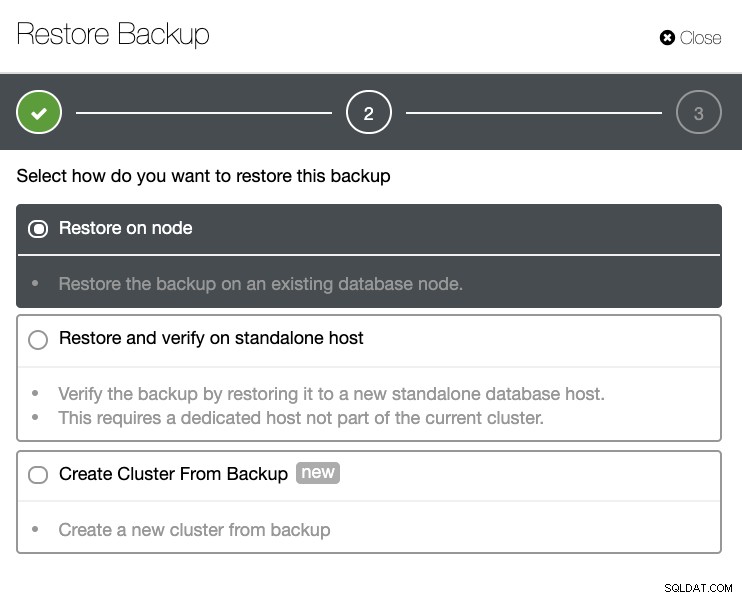
Du kommer att ha en fullständig lista över lyckade och misslyckade säkerhetskopieringar. Sedan kan återställningen göras genom att välja målsäkerhetskopieringen och klicka på knappen "Återställ". Detta gör att du kan återställa på en befintlig nod som är registrerad inom ClusterControl, eller verifiera på en fristående nod, eller skapa ett kluster från säkerhetskopian.
Slutsats
Att använda pg_dump och pg_restore förenklar tillvägagångssättet för säkerhetskopiering/dumpning och återställning. Men för en storskalig databasmiljö kanske detta inte är en idealisk komponent för katastrofåterställning. För ett minimalt urval och återställningsprocedur, genom att använda kombinationen av pg_dump och pg_restore ger dig möjligheten att dumpa och ladda dina data enligt dina behov.
För produktionsmiljöer (särskilt för företagsarkitekturer) kan du använda ClusterControl-metoden för att skapa en säkerhetskopia och återställa med automatisk återställning.
En kombination av tillvägagångssätt är också ett bra tillvägagångssätt. Detta hjälper dig att sänka din RTO och RPO och samtidigt utnyttja det mest flexibla sättet att återställa dina data när det behövs.