Failover är förmågan hos ett system att fortsätta fungera även om något fel inträffar. Det antyder att systemets funktioner övertas av sekundära komponenter om de primära komponenterna misslyckas eller om det behövs. Så om du översätter det till en PostgreSQL multi-molnmiljö, betyder det att när din primära nod misslyckas (eller en annan orsak som vi kommer att nämna i nästa avsnitt) i din primära molnleverantör, måste du kunna marknadsföra standbynoden i den sekundära för att hålla systemen igång.
Allmänt sett ger alla molnleverantörer dig ett failover-alternativ i samma molnleverantör, men det kan vara möjligt att du behöver överta till en annan molnleverantör. Naturligtvis kan du göra det manuellt, men du kan också använda några av ClusterControl-funktionerna som auto-failover eller främja slavåtgärder för att göra detta på ett vänligt och enkelt sätt.
I den här bloggen kommer du att se varför du skulle behöva failover, hur du gör det manuellt och hur du använder ClusterControl för denna uppgift. Vi antar att du har en ClusterControl-installation igång och redan har ditt databaskluster skapat i två olika molnleverantörer.
Vad används failover till?
Det finns flera möjliga användningsområden för failover.
Masterfel
Om din primära nod är nere eller till och med om din huvudsakliga molnleverantör har några problem måste du failover för att säkerställa att ditt system är tillgängligt. I det här fallet kan det vara nödvändigt att ha ett automatiskt sätt att göra detta för att minska stilleståndstiden.
Migrering
Om du vill migrera dina system från en molnleverantör till en annan genom att minimera din driftstopp, kan du använda failover. Du kan skapa en replik i den sekundära molnleverantören, och när den väl är synkroniserad måste du stoppa ditt system, marknadsföra din replik och failover innan du pekar ditt system till den nya primära noden i den sekundära molnleverantören.
Underhåll
Om du behöver utföra någon underhållsuppgift på din PostgreSQL primära nod kan du marknadsföra din replik, utföra uppgiften och bygga om din gamla primära som en standbynod.
Efter detta kan du marknadsföra den gamla primära och upprepa ombyggnadsprocessen på standbynoden och återgå till det ursprungliga tillståndet.
På detta sätt kan du arbeta på din server, utan att riskera att vara offline eller förlora information när du utför någon underhållsuppgift.
Uppgraderingar
Det är möjligt att uppgradera din PostgreSQL-version (sedan PostgreSQL 10) eller till och med uppgradera ditt operativsystem med logisk replikering utan stilleståndstid, eftersom det kan göras med andra motorer.
Stegen skulle vara desamma som att migrera till en ny molnleverantör, bara att din replika skulle vara i en nyare PostgreSQL- eller OS-version och du måste använda logisk replikering eftersom du inte kan använda streaming replikering mellan olika versioner.
Failover handlar inte bara om databasen utan också om applikationen. Hur vet de vilken databas de ska ansluta till? Du vill förmodligen inte behöva modifiera din applikation, eftersom detta bara kommer att förlänga din stilleståndstid, så du kan konfigurera en lastbalanserare så att när din primära nod är nere kommer den automatiskt att peka på servern som marknadsfördes.
Att ha en enda Load Balancer-instans är inte det bästa alternativet eftersom det kan bli en enda felpunkt. Därför kan du även implementera failover för Load Balancer, med hjälp av en tjänst som Keepalved. På det här sättet, om du har problem med din primära lastbalanserare, kommer Keepalived att migrera den virtuella IP-adressen till din sekundära lastbalanserare, och allt fortsätter att fungera transparent.
Ett annat alternativ är användningen av DNS. Genom att marknadsföra standbynoden i den sekundära molnleverantören ändrar du direkt värdnamnets IP-adress som pekar på den primära noden. På så sätt slipper du att behöva modifiera din applikation, och även om det inte kan göras automatiskt är det ett alternativ om du inte vill implementera en lastbalanserare.
Hur man failover PostgreSQL manuellt
Innan du utför en manuell failover måste du kontrollera replikeringsstatusen. Det kan vara möjligt att standbynoden inte är uppdaterad när du behöver failover på grund av ett nätverksfel, hög belastning eller något annat problem, så du måste se till att din standbynod har allt (eller nästan all information. Om du har mer än en standby-nod bör du också kontrollera vilken som är den mest avancerade noden och välja den till failover.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)När du väljer den nya primära noden kan du först köra kommandot pg_lsclusters för att få klusterinformationen:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logDå behöver du bara köra kommandot pg_ctlcluster med åtgärden främja:
$ pg_ctlcluster 12 main promoteIstället för föregående kommando kan du köra kommandot pg_ctl på detta sätt:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedDå kommer din standbynod att flyttas upp till primär, och du kan validera den genom att köra följande fråga i din nya primära nod:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Om resultatet är "f" är det din nya primära nod.
Nu måste du ändra den primära databasens IP-adress i din applikation, Load Balancer, DNS eller implementeringen som du använder, vilket, som vi nämnde, ändrar detta manuellt kommer att öka stilleståndstiden. Du måste också se till att din anslutning mellan leverantörerna fungerar korrekt, applikationen kan komma åt den nya primära noden, applikationsanvändaren har behörighet att komma åt den från en annan molnleverantör, och du bör bygga om standbynod(erna) i fjärrkontrollen eller till och med i den lokala molnleverantören, för att replikera från den nya primära, annars har du inte ett nytt failover-alternativ om det behövs.
Hur man failover PostgreSQL med ClusterControl
ClusterControl har ett antal funktioner relaterade till PostgreSQL-replikering och automatiserad failover. Vi antar att du har din ClusterControl-server installerad och att den hanterar din Multi-Cloud PostgreSQL-miljö.
Med ClusterControl kan du lägga till så många standbynoder eller Load Balancer-noder som du behöver utan några nätverks-IP-begränsningar. Det betyder att det inte är nödvändigt att standbynoden finns i samma primära nodnätverk eller ens i samma molnleverantör. När det gäller failover låter ClusterControl dig göra det manuellt eller automatiskt.
Manuell failover
För att utföra en manuell failover, gå till ClusterControl -> Välj Cluster -> Noder, och i Nod Actions för en av dina standbynoder, välj "Promote Slave".
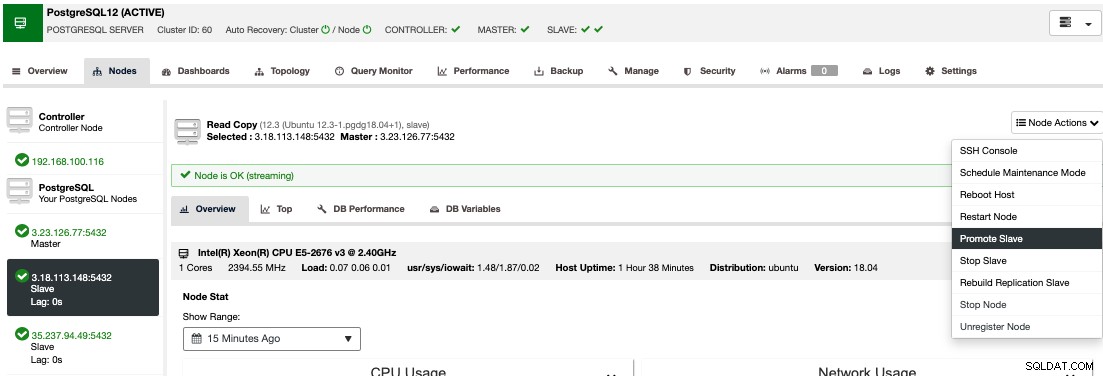
På detta sätt, efter några sekunder, blir din standbynod primär, och det som var din primära tidigare, förvandlas till standby. Så om din replik var i en annan molnleverantör, kommer din nya primära nod att vara där och vara igång.
Automatisk failover
I fallet med automatisk failover, upptäcker ClusterControl fel i den primära noden och främjar en standby-nod med de senaste uppgifterna som den nya primära. Det fungerar också på resten av standbynoderna för att få dem att replikera från denna nya primära.

Om du har alternativet "Autorecovery" PÅ kommer ClusterControl att utföra en automatisk failover som samt meddela dig om problemet. På så sätt kan dina system återhämta sig på några sekunder och utan din inblandning.
ClusterControl erbjuder dig möjligheten att konfigurera en vitlista/svartlista för att definiera hur du vill att dina servrar ska beaktas (eller inte tas med) när du bestämmer dig för en primär kandidat.
ClusterControl utför också flera kontroller av failover-processen, till exempel, som standard, om du lyckas återställa din gamla misslyckade primära nod, kommer den inte att återinföras automatiskt till klustret, varken som en primär eller som standby måste du göra det manuellt. Detta kommer att undvika risken för dataförlust eller inkonsekvens i fallet att ditt standbyläge (som du marknadsförde) försenades vid tidpunkten för felet. Du kanske också vill analysera problemet i detalj, men när du lägger till det i ditt kluster kan du eventuellt förlora diagnostisk information.
Load Balancers
Som vi nämnde tidigare är lastbalanseraren ett viktigt verktyg att överväga för din failover, speciellt om du vill använda automatisk failover i din databastopologi.
För att failover ska vara transparent för både användaren och applikationen behöver du en komponent däremellan, eftersom det inte räcker för att främja en ny primär nod. För detta kan du använda HAProxy + Keepalved.
För att implementera den här lösningen med ClusterControl, gå till Cluster Actions -> Add Load Balancer -> HAProxy på ditt PostgreSQL-kluster. Om du vill implementera failover för din lastbalanserare måste du konfigurera minst två HAProxy-instanser, och sedan kan du konfigurera Keepalived (klusteråtgärder -> Lägg till lastbalanserare -> Keepalived). Du kan hitta mer information om denna implementering i det här blogginlägget.
Efter detta kommer du att ha följande topologi:

HAProxy är som standard konfigurerad med två olika portar, en läs-skriv- och en skrivskyddad.
I läs-skrivporten har du din primära nod som online och resten av noderna som offline. I den skrivskyddade porten har du både den primära och standbynoden online. På så sätt kan du balansera lästrafiken mellan noderna. När du skriver kommer läs-skrivporten att användas, som pekar på den aktuella primära noden.

När HAProxy upptäcker att en av noderna, antingen primär eller standby, är inte tillgänglig, den markerar den automatiskt som offline. HAProxy kommer inte att skicka någon trafik till den. Denna kontroll görs av hälsokontrollskript som är konfigurerade av ClusterControl vid tidpunkten för distributionen. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
När ClusterControl marknadsför en ny primär nod, markerar HAProxy den gamla som offline (för båda portarna) och lägger den marknadsförda noden online i läs-skrivporten. På så sätt fortsätter dina system att fungera normalt.
Om den aktiva HAProxy (som har tilldelats en virtuell IP-adress som dina system ansluter till) misslyckas, migrerar Keepalved denna virtuella IP till den passiva HAProxy automatiskt. Det betyder att dina system sedan kan fortsätta att fungera normalt.
Kluster-till-klusterreplikering i molnet
För att ha en multimolnmiljö kan du använda ClusterControl Lägg till slav-åtgärden över ditt PostgreSQL-kluster, men också funktionen Cluster-to-Cluster-replikering. För närvarande har den här funktionen en begränsning för PostgreSQL som gör att du bara kan ha en fjärrnod, men vi arbetar för att ta bort den begränsningen snart i en framtida version.
För att distribuera det kan du kolla avsnittet "Kluster-till-klusterreplikering i molnet" i det här blogginlägget.

När det är på plats kan du marknadsföra fjärrklustret som kommer att generera ett oberoende PostgreSQL-kluster med en primär nod som körs på den sekundära molnleverantören.

Så, om du behöver det, kommer du att köra samma kluster i en ny molnleverantör på bara några sekunder.
Slutsats
Att ha en automatisk failover-process är obligatoriskt om du vill ha mindre driftstopp som möjligt, och även att använda olika tekniker som HAProxy och Keepalved kommer att förbättra denna failover.
ClusterControl-funktionerna som vi nämnde ovan kommer att tillåta dig att snabbt växla mellan olika molnleverantörer och hantera installationen på ett enkelt och vänligt sätt.
Det viktigaste att ta hänsyn till innan du utför en failover-process mellan olika molnleverantörer är anslutningen. Du måste se till att din applikation eller dina databasanslutningar kommer att fungera som vanligt med den huvudsakliga men även den sekundära molnleverantören vid failover, och av säkerhetsskäl måste du begränsa trafiken endast från kända källor, alltså endast mellan molnet leverantörer och inte tillåta det från någon extern källa.