Att använda en miljö med flera moln eller flera datacenter är användbart för geodistribuerade topologier eller till och med för en katastrofåterställningsplan, och faktiskt blir det mer populärt nuförtiden, därför är konceptet split-brain blir också viktigare eftersom risken för att den ökar i denna typ av scenario. Du måste förhindra en split-brain för att undvika potentiell dataförlust eller datainkonsekvens, vilket kan vara ett stort problem för verksamheten.
I den här bloggen kommer vi att se vad en split-brain är och hur ClusterControl kan hjälpa dig att undvika detta viktiga problem.
Vad är Split-Brain?
I PostgreSQL-världen uppstår split-brain när mer än en primär nod är tillgänglig samtidigt (utan något tredjepartsverktyg för att ha en multi-mastermiljö) som gör att applikationen kan skriva i båda noderna. I det här fallet kommer du att ha olika information om varje nod, vilket genererar datainkonsekvens i klustret. Det kan vara svårt att åtgärda det här problemet eftersom du måste slå samman data, något som ibland inte är möjligt.
PostgreSQL delad hjärna i en multimolntopologi
Låt oss anta att du har följande multimolntopologi för PostgreSQL (vilket är en ganska vanlig topologi nuförtiden):
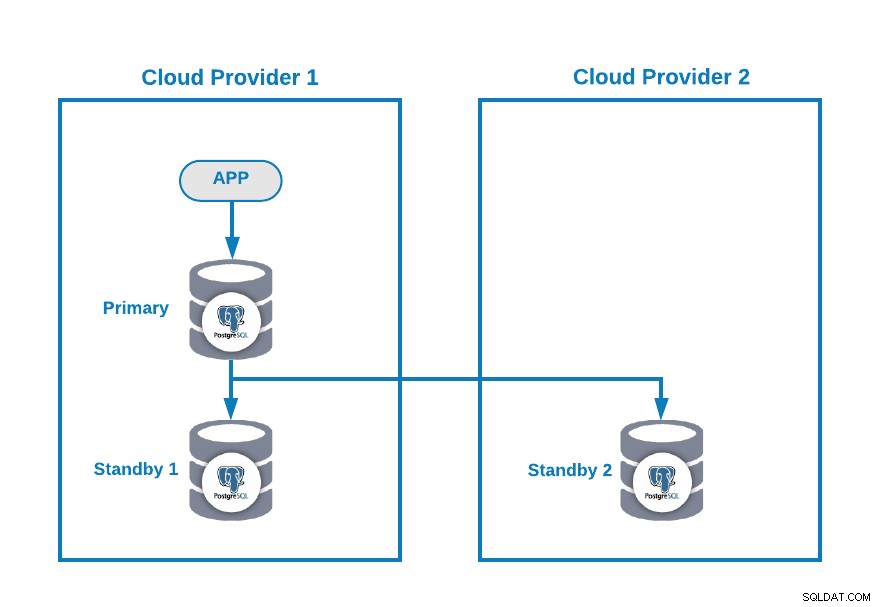
Självklart kan du förbättra den här miljön genom att till exempel lägga till en Application Server in the Cloud Provider 2, men i det här fallet, låt oss använda den här grundläggande konfigurationen.
Om din primära nod är nere bör en av standbynoderna marknadsföras som en ny primär och du bör ändra IP-adressen i din applikation för att använda denna nya primära nod.
Det finns olika sätt att göra detta på ett automatiskt sätt. Du kan till exempel använda en virtuell IP-adress som tilldelats din primära nod och övervaka den. Om det misslyckas, främja en av standbynoderna och migrera den virtuella IP-adressen till denna nya primära nod, så att du inte behöver ändra något i din applikation, och detta kan göras med ditt eget skript eller verktyg.
För tillfället har du inga problem, men... om din gamla primära nod kommer tillbaka måste du se till att du inte har två primärnoder i samma kluster samtidigt .
De vanligaste metoderna för att undvika denna situation är:
- STONITH:Skjut den andra noden i huvudet.
- SMITH:Skjut mig själv i huvudet.
PostgreSQL ger inget sätt att automatisera denna process. Du måste göra det på egen hand.
Hur man undviker split-brain i PostgreSQL med ClusterControl
Låt oss nu se hur ClusterControl kan hjälpa dig med den här uppgiften.
För det första kan du använda den för att distribuera eller importera din PostgreSQL Multi-Cloud-miljö på ett enkelt sätt som du kan se i det här blogginlägget.
Då kan du förbättra din topologi genom att lägga till en lastbalanserare (HAProxy), vilket du också kan göra med ClusterControl efter den här bloggen. Så du kommer att ha något sånt här:
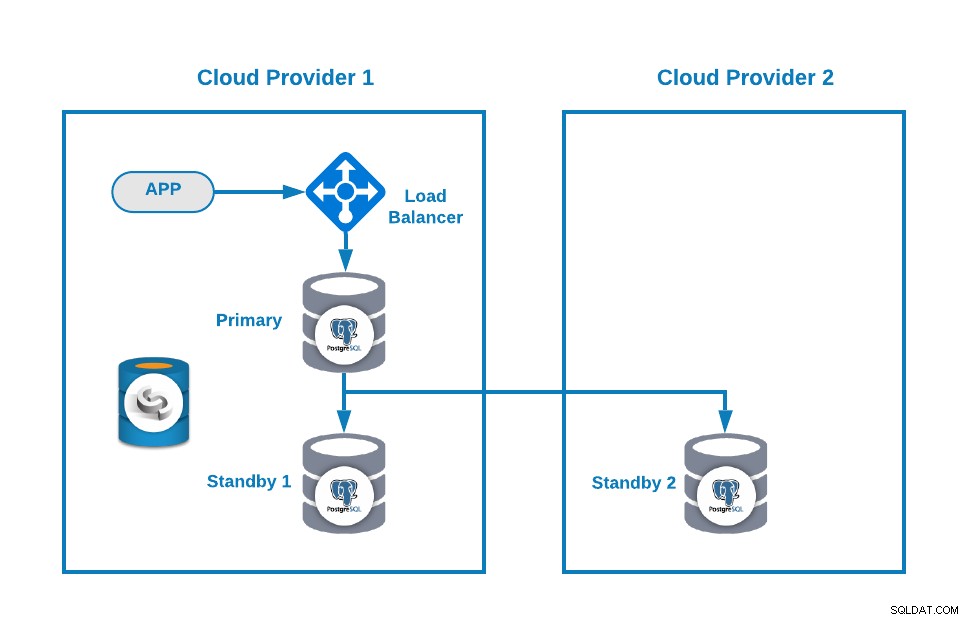
ClusterControl har en auto-failover-funktion som upptäcker masterfel och främjar standby nod med den senaste datan som ny primär. Det misslyckas också över resten av standbynoderna att replikera från den nya primära noden.
HAProxy konfigureras av ClusterControl med två olika portar som standard, en läs-skriv- och en skrivskyddad. I läs-skrivporten har du din primära nod som online och resten av dina noder som offline, och i den skrivskyddade porten har du både den primära och standbynoden online. På så sätt kan du balansera lästrafiken mellan dina noder men du ser till att i skrivande stund kommer läs-skrivporten att användas, skriva i den primära noden som är servern som är online.
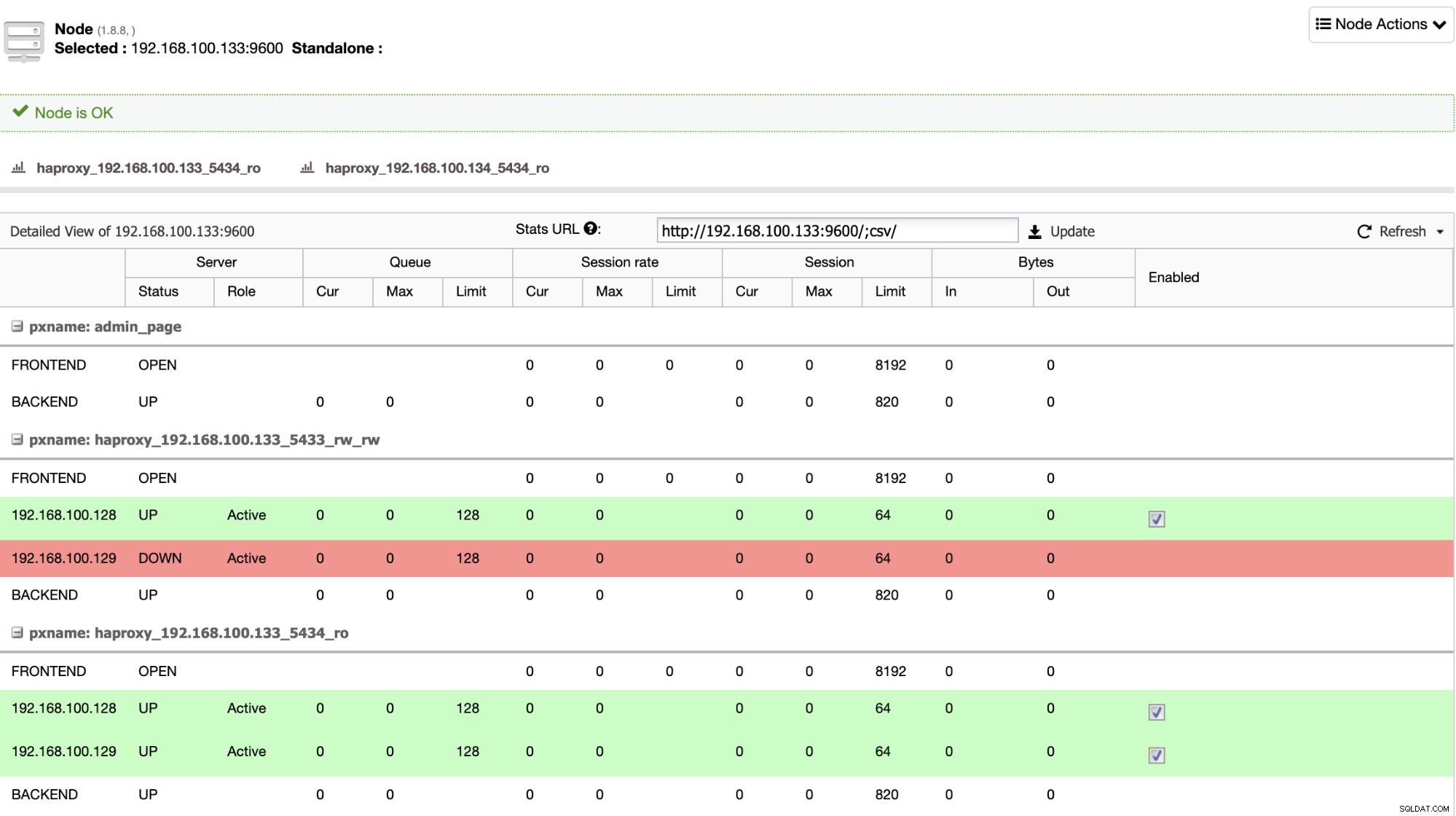
När HAProxy upptäcker att en av dina noder, antingen primär eller standby, är inte tillgänglig, den markerar den automatiskt som offline och tar inte hänsyn till den för att skicka trafik till den. Denna kontroll görs av hälsokontrollskript som är konfigurerade av ClusterControl vid tidpunkten för distributionen. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
Om din gamla primära nod kommer tillbaka kommer ClusterControl också undvika att starta den, för att förhindra en potentiell split-brain om du har en direkt anslutning som inte använder Load Balancer, men du kan lägga till den till klustret som en standby-nod på ett automatiskt eller manuellt sätt med hjälp av ClusterControl UI eller CLI, sedan kan du marknadsföra det till att ha samma topologi som du körde innan problemet.
Slutsats
Om du har alternativet "Autoåterställning" PÅ, kommer ClusterControl att utföra denna automatiska failover samt att meddela dig om problemet. På så sätt kan dina system återhämta sig på några sekunder utan ditt ingripande och du slipper en split-brain i en PostgreSQL Multi-Cloud-miljö.
Du kan också förbättra din High Availability-miljö genom att lägga till fler ClusterControl-noder med funktionen CMON HA som beskrivs i den här bloggen.